Comments 238
Не понял, при чем тут коробки и всё остальное. Типы никуда не делись, просто их писать необязательно. Про то, что вывод типов удобнее чем их явное написание спросите у сишарпистов. Я помню как Java-разработчики запрещали в шарповых проектах var, потому что неочевидно.
Лично я, конечно, за то, чтобы фиксировать типы в топ-декларациях, это в принципе считается правилом хорошего тона:
consume :: (Foldable t, Ord a, Num a) => a -> t a -> [a]
consume quantity = reverse . snd . foldl go (0, [])
where
go (acc, ys) x = if quantity <= acc then (acc, x:ys) else (acc + x, ys)Но основной поинт остается: правило что в статически типизированных языках нужно только и дело что писать безумное количество типов давно устарело.
не трудно бы догадаться, что вероятнее всего там будет int
или uint, или string но ты кавычки забыл
или string но ты кавычки забыл
В 99.999% никто никакие кавычки не забыл, ради 0.001% везде писать по пять лишних символов — такое себе развлечение. Не говоря уже о том, что строгая типизация поймает такую ошибку, как только вы попробуете что-нибудь сделать с этим нулем.
или uint
А вот такое вообще должно остаться только в языках «близких» к железу, вроде С/С++
Так же динамическая типизация помогает в случаях, если функция занимается вызовом других функций, в зависимости от их типов (для тех языков, где не придумали конструкции как в Swift, которая действительно удобнее)
А какие конструкции придумали в свифте? Ниразу свифт не щупал, но интересно что там с функциями интересного "придумали" :)
А какие в С++ церемонии именно касательно типов? Auto и шаблоны уже давно к услугам автора. Имхо на С++ вполне себе можно писать в питоник-стиле.
Ну на самом деле на плюсах довольно вербозно. Например, возьмем функтор списка:
class Functor f where
fmap :: (a -> b) -> f a -> f b
instance Functor [a] where
fmap f (x:xs) = (f x) : (fmap f xs)и плюсы
template<template<class> F, class A, class B>
F<B> fmap(std::function<B(A)>, F<A>);
template<class A, class B>
std::vector<B> fmap(std::function<B(A)> f, std::vector<A> v) {
std::vector<B> w;
std::transform( std::begin(v)
, std::end(v)
, std::back_inserter(w)
, f);
return w;
}Но вообще плюсы да, наверное чуть попроще в чем-то. Но в чем-то наоборот сложнее.
В моих проектах более-менее давно используются элементарные альтернативы грядущим ranges. Я обычно именую такую библиотеку pythonic или pt. Записать код выше более-менее симпатично без старой вербозной идиоматики итераторов вполне возможно. Да, нет одной стандартной замены. Это немного удручает.
И с std:: function так не стоит. Компилятор не соптимизирует, будет неоправданное замедление.
Ну, с новым стилем главное тоже не упороться :)
И с std:: function так не стоит. Компилятор не соптимизирует, будет неоправданное замедление.
К сожалению, я не очень близко знаком с плюсами. Буду иметь в виду, спасибо.
Да, это точно. Я потому и избегаю ranges по Ниблеру, так как куда-то это не туда зашло. :) Это бич С++, что в итоге все пишут какую-то свою метабиблиотеку, которая у всех примерно об одном, но в стандарте её нет. Зато есть всякое другое, иногда сломанное.
К сожалению, я не очень близко знаком с плюсами. Буду иметь в виду, спасибо.
В С++ нету генериков и связанных с ними ограничений. Типы внутри функций не затираются и их ненужно аннотировать ещё раз. Поэтому везде можно писать auto, а типы нужны почти только для перегрузок(чего в данном случае нет).
Все остальные аннотации типов в 95% случаев несут только dx-назначение — поднять ошибки подстановки выше.
и плюсы
Вот плюсы:
auto fmap(auto f, auto v) {
return v | transform(f) | to<std::vector>();
}К тому же пример крайне сомнительный. В плюсах все интерфейсы созданы из расчёта производительности. Им попросту чужда подобная крайне неэффективная семантика. Да и пример явно манипулятивный.
Ух ты, C++20.
Он там не особо нужен — после fmap можно добавить = [] и будет не С++20. Да и в чем проблема с С++20?
Ага, например, интерфейс std::unordered_map с доступом к конкретным корзинам (который, по факту, запрещает реализацию ряда куда более эффективных вариантов реализации хешмапы).
Попытка оптимизации одного приведёт к ограничению других оптимизаций. Это всегда будет компромиссом. Это не является чем-либо значимым без полного сравнения с интерфейсами в других языках.
А тем, кому нужна производительность — ему ненужны стандартные решения. Ключевым является то — можно ли свои эти решения интегрировать во всю остальную инфраструктуру. Это важно. Всё остальное — не особо.
И заодно не будет перегрузок, да и более точные указания типов теперь не добавить совсем никак (без SFINAE по возвращаемому значению, но давайте не будем об этом, это выглядит уж больно плохо).
Я об писал выше. Это не выглядит плохо — это не выглядит сильным аргументом. Покажите для начала альтернативы приведённого функционала в F#/hs.
К тому же, сами тезисы не очень верные. Перегрузку добавить можно композицией. Более точные указания типов добавить можно(это тоже С++20, но это не концепты — это уже давно есть). sfinae — покажите в других языках альтернативы.
В том, что он ещё не вышел, поддерживающих язык компиляторов нет, да и даже когда они появятся, то до прода докатятся нескоро.
Не вышел стандарт? Поделитесь стандартом упомянутых автором перевода hs/scala/rust/F#? Либо хотя-бы F#/hs.
Поддерживающий компилятор есть. А то, что существуют не поддерживающие компиляторы — проблема тех, кто их использует. Во всех упомянутых выше одного компилятора достаточно — почему С++ не должно быть достаточно?
Отсылки к продакшену так же не засчитываются. Потому как используется уже много где. Да и отсылки к продакшену на фоне F#/hs так же несостоятельны. Продакшена на актуальном компиляторе не меньше, чем того же продакшена на
F#/hs.
