Comments 27
Пара контроллеров в наших краях влетает уже в четверть ляма.
Шасси, диски и прочее — еще поллляма.
Не спорю что ниша своя должна быть, но есть от тех же LSI сбагренная в NetApp Е-серия, которая стоит так же, и расширяется недорого и занимает меньше места.
Есть еще чисто софтовое решение из СПб под названием Raidix.
В общем вы предлагаете не платить мегадоллары HP/EMC/IBM — Ок. Но вы предлагаете занести столько же в LSI и еще основательно по@#$@#$тся с обеспечением например балансировки каналов, настройкой корректного отстрела узла в случае изоляции, попыткой засунуть тиринг туда где для него и крепежных мест то нет.
Тоже самое в режиме active-passive (что не снижает надежность решения) делается на двух обычных LSI SAS HBA и том же всем остальном (два сервака, двухэкспандерная полка с возможностью каскадирования). Работает так же, но дешевле. И цепляется к WSS 2012 за 10 минут, благо поддержка storage pool/ storage spaces — позволяет спокойно с этим работать в кластерном режиме, причем в этом случае возможно даже active/active.
Шасси, диски и прочее — еще поллляма.
Не спорю что ниша своя должна быть, но есть от тех же LSI сбагренная в NetApp Е-серия, которая стоит так же, и расширяется недорого и занимает меньше места.
Есть еще чисто софтовое решение из СПб под названием Raidix.
В общем вы предлагаете не платить мегадоллары HP/EMC/IBM — Ок. Но вы предлагаете занести столько же в LSI и еще основательно по@#$@#$тся с обеспечением например балансировки каналов, настройкой корректного отстрела узла в случае изоляции, попыткой засунуть тиринг туда где для него и крепежных мест то нет.
Тоже самое в режиме active-passive (что не снижает надежность решения) делается на двух обычных LSI SAS HBA и том же всем остальном (два сервака, двухэкспандерная полка с возможностью каскадирования). Работает так же, но дешевле. И цепляется к WSS 2012 за 10 минут, благо поддержка storage pool/ storage spaces — позволяет спокойно с этим работать в кластерном режиме, причем в этом случае возможно даже active/active.
Есть еще чисто софтовое решение из СПб под названием Raidix.
Слышал, но не трогал. И отзывов мало пока, в отличии от пиарящегося Нутаникса. Да и цена, опять же.
Не спорю что ниша своя должна быть, но есть от тех же LSI сбагренная в NetApp Е-серия, которая стоит так же, и расширяется недорого и занимает меньше места.
Да, нетапп это вариант, но он всё же дороже получается. Проблема брендовых СХД именно в цене на диски, а не сами коробки. Вот тут за 12х4Тб хотят 23k$, а вот сколько будут стоить SSD…
Плюс, у меня были ещё специфические требования вроде полнодискового шифрования на самом хранилище.
но вы предлагаете занести столько же в LSI и еще основательно по@#$@#$тся с обеспечением например балансировки каналов, настройкой корректного отстрела узла в случае изоляции
Ну, зачем @#$@#$тся-то? Эти вопросы давно решены в менеджерах кластера, в виде разных STONITH-хэндлеров. Да и изолировать ноду в данном случае практически нет необходимости.
Про балансировку каналов проблем не вижу, всё используется на полную.
попыткой засунуть тиринг туда где для него и крепежных мест то нет
Не понял о чём речь. О каком тиринге идёт речь?
Тоже самое в режиме active-passive (что не снижает надежность решения) делается на двух обычных LSI SAS HBA и том же всем остальном (два сервака, двухэкспандерная полка с возможностью каскадирования)
Насчёт надёжности решения как-то сомневаюсь — детектировать отключение второго хоста, дать приказ своему контроллеру импортировать Foreign конфигурации… Это может занять продолжительное время, я такой вариант не рассматривал даже. Да и экономия на Syncro в общем бюджете решения растворится.
