Comments 82
> Однажды наш ЦОД действительно потерял внешнее питание, и мы узнали, что кондиционеры не были подключены к ИБП. Машзалы мгновенно перегрелись, и через полчаса все системы начали отключаться.
У нас такая же фигня в одной серверной была. Питание резервировано очень мощными ИБП, хватало где-то на час или даже больше. А вот кондеры забыли зарезервировать. В итоге половина техники отключилась через полчаса, а вторая половина техники продолжила работать, но «сошла с ума»: кто стал сыпать ошибками, кто перешел в третье состояние и не поддавался перезагрузке удаленно. В общем весело было.
У нас такая же фигня в одной серверной была. Питание резервировано очень мощными ИБП, хватало где-то на час или даже больше. А вот кондеры забыли зарезервировать. В итоге половина техники отключилась через полчаса, а вторая половина техники продолжила работать, но «сошла с ума»: кто стал сыпать ошибками, кто перешел в третье состояние и не поддавался перезагрузке удаленно. В общем весело было.
Но около 6 утра эскаватор перерубил шедшую через континент оптику.
Только хотел написать о правиле экскаватора, но бравые австралийцы меня опередили
Только хотел написать о правиле экскаватора, но бравые австралийцы меня опередили
Знаю я и в России случаи, когда ЦОД дерьмом залило. Потом с инженерами этого ЦОДа все корректно отказывались за руку в этот день здороваться.
А в ЦОД было несколько других приколов. В нем используется воздушное охлаждение, но теплоотвод осуществляется в частности при помощи здоровенных холодильников с использование гликоля. В новогодние праздники один из холодильников дал течь и вышел из строя. Автоматика почему-то это не заметила. В итоге когда проверяющий инженер во время обхода заметил протечку, а прошло уже около 6 часов, в машинном зале температура была 55+ градусов.
Еще было весело с контроллером, который следит за насосами для этих холодильников. Это простой ПЛМ с небольшой мозгой и вебмордой, торчащей во внутренней сети. Эта штука всего одна на все насосы. Сбой насоса считается критическим и приводит к аварийной остановке всего ЦОДа в течении 5 минут. Так вот, оказалось что для этой штуки существует свой пакет-убийца, который при внезапном попадании вызывает сброс контроллера, который при этом тут же сообщает выше, что всем насосам кирдык и в итоге весь ЦОД мгновенно складывается. То, что это именно эта железка виновата сообразили далеко не сразу…
Еще было весело с контроллером, который следит за насосами для этих холодильников. Это простой ПЛМ с небольшой мозгой и вебмордой, торчащей во внутренней сети. Эта штука всего одна на все насосы. Сбой насоса считается критическим и приводит к аварийной остановке всего ЦОДа в течении 5 минут. Так вот, оказалось что для этой штуки существует свой пакет-убийца, который при внезапном попадании вызывает сброс контроллера, который при этом тут же сообщает выше, что всем насосам кирдык и в итоге весь ЦОД мгновенно складывается. То, что это именно эта железка виновата сообразили далеко не сразу…
Когда американцы проектировали АЭС они учли всё. В случае землетрясения останавливаются турбоагрегаты — основной источник питания циркуляционных насосов и они запитываются от дизеля. Надежно? Вроде да. Вот только после землетрясения прошло цунами (вызванное опять-таки землетрясением), затопившее дизельгенератор, отвечающий за питание цирк. насосов.
Думаю, все уже поняли, что речь о Фукусиме.
Согласен, что к IT относится слабо, но опыт тоже полезный.
* На правах истории, рассказанной мне преподавателем после аварии.
Думаю, все уже поняли, что речь о Фукусиме.
Согласен, что к IT относится слабо, но опыт тоже полезный.
* На правах истории, рассказанной мне преподавателем после аварии.
Простите, но что именно учли проектировщики построив АЭС с основанием ниже уровня моря? Да еще и на берегу моря.