Это, кстати, интересный вопрос. Почему-то компиляторы плюсов очень долго и болезненно обновляются на продакшене. Даже какой-нибудь ghc, даже, простите, питон обновляют быстрее и с большей охотой.
Это проблемы этого продакшена. Нас они волновать при сравнении не должны. К тому же, существует много продекшена на чём угодно. Другое дело, что у С++ продакшена тупо больше. А какого-нибудь F#/rust легаси вообще нет.
Во-первых, ваш же исходный тезис был, гм, немного другим.
Он был о том самом. Очевидно, что я не буду в базовом тезисе уточнять все нюансы. Это базовая, очевидная практика. Контейнеры в С++ универсальны. С ними мало кто вообще живёт. Какая-то средняя прикладуха/прототипы, либо так где они на горячем пути — за рамками этими дефолтные хешмапы обычно выпиливаются.
Во-вторых, что именно оптимизирует вытаскивание некоторых кишок std::unordered_map наружу, да ещё и не очень удачных? Я, наверное, ни разу не видел проекта, где этим бы пользовались (или, вернее, где это было бы необходимо).
Я не совсем понимаю. Вы ссылаетесь на то, что вы(или кто-то ещё) хотел написать более оптимальную хешмапу для stl, но она оказалась не совместима с интерфейсом? Зачем эта более оптимальная хешмапа в stl? Её можно использовать без проблем без каких-либо проблем — это С++.
К тому же, не большая проблема задепрекетить api, которым никто не пользуется. Осталось только доказать, что это мешает. Здесь уже я не видел подобных работ.
Какого именно? auto auto auto или рейнджей?
Того, на который вы ссылались. sfinae/перегрузку/decltype
Как? Чтобы fmap работал и с optional, и с определённым в сторонней библиотеке типом, например, бинарного дерева. Или хешмапы (только по значениям, естественно).
В чём проблема? Лямбда — это просто оператор(). Композиция лямбд — композиция этих операторов. Всё так же как и просто с перегрузкой оператора().
Они там не нужны. Туда завезли, например, тайпклассы.
Покажите пример того, о чём говорили. Допустим, перегрузка по decltype.
Мне не нужен факт наличия шильдика ISO самого по себе, мне нужно знать, могу ли я рассчитывать на то, что эту фичу в обозримом будущем не сломают.
Раз шильдик неважен — не говорите о нём.
Отсутствие зарелиженного стандарта эквивалентно непринятому пропозалу в hs-коммьюнити, например.
Основания.
Как он называется? А то ни кланг, ни гцц не поддерживают C++20.
Никакого С++20 теймплейты в лямбдах не требуют. Я ссылался на p0428r2 и по вашей ссылке он реализован, причём реализован очень давно.
Делюсь исключительно личным опытом.
Это всё печально, но ничего не значит. Можно назвать ещё больше прода, где никакого хаскеля в принципе нет. А питон древней версии. Проблема тут в основном связано с тем, что сидят на каком-то древнем дырявом говне, где гцц берут из реп диструбитива, а хаскель ставят кастомный. Но там и питон древний.
Хаскель здесь спасает только то, что его либо нету в репах, либо его не ставят из них. Но это, повторюсь, ничего не значит.
К сожалению, мне приходится писать код не только дома для себя, но и на работе в этот самый продакшен, и пользоваться тем, что дают.
Это не проблема не языка, а тех, кто даёт такое. С таким же успехом можно хаять скалу/котлин за то, что на 95% прода дадут жаву.
ну вот забавно, что плюсы у вас легаси.
Для меня легаси не плюсы. Я нигде такого не говорил. Для меня легаси — это легаси. А на плюсах оно или на пхп — мне без разницы.
Потому что хешмапа — это один из словарных типов. Кусок общего языка, на котором говорят разные библиотеки. Ну, почти как строковый тип.
В С++ библиотеки на таких языка не говорят. По крайней мере те, что использую я.
И вы так и не сказали, на компромисс с какой именно характеристикой (кроме невнимательности, конечно же) идёт текущая реализация.
В смысле? Вы ссылались на то, что открытие кишков вызывает проблемы. Вы так и не показали эти проблемы и не показали, что их зарубили при попытки пронести в стадарт. Поэтому я спрошу для начала об этом, если мы хотим говорить о конкретике.
Оказывается, что в случае плюсов это таки большая проблема. А что до работ — не так давно тот же Титус Винтерс что-то на тему писал.
Какие ваши доказательства?
Реализуется через тайпклассы.
Покажите.
Не нужно в виду неявной типизации.
Т.е. нельзя? Никакая явная типизация не может, потому как она не сможет в такое decltype(a + b)
Ну так у вас не будет перегрузки. И одного имени для кучи разных типов тоже не будет.
С чего вдруг? Не понимаю зачем вы спорите на тему С++, если все ваши познания, судя по всему, ограничены каким-то древним легаси? Композиция ламбд достаточно старый паттерн и о нём знают все, кто что-то знает о современных плюсах.
Зачем что-то утверждать не имея представления о предмете.
И даже в случае реализации через функции и наличия перегрузки, кстати, вы это имя никуда передать не сможете, потому что передавать overload set в плюсах нельзя.
Если мне нужно передать имя — я заюзаю лямбду/типа. Точно так же я могу передать его через лямбду. [](auto ... args) { return f(args...); } — так.
Я не знаю, что вы имеете в виду под перегрузкой по decltype, потому что общепринятого такого термина нет.
(auto a, auto b) -> decltype(f(a, b)) перегрузка для случая, когда тип данного выражения выводится. Т.е. функция есть и оно возвращает значение какого-либо типа. Реализуйте тоже самое "не на костылях".
В C++ основной документ, на который ссылаются при обсуждении языка, называется стандартом. Не вижу причин пытаться его называть как-то по-другому.