И цепляется к WSS 2012 за 10 минут, благо поддержка storage pool/ storage spaces — позволяет спокойно с этим работать в кластерном режиме, причем в этом случае возможно даже active/active.
Винду не рассматривал, да и каким образом там будет active/active если железо не позволяет — не очень понимаю.
Ответы на вопросы:
1. Raidix умеет в cluster, unified storage и infiniband. В целом если Вам хочется платить своим людям за разработку своего решения и в результате его продавать еще комуто и внедрять или у Вас игра в импортозамещение, то я Вас понимаю. одно могу сказать: после тогоа как Вы это у себя внедрите — Вас еще долго не уволят :)
2. Вы хотите быстро и дешево? нетапп на самом деле лишнее берет за сущую мелочь. 20 часов разнорежимной работы диска на стенде, что исключает стартовый отказ диска после установки (как известно — бОльшая часть отказов любого оборудования происходит непосредственно после начала эксплуатации). Потоковое шифрование к сожалению изза бугра нам не продают. Даже адаптеки свои мегашифрующие хбашки не продают.
3. Sync работает в режиме active-passive (один массив в один момент обслуживается одним контроллером). Единственный плюс втыкания пары контроллеров за 10 штук баксов (за сайте ценник посмотрел, икском оказывается за копейки продает) это отзеркалированный на соседе кэш защищенный батарейкой.
4. Про тиринг: Tiered storage is the assignment of different categories of data to different types of storage media in order to reduce total storage cost.
5. Тут вы рассуждаете о том что решение должно быть быстрым и надежным. Я понимаю, курс рубля, санкции, шифрование, дорого, но напишите хотя бы в личку сколько и какой скорости вы хотите и для чего? А то ССД и 12 *4ТБ это непонятно. Обработка видео?
6. Скажу по чести. Чистого Active/active в жизни не видел. Весь А/А когда его начинаешь ковырять сразу же палится и выясняется что это А/Р но с очередной хитрой схемой обмана покупателя. Пока только очень близко лежат ONTAP Cluster mode и 3-PAR — мне не дают их подержать до полного раскрытия заговора :). Hitachi я правда не ковырял. Таже E-series меня вообще поразила коварством. Работа внешне выглядит как А/А, но по факту один контроллер просто замыкает запросы записи на owner'а, а тот уже транслирует запросы к дискам. Чтение честное А/А, а запись А/Р. Ну маркетинг и пишет что А/А. :)
О моей возне с этим: Меня в этом решении смущает то что оно полкозависимое. Прямого контакта у контроллеров друг с другом нет. SAS expander животное тупое (не все, но...), порты как встали в режим таргета, так и стоят, то есть контроллеры по SAS друг друга не видят, что непонятно — тут надо или кольцо замкнуть во втором контроллере, или сразу звезду строить на свитче (кстати гляньте в сторону LSI 6160). Изначально у них был план одну SAS четверку использовать для синхронизации кэшей контроллеров, но сейчас КЭШи несиннхронизированные получаются. А несинхренный кэш это потеря консистентности или отказ от кэша. В общем мне слишком уж костылисто показалось.
1. Raidix умеет в cluster, unified storage и infiniband. В целом если Вам хочется платить своим людям за разработку своего решения и в результате его продавать еще комуто и внедрять или у Вас игра в импортозамещение, то я Вас понимаю. одно могу сказать: после тогоа как Вы это у себя внедрите — Вас еще долго не уволят :)
2. Вы хотите быстро и дешево? нетапп на самом деле лишнее берет за сущую мелочь. 20 часов разнорежимной работы диска на стенде, что исключает стартовый отказ диска после установки (как известно — бОльшая часть отказов любого оборудования происходит непосредственно после начала эксплуатации). Потоковое шифрование к сожалению изза бугра нам не продают. Даже адаптеки свои мегашифрующие хбашки не продают.
