Comments 74
В основном одно и то же. Но есть мелкие удобства в DataGrip, которых нет в DataBase plugin.
С тех пор сижу на PL\SQL Developer, и горя не знаю.
А вот как у IntelliJIdea обстоят дела с сессиями? В TOAD, няп, один экземпляр программы = 1 оракловая сессия, и пока там выполняется запрос, ты ничего не можешь делать. В PL\SQL Developer — одна вкладка с текстом = 1 сессия.
Тогда получается, что кому больше приглянулось, скажем визуально, тот то и выберет?(помимо важного критерия — запуска PL/SQL только на windows)
Тогда получается, что кому больше приглянулось, скажем визуально, тот то и выберет?Ну в общем да, если брать только список доступных функций, то отличия не сказать что очень большие, разница больше касается того, как все выглядит и насколько удобно пользоваться, а это довольно индивидуальные вещи.
Попробуйте еще dbForge Studio for Oracle для сравнения.
Сама по себе IDE очень приятная.
Сейчас в результате остановился на DataGrip, он довольно сносен и недорог (в тексте неполный/неправильный (смайл) ценник, для пользователя в РФ никаких не 199 евро, а вполне себе $89/71/53 за 1/2/3-й год, если покупать для себя).
A IDEA только вчера ставил в виртуалку. Реакция по секунде на некоторые! клики бесит (проверил сейчас — по клику на коде — 1.5с — но это с плагинами, буду разбираться). И 1Гб рабочего набора памяти для хелловорлда (
С 2009 до 2013 года работал исключительно в TOAD. Oracle SQL Developer сильно подтянулся к 2015-2017 году. Поправили много мелких багов, интегрировали все тулы, например, моделирование, версионирование и др.
При написании кода вставляю все атрибуты исследуемого объекта и вокруг них пишу код. Получается эффективнее, чем нервничать из-за непоявляющихся окошек.
Время появление окошка автодополнения по ctrl+пробел можно настроить.
Если в настройках отключить неиспользуемые модули, например миграция, дампы и т.п., выбрать тему ОС, то инструмент работает сильно быстрее и окошки появляются активнее.
К отладке пакетов нужно приловчиться, всё ещё остаются некоторые моменты.
Однако, наличие модулей моделирования, планировщика, экспорта и пр. считаю сильным преимуществом, т.к. экономится много времени. Много работаю с данными, вставить из экселя, импортировать/экспортировать, файл закачать в blob — это одна из причин окончательного перехода к Oracle SQL Developer.
Версионирование csv и git есть встроенное, одно время использовал, но самому через файловый менеджер как-то надёжнее получается.
Остаётся момент с сессиями. Бывает, долго выполняется запрос или подвис, то подвисает весь Oracle SQL Developer, а там, например, код остался, модель и джоб запущенный. Помогает оставить в покое в таком состоянии, редко даже день-два. Открыть второе окно, спровоцировать ошибку в выполняемом коде или просто другую работу делать и в 99% всё возвращается. Но это не серьёзно для такого тула.
Это не проблема sql developer, это проблема Oracle JDBC Thin Driver. Он не умеет cancel запросов до того как он верну хотя бы одну запись. Как лечить: поставить Oracle сlient и использовать thick JDBC драйвер/OCI. После настройки — запросы прерываются в любой момент, ничего не подвисает.
Как настроить можно почитать например здесь: https://www.thatjeffsmith.com/archive/2019/04/sql-developer-19-1-connections-thick-or-thin/
Драйвер поддерживает несколько режимов отмены запроса. Самый продвинутый (out of band breaking) — через TCP-пакет с флагом urgent. Как только БД получает его, она прерывает запрос. Проблема в том, что некоторые активные участники сети любят сбрасывать этот флаг у пакета, в итоге отмена не срабатывает. В нашем компании именно так обстоит дело: что-то сбрасывает этот флаг. Проблема довольно популярная, по-моему в оракле версии 18 при установке соединения драйвер и база проверяют, нормально ли проходят urgent-пакеты. Если нет, то откатывается на старый режим работы, при котором запросы работают чуть медленнее, но при этом отмена работает стабильно. Запросы действительно работают медленее, мы гоняли тесты в разных комбинациях, и запрос из таблицы с сортировкой без индекса работал на 10% быстрее в случае thin. Где-то я читал, что это связано с необходимостью дополнительных опросов в БД, но подтверждений этому я не нашел, хотя на правду похоже.