Нет, это не основной документ. Это просто то, что есть у С++ и чего нет у раста/хаскеля и прочего. Нет смысла ссылаться на стандарт в ситуации, когда у оппонента его нет.
Да.
Оснований нет, хорошо. Зачем о чём-то пытаться рассуждать, если оснований нет?
Это кусок C++20. Значит, темплейты в лямбдах требуют C++20.
Никто не измеряет стандарты в компиляторах какими-то С++20. Зачем вы, опять же, рассуждаете о том, в чём не разбираетесь? Там половина компиляторов вообще никакой стандарт "полностью" не поддерживает.
Поэтому никто и никогда такой глупость не занимается. Стандарт в основном нужен для того, что-бы эти куски не противоречили друг другу. Никто не сидит и не реализует какой-то там "весь стандарт".
По моему личному опыту, опять же, проблема в основном в том, что компилятор апгрейдить стрёмно. Там на новых версиях в старом коде часто баги вылезают, «ой этот тупой компилятор сломал мой гениальный код с кучей гениальных хаков» я видел неоднократно.
У меня другой опыт. Какой смысл ссылаться на чей-то опыт?
Я вот прям вчера дёргал библиотеку, которая возвращает std::unordered_map из чего-то в чего-то. Правда, её название вам вряд ли о чём-то скажет.
И что?
Или вот та же nlohmann/json умеет работать с std::unordered_map, а не с аналогами от folly, abseil или чего там.
json особенно nlohmann — это прикладуха. Какой смысл ссылаться на nlohmann, который вообще не имеет никакого отношения к производительности?
Титусовское вообще легко гуглится: вот.
И что? Это документ 2 месячной давности. Очевидно, что никто там за 2 месяца ничего и нигде не изменит.
К тому же, этот документ про abi. И там даже явно написано
API-compatible unordered_map
Т.е. он вообще противоречит вашим тезисам.
Ресёрч на тему совместимости какой-нибудь там open addressing пополам с cuckoo hashing с unordered_map гуглится чуть сложнее, но их несовместимость — это уровень фольклора (в математическом смысле), не надо писать статьи, чтобы показать, что 2+2 ≠ 5.
2+2 != 5 гуглится просто. К тому же, нужны конкретные предложения и конкретные сравнения. Всё остальное — не говорит о какой-то проблеме в смене api.
Я ж писал уже — просто пишете инстанс Functor для другого типа, а fmap выбирается уже согласно типу в точке вызова.
Напишите.
А зачем это надо?
Вот получили вы тип результата выражения. А дальше-то что вы с ним делаете?
С ним что-то делает в момент вычисления типа. Я объяснил что выше.
У вас на лямбдах не получится это сделать либо без if constexpr внутри (что не очень расширябельно, мягко скажем), либо без перегрузки или специализации какой-то функции, вызываемой из лямбды (что просто добавляет уровень абстракции).
Зачем вы продолжаете писать глупости? Вам сообщили про композицию лямбд — там работает перегрузка. Всё.
Но вы при этом не передаёте имя. И, кстати, надеетесь на компилятор, что он лямбду развернёт и соптимизирует, но это так.
Если мне нужно имя — я пишу структуру/лямбду. Я ни на что не надеюсь.
Неверно.
Верно, а ваша перепаста к теме отношения не имеет. Потому как никакого форварда в хаскеле нет. А значит и в С++ нет. Либо показывайся pf/ссылки и прочее в хаскеле.
Зачем? Что вы дальше с этой функцией делать будете? Вы ведь не пишете код с той лишь целью, чтобы написать вот такую сигнатуру?
Зачем вы съезжаете с темы? Я пишу код для того, что-бы у меня была перегрузка. Показывайте на хаскеле аналогичный функционал. Мне нужно при наличии f() — один вызов, а при наличии, допустим, x() — другой.
decltype здесь — кусок SFINAE, костыль поверх отсутствующего механизма адекватной спецификации требований к типам (и их проверки).
Нет, очевидно. Это не кусок sfinae
Обоснуйте, почему нехорошо о чём-то пытаться рассуждать, если оснований нет.
Обоснуйте, почему хорошо о чём-то пытаться рассуждать, если оснований нет.
А какой основной документ?
А какой основной документ у хаскеля?
Куда вы идёте, когда компилятор ведёт себя не так, как вы ожидаете от него, например?
Никуда, да и заход некорректный. Но в любом случае если мне понадобиться куда-то идти — начну я не со стандарта, очевидно, а с его кусков.
Вы уж аккуратнее, а то сейчас дойдёте до того, что C++ — язык то ли без де-факто стандарта, то ли без реализации этого стандарта, то ли на стандарт всем плевать, и комитет (который в прошлых выпусках был просто острием прогресса в области систем типов) работает, чтобы… Ээ, зачем они вообще работают, зачем они стандарты тогда пишут? Никто на них не смотрит же, основным документом это не является.
Стандарт — это чего нет у вас. Всё, на этом можно закончить. Все отсылки к стандарту сразу множатся на ноль. Стандарт — это надстройка над системой предложений. И если у вас они сразу имплементируются в компиляторе, то в С++ почти так же. За разницей в том, что существует тот самый комитет и стандарт, который собирает все эти предложения вместе, выкидывает неугодные, проверяет на совместимость и опубликовывает их набор как стадарт.
А, таки дошли. Ну, на самом деле, я думаю, что продуктивный разговор после этого можно сворачивать (хотя это было понятно примерно после второй вашей реплики, уж больно характерно оно всё).
А, ну т.е. всё, аргументация кончилась?
Универсальный ответ. Возьму на вооружение.
Ответ достойный глупостям, что были написаны выше. Какому какое дело до того, что вы там дёргали? Вы выдвигали тезис "везде в С++", а после ссылались на "я". Очевидно, что это позор.
Удобно, ненастоящий шотландец.
Аргументов опять нет? Так и запишем. Или мне бенчмарки доставать? Хотя уже всё забенчено за меня.