3. Sync работает в режиме active-passive (один массив в один момент обслуживается одним контроллером). Единственный плюс втыкания пары контроллеров за 10 штук баксов (за сайте ценник посмотрел, икском оказывается за копейки продает) это отзеркалированный на соседе кэш защищенный батарейкой.
4. Про тиринг: Tiered storage is the assignment of different categories of data to different types of storage media in order to reduce total storage cost.
5. Тут вы рассуждаете о том что решение должно быть быстрым и надежным. Я понимаю, курс рубля, санкции, шифрование, дорого, но напишите хотя бы в личку сколько и какой скорости вы хотите и для чего? А то ССД и 12 *4ТБ это непонятно. Обработка видео?
6. Скажу по чести. Чистого Active/active в жизни не видел. Весь А/А когда его начинаешь ковырять сразу же палится и выясняется что это А/Р но с очередной хитрой схемой обмана покупателя. Пока только очень близко лежат ONTAP Cluster mode и 3-PAR — мне не дают их подержать до полного раскрытия заговора :). Hitachi я правда не ковырял. Таже E-series меня вообще поразила коварством. Работа внешне выглядит как А/А, но по факту один контроллер просто замыкает запросы записи на owner'а, а тот уже транслирует запросы к дискам. Чтение честное А/А, а запись А/Р. Ну маркетинг и пишет что А/А. :)
О моей возне с этим: Меня в этом решении смущает то что оно полкозависимое. Прямого контакта у контроллеров друг с другом нет. SAS expander животное тупое (не все, но...), порты как встали в режим таргета, так и стоят, то есть контроллеры по SAS друг друга не видят, что непонятно — тут надо или кольцо замкнуть во втором контроллере, или сразу звезду строить на свитче (кстати гляньте в сторону LSI 6160). Изначально у них был план одну SAS четверку использовать для синхронизации кэшей контроллеров, но сейчас КЭШи несиннхронизированные получаются. А несинхренный кэш это потеря консистентности или отказ от кэша. В общем мне слишком уж костылисто показалось.
>>«Прямого контакта у контроллеров друг с другом нет. SAS expander животное тупое (не все, но...), порты как встали в режим таргета, так и стоят, то есть контроллеры по SAS друг друга не видят»
Вот именно что видят и кэши синхронизируют по SAS. В обоих SAS-доменах присутствуют оба контроллера. Работает всё только в связке с экспандерами LSI.
Вот именно что видят и кэши синхронизируют по SAS. В обоих SAS-доменах присутствуют оба контроллера. Работает всё только в связке с экспандерами LSI.
5. Я не про 12х4Тб SSD, а про цены на SSD у них вообще
Разве это проблема? Полка — это, по сути, сдвоенный SAS-коммутатор со сдвоенными блоками питания. Всё зарезервировано. Отказов платы распределения питания (в которую втыкаются БП) или бэкплейна (куска текстолита куда подключаться два экспандера и диски) на моей памяти не было. Да и у всех двухконтроллерных хранилок брендовых (лоу-энд) те же проблемы, в общем, ибо та же архитектура.
Вы невнимательно читали статью, либо её вообще не читали.
1. Контроллеры друг друга видят как раз через SAS и только через него. Причём видят по двум независимым путям (при правильном подключении)
2. Кеши синхронизированы
О моей возне с этим: Меня в этом решении смущает то что оно полкозависимое
Разве это проблема? Полка — это, по сути, сдвоенный SAS-коммутатор со сдвоенными блоками питания. Всё зарезервировано. Отказов платы распределения питания (в которую втыкаются БП) или бэкплейна (куска текстолита куда подключаться два экспандера и диски) на моей памяти не было. Да и у всех двухконтроллерных хранилок брендовых (лоу-энд) те же проблемы, в общем, ибо та же архитектура.
то есть контроллеры по SAS друг друга не видят, что непонятно — тут надо или кольцо замкнуть во втором контроллере, или сразу звезду строить на свитче
одну SAS четверку использовать для синхронизации кэшей контроллеров, но сейчас КЭШи несиннхронизированные получаются
Вы невнимательно читали статью, либо её вообще не читали.