Если драйвер начал использовать out of band breaking, а пакеты urgent режутся, то отмена произойдет в тот момент, когда БД отправит первый пакет клиенту, и у клиента появится возможность отправить серверу информацию о том, что уже хватит (как раз потому у вас происходила отмена после первой строки).
У thin можно принудительно включить такой же режим работы как и у thick, это делается через свойство oracle.net.disableOob. Выставьте его в true и проверьте, отмена может начать работать.
В TOAD есть возможность указывать для bind-переменных типы и направление(in, out, in out).
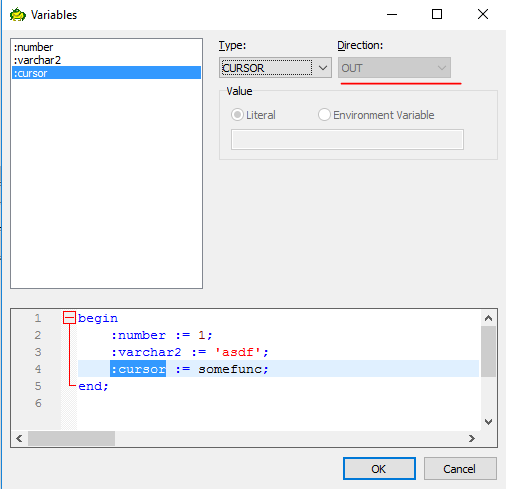
Очень удобно для каждого типа такие настройки выставить, например.
Как это сделать в IDEA? Оно не умеет ни в направление, ни в тип. Или я не правильно делаю?

Еще в TOAD можно открыть, например, код процедуры/функции/чегоугодно прямо из редактора. Выделяешь нужный элемент, жмешь F4. Это так же полезно если знаешь как называется нужный элемент, например функция myfunc, пишешь её в редакторе, жмешь F4, открывается её код. В IDEA такого нет или я не нашел? Остается только возможность искать в дереве объектов.
Ctrl + Alt + G (откроется в отдельном табе)
Если держать Ctrl + клик на функции/объекте, то откроется в дереве объектов
(Это в DataGrip. IDEA по-моему всё-таки для Java, а работа с бд там немного сбоку приделана).
2. Есть несколько способов. Самый простой, нажимать на объекте в коде Ctrl+Q, откроется попап с важной информацией, в том числе DDL.
Если DDL надо поправить, нажимайте Ctrl+Клик или Ctrl+B — откроется редактор исходника.
А если надо сгенерировать DDL с разными опциями, например, для миграции — тогда уже используйте полноценный генератор Ctrl+Alt+G.
Подозреваю, что ваш случай первый.
Как вы вообще живёте с этими модалками? При разработке типична ситуация, когда надо один и тот же код запускать множество раз, периодически меняя параметры. По сравнению test window в pl/sql developer-е с этими подарками тупо неудобно.
При этом, в jetbrains о недостатке такого варианта знают, но не считают фичу реализации аналога test window приоритетной. Учитывая то, что у idea фиксированный keymapping, к которому еще нужно привыкнуть (лично меня, например, как адепта эклипса, бесит дублирование строки по ^D), переходить на неё с pl/sql developer'а не особо хочется (хотя я в последнее время больше с postgresql работаю и там вопрос проблема удобной ide стоит более остро).
И про dbeaver ещё забыли.
Тоже лет 5 как перешел на Sql Developer.
Проблему зависания как решать описал выше.
К плюсам могу отнести:
- отличная работа с планами запросов (можно например сравнить планы и увидеть чем отличаются, различия выделяются красным)
- аналог set autotrace on также с возможностью сравнения статистки разных версий запросов
- встроенные data modeler (ER диаграммы, генерация Oracle кода для конкртеной версии, реверс инжениринг)
- куча утилит по экспорту импорту, захвату DDL и прочее
- нормальный монитор сессий
- sql monitor (мониторинг запроса в стадии выполнения)
- отличный отладчик
- наличие плагина для unwrap
- интеграция с git (нужна не для коммитов, а что бы посмотреть различия от предыдущих версий)
Отдельными фишками выделю не профильные для разработчика вещи:
- нормальный DBA раздел с мониторингом а ля Quest Software, AWR и ASH
- встроенный мини репортинг модуль, можно сделать простенькие отчеты и использовать их для типовых запросов
1. Цена 199 долларов — для компаний. Не знаю, это ли вы имели в виду, но иногда случается, что люди не замечают, что цена за первый год, если вы покупаете IDE себе — 89 долларов.