Этот документ подытоживает многолетний опыт работы в комитете (ну работы и на позиции одного из главных по поддержке кучи легаси в компании с одной из крупнейших в мире кодовых баз, наверное).
Пруфы.
Если тяжело поменять ABI, то API тем более тяжело поменять.
Нет, очевидно. Т.е. вы засыпались с примеров, выдавая его не за то, о чём говорили? А теперь уже пошли отговорки вида "да abi/api — какая разница". А чего же так?
Он бы противоречил, если бы там утверждалось, что там можно реализовать любую хешмапу с любым известным алгоритмом. А этого там не утверждается.
Нет, он противоречит потому, что говорит о том, что изменения api-совместимые. Вы говорили о других изменениях api-несовместимых. И выдавали его за пруф ваших тезисов — т.е. врали, кидая рандомный документ из гугла.
Вот плюсы:
Насколько я понимаю, этот синтаксис буквально вот-вот появился. А пример, который я взял, я взял из книжки 2015 года. Поэтому ваше утверждение что
пример явно манипулятивный.
необосновано: я взял тот, который был в наличии. Если у вас есть другой, менее манипулятивный с вашей точки зрения, давайте рассмотрим.
Тем более, что в мире остается 99.999% кода, написанного в ином стиле, и это надо учитывать. Я вот очень сомневаюсь, что если завтра вам понадобится написать в рабочем коде такую функцию, то вы её вот таким однострочником запишете.
Насколько я понимаю, этот синтаксис буквально вот-вот появился.
Нет, из нового там только auto, но в данном случае функция тут ненужна — её можно заменить на лямбду добавлением двух символов. auto там уже давно есть.
К тому же, это не является проблемой, потому как не является проблемой для js/rust и множества других языков.
А пример, который я взял, я взял из книжки 2017 года. Поэтому ваше утверждение что
Ну это явно не 17 год, даже если книжка 17 года.
необосновано: я взял тот, который был в наличии. Если у вас есть другой, менее манипулятивный с вашей точки зрения, давайте рассмотрим.
Манипулятивный не в этом смысле. Это базовый пример из fp-букваря с откусыванием элемента списка. В С++ просто нету таких интерфейсов и не потому, что их нельзя сделать — нет. Просто они не пользуются спросом.
Тоже самое и с fmap. Здесь создаётся новый список, что в языка типа С++ не приемлемо, поту как очень медленно. Поэтому там и реализовать transform с такой семантикой — он призван в основном для мутаций, но не только.
Допустим, я вынужден был написать to<vector>(), который там не нужен. Так же я вынужден был принять вектор "по значению", что так же не оптимально.
Так же, в С++ вообще контейнеры как таковые кого-то мало волнуют. Поэтому и принимаются итераторы.
Т.е. данный код целиком и полностью противоречит принятым в С++ подходам. Но он целиком и полностью соответствует паттернам принятым в хаскеле. Он и взят из хаскель-букваря.
В этом и заключается манипуляция, на мой взгляд.
Он создаётся только тогда, когда компилятор не может вывести, что старый не используется.
Это просто оптимизация находящая за рамками семантики. Она ни о чём не говорит. К тому же, в С++ нету никаких проблем с тем, что используется. Наоборот — он почти всегда где-то используется. Да и списки никто не использует.
А вот если может, или если вы языку можете про это рассказать, то всё меняется.
Только вот в данном коде ничего не рассказывается. А никакие оптимизации на "авось" не полагаются. Предсказуемость — это база любой оптимизации.
И да, воспринимайте ФП-шный список как такой итератор на стероидах, а не как структуру данных.
Только одна проблема — когда вам нужно показать то, что hs не медленный — списки вы почему-то выкидываете. Почему? Не хотите поумножать матрицы на списках?
И не в C++ ее сделать проще, потому что компилятору о коде рассуждать проще.
В С++ её ненужно делать — она уже сделана на уровне семантики.
Это типа на race condition'ы намёк? Спасибо, оценил.
Нет, это намёк на что угодно. Самое интересное тут то, что вы сами выше ссылаетесь на то, что компилятор в кишках заменяет(чисто на уровне тезисов и даже на уровне них — исходя из фазы луны) всё на мутельные структуры данных. А теперь уже это race condition'ы?
Везде, где производительность — везде мутации. Именно поэтому вы идёте и используете массивы. Просто на уровне С++ изначально всё пишется так, как нужно. Без наивной надежды на компилятор.
Естественно, потому что это свойство кода, вызывающего fmap. Если он будет рекурсивно вызывать себя, то компилятор выведет, что старая копия в рекурсивном вызове не используется, и никакие копирования не нужны.
Ещё раз — это ничего не значит. Нет никаких гарантий. К тому же, копия как минимум одна да будет. В случае с С++ её не будет.
Примерно потому же, почему я не умножаю матрицы на итераторах.
А я умножаю, с этим есть какая-то проблема? Ну а как же оптимизации? Почему вы рассказываете о том, что списки не проблема и всё оптимизируется, но когда дело доходит до реальных примеров — вы первым же делом выкидываете списки? Выкидываете иммутабельность?
Почему ваши тезисы расходятся с действиями?
C++ это не специфицирует на уровне семантики. Он требует, чтобы программист не делал ошибок, но никаких гарантий или безопасности сам при этом не даёт
Это лозунги. Конкретика. Очевидно, что язык с лоулевел доступом даёт больше возможностей, но увеличивает вероятность ошибок. Именно поэтому вы идёте в очередных сравнения С++/hs используете unsafe. Почему?
(и не может давать, система типов не позволяет).
Основания предоставьте.
Мне нужна управляющая структура — я использую список. Мне нужно нелениво хранить все элементы сразу и что-то с ними делать — я беру вектор. Мне нужно потратить лишних 10 минут, чтобы выжать немного производительности — перехожу в монаду ST.
Вы утверждали, что список оптимизируется. Вектор берётся только для оптимизаций. Значит, если он берётся — оптимизаций списка недостаточно, если они вообще есть. Это полностью противоречит вашим начальным тезисам.