1. Контроллеры друг друга видят как раз через SAS и только через него. Причём видят по двум независимым путям (при правильном подключении)
2. Кеши синхронизированы
Я внимательно смотрел схему:
Для описанного вами функционала экспандер должен уметь держать порт в гибридном режиме target/initiator — иначе синхриться будут через метаданные на жестких дисках. Данные всегда идут от target к initiator. Отсюда и следствие — или звезда или кольцо. На схеме ни то ни другое. Порты в контроллере могут быть умными, но тупые экспандеры в полке запорют всю идею. Тот же х36.
Вы какой backplane в полке используете, с какими экспандерами??
Для работы:
1. Контроллеры должны друг друга видеть как раз через SAS и только через него. Причём видят по двум независимым путям (при правильном подключении)
2. Кеши должны быть синхронизированы
Но с такой схемой (как на картинке — ни кольцо — ни звезда) экспандер на полке может запороть всю малину (что у меня успешно получилось).
Сравните кстати с нетапповским крассическим SAS кольцом и прочувствуйте разницу (на АСР не смотрите):
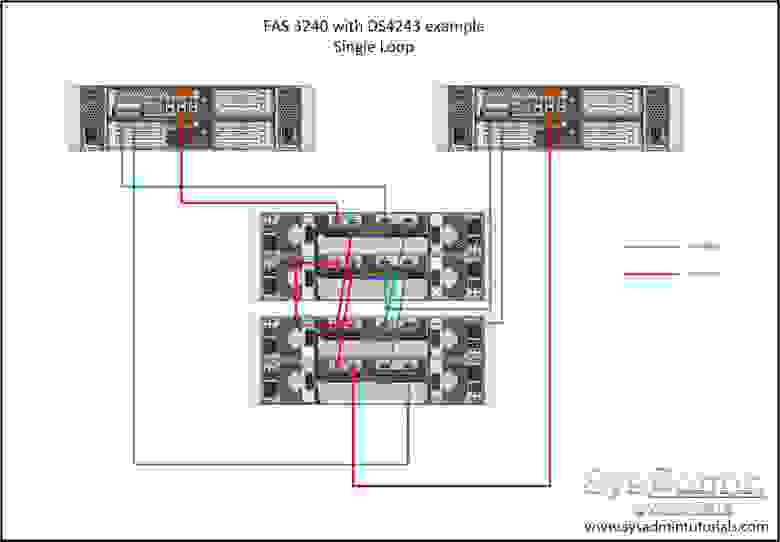
Здесь есть SAS соединение между контроллерами.
Для описанного вами функционала экспандер должен уметь держать порт в гибридном режиме target/initiator — иначе синхриться будут через метаданные на жестких дисках. Данные всегда идут от target к initiator. Отсюда и следствие — или звезда или кольцо. На схеме ни то ни другое. Порты в контроллере могут быть умными, но тупые экспандеры в полке запорют всю идею. Тот же х36.
Вы какой backplane в полке используете, с какими экспандерами??
Для работы:
1. Контроллеры должны друг друга видеть как раз через SAS и только через него. Причём видят по двум независимым путям (при правильном подключении)
2. Кеши должны быть синхронизированы
Но с такой схемой (как на картинке — ни кольцо — ни звезда) экспандер на полке может запороть всю малину (что у меня успешно получилось).
Сравните кстати с нетапповским крассическим SAS кольцом и прочувствуйте разницу (на АСР не смотрите):

Здесь есть SAS соединение между контроллерами.
Экспандеры в полке — 2 штуки SAS2X36 в каждом из 3 бэкплейнов, прошивка 55.14.18.0
А схема нетаппа, в принципе, аналогична первой схеме SAS из статьи, разницу особо не прочуствовал.