2. Автодополнение. Это та область поддержки кода, которой мы очень гордимся, поэтому было бы круто, если бы вы показали нам случай, когда DataGrip не дополняет то, что вы хотели. Кстати. По Ctrl+Space окно автодополнение покажется и у нас :)
3. Про специальный режим отображения результатов селектов, когда поля идут в столбик, а в соседнем столбике одна строка данных – это есть, на редакторе данных нажмите шестеренку и далее Transpose. Еще ознакомиться с полями поможет список полей по Ctrl (Cmd)+F12.
4. Про таймстемпы в Output — если это мешает, создайте пожалуйста реквест у нас в трекере. youtrack.jetbrains.com/issues/DBE
5. Дерево объектов: поиск у нас есть, просто начните печатать. Фильтрация тоже: если по имени, напишите шаблон в свойствах источника данных. Если по типу, кликните вороночку на тулбаре. Вообще, поиск объектов есть откуда угодно: в IDEA можно вызывать Go To Symbol (Shift+Ctrl+Alt+N или Alt+Cmd+O) и написать там название таблицы. В DataGrip вместо go to class есть go to object (Ctrl+N или Cmd+O).
6. Вообще, вы написали, что проводник у нас не очень, но не описали почему конкретно. Мы были бы рады, если бы вы рассказали, что неудобно.
7. Куда слать пиво?
2. Да, проверил еще раз, всё работает. Просто довольно долгое время пользовался Oracle SQL Developer, где эта функция не работала, и отвык. Видимо, даже не попробовал. А вот подсказка по аргументам функций как у PL/SQL Developer есть? Я только не помню, где я видел это — то ли в PL/SQL Developer, то ли вообще в Lazarus. Там была, помнится, совершенно очаровательная вещь: когда пишешь вызов функции и курсор стоит внутри скобок, ниже отображается окно с подсказками, в котором есть список названий аргументов и их типов, и вдобавок жирным выделен агрумент, на котором курсор стоит сейчас. Если у вас такого нет, напишу реквест. Пока же все IDE прячут подсказки, когда имя функции уже написано, и курсор стоит в скобках.
3. Попробовал. Выглядит круто, спасибо, то что надо.
4. Практически не мешает с тех пор, как я обнаружил, что можно выделять текст мышкой, удерживая Alt. Ну может и напишу.
5. Спасибо, надо попробовать.
6. Ох, ну и запросы у вас ;) Это материал на целую статью. Кроме того, тут в комментариях уже много написано всяких советов, нужно их сначала переварить. Из того, что сразу приходит в голову, хотелось бы видеть в списках объектов внутри схемы ДБ линки (вчера как раз искал их и не нашел), публичные синонимы, индексы и триггеры.
7. Это был шуточный намек на то, что статья — моя частная инициатива, никак не связанная с JetBrains (уж не знаю, насколько удачный). Живу я от вас далековато (в одной маленькой, но гордой западноевропейской стране), но если будете у нас на колыме — милости просим, пиво тут хорошее.
6. Вроде все есть, кроме ДБ Линков (про них тут youtrack.jetbrains.com/issue/DBE-4588). Индексы и триггеры в нодах соотвествующих таблиц.
7. Ну вы напишите в личку где вы, заглянем при случае :)
6. Да, посмотрел, действительно есть. Не понравилось, что там идет всё вперемешку. Столбцы, констрейнты, индексы, у разных типов вдобавок разные иконки, всё сливается. Может, лучше сделать подкатегории? Столбцы показывать сразу, как только кликаешь на треугольник у имени таблицы, а индексы, констрейнты и прочее показывать отдельными подкатегориями, свернутыми по умолчанию?
7. Отправил.
От себя:
8. Визуальный редактор таблиц слишком примитивный, чтобы им пользоваться по-взрослому. Нет триггеров, нет чеков, нет грантов.
9. Аналогично и с объектами — через интерфейс особо ничего и не сделаешь, всё ручками.
10. Огромные тупняки на больших схемах. Полная синхронизация занимает с десяток минут, а by lazy не предусмотрено (либо запрятано глубоко в настройках и мы её не нашли). В итоге хочешь обновить данные после добавления поля в таблицу, и получаешь полумертвую IDE на 5-10 минут (и хорошо, если схему SYS еще не присоединил для линковки).