Ага. Вы правда не надеетесь, что компилятор развернёт все ваши итераторы и слои шаблонов? На NRVO и copy elision не надеетесь? Не надеетесь, что компилятор соптимизирует memcpy для копирования представления объекта без type punning'а? Если писать на плюсах аккуратно, как нужно, без UB, то плясок и пританцовываний будет куда больше, чем, гм, в среднем коде.
Вы запутались в логике. Вы же там сами говорили, что С++ код проще оптимизируется. Ведь компилятору о коде рассуждать проще. Я знаю что развернёт компилятор и развернёт он это всегда. Потому как это примитивные лоулевел оптимизации. rvo для всех(либо почти всех) случаев уже давно требование стандарта.
К тому же, почему я не могу надеяться на оптимизации, а вы можете? Разница между нами в том, что я надеюсь на то, что есть и что работает. Я не надеюсь на хайлевел оптимизации.
И если вы не надеетесь на компилятор, то собирайте код с -O0, в конце концов. В производительности не потеряете, не так ли?
Не засчитывается. Во-первых -O0 не значит "без оптимизаций". Компилятор в принципе не заточен на то, что-бы генерировать код без оптимизаций. Поэтому этот режим стоит назвать "режим пессимизации с максимальным сохранением языковой семантики". Правда зачастую почти никакая семантика не определена. Допустим есть типы памяти, но нигде не написано как и что хранить.
Во-вторых, я не отказываюсь от компилятора. Проблема ваша не в том, что вы надеетесь на компилятор — проблема в том, что вы надеетесь ТОЛЬКО на компилятор. Потому как семантически ваш код не оптимален.
Откуда?
Если я буду использовать старый список одновременно с новым. Семантически в С++ это можно быть один и тот же "список", а в hs нет.
Какая там нынче актуальная рекомендация для передачи параметров? Pass-by-value и всегда иметь как минимум один мув (привет ммммаксимальной производительности)?
Понятия не имею. Мув — это базовая семантика копирования из си. Копирование не является проблемой.
Или делать везде perfect forwarding, вынося весь код в хедер?
pf вообще ненужен, если нету raii. Я не являюсь адептом raii и его у меня почти нигде нет. Поэтому мне вообще без разницы.
А код у меня итак весь в хедерах. И он в хедерах у любого, кто может и умеет писать на С++, потому как иначе нельзя.
Что, кстати, тоже не гарантирует максимальной производительности, но соответствующий пример будет сконструировать уже чуть сложнее.
Мне гарантирует максимальную производительность(если она мне нужна, конечно) я, а не язык.
Потому что, ещё раз, каждой задаче свой инструмент. Я сразу сказал, что список — это управляющая структура, не надо к ней относиться как к структуре данных (и строить соломенные чучела тоже не надо).
Для списка вообще нет задач. Это почти всегда мёртвая структура данных.
Нужно прочитать построчно файл и что-то с ним сделать — делаете unlines <$> readFile path и обрабатываете, лениво и в O(1), прям как с итераторами (только без необходимости писать итераторы и весь код делать зависящим от конкретного типа итератора или выносить в шаблоны).
Мне вообще ничего ненужно читать — у меня есть mmap. И я не пишу какие-то итераторы и прочие базворды.
Нужно дробить числа и что-то хитрое делать — перегоняете список в массив и работаете с ним. Чисто, или нет, или через repa или accelerate какой — вообще десятый разговор.
Т.е. вы признаете, что fmap несостоятелен? И нужно перегонять в массив и мутировать его, если мне, допустим, нужно заинкрементить списку интов значения?
Причём тут иммутабельность-то?
При том. Что с неё всё и началось. Вы про что говорили? Что иммутабельная семантика не слабая — компилятор заменит её на мутабельную.
Копирования — это уже следствие этой семантики.
Потому что в этот конкретный язык не завезли пока средства для того, чтобы статически доказать безопасность.
Ну т.е. у вас ничего нет, никаких оптимизаций нет. Но С++ плохой, потому что там безопасности нет? Это настолько нелепо.
Теория зависимых типов, зависящих от динамических термов, для императивных языков неизвестна. То есть, вообще, даже в академии, даже на папирах. Топчик, наверное, это ATS, но оно там ближе к стратифицированной системе типов, а не к полноценной зависимой системе типов. Поэтому выразить инвариант «индекс внутри» у вас не получится.
Не, это не основания. Это "я не знаю". Основания должны звучать так. "Это невозможно потому-то — вот пруфы". К тому же, зависимых типов в хаскеле нет.
Перечитайте тезисы-то. Речь о том, что иммутабельность не обязательна, компилятор может свернуть список во что-то мутабельное, если он видит, что, например, персистентности не нужно. Увы, видеть всегда он это не может, там теорема Райса где-то рядом.
Ну, если список мутабельный — вектор ненужен при данном кейсе. Потому как вектор туда вставляется именно потому, что он мутабельный. Единственная ваша возможность — это сослаться на то, что верктор при любой доступе оптимальней. Но тогда вы сразу же определяете список не оптимальным в данном кейсе, а все рассуждения не имеют смысла. Ведь про оптимизации вы начали говорить именно в контексте "не тормозит потому-то".
Основания.
Я написал основания. Основания для игнорирования.
И что?
И то, что понятия "без оптимизаций" в принципе нет. А -O0 к нему никакого отношения не имеет.
Простите, не мог себе отказать в удовольствии.
Не засчитывается.
Ясно.
А теперь полные цитаты.
Код на плюсах тоже неоптимален. Ну вот так получается, что код на ЯВУ без ручного инлайнинга всего подряд или ручной аллокации регистров или ручного выбора инструкций неоптимален. Ну, просто по определению.
Это какое-то заклинание. Просто перечисление услышанных где-то базвордов. Я могу руками аллоцировать регистры, как и руками инлайнить. Как и могу руками подставлять инструкции — asm часть С/С++.