А схема нетаппа, в принципе, аналогична первой схеме SAS из статьи, разницу особо не прочуствовал.
Для аналогичности надо DE(В)E(B)1 переткнуть в DE(В)E(B)2 и соответственно с другой стороны. Но это требует межэкспандерного интерконнекта внутри полки.
В общем, не сочтите за комплимент, это Вы сделали и сделали для себя. В широких массах нет достаточного количестваквалифицированных специалистов для самостоятельного внеджрения таких решений.
В общем, не сочтите за комплимент, это Вы сделали и сделали для себя. В широких массах нет достаточного количестваквалифицированных специалистов для самостоятельного внеджрения таких решений.
Вы сделали и сделали для себя.
В широких массах нет достаточного количестваквалифицированных специалистов для самостоятельного внеджрения таких решений.
Ну так не для себя же (хотя и это, конечно, тоже — опыт никогда не помешает), туториал как раз и нужен для того, чтобы всё более широкие массы могли научиться делать что-то подобное.
UFO just landed and posted this here
Storage Spaces — это конечно хорошо, если обойти его слабые стороны (беда с записью на parity/dual parity пулы без SSD в качестве WB-кэша и быстрого яруса), но:
1) Автору нужен был FC таргет и/или (даже если бы устроил iSCSI) больше опыта с кластеризацией в Linux.
2) Откуда там Active-Active? Storage Spaces выступает в качестве основы для обычного MS Failover Cluster, а на нём iSCSI-таргет — ЕМНИП, вот так это выглядит.
3) Как Storage Spaces масштабируется на большое кол-во SSD? Есть ли у Вас опыт? Есть подозрение, что весьма неплохо, если не забывать про правильное кол-во столбцов, но просто не было возможности измерить.
1) Автору нужен был FC таргет и/или (даже если бы устроил iSCSI) больше опыта с кластеризацией в Linux.
2) Откуда там Active-Active? Storage Spaces выступает в качестве основы для обычного MS Failover Cluster, а на нём iSCSI-таргет — ЕМНИП, вот так это выглядит.
3) Как Storage Spaces масштабируется на большое кол-во SSD? Есть ли у Вас опыт? Есть подозрение, что весьма неплохо, если не забывать про правильное кол-во столбцов, но просто не было возможности измерить.
1) Пардон пропустил.
2) Я сам фанат SAS топологии ^_^/ Сейчас WSS весьма подрос над собой. Может на Storage Spaces изображать A/A c CIFS шарой (ну или iSCSI 3.0)
3) Надо брать задачу и под неё считать, тестировать и снова считать. С ССД на серверных платформах надо осторожнее — можно в ширину шины PCI упереться. У автора две фибры на ноду, даже если 8-ка (а не 16) это пиковая отдача в прыжке с табуретки — 8*4=32, учитывая что контроллер не напрямую в FC адаптер воткнут и там еще процессор и ОС периодически хотят с ними пообщаться, да и шифрование еще — как бы шина не лопнула. В хранилках как никак SAS чуть ли не сразу в порт выводят (благо у них система команд одна и таже — много переделывать не надо)
Я просто не могу понять для чего это. Да еще и с шифрованием на дисковом уровне.
2) Я сам фанат SAS топологии ^_^/ Сейчас WSS весьма подрос над собой. Может на Storage Spaces изображать A/A c CIFS шарой (ну или iSCSI 3.0)
3) Надо брать задачу и под неё считать, тестировать и снова считать. С ССД на серверных платформах надо осторожнее — можно в ширину шины PCI упереться. У автора две фибры на ноду, даже если 8-ка (а не 16) это пиковая отдача в прыжке с табуретки — 8*4=32, учитывая что контроллер не напрямую в FC адаптер воткнут и там еще процессор и ОС периодически хотят с ними пообщаться, да и шифрование еще — как бы шина не лопнула. В хранилках как никак SAS чуть ли не сразу в порт выводят (благо у них система команд одна и таже — много переделывать не надо)
Я просто не могу понять для чего это. Да еще и с шифрованием на дисковом уровне.