Если бы ДГУ установили на платформу выше уровня цунами, то дизель бы не остановился и циркуляция в реакторной зоне продолжалась бы.
Цунами несет гораздо больше энергии, чем обычные штормовые волны той-же высоты, по этому конструкция, которая рассчитывалась на 10 метровые штормовые волны скорее всего не выдержит аналогичной по высоте волны цунами.
Следовательно подъем платформы с дизелями сводится к вопросу о том, как можно было строить АЭС, основание которой ниже уровня моря.
Не забывайте еще учесть, какие повреждения нанесло цунами электрике и трубопроводам станции. Мы видим только самую очевидную проблему: нет дизелей->нет электричества->нет циркуляции воды, но кто знает была ли возможность охлаждать при наличии электричества? Насколько были живы насосы и трубопроводы? Этого мы не знаем.
Прочность цепи не может быть выше прочности самого слабого звена, по этому совершив очевидный ляп по строительству АЭС ниже уровня моря на самом берегу рассуждать об остальных системах не имеет смысла. Если бы АЭС была выше или дальше от берега, то она прекрасно бы работала и дальше даже после цунами.
Следовательно подъем платформы с дизелями сводится к вопросу о том, как можно было строить АЭС, основание которой ниже уровня моря.
Не забывайте еще учесть, какие повреждения нанесло цунами электрике и трубопроводам станции. Мы видим только самую очевидную проблему: нет дизелей->нет электричества->нет циркуляции воды, но кто знает была ли возможность охлаждать при наличии электричества? Насколько были живы насосы и трубопроводы? Этого мы не знаем.
Прочность цепи не может быть выше прочности самого слабого звена, по этому совершив очевидный ляп по строительству АЭС ниже уровня моря на самом берегу рассуждать об остальных системах не имеет смысла. Если бы АЭС была выше или дальше от берега, то она прекрасно бы работала и дальше даже после цунами.
UFO just landed and posted this here
Угу.
У нас на складе до сих пор валяется шасси cat6509, которое затопило в подвале :)
И дизель, питавший наш офис, один раз не завелся. Дело было этим летом, с утра, и всех, кому не требуется сидеть на рабочем месте и у кого есть VPN, распустили по домам — ибо ИБП есть на много часов, но кондиционеры сразу умерли, а окна в БЦ принципиально не открываются, и уже через 10 минут работать стало совсем невыносимо. Хоть в серверных помещениях кондиционеры продолжали работать…
И один из наших ЦОДов года 4 назад ложился часов на 6 по питанию.
И падения двух совершенно независимых каналов от двух разных операторов до одной важной региональной площадки были (с интервалом в полчаса).
И внезапно выяснялось, что некая система, адски важная и подключенная к двум разным выделенным каналам, на самом деле имела связь лишь с одним из них, а резерв администраторы за долгие годы так и не удосужились проверить.
Эх…
У нас на складе до сих пор валяется шасси cat6509, которое затопило в подвале :)
И дизель, питавший наш офис, один раз не завелся. Дело было этим летом, с утра, и всех, кому не требуется сидеть на рабочем месте и у кого есть VPN, распустили по домам — ибо ИБП есть на много часов, но кондиционеры сразу умерли, а окна в БЦ принципиально не открываются, и уже через 10 минут работать стало совсем невыносимо. Хоть в серверных помещениях кондиционеры продолжали работать…
И один из наших ЦОДов года 4 назад ложился часов на 6 по питанию.
И падения двух совершенно независимых каналов от двух разных операторов до одной важной региональной площадки были (с интервалом в полчаса).
И внезапно выяснялось, что некая система, адски важная и подключенная к двум разным выделенным каналам, на самом деле имела связь лишь с одним из них, а резерв администраторы за долгие годы так и не удосужились проверить.
