Comments 59
Девушка кстати известно как выступила, не?
О, и Гор Нишанов здесь :) В одной школе учились (сейчас она правда уже не с.ш., а ФМЛ №61 г. Бишкек). Насколько я знаю, также работает в MS.
Результаты не загружаются. Может, под спойлер?
UFO just landed and posted this here
Так алгоритм и так дан, переписать его на любом доступном высокоуровневом языке — не проблема (даже тогда). Задача состоит в том, чтобы без компьютера рассчитать, что программа вывела бы на экран после запуска.
Ну, положим, вывод всех делителей с учётом кратности тут виден довольно прозрачно. Когда бы они знали про то, что спустя 20 лет будет представлять собой минифицированный javascript…
Ну, или тот же ioccc, где сокрытие смысла возведено в ранг искусства.
Однако да, с тем, что условия у них были суровы, не поспоришь.
Тогда: без доступа к компьютеру решай задачку за олимпиадные часы.
Сейчас: google, stackoverflow, google, msdn, пишем, ух ты, codeproject!……… итого в ютреке таск закрыт за 8 часов. Совершенно необязательно, что алгоритмически более сложный (а то и вообще не более сложный).
Ну, или тот же ioccc, где сокрытие смысла возведено в ранг искусства.
Однако да, с тем, что условия у них были суровы, не поспоришь.
Тогда: без доступа к компьютеру решай задачку за олимпиадные часы.
Сейчас: google, stackoverflow, google, msdn, пишем, ух ты, codeproject!……… итого в ютреке таск закрыт за 8 часов. Совершенно необязательно, что алгоритмически более сложный (а то и вообще не более сложный).
Во первых, все-же код должен быть написан так, чтобы его понимали люди и иногда машины. Минификация и обфускация имеют совсем другие причины и преследуют иные цели.
Во вторых, пусть в 88 мне было только 8 лет, но в уже в 95 я во всю строчил говнокод на листочках бамаги
В третьих, сейчас, есть задачи не имеющие даже общего решения, задачи вполне типовые(кажется на первый взгляд), форкать библиотеки и подпиливать под свои частные условия, тоже регулярно приходится. Нередки проекты в которых 20% тасков закрываются 80% времени. И никакие гугли с мсднами не помогут.
Во вторых, пусть в 88 мне было только 8 лет, но в уже в 95 я во всю строчил говнокод на листочках бамаги
В третьих, сейчас, есть задачи не имеющие даже общего решения, задачи вполне типовые(кажется на первый взгляд), форкать библиотеки и подпиливать под свои частные условия, тоже регулярно приходится. Нередки проекты в которых 20% тасков закрываются 80% времени. И никакие гугли с мсднами не помогут.
«Тогда» и «Сейчас» вы что вообще сравниваете?
Сейчас на Всероссийских олимпиадах доступа к интернету тоже нет. Хотя инструментарий и стандартизация, конечно, расширились. Да и типы задач/сложность.
Сейчас на Всероссийских олимпиадах доступа к интернету тоже нет. Хотя инструментарий и стандартизация, конечно, расширились. Да и типы задач/сложность.
Не столько сравниваю, сколько просто замечаю, что тогда приходилось держать всю задачу и весь код в голове, а сейчас — есть не только быстрый комп (для задач попроще уже это — решающий фактор), но и отладчик (а вот уже это очень много и «решает» в случае задач посерьёзнее).
Ну и, благодаря инструментарию, появилась возможность ставить и решать задачки потяжелее. В голове-то, наверное, что-нибудь из динамического программирования тяжко было бы держать целиком…
Ну и, благодаря инструментарию, появилась возможность ставить и решать задачки потяжелее. В голове-то, наверное, что-нибудь из динамического программирования тяжко было бы держать целиком…
Ту же четвёртую задачу за разумное время не очень-то напишешь. Если на бумажке достаточно написать «сливаем отсортированные блоки на 10 лентах и записываем на новую ленту», то на компьютере это пришлось бы программировать — а там столько мелочей, что времени на их проработку может не хватить. На командной студенческой олимпиаде с ней, может быть, и справятся. Да и то только сильные.