11. Нет вменяемого средства ручного запуска процедуры/функции. Просто поглядите в PL/SQL Dev в окно «Test» и сделайте так же — стационарное окошко с возможностью подставлять аргументы и прочитать курсор в обычное окно результата. Вам очень многие спасибо скажут. Пока это одна из двух штук, из-за которых мне приходится держать открытым старую тормозную прогу — у нас половина кода проекта в процедурах БД.
Резюмируя — просто попользуйтесь PL/SQL Dev чуть более, чем на домашний проект с парой таблиц — и будет заметно, чего не хватает в Идее/Грипе.
6. Либо я не разобрался, либо ваш модуль не поддерживает синонимы на соседние схемы, даже в пределах одного физического инстанса. В редакторе — краснота сплошная.У нас тоже все на синонимах, но все распознается. У меня тоже была проблема с тем, что все было красное, когда открывал *.sql файлы с диска. Эта проблема решается примерно так: нужно поставить курсор на любое красное слово, слева появится (может не сразу, а через секунду) кнопочка, на которую нужно ткнуть, появится меню, там нужно выбрать «Attach session». После этого в правом верхнем углу редактора кода появится выбор схем. Выберите нужную схему, должно заработать.
10. Огромные тупняки на больших схемах.Да, такое есть, и раздражает, кажется, вообще всех. Я уже месяц собираюсь написать реквест. Может, сегодня напишу.
Резюмируя — просто попользуйтесь PL/SQL Dev чуть более, чем на домашний проект с парой таблиц — и будет заметно, чего не хватает в Идее/Грипе.В этом самая большая сложность разработки специализированного ПО. Очень тяжело высасывать из пальца задачу, приближенную к боевой, а потом смотреть, чего не хватает. Проще собирать фидбек от пользователей.
Live Template — в PL/SQL Developer, и переменные можно в шаблоны вставлять, и курсор размещать в заданной позиции (через [#]), посмотрите документацию
Refactoring — в PL/SQL Developer работает именно так, как вы описали, переименовывает правильно имена объектов и переменных
Code Inspection — про расширяемость не в курсе, но в PL/SQL Developer все эти ворнинги при компиляции есть, и неиспользуемые переменные и многое другое
Запуск скриптов — PL/SQL Developer умеет прямо из IDE запускать SQLPlus с кредами текущего соединения к базе, очень удобно для запуска скриптов. Про подсветку синтаксиса для скриптов ничего не знаю, скорее всего её нет.
Usability — интерфейс PL/SQL Developer очень отзывчивый и не жрёт память, тёмной темы нет, это да…
Для тех, кому интересно рекомендую 2 статьи по детальной настройке PL/SQL Developer под себя:
www.williamrobertson.net/documents/plsqldeveloper-setup-1.html
www.williamrobertson.net/documents/plsqldeveloper-setup-2.html
Чтобы совсем никто не мешал — надо каждому разработчику делать свою изолированную базу.
У нас есть один сервер для разработки, один для тестирования, один — копия продакшена и последний — собственно продакшен. На копии прода мы тестируем установку. Если там она пройдет, значит и на настоящем проде пройдет. А на девелоперской среде проблема мешания друг другу решена с помощью синонимов. Есть одна схема с таблицами, и есть схемы для разработки, где вместо таблиц — синонимы, которые ссылаются на основную схему. Можно держать параллельно несколько схем для разработки с разными версиями пакетов и править их назависимо друг от друга.
Вот несколько лет назад я работал в одном проекте, где все было на одном инстансе. Одна схема — прод, одна — дев. И крутись как хочешь. Вот там да, было весело. Я уж думал у вас что-то вроде такого.
У нас есть один сервер для разработки, один для тестирования, один — копия продакшена и последний — собственно продакшен.
Все абсолютно так,
Только последнее время удалось каждому разработчику выделить изолированную базу GIT+DelphiX. То есть разработчик скачивает код с репозитория GIT, дописывает его и тестирует на своей изолированной базе. По желанию разработчик может стереть свою базу и закачать снимок боевого сервера. Потом через GIT отправляет на процедуру слияния с боевым сервером. Этот код пропускают через тест и раз в неделю делают слепок для выкатывания на прод. Финальный слепок тоже тестируют некоторое время перед выкладкой. Плановая процедура выкладки занимает 2 недели. Но стабильность работы очень высокая. Через GIT видны абсолютно все правки каждой строчки, виден автор и по какой задаче работал.

