Comments 20
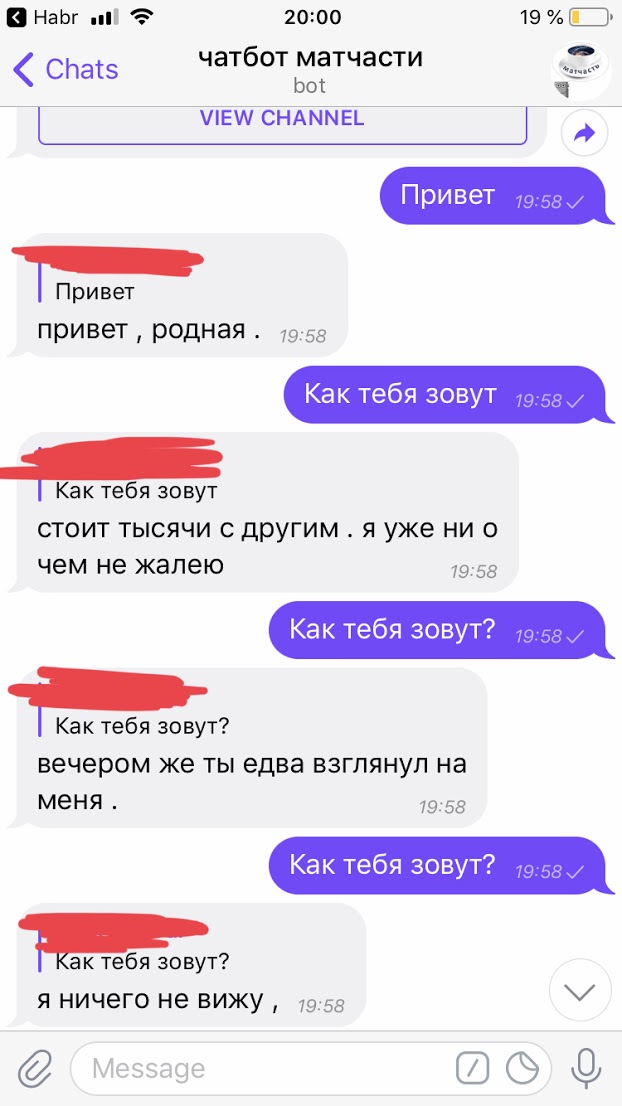
Спасибо, умеем треннировать попугая. Как писали на Хабре,
— алиса, включи чайник.
— Включаю режим чайника. Ой тут столько кнопочек, ничего не понимаю))
— алиса, включи чайник.
— Включаю режим чайника. Ой тут столько кнопочек, ничего не понимаю))
такое ощущение, что это перевод
Интересно, а насколько повышается точность ответов, если использовать оригинальную несжатую матрицу?
Идея хорошая, но ответы подбирает как-то слабо.
Нужно датасет побольше или уже нейросеть с Attention-механизмом, для понимания контекста.
Наш разговор:
Нужно датасет побольше или уже нейросеть с Attention-механизмом, для понимания контекста.
Наш разговор:

плюс в датасете может не быть подходящего чёткого контекста к словам. Люди всякую чушь пишут, понимая контекст — попробуй докопаться
Да можно и без атеншна, CNN с двумя башнями (для контекста и для ответа) уже сильно лучше работает. Но интересно было, чего можно получить без нейронок и вообще без супервижна.
Дело вообще не в архитектуре а то что для понимания слов контекста тоже нужен контекст.
Я сейчас забавляюсь такой бредовой вещью каккибернетическая обьектная модель понятий. Начал для того чтобы генерировать текст с заданным смысловым значением и учить по этому нейронку, в отсутствие нормальных датасетов с покрытием всех слов. Но потом нетрудно увидеть что метод который генерирует текст со связанным смысловым значением фактически «понимает» его и можно использовать наоборот для парсинга из текста в модель. Может когда то даже выложить на Habre, шас в очень неготовом состоянии, это ж хобби проэкт…
Но интересно было, чего можно получить без нейронок и вообще без супервижна.
Я сейчас забавляюсь такой бредовой вещью как
Судя по Вашим примерам, работает подход из рук вон плохо.
Выполнил до конца на своей машине, однако внезапно завалился на взаимодействии с телеграмом. Бота-то я создал, но вот подсоединитьсяк нему не сумел. Это случаем не потому, что код был написан в исходной статье год назад, до блокировки телеграма?
Да, всё верно. Нужно соединяться из-под VPN. Спасибо за замечание, сейчас дополню.
Или, кстати, можно в гугл колабе запускать бота (в режиме polling, как и на локальном компе). Кажется, это самый дешёвый вариант. Вот минимальный пример.
Большое спасибо за статью!
Есть ли возможность найти оптимальное сочетание размерность/информация об исходной матрице? Или можно подбирать только руками?
Есть ли возможность найти оптимальное сочетание размерность/информация об исходной матрице? Или можно подбирать только руками?
Я знаю, что есть учёные, которые работают над поиском формулы оптимальной размерности, но, кажется, серебряной пули пока не придумали. Так что, наверное, перебор.
Подбирать, имея принцип что чем сложнее инфа на входе тем больше надо будет слоёв и толщины. У меня есть предположение что примерно прикинуть можно через энкодер. Сделать энкодер-декодер одного ввода, выявить оптимальное узкое горлышко и брать размер этого горлышка умноженный на среднюю длинну секвенции.
Например, применим это к char rnn. Один символ сжимается в энкодере примерно до 10 значений в узком горлышке, до 5 пытался треннировать но плохо, начинает сильно врать. Имея среднюю длинну предложения в 50 символов будет ~ 500 нейронов в скрытом RNN слое, правда одинарной толщины.
Например, применим это к char rnn. Один символ сжимается в энкодере примерно до 10 значений в узком горлышке, до 5 пытался треннировать но плохо, начинает сильно врать. Имея среднюю длинну предложения в 50 символов будет ~ 500 нейронов в скрытом RNN слое, правда одинарной толщины.
У кого кривые ручки, тем такое не создать. А можно бы было отличного бота замутить, чтоб без геморочного программирования доступно было добавление фраз.
ого
Вот что думаю. Сама задача интересная, а телеграм бот как привлекающий маневр.
Датасет побольше бы, тогда однозначно лучше будет
Sign up to leave a comment.
Создание простого разговорного чатбота в python