Зависит от опыта аккуратного написания алгоритмов. Например, я не вижу в MergeSort (для двух лент) никаких случаев и мелочей — код очень простой: один цикл и один if.
Не забывайте, что там нужно постепенно укрупнять блоки (сначала будут отсортированы блоки из одного элемента, потом из двух, потом из четырёх..), что некоторые блоки могут быть неполными, что результат слияния надо либо сразу записывать на две ленты, либо потом переносить половину с одной ленты на другую, что число блоков на лентах может оказаться разным… Да, мелочи. Но одним циклом обойтись будет сложно. А поскольку требуется «быстрее», то надо ещё предусмотреть какое-нибудь блочное чтение — отдельный запуск магнитофона для чтения каждой записи может быть дорогим.
Если делать с фиксированным размером — то так даже проще, чем если брать максимальные по включению неубывающие блоки.
И я всё еще не отрекаюсь от своего утверждения. Вы меня сейчас даже заинтересовали, надо будет попробовать и сюда запостить. Хотя да, еще потребуется внешний цикл по длине блока, потому что надо сортировку, а не простое слияние.
Блочное чтение — да, не предусмотрел. Кажется, что просто выделяется один слой абстракции (читать как «функция чтения с ленты, кэширующая результат») и, опять же, в самом алгоритме ничего сложного.
Вы меня заинтриговали, challenge accepted.
И я всё еще не отрекаюсь от своего утверждения. Вы меня сейчас даже заинтересовали, надо будет попробовать и сюда запостить. Хотя да, еще потребуется внешний цикл по длине блока, потому что надо сортировку, а не простое слияние.
Блочное чтение — да, не предусмотрел. Кажется, что просто выделяется один слой абстракции (читать как «функция чтения с ленты, кэширующая результат») и, опять же, в самом алгоритме ничего сложного.
Вы меня заинтриговали, challenge accepted.
Почему же «в голове»? В голове и на черновике, думаю — а это уже существенное подспорье.
Например, я и многие мои знакомые из инструментария используют только редактор с подсветкой синтаксиса, компилятор и (очень редко) gdb в режиме «покажи мне, в какой строчке упала программа», Остальное — мозг, черновик, проработка, чтение кода, что можно было делать и тогда. Хотя и отладчики тоже используют. Но, например, на командных это жутко неэффективное использование компьютерного времени — вдумчивое чтение кода.
Более сложные задачи — я скорее отношу это к общему повышению уровня (что хорошо наблюдается в том числе и в последние годы), и бОльшему распространению олимпиад. Например, по воспоминаниям Андрея Лопатина в 2000-2001 году для победы в финале ACM ICPC хватало просто «быть крутым программистом, знать какие-то алгоритмы и офигительно работать в команде». Сейчас к этому необходимо добавить огромный опыт решения именно олимпиадных задач, недюжинной аккуратности и знания чего-то не самого тривиального из Computer Science.
ДП, вычислительная геометрия и прочее — я не знаю, как тут может помочь компьютер. Только бумажка и аккуратность.
Например, я и многие мои знакомые из инструментария используют только редактор с подсветкой синтаксиса, компилятор и (очень редко) gdb в режиме «покажи мне, в какой строчке упала программа», Остальное — мозг, черновик, проработка, чтение кода, что можно было делать и тогда. Хотя и отладчики тоже используют. Но, например, на командных это жутко неэффективное использование компьютерного времени — вдумчивое чтение кода.
Более сложные задачи — я скорее отношу это к общему повышению уровня (что хорошо наблюдается в том числе и в последние годы), и бОльшему распространению олимпиад. Например, по воспоминаниям Андрея Лопатина в 2000-2001 году для победы в финале ACM ICPC хватало просто «быть крутым программистом, знать какие-то алгоритмы и офигительно работать в команде». Сейчас к этому необходимо добавить огромный опыт решения именно олимпиадных задач, недюжинной аккуратности и знания чего-то не самого тривиального из Computer Science.
ДП, вычислительная геометрия и прочее — я не знаю, как тут может помочь компьютер. Только бумажка и аккуратность.