Но в любом случае это ничего не значит. Если компилятор сделал то, что нужно мне — код уже оптимален. И даже если я не могу что-то сделать напрямую(а я почти всё могу), то это не значит что чего-то нельзя. Можно это сделать не напрямую.
Т.е. если я знаю паттерны в которых компилятор генерирует нужную мне инструкцию — я использую этот паттерн. И получу то, что мне нужно.
У вас не получится это делать. Если вы мутировали список, то старую копию вы потеряли, всё, нет её.
В С++ я ничего не теряю.
Ну и что, что один TU компилируется 10 минут после малейшего изменения
Полная чушь.
а clangd жрёт 20 гигов памяти.
Нет, очевидно. Он её столько не жрёт. А даже если бы жрал — это не проблема. Эта память ничего не стоит.
А мужики и не знали.
Ну теперь знают.
И как вы реализуете эти гарантии?
Руками. Если компилятор собрал код нужным образом — он его соберёт.
Структура данных — да. Сколько раз мне повторить, что список в ФП — это управляющая структура?
А, ну значит вы мне покажите fmap описанный мною ранее.
И руками находите \n, руками нуль-терминируете строку,
Я ничего не нуль-терминирую. Нахожу руками. А могу и не руками.
чтобы передать её в какое-нибудь легаси (всего-то двухлетнее),
Я не пишу прикладуху. А даже если бы писал — это не проблема.
которое ждёт std::string, а не std::string_view (которым тоже прикольно стрелять себе в ноги)?
Ждёт std::string — это прикладу. И это её проблемы. К тому же, всё это без проблем конвертируется автоматически.
Очень модульно и тестируемо, скажем, ага.
Опять какие-то лозунги.
Лол. fmap к спискам имеет околонулевое отношение. Он точно так же радостно выполнит вашу функцию по какому-нибудь вектору. Привет перегрузкам.
Если fmap для списка оптмизируется, то нет смысла использовать чуждый вектор. Вот пойдите и покажите, что разницы нет.
Смотря что вы хотите сделать. Записать их потом в файл? Показать на экран? Отправить в сеть? Просуммировать? Ещё как-то свернуть? Во всех этих случаях ничего не надо никуда перегонять или мутировать, можно работать со списком.
Это неважно. Просто записать в /dev/null. Хорошо, а теперь это нужно проверить. Реализуйте задачу выше на списках, а я на массиве. Сравним.
Допустим, я вынужден был написать to<vector>(), который там не нужен. Так же я вынужден был принять вектор «по значению», что так же не оптимально.
ак же, в С++ вообще контейнеры как таковые кого-то мало волнуют. Поэтому и принимаются итераторы.
Т.е. данный код целиком и полностью противоречит принятым в С++ подходам. Но он целиком и полностью соответствует паттернам принятым в хаскеле. Он и взят из хаскель-букваря.
В этом и заключается манипуляция, на мой взгляд.
Ну тут наверное неудачно то, что автор использует именно что вектор. В том же расте это выглядело бы так:
fn fmap<A, B>(f: impl FnMut(A) -> B, xs: impl Iterator<Item=A>) ->
impl Iterator<Item=B> {
xs.map(f)
}Нужно понимать, что списки — это больше итераторы, нежели массивы, и паттерны их использования соответственно совпадают.
Ну тут наверное неудачно то, что автор использует именно что вектор. В том же расте это выглядело бы так:
Какая версия раста нужна что-бы это собрать?
Нужно понимать, что списки — это больше итераторы
Если это итератор и так xs.map(f) можно, то функция реализуется так: auto fmap = transform. Да даже если не итератор — эта реализация так же пойдёт.
Какая версия раста нужна что-бы это собрать?
Конкретно этот — 1.26, когда impl Trait стабилизировали. Но это непринципиально, вот так:
pub fn fmap<A, B, F: FnMut(A) -> B, TA: Iterator<Item=A>>(f: F, xs: TA)
-> std::iter::Map<TA, F> {
xs.map(f)
}Соберется на 1.0
Если это итератор и так xs.map(f) можно, то функция реализуется так: auto fmap = transform. Да даже если не итератор — эта реализация так же пойдёт.
Ну выше мы объявляем все же не функцию, а тип на которой эта функция реализована. Но вообще интересно, да.
Конкретно этот — 1.26, когда impl Trait стабилизировали.
Ну в это время гцц уже мог во всех используемые мною фичи.
Ну выше мы объявляем все же не функцию, а тип на которой эта функция реализована. Но вообще интересно, да.
А в С++ ненужно ничего объявлять. В этом суть С++. Вы в расте определяте все эти типы потому, что раст стирает типы. Если вы уберёте аннотации у типов — у вас всё поломается.
В С++ же ненужно ничего аннотировать — он не стирает типы. Обычно людям после генериков подобное поведение непривычно и они пытаются добавлять аннотации там, где в С++ они ненужны.
Ну в это время гцц уже мог во всех используемые мною фичи.
Вопрос не в том, когда кто умел, а в том, можно ли это тащить в прод. Если все съездили на конфу, услышали умных чуваков, а потом пошли дальше пилить проект где эти знания ближайшие лет 10 не применить — это такое.
А в С++ ненужно ничего объявлять. В этом суть С++. Вы в расте определяте все эти типы потому, что раст стирает типы. Если вы уберёте аннотации у типов — у вас всё поломается.
Я про другое говорю, что все это реализация тайпкласса, а не просто функция, висящая в воздухе.
В С++ же ненужно ничего аннотировать — он не стирает типы. Обычно людям после генериков подобное поведение непривычно и они пытаются добавлять аннотации там, где в С++ они ненужны.
Ни шаблоны ни генерики ничего не стирают, вопрос в инстанцировании в момент вызова или в момент объявления. Лично я предпочитаю второе, потому что во-первых ошибки намного понятнее, во-вторых понятно какие требования к типу. Лично мне проще понять constraint T : Foo + Bar is not satisfied чем какой-нибудь couldn't apply operator &>>< to operands "MyDuper" and "MySuper".