Теперь хочу бросить маленький камушек в сторону DataGrip. Среда отличная, конечно же, и я использовал в редких случаях её немного урезанную версию в составе IntelliJ IDEA Ultimate. Но именно для работы с Oracle она мне в своё время не подошла по двум причинам.
PL/SQL Developer, в свою очередь, достает метаданные из БД (и кеширует их) по запросу, в первый момент обращения к объекту, так что ждать ничего не нужно.
2. Про java пакеты я даже тикета не нашел. А что значит не поддерживается? Исходник не достается?
3. А что вам сейчас, на постгресе мешает использовать Idea/DataGrip? Тормозов в интроспекции нет, а мы явно помощее :)
Как я написал выше, «Возможно, эту фичу уже завезли, тогда прошу прощения». Давно не работал с этим функционалом.
Далее по пункту 3.
Честно говоря, как-то все чересчур запутанно, непрозрачно. Концепция выбора активных data source/database/schema для консоли просто убивает.
У меня много PostgreSQL баз, в каждой из них несколько десятков схем, доступные разным ролям. Есть схемы с только с хранимыми процедурами (для эмуляции пакетов Oracle). Я обычно имею открытыми около 10 окон с кодом для разных бизнес-областей (например, для разных микросервисов или их кусков). Все окна имеют отдельные коннекты и разные настройки (авто-коммит, уровень изоляции и т.п.). Я постоянно переключаюсь между несколькими кластерами/базами с похожими схемами (но всё-же они отличаются).
1) Когда я переключаюсь на новую БД, я делаю это глобально. Это означает что я хочу чтобы все окна сразу закрыли коннект, и после этого, когда я отправляю первый запрос в любом окне, то это окно открывает новый коннект с текущей выбранной БД.
Да, вы поддерживаете возможность подключения к нескольким БД параллельно, но из моего опыта — это является источником граблей. Я и сам наступал, и много раз видел как другие по ошибке изменяют не ту БД, с которой, как им кажется, в данный момент работают. Цветные метки помогают, конечно, но не сильно.
2) Я не хочу кликать мышкой десятки схем только для того, чтоб заработало авто-дополнение. Если же я отмечаю только «Current schema», то авто-дополнение не будет работать для других схем, даже если всегда указывать имя схемы. И как установить эту текущую схему, не кликая мышкой? Кажется, никак. Это, наверное, самый неприятный момент. С другой стороны, мне совсем не нужны все схемы, особенно системные, поэтому вариант «All schemas» меня не устраивает. Слишком много лишней информации.
3) Если я выполню запрос «set role xxx», я хочу чтоб для текущей сессии автодополнение работало для всего, что доступно этой роли. До тех пор пока я не переключился на другую (set role yyy).
Я пишу «select * from xxx.» и теперь при нажатии на Ctrl+Space я хочу видеть доступные мне объекты схемы xxx и только. А если я не указал схему явно, что ж, для этого есть search_path (по умолчанию search_path = '"$user", public').
Даже если я знаю имя таблицы, все равно автодополнение не работает! Пример: «select * from xxx.yyy as t where t.» -> «ctrl+space» -> вываливается огромный список встроенных функций. В конце списка присутствуют некоторые системные поля типа ctid, а больше ничего! В общем, интроспекция просто не работает. Не могу же я каждый раз лазить по интерфейсу, менять настройки схем, потом нажимать refresh и ждать.
Нет времени больше писать, но есть и другие претензии. Поэтому из GUI тулзов я остаюсь на «SQL Workbench/J» как на наиболее адекватной из всех сред под Linux, что я пробовал. Там все работает ровно так, как это ожидается, без сюрпризов.
Ну и конечно, без консольных клиентов никуда, у меня всегда открыто несколько терминальных окон к разным БД (для Postgres это psql, pgcli). Они работают намного быстрей любых GUI сред, особенно что касается показа метаданных объектов и автодополнения кода.
Кроме того, предзагрузка метаданных по определению не может учитывать доступность объектов для разных ролей. Если в одном окне роль X даёт грант на объект роли Y, то в другом окне (сессии) для роли Y должно заработать автодополнение. И это работает во многих GUI.
Таким образом, для подобных моему сценариев использования было бы неплохо иметь возможность переключаться в режим real-time интроспекции, с возможностью быстрого сброса кэша по хоткею.