Прикольно показывать Junior'ам, сразу запускающим debug, что путем чтения кода можно найти ошибку быстрее, чем соберется проект. :-) А без сборки и запуска, ясно-понятно, в debug не попадешь. Еще и тестовые данные нужно подготовить, попасть в нужный сценарий…
Хотя иногда отладчик незаменим — бывает и такое.
Хотя иногда отладчик незаменим — бывает и такое.
Давайте задачу №4 на C#.
Вряд ли C# пойдёт на ЭВМ с 64 КБ памяти :(
Да, внешняя сортировка на 30 лентах — это жестоко. Основная проблема, как и ожидалось, была с неполным блоком — на выходных лентах он должен быть только один, на любой стадии алгоритма.
www.dropbox.com/s/4zo294kam8efziw/QueueSort.cs?dl=0
В итоге поиск нужного человека в очереди выполняется примерно за 210 просмотров данных. Что любопытно, если длина фамилии ограничена 30 символами, то фамилии первого и последнего человека можно найти за один просмотр ленты, не пользуясь другими лентами! На это нужно меньше 8 КБ. Но на поиск более далёких людей этот алгоритм пока не обобщается.
www.dropbox.com/s/4zo294kam8efziw/QueueSort.cs?dl=0
В итоге поиск нужного человека в очереди выполняется примерно за 210 просмотров данных. Что любопытно, если длина фамилии ограничена 30 символами, то фамилии первого и последнего человека можно найти за один просмотр ленты, не пользуясь другими лентами! На это нужно меньше 8 КБ. Но на поиск более далёких людей этот алгоритм пока не обобщается.
Вроде разобрался с задачами, но не совсем ясно:
1) Тут вычисляются все делители числа
2) чистая геометрия с проверками условий
3) на сколько я понял обход графа и алгоритм дейкстры
4) работа с деревьями, но не совсем понял про магнитофоны, что имели в виду, что на касетах можно хранить инфу, так как в память не влезит? Ну можно хранить список на касете, Вирт об этом писал в книге какой-то + хранить не сами фамилии а их хеш.
5) Цикл и длинная арифметика + вывод более простой арифметики для этой последовательности
6) Бэктрегинг.
1) Тут вычисляются все делители числа
2) чистая геометрия с проверками условий
3) на сколько я понял обход графа и алгоритм дейкстры
4) работа с деревьями, но не совсем понял про магнитофоны, что имели в виду, что на касетах можно хранить инфу, так как в память не влезит? Ну можно хранить список на касете, Вирт об этом писал в книге какой-то + хранить не сами фамилии а их хеш.
5) Цикл и длинная арифметика + вывод более простой арифметики для этой последовательности
6) Бэктрегинг.
1) Незачет. Не все делители, а разложение на множители. Например, 12 делится на 2,3,4,6,12. А программа выведет 2,2,3
4) Магнитофоны — означает, что вы не можете хранить во внешней памяти все данные сразу. Если фамилия не найдена на 1 из 32 лент, кому-то придется идти к лентопротяжке и ставить другую бабину.
4) Магнитофоны — означает, что вы не можете хранить во внешней памяти все данные сразу. Если фамилия не найдена на 1 из 32 лент, кому-то придется идти к лентопротяжке и ставить другую бабину.
Нет, магнитофоны — это и есть внешняя память. У нас это были бы файлы с последовательным доступом. Скорее всего, на каждой ленте могут уместиться все фамилии (причём по два раза). В сущности, задача на то, чтобы описать внешнюю сортировку, и правильно её использовать.
Нет, магнитофоны — это и есть внешняя память.
Я это и сказал. Внешняя память с ограничениями.
Скорее всего, на каждой ленте могут уместиться все фамилии (причём по два раза).
Не согласен. Тогда не было бы ограничения по количеству лентопротяжек. 3млн пар по 32 символа это 183 МБт. На одну ленту дай бог 40 Мбт помещается.
Из условия: «упорядоченные пары фамилий записали на магнитофонную ленту». Значит, помещается.
Это означает тип носителя, а не количество единиц.