Эх…
Но ведь есть бумага, которая побеждает камень (здесь должна быть картинка)

Raid10, но диски одной партии(даже серийники почти по порядку).
В результате они оказались очень похожими.
В общем, механически сдохли 3/4 с интервалом 15 минут.
В результате они оказались очень похожими.
В общем, механически сдохли 3/4 с интервалом 15 минут.
Ага, похожая ерунда была. Еще и диски оказались из проблемной серии Seagate, причем все!
Одна знакомая контора (украинская) все, казалось бы сделала правильно — рабочий сервер, и резервный сервер, бекапы — на отдельном сервере. Но все это было у одного хостера, в одном ЦОДе. И там случился пожар… Не помню точно, как назывался тот хостер, но наверняка кто-то из хабровцев помнит эту историю.
Базу потом восстанавливали из той, что скачали к себе в локалку для тестирования новой версии софта.
Базу потом восстанавливали из той, что скачали к себе в локалку для тестирования новой версии софта.
Если не ошибаюсь было жарким летом 2010, я пользовался услугами хостинга и сервис был недоступен около 2х недель, а хостинг назвался «хостия», пожар был по причине электропитания
imhost?
Hosting.ua
В комментах даже пару фотографий есть.
В комментах даже пару фотографий есть.
Статья написана в духе «что ни делай, а всё равно произойдет две лажы подряд и всё сломается». Но ведь в 99% случаев случается лишь одна лажа в один момент времени и тут уж любой резерв пригодится.
Вам нужна надежность? Нет? Ну тогда можете обойтись простыми способами резервирования, не предполагающими катастрофоустойчивости и допускающими надежность на те самые две девятки :)
Кому-то ведь действительно этого хватает. Ну упадет инфраструктура на пару часов — ничего страшного.
А кому-то минута простоя одного участка — серьезная проблема.
Кому-то ведь действительно этого хватает. Ну упадет инфраструктура на пару часов — ничего страшного.
А кому-то минута простоя одного участка — серьезная проблема.
Это понятное дело. Просто от статьи веет безысходностью и детерминизмом. Мол, «и нафига было вообще стараться, если вот такие двойные беды бывают». Стараться всё-равно надо, и чем больше, тем лучше. А статья подбивает только руки опустить и молиться случаю.
Эта статья — из цикла «как делать не надо» или «о чем нужно помнить»
Нет. Именно что статья подбивает строить сервис так, чтобы при падении крупного метеорита на любой из хостящих его ЦОДов сервис продолжил работу с минимальным простоем. И нельзя исходить из того, что вроде бы на первый взгляд не связанные друг с другом компоненты, резервирующие друг друга, не могут отказать одновременно.
Не совсем. Статья начиналась с того, что каждый компонент должен разрабатываться с требованием надежности, а не надеяться на надежность нижележайших уровней.
а по мне, статья очень веселая! =) И понятно, что описаны редкие случаи, ясное дело обычно не происходит «сразу всё».