1. Ваши чаяния понятны, но переключение базы во всех вкладках сразу уж очень противоречит тому, как устроена у нас работа. Уверен, что сделай мы такое, мы получим много фидбека :)
В вашем случае, если цветовые метки не помогают и режим read-only для источника тоже не то, что нужно, я бы посоветовал использовать под каждую базу своей проект. Захотели переключить базу? Открываете нужный проект.
2. Установить текущую сехму, не кликая мышкой можно вызвав действие Switch schema. У меня лично на него замаплен шорткат Cmd+Up.
3. Real-time автодополнения у нас действительно нет. И я не думаю, что оно появится в ближайшем будущем. То есть, если объекта нет в дереве — его нет в автодополнении. Это базовая вещь для нас :) Исключение составляют системные объекты, о которых мы можем знать заранее.
Может быть вам поможет небольшой финт: если имена объектов засунуть в соседний текстовый файл, то будет работать дополнение по словам: Alt+/
У нас даже тикета нет на real-time completion, никто не просил. В целом, думаю, это будет очень медленно, а наша фишка как раз в том, что дополнение почти мгновенное.
Просто пара тонкостей по памяти, которых не было в других инструментах:
— В настройки подсветки синтаксиса можно внести свои слова. Для этого обычно выбирал из all_objects имена объектов, дополнял именами имеющихся колонок из all_tab_columns, вставлял список туда, а в настройках подсветки ставил особый цвет.
— Очень полезна работа с записанными текстовыми макросами. Тупо пример — на какой-нибудь «Alt+S» назначить вывод «select * from ». Или на что-нибудь типа «Alt+D» выводить «to_date('','dd.mm.yyyy') и курсор поставить в первые апострофы. Особенно часто нужно второе. Для тех, кому совесть не позволяет написать „where start_date > '01.01.2001'“
Но были и весёлые приколы. Если у объекта (таблицы) в браузере раскрыть „Granted to“, то там можно на пользователе по ПКМ найти пункт „Delete“. Который (тадам!!) удаляет пользователя. И хорошо. если это была не схема с объектамми.
А чел. хотел просто отнять у него грант :)
—
есть еще timestamp'2001-01-01 00:00:00' или TIMESTAMP '1997-01-31 09:26:56.666 +02:00'
С выходом IDEA 2017 начал пользоваться её БД-модулем. Да, это по прежнему Идея, с её огроменной юзательностью. Но вот PL/SQL Dev всё еще приходится использовать.
1. Объекты. С ними всё плохо, в интерфейсе ты можешь, по сути, только посмотреть и дропнуть. Создавать проще в консоли.
2. Редактор таблиц. Основные правки можно делать и в редакторе. Но такие правки с легкостью делаются и в консоли. А то, что в консоли делается сложнее — в интерфейсе недоступно. Гранты не посмотреть, чеки не изменить, с триггерами тоже не всё так однозначно.
3. Самая большая проблема, от которой вешаемся всем отделом. Синхронизация. У нас в БД порядка 300+ таблиц, и 150+ пакетов. Не говоря уже об объектах, функциях/процедурах без пакета, и прочей шелухи. И вот когда ты хочешь обновиться — тебе приходится обновлять ВСЁ. Занимает это больше 5 минут — я успеваю надеть куртку, спуститься с 4го этажа и пройти пол сотни метров к месту перекура, покурить, вернуться, налить кофе. Только тогда оно гарантированно уже обновится. Парни из ДжетБреинс, можете что-то с этим сделать? Тот же PL/SQL Dev делает это всё раздельно, и на порядки быстрее.
4. DB-link и синонимы. Всё просто — их поддержки нет. В редакторе гиперемия.
В итоге я пользуюсь в Идее только консолью. Иногда диспетчером объектов. Но пользуюсь, ибо проще и удобнее остального софта.
PS: Автор, а ты забыл еще и про автоформатирование стиля кода — это половина юзабельности Идеи.
PPS: После написания комментария пошел прогать, и вспомнил, чего мне еще не хватает — тестирования функций. Нельзя просто так взять и вычитать курсор из функции в интерфейс Идеи.
Автор, а ты забыл еще и про автоформатирование стиля кода — это половина юзабельности Идеи.Вообще-то нет, не забыл. Но про это у меня всего одно предложение:
Настройки форматирования SQL и PL/SQL тоже есть у всех, более-менее одинаковые по мощности, и превью тоже есть.Настройки форматирования у IDEA очень мощные, но прикол в том, что у всех остальных они такие же мощные. Можно было бы развернуть мысль шире, но я подумал, что любой, кто настраивал хотя бы одну IDE, уже знает, что там, а тут я просто написал, что у остальных не хуже.