К тому же, если следовать вашей логике, то записали на 1 бобину, а не на 32 — тогда указание количества лентопротяжек бессмысленно — у нас же одна лента только! Значит, «записали на ленту» означает только лишь тип носителя. Вы можете сказать «я записал архив на ленту», при том что сам архив состоит из 10 томов, следовательно, 10 лент. Просто никто не говорит «я записал на лентЫ».
К тому же, если следовать вашей логике, то записали на 1 бобину, а не на 32 — тогда указание количества лентопротяжек бессмысленно — у нас же одна лента только! Значит, «записали на ленту» означает только лишь тип носителя. Вы можете сказать «я записал архив на ленту», при том что сам архив состоит из 10 томов, следовательно, 10 лент. Просто никто не говорит «я записал на лентЫ».
Записали на одну ленту. Остальные пока пустые, и их можно использовать для работы программы. Возможно, авторы имели в виду что-то другое, но когда я читал подобную задачу у Кнута, то понял её так же (правда, там было «штук шесть» лентопротяжных устройств).
Возможно, остальные ленты пустые, возможно, запись полного набора производится на 2-3 ленты (записать на 1 ленту 3 млн пар фамилий нереально. В 80х по крайней мере). Ладно, замнем; просто задача допускает чуть разную трактовку. Так или иначе — есть ограниченная внешняя память. Хоть на 31 единицу, хоть на 15 — смысл задачи тот же.
1) я именно это и имел в виду.
3) Поправьте меня, если ошибаюсь, но разве здесь нужен алгоритм дейкстры? Ведь в данной задаче ребра без веса, а значит кратчайший путь — это путь с минимальным количеством ребер, и поэтому можно просто использовать поиск в ширину, нет?
Не будет, прогнал
Нет. Например, для N0=7 будет последовательность 7,22,11,34,17,52,26,13,40,20,10,5,16,4,2,1, т.е. N=15.
Угу. Это «числа-градины», про них 3n+1-гипотеза. Ещё вообще неизвестно, для всех ли чисел последовательность вырождается в цикл 4-2-1, если только её вдруг кто-нибудь уже не доказал. разумеется, во всех разумных олимпийских пределах там всё сходится — народ уже обсчитал в том числе и оооочень большие числа.
Вот интересно было бы почитать, как сложилась судьба каждого.
Как-то непонятно… В 1988-м я не участвовал, и на Союз не попал, но до областной олимпиады в 1989-м добрался, заняв там третье место. И:
>80 школьников из всех союзных республик 2 дня осваивали компьютеры
— Нас посадили за IBM с 3.5" дисководами с гибким(!) конвертом (как у 5.25") — я такие приводы больше никогда не видел и даже про такие не слышал :D До этого у меня был опыт работы только с БК-0010 и ДВК-2. У некоторых других участников — Yamaha MSX или даже ZX-Spectrum. Ничего, все участники разобрались с новой техникой в течении зачётного времени :) То есть нам показали, как запускать текстовый редактор и сказали, что интерпретируется программа GWBASIC'ом. Этого хватило, чтобы начать работать. И даже на то, чтобы разобраться, что умеет этот Бейсик времени тоже много не ушло :)
>Теоретический тур. Выполнялся письменно, без доступа к компьютеру.
У нас теоретический тур шёл в тот же день, что и практический (всего олимпиада занимала три, кажется, дня, но решали мы в один день — плюс по дню на заезд и подведение итогов). Просто задания делились на теоретические (алгоритмика) и практические (вычислительные).
…
Но, вообще, ключевым моментов жизни эта олимпиада не была. Ключевой была олимпиада по химии за два года (1987) до этого. На ней я впервые увидел компьютер (не терминал, а стойку, которая самостоятельно жужжала приводами, елозила приводом 8" дисковода с открытым корпусом и т.п.) и вот тут моя судьба круто переменилась. Хотя связывать себя с компьютерами я тогда и близко не планировал, но семена были зарождены и в 1990-м, когда я уже учился в химико-технологическом, проросли в компьютерную одержимость :D
>80 школьников из всех союзных республик 2 дня осваивали компьютеры
— Нас посадили за IBM с 3.5" дисководами с гибким(!) конвертом (как у 5.25") — я такие приводы больше никогда не видел и даже про такие не слышал :D До этого у меня был опыт работы только с БК-0010 и ДВК-2. У некоторых других участников — Yamaha MSX или даже ZX-Spectrum. Ничего, все участники разобрались с новой техникой в течении зачётного времени :) То есть нам показали, как запускать текстовый редактор и сказали, что интерпретируется программа GWBASIC'ом. Этого хватило, чтобы начать работать. И даже на то, чтобы разобраться, что умеет этот Бейсик времени тоже много не ушло :)
>Теоретический тур. Выполнялся письменно, без доступа к компьютеру.