В хранилках как никак SAS чуть ли не сразу в порт выводят (благо у них система команд одна и таже — много переделывать не надо)
Там всё примерно так же, благо хранилки нынче построены на той же архитектуре (x86, low-voltage Xeon какой-нибудь). Так что путь данных от диска до порта внешнего там такой же: SAS контроллер -> память/CPU -> FC/SAS контроллер-таргет.
Я просто не могу понять для чего это. Да еще и с шифрованием на дисковом уровне
У меня конкретно эта система будет обслуживать в основном большой VDI на базе VMWare View.
Шифрование на IOPS влияет слабо, в отличии от последовательных операций.
У меня вопрос к автору сколько миллионов руб. бюджет расмотренного решения на дату 16.03.2015?
Сложно сказать. Я практически полный перечень компонентов написал — закиньте поставщикам. Но думаю на 1.5 можно умножать смело, как минимум.
я примерную сумму спрашиваю…
ясно что не для каждого это будет «бюджетным» )))
уже 48 данных SSD = минимум 2.5 млн.
Не обязательно же абсолютно все покупать, тем более, что существуют например схемы «лизинга»… и т.д.
ясно что не для каждого это будет «бюджетным» )))
уже 48 данных SSD = минимум 2.5 млн.
Не обязательно же абсолютно все покупать, тем более, что существуют например схемы «лизинга»… и т.д.
Ну, бюджетность тут в самом принципе построения хранилища и самый дорогой элемент, если экономить на остальном — сам Syncro.
В принципе, если брать диски SATA и дисков будет не очень много, то выгоднее строить на основе DRBD с двойным набором дисков.
Примерную — не знаю, я прикинул выше что на 1.5 умножить надо. SSD мне при закупке как раз обошлись примерно в 2.3млн, Syncro — 160т, остальное ещё сколько-то. В статье я указал 4млн стоимость, но в эту сумму, как я уже потом вспомнил, помимо коммутаторов вошёл UPS Symmetra с акксуссуарами ценой больше 400т.р., так что общая цена меньше 3.5млн.
В принципе, если брать диски SATA и дисков будет не очень много, то выгоднее строить на основе DRBD с двойным набором дисков.
Примерную — не знаю, я прикинул выше что на 1.5 умножить надо. SSD мне при закупке как раз обошлись примерно в 2.3млн, Syncro — 160т, остальное ещё сколько-то. В статье я указал 4млн стоимость, но в эту сумму, как я уже потом вспомнил, помимо коммутаторов вошёл UPS Symmetra с акксуссуарами ценой больше 400т.р., так что общая цена меньше 3.5млн.
Отличная статья по применению SyncroCS. Не каждый день можно встретить человека, умеющего правильно готовить SCST + Pacemaker. Несколько моментов:
1) В готовом коммерчески поддерживаемом виде такая связка реализована в Open-E (http://www.open-e.com/about-us/news/newsletters/product-information-open-e-dss-v7-with-avago-syncro-solution-users-en/)
2) >>«По причине отказоустойчивой натуры решения, LSI Syncro поддерживает только двухпортовые SAS диски.»
Не просто 2-портовые, а ещё и поддерживающие SCSI PR (т.е. не совсем древние). Я когда первый раз пробовал прототип Syncro CS, то со старыми 36ГБ Fujitsu ничего не завелось по этой причине.
3) >>«SC417E16-RJBOD1 — на 88 дисков, но там лишь одинарные экспандеры, что плохо скажется на надёжности, да и слотов расширения мало.»
Хм, я действительно не задумывался, будет ли Syncro работать через 1 экспандер. Официально вроде как нет?
Технически, думаю, возможно, просто теряем пропускную способность (входов не хватит, чтобы подключить оба порта с двух контроллеров и ещё каскадировать) и надёжность при каскадировании.