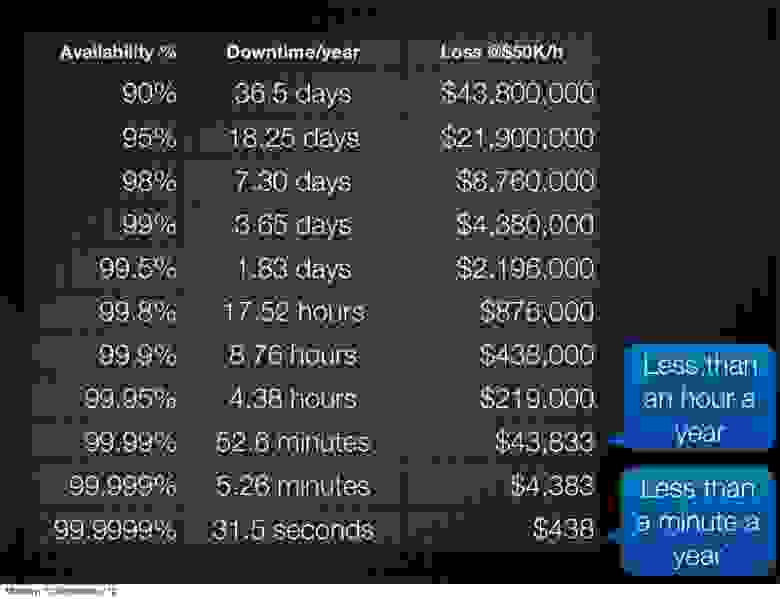
Кстати, по поводу отличной от нуля вероятности и SLA. Вот о таких цифрах мы никогда не задумываемся, но что если простой стоит $50к в час, то от девяток много что зависит. Вот такой слайд я видел на конференции Cloud Connect:

вчера экскаватор перебил 4 оптики в канализации. По иронии судьбы работали без согласований, без ордеров и яма аккурат под огромным желтым щитом, на котором красными большими буквами написано. ЗДЕСЬ КОПАТЬ ЗАПРЕЩЕНО.
Обратная ситуация:
Небольшая серверная небольшого провайдера, питание резервировано UPS и генераторами, все корректно отрабатывает, упсы перехватывают, генераторы заводятся, кондиционеры работают. Вот только работающие маршрутизаторы, бесперебойная связь и продолжающее выдавать прекрасную картинку оборудование головной станции КТВ никому не нужно — обесточен весь район обслуживания. Погасили все и пошли по домам.
Небольшая серверная небольшого провайдера, питание резервировано UPS и генераторами, все корректно отрабатывает, упсы перехватывают, генераторы заводятся, кондиционеры работают. Вот только работающие маршрутизаторы, бесперебойная связь и продолжающее выдавать прекрасную картинку оборудование головной станции КТВ никому не нужно — обесточен весь район обслуживания. Погасили все и пошли по домам.
И это все от недостатка тестирования… но с другой стороны как его осуществлять?)
Еще один случай из классики жанра:
royal.pingdom.com/2007/11/13/truck-takes-down-rackspace/
В 2007 году грузовик въезжает в подстанцию, и выносит питание ЦОДу Rackspace — ага, вот те ребята (с) с 100% аптаймом по их рекламе. Бэкапное питание завелось, а два кондиционера — нет. Было выключено довольно много серверов, которым светил перегрев, включая 37signals, а так же сервер вашего покорного, на котором крутился софт медицинского назначения. Крику было… RS потом две недели сочиняла извинения.
Ну и давний эпик из Германии (sic!). Не помню точно год, где-то 2003 — но полстраны как-то утром осталась без Интернета. Пьяный экскаваторщик перерубил магистральную оптику под Франкфуртом — просто вот так, несмотря на кучу предупреждений аля «не копать — кабЕль». И это при местной рабочей культуре, которая без команды обычно чихнуть не смеет, т.е. проверять перед копанием — как бы само собой. Доступ появился только после обеда.
royal.pingdom.com/2007/11/13/truck-takes-down-rackspace/
В 2007 году грузовик въезжает в подстанцию, и выносит питание ЦОДу Rackspace — ага, вот те ребята (с) с 100% аптаймом по их рекламе. Бэкапное питание завелось, а два кондиционера — нет. Было выключено довольно много серверов, которым светил перегрев, включая 37signals, а так же сервер вашего покорного, на котором крутился софт медицинского назначения. Крику было… RS потом две недели сочиняла извинения.
Ну и давний эпик из Германии (sic!). Не помню точно год, где-то 2003 — но полстраны как-то утром осталась без Интернета. Пьяный экскаваторщик перерубил магистральную оптику под Франкфуртом — просто вот так, несмотря на кучу предупреждений аля «не копать — кабЕль». И это при местной рабочей культуре, которая без команды обычно чихнуть не смеет, т.е. проверять перед копанием — как бы само собой. Доступ появился только после обеда.