Пожалуй, забыл только упомянуть, что у IDEA есть две фишки:
— форматирование при вставке (ctrl+V) — вставляемый кусок форматируется, отступы корректируются под место вставки
— если написать селект, потом перед ним написать «select * from (», а после него — закрывающую скобку, то после скобки IDEA сама форматирует этот селект, оказавшийся внутри, и это нечеловечески удобно. Два пива тому, кто это придумал! ;)
Нельзя просто так взять и вычитать курсор из функции в интерфейс Идеи.А кстати, у кого еще кроме TOAD есть эта функция?
1. Только в Alt\SQL Developer’е есть режим «Direct Mode», который позволяет подключаться к Бд без установленного клиента Oracle. Если учесть, что и сама программа умеет работать в portable режиме – иногда очень выручает при авральном режиме правки багов.
2. В Oracle есть возможность именование объектов не только TABLE1.FIELD1, но и «TaBle1».«Field1». Во втором случае, обращаться нужно именно в таком регистре(и с кавычками), каким и был создан объект. И даже больше, такой способ позволяет использовать почти любые символы, включая кириллицу и пробелы. «Таблица номер 1».«Поле номер 1» – считается корректным для Oracle, но, как оказалось, не для абсолютного большинства IDE. Так вот, в Alt\SQL Developer’е подсказка с такими таблицами и полями работает правильно. (я понимаю что это может выглядит абсурдно, но вы и представить не можете с каким legacy-кодом иногда приходиться работать).
Успешно использую сию програмульку уже больше 4-ох лет и держу связь с разработчиком.
P.S. Если кому то интересно, темная тема сейчас на стадии беты.
1 — есть у IDEA и Oracle SQL Developer.
2 — ни разу не встречал, чтобы такое именование объектов использовалось на практике, то идентификаторы в кавычках должны понимать вроде бы все.
P.S. Если кому то интересно, темная тема сейчас на стадии беты.Это вообще супер, можете мне написать, когда фича будет готова? Можно в личку.
Он может работать с Instant client вместо стандартного.
— Качаете Instant client здесь www.oracle.com/database/technologies/instant-client/downloads.html
Например Basic Light Package занимает всего 40 мб. Если вам надо дополнительно SQL Plus и прочие утилиты их там же можно скачать.
— Распаковываете в любое место
— В ярлыке к запуску программы указываете путь через параметр InstantClient, например вот так ...\plsqldev.exe" InstantClient=C:\oracle\product\instantclient_18_3
И всё, полный клиент на гигабайты — не нужен.
Можно добавить этот путь в PATH. Параметры TNS_ADMIN, SQLPATH, NLS_LANG и прочие (если надо) устанавливаете через переменные окружения в Windows.
oci.dll
oraocci18.dll
oraociicus18.dll
oraons.dll
orasql18.dll
Чтобы не изменять ярлык – в PL/SQL Developer есть в настройках папка с клиентом.
А если говорить о любой программе – то эти файлы достаточно кинуть рядом с exe-шкой.
Когда мы говорим об настройке своего личного рабочего места, то здесь это не проблема. Но если возвращаться к моему посту – я писал об авральном режиме, если есть комп и не всегда даже права администратора.
В случае с Alt\SQL Developer: Сайт -> Скачать Portable – работаем (проверяем количество активных сессий или почему истек пароль на схему, и кто за это получит по голове)
В случае с PL\SQL Developer: Сайт программы –> Скачать –> Сайт Oracle -> Скачать -> распаковать -> Изменить Path -> сайт Microsoft -> скачать vc_redist.x64.exe (Да, без него клиент не работает) – работаем. На это все нужно время и права Администратора.
2 — в одной компании, которая тут периодически публикует статьи про оптимизацию в postgresql, и не такое позволяется, как я понял. Статьи у них интересные, но их либеральный подход к стилю кода удивляет.
Если поле таблицы имеет тип
… WITH LOCAL TIME ZONE
idea по-умолчанию использует UTC.
Где его можно изменить?
Toad/ plsql developer видимо автоматом тянут Europe/Moscow из винды
На чем разрабатывать Oracle разработчику в 2019-м году (и после)