У нас теоретический тур шёл в тот же день, что и практический (всего олимпиада занимала три, кажется, дня, но решали мы в один день — плюс по дню на заезд и подведение итогов). Просто задания делились на теоретические (алгоритмика) и практические (вычислительные).
…
Но, вообще, ключевым моментов жизни эта олимпиада не была. Ключевой была олимпиада по химии за два года (1987) до этого. На ней я впервые увидел компьютер (не терминал, а стойку, которая самостоятельно жужжала приводами, елозила приводом 8" дисковода с открытым корпусом и т.п.) и вот тут моя судьба круто переменилась. Хотя связывать себя с компьютерами я тогда и близко не планировал, но семена были зарождены и в 1990-м, когда я уже учился в химико-технологическом, проросли в компьютерную одержимость :D
К прискорбию в вычислительные методы в химии тогда верили плохо, максимум где использовалась вычислительная техника так это в написании научных трудов в ChiWriter-е да в первичной обработке входящих аналоговых данных со всяких массспектрометров, дериватографов и иных анализаторов, да и то только из прибора на плоттер. Аналитикой результатов тогда занимались вручную, графики в таблицы, таблицы сравнивались, подводились итоги. С физической химией в те годы я завязал.
Зато сейчас вычислительными методами кристалические структуры предсказывают, да и софт под любой анализатор индийскими специалистами накарябан.
Зато сейчас вычислительными методами кристалические структуры предсказывают, да и софт под любой анализатор индийскими специалистами накарябан.
>Зато сейчас вычислительными методами кристалические структуры предсказывают, да и софт под любой анализатор индийскими специалистами накарябан.
Ну так это ж вопрос не веры/не веры, а доступных вычислительных мощностей :) Как в начале 1990-х доступное мощное железо появилось, так сразу и начали использовать активно вычислительные методы не только для расчёта процессов и аппаратов, как ранее. У меня однокурсник как раз кристаллические структуры много рассчитывал именно где-то с середины 1990-х.
Ну так это ж вопрос не веры/не веры, а доступных вычислительных мощностей :) Как в начале 1990-х доступное мощное железо появилось, так сразу и начали использовать активно вычислительные методы не только для расчёта процессов и аппаратов, как ранее. У меня однокурсник как раз кристаллические структуры много рассчитывал именно где-то с середины 1990-х.
Ну может быть в институтах с мощными ИТ факультетами так и было.
Но я в 97 поступил в вуз и эту картину наблюдал. Ворд, автокад — потолок.
Более того, я был особенно ценен, благодаря владению автокадом.
Но я в 97 поступил в вуз и эту картину наблюдал. Ворд, автокад — потолок.
Более того, я был особенно ценен, благодаря владению автокадом.
>Ворд, автокад — потолок.