4) Я недавно считал стоимость нескольких бюджетных решений для СХД с тирингом. У меня получалось, что Infortrend 3024 обходится всего на 10% дороже Syncro CS. Обещанные 1,3 мегаиопса (с двух контроллеров) проверить не мог в своё время из-за отсутствия достаточного кол-ва SSD, но 200k получил, как и пропускную способность > 3ГБ/с. В качестве плюса помимо поддержки и всяких других фич получаем VAAI.
1) В готовом коммерчески поддерживаемом виде такая связка реализована в Open-E (http://www.open-e.com/about-us/news/newsletters/product-information-open-e-dss-v7-with-avago-syncro-solution-users-en/)
2) >>«По причине отказоустойчивой натуры решения, LSI Syncro поддерживает только двухпортовые SAS диски.»
Не просто 2-портовые, а ещё и поддерживающие SCSI PR (т.е. не совсем древние). Я когда первый раз пробовал прототип Syncro CS, то со старыми 36ГБ Fujitsu ничего не завелось по этой причине.
3) >>«SC417E16-RJBOD1 — на 88 дисков, но там лишь одинарные экспандеры, что плохо скажется на надёжности, да и слотов расширения мало.»
Хм, я действительно не задумывался, будет ли Syncro работать через 1 экспандер. Официально вроде как нет?
Технически, думаю, возможно, просто теряем пропускную способность (входов не хватит, чтобы подключить оба порта с двух контроллеров и ещё каскадировать) и надёжность при каскадировании.
4) Я недавно считал стоимость нескольких бюджетных решений для СХД с тирингом. У меня получалось, что Infortrend 3024 обходится всего на 10% дороже Syncro CS. Обещанные 1,3 мегаиопса (с двух контроллеров) проверить не мог в своё время из-за отсутствия достаточного кол-ва SSD, но 200k получил, как и пропускную способность > 3ГБ/с. В качестве плюса помимо поддержки и всяких других фич получаем VAAI.
Спасибо!
1) Да, интересно, они там ещё и ZFS прикрутили. Но почитав какие-то обзоры Нексенты и какие там бывают просадки скорости решил с ним не связываться до поры до времени.
2) Угу, я на это не указывал т.к. вряд-ли кто-то будет городить такую систему с дисками 5-7 летней давности :)
3) Работать будет, я подключал только 1 проводом каждый контроллер только к 1 экспандеру, но смысла в такой конфигурации не очень много
4) Да, наверное mid-tier вендоры уже могут тягаться с самосборными решениями, но у меня с ними опыта работы не было. Да и при сравнимой цене я лучше соберу что-то своё, где смогу найти проблемы если таковые будут, чем насиловать техподдержку, которая не всегда адекватна.
1) Да, интересно, они там ещё и ZFS прикрутили. Но почитав какие-то обзоры Нексенты и какие там бывают просадки скорости решил с ним не связываться до поры до времени.
2) Угу, я на это не указывал т.к. вряд-ли кто-то будет городить такую систему с дисками 5-7 летней давности :)
3) Работать будет, я подключал только 1 проводом каждый контроллер только к 1 экспандеру, но смысла в такой конфигурации не очень много
4) Да, наверное mid-tier вендоры уже могут тягаться с самосборными решениями, но у меня с ними опыта работы не было. Да и при сравнимой цене я лучше соберу что-то своё, где смогу найти проблемы если таковые будут, чем насиловать техподдержку, которая не всегда адекватна.
1) Не, на ZFS у них совсем другой, отдельный продукт — Jovian DSS. В обычном Open-E единственный плюс — простой web-интерфейс, те же самые 2-узла с drbd или Syncro CS там может поднять даже неподготовленный человек относительно быстро. А вот дальше начинаются проблемы, связанные с тем, что Linux там со всех сторон огорожен, ни логи нормально посмотреть, ни производительность помониторить (те графики, что есть — ни о чём). Еще, ЕМНИП, там проблема с PR'ами при переезде решена.