100% гарантия SLA Rackspace в рекламе означает что за любой прокол компания отвечает и оплатит издержки.
100% uptime, к сожалению, не возможен даже у Rackspace, максимум – много девяток после запятой. Я тоже по началу удивился, но потом понял что там не uptime, а SLA.
100% uptime, к сожалению, не возможен даже у Rackspace, максимум – много девяток после запятой. Я тоже по началу удивился, но потом понял что там не uptime, а SLA.
UFO just landed and posted this here
Вчера отключили электиричество, но angri birds всеравно работает на айпаде. :) 4 часа, полет нормальный. По одному айпаду на каждого члена семьи. + два вайфай-3г маршрутизатора разных производителей, htc и nokia. Бюджет системы менее 100к рублей.
Здание, не ЦОД, и все его основные BMS, включая серверную комнату запитаны по 1 категории, т.е. 2 различных ввода + ИБП для серверной и дизель на пол мегаватта для основных BMS, в серверной комнате 1 центральный прецизионный кондиционер и 2 резервных тоже прецизионники, но меньшего размера — центральный по 1 категории, резервные дополнительно еще и на ИБП.
Где-то в районе 3-х часов утра выключается 1 линия, все сотрудники ИТ получили уведомление в виде смс о падении одной линии питания, инженеры-электрики (но не ИТ) вызваны на место, но не успевают доехать, через полчаса после первой падает вторая линия, снова уведомление в виде смс, срабатывают ИБП, все основные системы продолжают нормально работать, за исключением внешних блоков резервных кондиционеров. Во время переключения на ИБП по какой-то причине внешние блоки кондиционеров перезапустились, в результате этого перезапуска оказалось достаточно для того, что бы управляющие блоки обоих резервных кондиционеров сошли с ума и потеряли связь с внешними блоками, а восстановить связь автоматически им не удалось. В виду того, что серверная вместе с кондиционерами должна была проработать минимум 6 часов, то ИТ не вызывали. Доступ в серверную комнату, как в помещение особого назначения есть только у ИТ, так что никто в нее не заходил и не проверял состояние систем. Вобщем через 2 часа после уведомления о переходе на ИБП посыпались уведомления о принудительном выключении оборудования по перегреву.
Первая линия электропитания выключилась из-за аварии на подстанции, вторая линия — золотое правило экскаватора, возможно даже и авария на подстанции связана с экскаватором.
Где-то в районе 3-х часов утра выключается 1 линия, все сотрудники ИТ получили уведомление в виде смс о падении одной линии питания, инженеры-электрики (но не ИТ) вызваны на место, но не успевают доехать, через полчаса после первой падает вторая линия, снова уведомление в виде смс, срабатывают ИБП, все основные системы продолжают нормально работать, за исключением внешних блоков резервных кондиционеров. Во время переключения на ИБП по какой-то причине внешние блоки кондиционеров перезапустились, в результате этого перезапуска оказалось достаточно для того, что бы управляющие блоки обоих резервных кондиционеров сошли с ума и потеряли связь с внешними блоками, а восстановить связь автоматически им не удалось. В виду того, что серверная вместе с кондиционерами должна была проработать минимум 6 часов, то ИТ не вызывали. Доступ в серверную комнату, как в помещение особого назначения есть только у ИТ, так что никто в нее не заходил и не проверял состояние систем. Вобщем через 2 часа после уведомления о переходе на ИБП посыпались уведомления о принудительном выключении оборудования по перегреву.
Первая линия электропитания выключилась из-за аварии на подстанции, вторая линия — золотое правило экскаватора, возможно даже и авария на подстанции связана с экскаватором.
