
Если вы не очень часто программируете на Java, то этот топик скорее всего будет для вас бесполезен. Не читайте его :)
Недавно понадобилось решить следующую задачу: определить класс, которым параметризован generic-класс.
Если кто-то сталкивался с подобной задачей, то наверное также сразу попробовал написать что-то вроде этого:
Увы, IDE либо компилятор сразу укажут вам на ошибку («cannot select from a type variable» в стандартном компиляторе): " E.class" — не является допустимой конструкцией. Дело в том, что в общем случае во время исполнения программы информации о реальных параметрах нашего generic-класса может уже и не быть. Поэтому такая конструкция в Java не может работать.
Недавно понадобилось решить следующую задачу: определить класс, которым параметризован generic-класс.
Если кто-то сталкивался с подобной задачей, то наверное также сразу попробовал написать что-то вроде этого:
public class AbstractEntityFactory<E extends Entity> {
public Class getEntityClass() {
return E.class;
}
}Увы, IDE либо компилятор сразу укажут вам на ошибку («cannot select from a type variable» в стандартном компиляторе): " E.class" — не является допустимой конструкцией. Дело в том, что в общем случае во время исполнения программы информации о реальных параметрах нашего generic-класса может уже и не быть. Поэтому такая конструкция в Java не может работать.



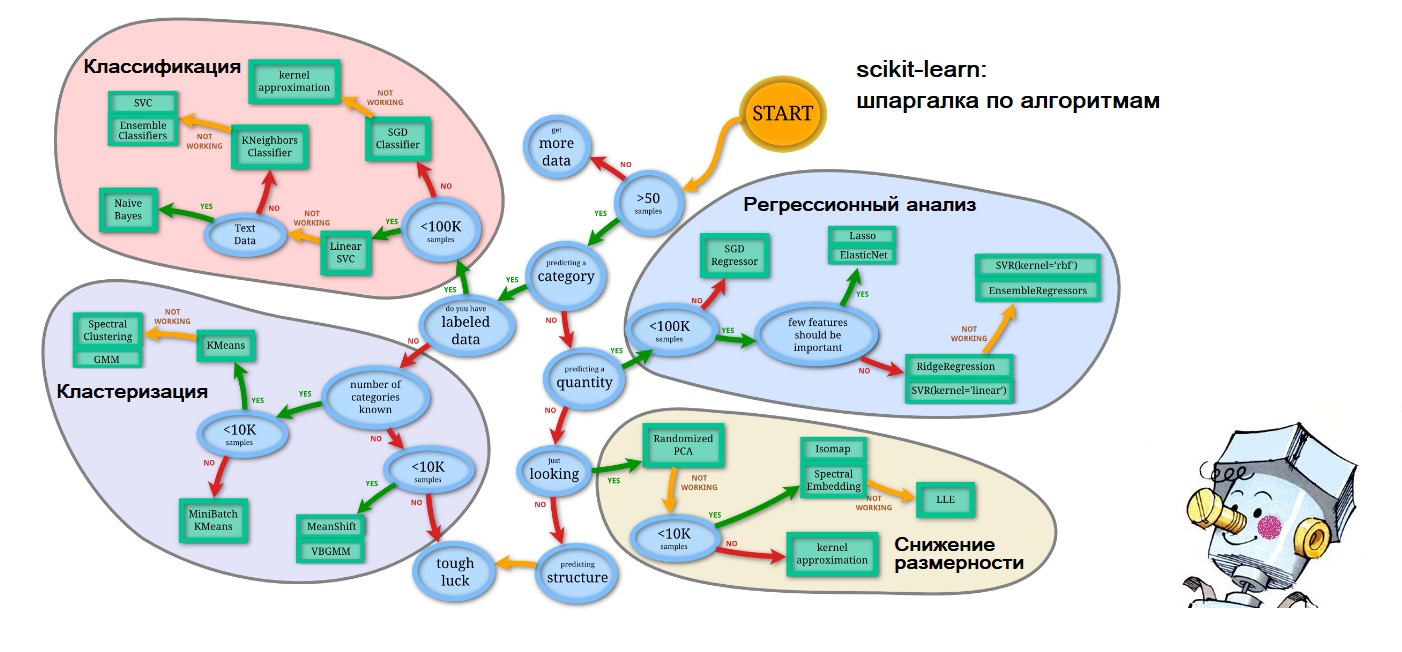







 Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности.
Посмотрим на то, как с ними работать в Python, какие возможные методы и модели можно использовать для прогнозирования; что такое двойное и тройное экспоненциальное взвешивание; что делать, если стационарность — это не про вас; как построить SARIMA и не умереть; и как прогнозировать xgboost-ом. И всё это будем применять к примеру из суровой реальности. 


{kind=link}