4) Это, как и Open-E на тот случай, если корпоративными стандартами не предусмотрен полный самосбор с самоподдержкой.
4) Это, как и Open-E на тот случай, если корпоративными стандартами не предусмотрен полный самосбор с самоподдержкой.
По поводу правильно готовить я тут уже написал: одно могу сказать: после того, как Вы это у себя внедрите — Вас еще долго не уволят
:)
Open-E уже сильно отстал. Его бы нексента давно вытеснила, но она стоит как крыло от самолета.
Четвертый пункт у вас получилось объяснить лучше чем у меня. Не только косноязычие у меня, но и косноклавиатурие видимо.
:)
Open-E уже сильно отстал. Его бы нексента давно вытеснила, но она стоит как крыло от самолета.
Четвертый пункт у вас получилось объяснить лучше чем у меня. Не только косноязычие у меня, но и косноклавиатурие видимо.
Положу в копилку… Много чего считать приходится по работе :). Особенно аналоги тяжелого оборудования. Попозже сделаю расчет твоей конфигурации.
Труд ваш достоин самой высокой оценки, но смущает вот этот момент:
То есть если один из хостов ESXi в случае ошибки пойдет по неоптимальному пути, при определенном стечении обстоятельств возможно разрушение данных?
То есть, если инициатор поставит блокировку на LUN через путь, ведущий на первый сервер, то через путь, ведущий на второй сервер, эта блокировка видна не будет. Для работы в режиме Round Robin это особенно важно, так как пути меняются постоянно и через какой путь будет установлена блокировка заранее неизвестно. В случае с VMWare ESXi это, в принципе, не проблема так как с версии VMFS5 не используются SCSI PR, а вместо них идёт в ход инструкция Atomic-Test-and-Set (которая, впрочем, тоже не реплицируется, но зато блокирует только нужную область на LUNе и на короткое время, а не весь LUN целиком), да и ALUA должен дать знать ESXi чтобы тот не использовал пути на второй сервер пока жив основной.
То есть если один из хостов ESXi в случае ошибки пойдет по неоптимальному пути, при определенном стечении обстоятельств возможно разрушение данных?
В каких-то очень редких случаях, думаю, что-то подобное возможно, но крайне маловероятно.
Да и SCSI PR используются только при операциях с метаданными (вкл-выкл ВМ, изменение конфигурации, снапшоты и т.п.) и если нет ATS.
Ну и шанс что один хост пойдёт по оптимальному пути, а другой — нет крайне мал. Для этого нужно будет что-то очень хорошо испортить.
Плюс, недавно вышел пре-релиз SCST 3.1, в котором уже добавлена поддержка репликации SCSI PR:
Да и SCSI PR используются только при операциях с метаданными (вкл-выкл ВМ, изменение конфигурации, снапшоты и т.п.) и если нет ATS.
Ну и шанс что один хост пойдёт по оптимальному пути, а другой — нет крайне мал. Для этого нужно будет что-то очень хорошо испортить.
Плюс, недавно вышел пре-релиз SCST 3.1, в котором уже добавлена поддержка репликации SCSI PR:
Highlights for this release:
— Cluster support for SCSI reservations. This feature is essential for initiator-side
clustering approaches based on persistent reservations, e.g. the quorum disk
implementation in Windows Clustering.
— Full support for VAAI or vStorage API for Array Integration: Extended Copy command
support has been added as well as performance of WRITE SAME and of Atomic Test & Set,
also known as COMPARE AND WRITE, has been improved.
— T10-PI support has been added.
— ALUA support has been improved: explicit ALUA (SET TARGET PORT GROUPS command) has
been added and DRBD compatibility has been improved.
— SCST events user space infrastructure has been added, so now SCST can notify a user
space agent about important internal and fabric events.
— QLogic target driver has been significantly improved.
Sign up to leave a comment.
Бюджетное SAN-хранилище на LSI Syncro, часть 1