У нас все было сделано как положено, кондиционирование тоже было с запасом, но тут наступает весна, тополи просыпаются и… в понедельник я прихожу, берусь за металлическую ручку деревянной двери ЦОД и отскакиваю — температура ручки — порядка 60 градусов. Заскочив в эту духовку, я обнаружил что рубашка моментально разогрелась и горячая, к стойкам больно прикасаться, оборудование почти все выдержало, сдохла пара БП в серверах, благо, второй БП перехватил, но поповина оборудования весело моргала огоньками и висела. Остывал ЦОД почти 6 часов при проточной вентиляции.
UFO just landed and posted this here
Согласен, но серверная была маленькая и бюджетная (чуть больше 30 серверов). Удивительно, что вообще было то, что было.
UFO just landed and posted this here
Даже встроенный софт наверняка умеет отправлять емейлы о факапах, будь то вылет винта или перегрев.
Хотя лучше, конечно, ставить внешние датчики температуры, влажности, шума и так далее.
Хотя лучше, конечно, ставить внешние датчики температуры, влажности, шума и так далее.
Бессмысленно — дело в том, что в нерабочее время в здание попасть было невозможно, а в рабочее мониторинг работал, целых две системы постоянно мониторили все сервисы и уведомления были настроены ответственным инженерам и мне. Поэтому, о том, что там проблемы с доступностью сервисов я знал еще в выходные, но что-то делать было бесполезно — все равно в серверную до понедельника не попасть.
Это где такой цирк твориться, что в аварийной ситуации, которая может привести минимум к выходу из строя оборудования, а как максимум к пожару персонал не допускается для ее ликвидации?
В любой нормальной организации даже с повышенными мерами безопасности есть регламент на доступ определенного персонала в определенные помещения в круглосуточном режиме. Охрана конечно будет не сильно рада такой радости, но раз регламент есть, то будут его выполнять.
В любой нормальной организации даже с повышенными мерами безопасности есть регламент на доступ определенного персонала в определенные помещения в круглосуточном режиме. Охрана конечно будет не сильно рада такой радости, но раз регламент есть, то будут его выполнять.
Здание Юниаструм банка на углу Селезневской и Суворовской площади.
Дело в том, что в том же здании находится Импромашпром — те самые, что ракетами занимались. Режимный объект. Им похер на все пожарные требования — на проходной стоит часовой с автоматом.
Дело в том, что в том же здании находится Импромашпром — те самые, что ракетами занимались. Режимный объект. Им похер на все пожарные требования — на проходной стоит часовой с автоматом.
Значит пока гром не грянет…
А про автоматчиков, ведь хотел же я написать, что ситуации, когда работы на объекте во вне рабочее время проводятся только в присутствии пары автоматчиков вполне реальны, но подумал, что это лишнее :)… Так что часовой с автоматом ничего не говорит об уровне общего бардака.
А про автоматчиков, ведь хотел же я написать, что ситуации, когда работы на объекте во вне рабочее время проводятся только в присутствии пары автоматчиков вполне реальны, но подумал, что это лишнее :)… Так что часовой с автоматом ничего не говорит об уровне общего бардака.
Резервирование делается для защиты от штатных отказов и аварий.
В случае катастрофы поможет только грамотно разработанный процесс Disaster Recovery. Поможет быстро восстановиться после катастрофы, а не защититься.
В случае катастрофы поможет только грамотно разработанный процесс Disaster Recovery. Поможет быстро восстановиться после катастрофы, а не защититься.
Случай из жизни.
Резервировалась база SQL Server.
Сначала на другой логический диск, потом записывалась на DVD-RW болванку.
Во время перезаписи текущей болванки накрывается физически жесткий диск,
+система рестартует.
База непоправимо уничтожена.
Последний и предпоследний бэкап на DVD-RW уничтожены.
Зато теперь 3 копии, на разнесенных серверах.
Полный бэкап+Разностный бэкап+бэкап trasaction log. )))
Если бы мне рассказали — не поверил бы. ))
Резервировалась база SQL Server.