А, нет. Тогда у нас всё круче было :) Я думал речь именно о фундаментальных теоретических расчётах. Просто вычислительная практика в МХТИ к моему поступлению была мощная — там был отдельный факультет кибернетики химико-технологических производств (КХТП), открытый аж в 1960-м. Но это именно прикладной уровень, т.е. расчёты производств, автоматизация управления, численные методы для обработки данных и т.п. И на нашем, инженерном физико-химическом нас начали компьютерной практикой грузить с первого же курса в 1990-м. Всякая статистическая обработка экспериментальных данных, вычислительные методы моделирования и т.п. Хотя было видно, что внедряться всё это только начинает, колбасило с программой тогда сильно. Нас учили QBasic'у на PC XT, следующий за нами курс — Turbo Pascal (тоже PC). В 1994-м на расчётах всякого хим. оборудования окунулись в Фортран на СМ-4, хотя я на сдачу зачётов волюнтаристски приносил решения на C++ :D
Весёлое было время… Забавно, что у нас со всего потока (больше сотни человек) едва ли десяток-другой пошёл работать по специальности. А вот по компьютерной части — чуть ли не половина. Из семи близких друзей один работает по специальности, один не по специальности, но в отрасли (Росатом), один и не по специальности, и не с компьютерами, двое работают с 1С (один — бухгалтер, другой — программист), один — админ, один — админ+программист. Ну и я в Web'е сейчас задержался :)
А, нет. Тогда у нас всё круче было :) Я думал речь именно о фундаментальных теоретических расчётах. Просто вычислительная практика в МХТИ к моему поступлению была мощная — там был отдельный факультет кибернетики химико-технологических производств (КХТП), открытый аж в 1960-м. Но это именно прикладной уровень, т.е. расчёты производств, автоматизация управления, численные методы для обработки данных и т.п. И на нашем, инженерном физико-химическом нас начали компьютерной практикой грузить с первого же курса в 1990-м. Всякая статистическая обработка экспериментальных данных, вычислительные методы моделирования и т.п. Хотя было видно, что внедряться всё это только начинает, колбасило с программой тогда сильно. Нас учили QBasic'у на PC XT, следующий за нами курс — Turbo Pascal (тоже PC). В 1994-м на расчётах всякого хим. оборудования окунулись в Фортран на СМ-4, хотя я на сдачу зачётов волюнтаристски приносил решения на C++ :D
Весёлое было время… Забавно, что у нас со всего потока (больше сотни человек) едва ли десяток-другой пошёл работать по специальности. А вот по компьютерной части — чуть ли не половина. Из семи близких друзей один работает по специальности, один не по специальности, но в отрасли (Росатом), один и не по специальности, и не с компьютерами, двое работают с 1С (один — бухгалтер, другой — программист), один — админ, один — админ+программист. Ну и я в Web'е сейчас задержался :)
UFO just landed and posted this here
Фотографии такого качества как будто им лет 90, не меньше.
Интересно, сколько памяти давали в последней задаче. Если доступно 60 килобайт, и не пытаться вывести формулу, то у меня получилось посчитать до 140. При более аккуратном хранении промежуточных результатов можно было бы довести до 200, но там могло не хватить отведённого на написание времени.
таблицу, наверное, они подразумевали печатать (не запоминая) — на бумагу или на очень длинный экран.
Да, самое суровое ограничение — это время.
Возможно, тут может помочь (как минимум, самопроверке) вот такое наблюдение: искомое число совпадает с числом «выпуклых» путей на сетке к n-ой диагонали
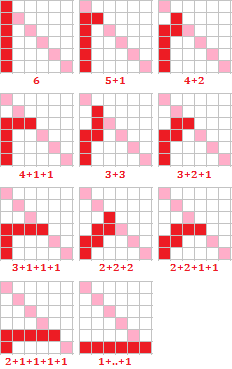
(«выпуклость» означает «на каждой следующей вертикали взято не больше, чем на предыдущей»), разрыв текущего блока означает переход на следующую вертикаль.
Да, самое суровое ограничение — это время.
Возможно, тут может помочь (как минимум, самопроверке) вот такое наблюдение: искомое число совпадает с числом «выпуклых» путей на сетке к n-ой диагонали

(«выпуклость» означает «на каждой следующей вертикали взято не больше, чем на предыдущей»), разрыв текущего блока означает переход на следующую вертикаль.
Аналогичная украинская олимпиада проходила 1987 году и мне там повезло занять 1ое место. До сих пор храню этот диплом как величайшую драгоценность :)
Увидел в списках призёров своего знакомого) Скинул ему ссылку, может отпишется!
Решения безнадежно утрачены? А то ничего не решил, но интересно же.
Немножко участвовал в городских-республиканских олимпиадах в 2000-2002. Задачи кажутся подозрительно похожими. :)
Вадим Завалишин действительно живет в Берлине и работает со звуком в NativeInstruments
Sign up to leave a comment.
Первая Всесоюзная олимпиада школьников по программированию (информатике) 1988 года