Вопрос не в том, когда кто умел, а в том, можно ли это тащить в прод. Если все съездили на конфу, услышали умных чуваков, а потом пошли дальше пилить проект где эти знания ближайшие лет 10 не применить — это такое.
Если на прод затащили раст — затащат и актуальные плюсы. А туда, где легаси — туда и раст не попадёт, как и F#. Как максимум там будет хаскель, но и то крайне сомнительно.
Я про другое говорю, что все это реализация тайпкласса, а не просто функция, висящая в воздухе.
В С++ это не просто функция весящая в воздухе. Типы нужны для того, что-бы код валидировался. Если он валидируется без аннотаций — аннотации ненужны. В этом и суть статьи. С++ этому следует как никто другой.
Ни шаблоны ни генерики ничего не стирают
Стираю. Попробуйте запустить эту функцию без аннотаций. Либо получить оригинальный тип. Вы не сделаете ни того ни другому. Потому как тип стёрт внутри функции.
вопрос в инстанцировании в момент вызова или в момент объявления.
Это уже следствие. А первый вопрос — стирать или не стирать типы. Если стирать типы — можно не инстанцировать для каждого типа и проверять только сигнатуру. А далее уже сгрузить подстановку типа на кодоген, хотя семантически там vtable.
Лично я предпочитаю второе, потому что во-первых ошибки намного понятнее, во-вторых понятно какие требования к типу.
А если вообще без генериков — ошибки ещё более понятны. А про требования к типу — это какой-то странный тезис. Такое чувство, что вы статью, которую перевели и не читали.
Ведь так и работает хаскель. И автор и говорит, что это хорошо. Мы хотим статически, но не писать тонны церемониальной лапши.
Лично мне проще понять constraint T: Foo + Bar is not satisfied чем какой-нибудь couldn't apply operator &>>< to operands "MyDuper" and "MySuper".
А мне проще читать второе — это не аргумент.
Проблема в том, что тот код, где будет сложная ошибка в С++ — на расте вы попросту не напишите не запутавшись в аннотациях. И ошибка несоответствия этим аннотациям будет не особо сложнее.
К тому же, в С++ уже есть и подход с аннотациями. Который, к тому же, не затирает типы.
Проблема в том, что код шаблонной функции очень так себе валидируется, пока вы её не вызываете. А лично мне бы хотелось, чтобы мой код проверялся, когда я пишу этот самый код, а не когда я его использую.
Никакой шаблонной функции нет — он не может в принципе валидироваться. И он должен валидироваться в момент использования, потому как только в момент использования там будут нужные типы.
Раз уж мы тут непонятно чем меряемся — покажите, пожалуйста, как можно ограничить тип шаблона наличием у него поля с определённым типом.
Я не вижу там полей. К тому же в С++ ничего ограничивать ненужно. Повторяю — вы что-то там ограничиваете лишь потому, что у вас затираются типы. И вы не можете иначе.
В С++ это ненужно. Единственное для чего в С++ существуют концепты — это для перегрузки, потому как перегрузка "не смотрит" в тело.
А так в С++ было с его рождения. https://godbolt.org/z/As4NVC — по модному так, а по старому — как угодно. Правило простое — от поля должна как-то зависеть сигнатура.
template<typename T, typename = decltype(T{}.name)> void f(T) {}Конечно, странно задавать такие вопросы используя с++. Все эти вопросы — детский сад для С++. Может какую угодно логику выполнять при перегрузки и про ограничения.
Даже факториал считать. https://godbolt.org/z/SBS4VA — вообще что угодно.
Так тип же вам доступен. Просто проверяется, что вы с ним не можете сделать ничего, кроме того, что объявлено в констрейнтах.
Тип не может быть доступен, потому на уровне тайпчекинга его нет. Именно поэтому в С++ такой тайпчекинг, ведь только такой тайпчекинг позволяет получить тип.
В вашем же случая вы внутри функции не имеете доступа к типу. Только к типам аннотаций, что вы на него навесили.
Почему? Кому должен? Кто мешает описать констрейнты заранее, проверить тело функции относительно этих констрейнтов, а потом подставлять конкретные типы, пусть даже безо всяких стираний?
Потому что нельзя ничего проверить не имя тип. В вашем случае вы никакие типы не проверяете — вы просто аннотируете параметры заново. И уже нету никаких генериков — поэтому и возможна проверка.
Если же не затирать тип, то я без проблем могу вызвать тот метод, допустим, которого нет в ваших аннотациях.
Ну серьёзно, перестаньте так воевать с другими языками. Попробуйте их. Ваши навыки в C++ от этого не пропадут и не испортятся.
Я не воюю с языками.
Они там в соседней функции, не конкретно в тех строках, на которые я сослался.
Ну приведите весь контент.
Не затираются, я ж вам пример показал. Это даже несерьёзно.
Затираются. Если они не затираются — нужно отдельно тайпчекать каждый вызов.
А ограничиваю я потому, что я пишу модульный код. Я хочу выразить констрейнт «функция может работать с любым объектом-конфигом, покуда у него есть поле (с произвольным именем) с заданным типом». Ближайший костыль — ограничиться, скажем, std::tuple и проверять, что std::get<T> — well-formed.Нет. Вы ограничиваете потому, что иначе не можете. Это очевидно, потому как в противном случае два разных теле функции могут противоречить друг другу. И невозможно их потайпчекать вместе.
Даже если вы можете не писать аннотации, то во-первых вы не сможете протайпчекать тело. Потому как типы неизвестны. Единственное что вы можете — это собирать сумтип в процессе вызова функции таким образом, что-бы одно тело удовлетворяло всем вызовав.
Прочитайте вопрос внимательнее. Он про наличие поля с заданным типом, а не именем.
Я не понимаю — зачем? Зачем вы задаёте такие нелепые вопросы. Любой тип проверяется. Любыми проверками. https://godbolt.org/z/CtUg9r
Да, можно magic-get (но будут ограничения). Можно ограничиться туплами. Но в общем случае вы эту задачу не решите никак без кучи ручной писанины.