Сначала на другой логический диск, потом записывалась на DVD-RW болванку.
Во время перезаписи текущей болванки накрывается физически жесткий диск,
+система рестартует.
База непоправимо уничтожена.
Последний и предпоследний бэкап на DVD-RW уничтожены.
Зато теперь 3 копии, на разнесенных серверах.
Полный бэкап+Разностный бэкап+бэкап trasaction log. )))
Если бы мне рассказали — не поверил бы. ))
А зря не поверили бы ) Дело в том, что когда что-то начинает ломаться, по определению все остальное оборудование работает в режиме повышенной нагрузки, а это существенно повышает шанс выхода из строя. Именно поэтому Backup сервер обычно отдельно стоящий, он принимает снимок, а потом уже пишет его спокойненько на ленту или болванку или куда там вы запланировали.
Не всегда директор понимает фразу «отдельно стоящий Backup сервер» ))
Ага, часто после первого невосстановимого бекапа только начинает понимать…
Угу, после переезда в новый офис, с большой серверной, файловый сервак с RAID5 из 10 дисков таки упал по вине контроллера (тот самый сервер, что пережил перегрев ранее), после этого ген.дир пришел и сказал (дословно):«что тебе нужно, чтобы такого больше не повторилось?» И выделил деньги на то оборудование, что я порекомендовал.
Ну, а бывает и по другму — до сих пор помню свой первый выговор, на заре админской карьеры, после невосстановимого бекапа и моего замечания, (мол, «а я же предупреждал что нужно отдельное железо») — деректор выдал перл «ну ты же спциалист, надо было НАСТОЯТЬ на своём». :)
И, как это ни обидно, в некотором смысле он был прав )
другой вопрос, что этому нигде не обучают, никогда об этом не предупреждают и тп. Но если нам отказывают, то желательно доводить до сведения того, кто подписывает отказ в письменной форме чем это грозит.
Если человек пишет — ок, с риском согласен, то тогда уже он будет неправ.
другой вопрос, что этому нигде не обучают, никогда об этом не предупреждают и тп. Но если нам отказывают, то желательно доводить до сведения того, кто подписывает отказ в письменной форме чем это грозит.
Если человек пишет — ок, с риском согласен, то тогда уже он будет неправ.
Прекрасно понимаю, я выделил под него сервер, который не тянул свою нагрузку, официально был устаревший, а для бэкапа много не нужно. К тому же отдельно стоящим он должен быть от сервера, который бэкапит. Главное, чтобы он не был нагружен под завязку дисковыми и вычислительными операциями. Совмещать никто не запрещает. Но то, что работает на нем, должно бэкапиться на другой сервер. Это усложняет поддержку, но если денег на отдельный сервер нет, то лучше так.
У нас в EDU все было резервировано. Но вот одно мы исправить не могли. Машинный зал находился прямо под туалетом художественного отдела. В общем, однажды нас натурально затопило говном. А вы знали, что можно заказать у Sun Microsystems выезд их бойцов для протирки оборудования СХД ватными тампонами со спиртом?
Вот это просто бесценно :D Представляю себе «радость» бойцов Сан, когда они приехали «протирать оборудование спиртом» после такого :D Серверную затопило говном дизайнеров… хмм, знакомо! :D
Пара случаев из моей жизни:
1. Две линии питания, с разных подстанций. Сводятся, разумеется, в одном релейном шкафу. Ночной охранник поставил на шкаф чайник с водой и опрокинул его.
2. ДЦ с двумя каналами выхода в инет, от двух разных провайдеров, выводы с разных сторон здания. Как оказалось позднее, чрез километр экономные провайдеры решили объединить усилия и потянули кабели вместе. Не в канализации, по воздуху. Упавшее во время шторма дерево накрыло оба кабеля.
Сколько не резервируй, где-то за стенами будет SPOF, и метеорит прилетит именно туда.
1. Две линии питания, с разных подстанций. Сводятся, разумеется, в одном релейном шкафу. Ночной охранник поставил на шкаф чайник с водой и опрокинул его.
2. ДЦ с двумя каналами выхода в инет, от двух разных провайдеров, выводы с разных сторон здания. Как оказалось позднее, чрез километр экономные провайдеры решили объединить усилия и потянули кабели вместе. Не в канализации, по воздуху. Упавшее во время шторма дерево накрыло оба кабеля.
Сколько не резервируй, где-то за стенами будет SPOF, и метеорит прилетит именно туда.
UFO just landed and posted this here
Ну не сам он, а вода из его чайника.
Обычно и сам машинный зал, и все вспомогательные объекты (ИБПшная и так далее) — те места, к которым охранник даже приближаться не может. В крайнем случае — в сопровождении дежурного инженера. Так что действительно странно.
Странно или нет. В РНД есть (или был) один такой провайдер, у которого весь город отрубило. Так вот один мой знакомый работал как раз дежурным инженером. И был дежурный электрик, который должен был следить ночью за энергообеспечением здания. Но и электрик был спросони, и инженер не сильно вкуривал в OVER 9000 рубильников. Сначала грохнули основное питание. Потом грохнули аварийное. Ну проработали маршрутизаторы порядка часа на ИБП. А потом и весь дневной состав приехал разбираться что случилось, и ночной. Чем для электрика история закончилась так и не узнал, было это давно и не правда.
Тоже наблюдал странные вещи.
У меня в квартире стоит стабилизатор на входе, вся техника подключена в сетевые фильтры, все заземлено — все как положено. И вот полетел не самый дешевый БП FSP через 2,5 года использования, унеся за собой винт Seagate с кучей ценной информации.
А у знакомого в деревне без заземления, с мигающими от перепадов лампочками стоит китайский Codegen, который даже по заявленной мощности не соответствует компонентам ПК — и подключен в уже оплавленную розетку. На мои возгласы «чуваак, выкинь эту штуку, тебе нужно купить нормальный БП!» он ответил: «Да ладно, я его в 2004 купил и все работает. Зачем что-то менять?».
Тут-то я и задумался…
У меня в квартире стоит стабилизатор на входе, вся техника подключена в сетевые фильтры, все заземлено — все как положено. И вот полетел не самый дешевый БП FSP через 2,5 года использования, унеся за собой винт Seagate с кучей ценной информации.
А у знакомого в деревне без заземления, с мигающими от перепадов лампочками стоит китайский Codegen, который даже по заявленной мощности не соответствует компонентам ПК — и подключен в уже оплавленную розетку. На мои возгласы «чуваак, выкинь эту штуку, тебе нужно купить нормальный БП!» он ответил: «Да ладно, я его в 2004 купил и все работает. Зачем что-то менять?».
Тут-то я и задумался…
Аппаратный Adaptec RAID 1 с батарейкой в состоянии «optimal» :) Сервер не перегружался… Суперблок на ext3 пропал, fsck по резервной копии супер-блока никак не помог, некоторые каталоги оказались в бесконечном цикле :)
До этого сервер проработал год без перезагрузки и каких-либо проблем…
Вобщем мистика в чистом виде… «НЛО прилетело и украло ваш суперблок»…
До этого сервер проработал год без перезагрузки и каких-либо проблем…
Вобщем мистика в чистом виде… «НЛО прилетело и украло ваш суперблок»…
Половину всех аварий можно было избежать проводя периодические учения и испытания разных сценариев отказа.
У нас тоже как-то накрылся европейский ЦОД во время грозы. Сначала выбило молнией подстанцию и ЦОД начал переключаться на генераторы, а следующий удар молнии накрыл цепи генераторов. Переключение на резервный ЦОД произошло с ошибками в результате чего всю сеть колбасило несколько часов…
Sign up to leave a comment.
Законы Мерфи в IT