Какую задачу? Показывайте, где у вас там что ищется по полям с произвольными именами по типу.
Если имён нет, то это тапл и там без проблем что-то ищется. Причём произвольно. К тому же — эта задача не имеет смысла. Зачем мне сувать разные типы в тапл, что-бы потом что-то там искать? Это ваши проблему — у вас нету имён и прочего.
У меня есть имена. А если прям мне нужно по типу что-то делать — я могу написать это руками без проблем. Повторю — С++ на уровне типов дважды тюринг-полный.
Щито? Типы по определению доступны на уровне тайпчекинга, в этом смысл тайпчекинга. Это уже как-то совсем несерьёзно.
Нет, у вас нет типов — у вас есть аннотации. Это и есть типы. Те типы, которые вы передаёте — в тайпчеке не участвуют. Если бы участвовали — нужно было бы тайпчекать каждый инстанс, как это делает С++.
Если проще у вас типизация как жава. f(base_class arg) и далее вы тайпчекаете с arg как с этим типом. А уже то, что туда передаёте тип g — вы не чекаете. Он просто затирается, как в жаве.
Правда у вас там не базовые классы, а больше интерфейсы из жавы. Но схема та же. Примитивная как топор. Самая базовая.
Вот же он — a, во всех случаях. Чем он вас не устраивает?
Тем, что у меня доступен тип. Тип именно аргумента(ну там после всякое сишной дристни типа decay). В этом фундаментальная разница.
Вот с поиском типа в тапле. А вообще меня удивляют эти вопрос, повторю. Какие-то крайне наивные представления о С++, фанатизм и прочее.
template<typename Ttuple, typename T> concept with_type = requires(Ttuple tuple) {
to_set(transform(tuple, decltype_))[type_c<T>];//я могу тут любую логику писать
};
void f(with_type<int> auto) {}
int main() {
f(std::tuple{10});
}Повторю ещё раз. Система типов С++ тюринг-полная( и не один раз). Сигнатура любой функции так же. Т.е. можно производить какие угодно вычисления. Их можно производить и через перегрузку и через базовую логику и через decltype().
Поэтому вопрос уровня "может ли С++ что-то там найти в типах" — несостоятелен. Скорее что-то иное чего-то не найдёт, но не С++.
Единственное чего нет в С++ — это интроспекции и рефлексии. Т.е. получить список полей структуры, либо ещё что-то — нельзя. Так же нельзя сгенерировать функции или прочее.
Но реализация рефлексии уже есть. Плюс есть clang — прикрутить рефлексию уровня "как в расте" — можно за пол дня. Да что угодно можно.
А полноценной статической рефлексии нету нигде, ни в одном языке. И обвинять С++ в том, что у него нету того, чего нету нигде — глупо. Ну хотя этим вы и занимаетесь.
Не получается придумать реальные проблемы — мы придумаем новые. Подумает, что это проблемы всех языков в целом.
Так и здесь. "у С++ слабая система типов, а вот у хаскеля". "ну зависимые типа, бла-бла". И уже не имеет значения, что их нету ни в хаскеле, ни в любом другом практически применимом языке. Всё это на уровне академических poc с бесконечным числом ограничений.
Ну так напишите код, который берёт произвольную struct пусть даже со всеми публичными полями и находит там поле с данным типом. Заодно посмотрим, как нам в этом поможет Тьюринг-полнота, базовая логика и decltype.
Вы уже один раз опозирились, теперь пошли новые потуги. Во-первых, перед тем как что-то там балаболить — нужно продемонстрировать это самому. Во-вторых я не вижу оправданий за предыдущие факапы?
Ну вы сами и ответили, тащем.
Нет, просто какой-то си с классами джун на базе моего тезиса придумал новое супер-задания в надежде, что никто не заметит. Но не сработало.
Непонятно, зачем было писать предыдущий тезис?
Там всё объясняно.
Есть. От TH и Generics в хаскеле (тут они подойдут лучше) до всяких растовских макросов.
Полная чушь. Опять я спорю с позорниками, которые нихрена не знают. Макросы — это отдельный язык. К тому же ничего этого в расте нет — опять кто-то опозорился.
Опять наш гений-джун увидел где-то макрос и решил, что в расте это делается макросом. Нет, джун опять опозорился. Потому как это делается плагином для компилятора.
Хотя зачем я что-то объясняю — пусть позорник сам пруфцует всю эту чушь нелепую.
Опять наш гений-джун увидел где-то макрос и решил, что в расте это делается макросом. Нет, джун опять опозорился. Потому как это делается плагином для компилятора.
И много Вы видели "вживую" плагинов для компилятора в Rust? Я так навскидку могу назвать разве что стандартные вещи типа clippy, и то с натяжкой (потому что это отдельная программа, которая использует компилятор как обычную библиотеку). Или Вам просто не нравится название "процедурные макросы"?
И много Вы видели "вживую" плагинов для компилятора в Rust?
Плагин это не только:
использует компилятор как обычную библиотеку
Это что угодно, что предоставлять/использует внутренней/внутреннюю логике/логику компилятора.
Или Вам просто не нравится название "процедурные макросы"?
Это другой, левый язык. Когда используется макросы — язык сам себя определяет несостоятельным.
А можно было сразу прямо сказать, что Вы не согласны с официально принятой в соответствующей среде терминологией (и поэтому procedural macros в Rust — это для Вас не макросы)? Ну и вообще в аналогичных случаях сразу раскрывать свою мысль. Меньше же потом объяснять придётся.
А можно было сразу прямо сказать, что Вы не согласны с официально принятой в соответствующей среде терминологией (и поэтому procedural macros в Rust — это для Вас не макросы)?
Очередной адепт скриптухи начал отождествлять себя с какой-то официальной принятой терминологией.
Хотя на самом деле он ссылается на догматы локальные своей веры, т.е. конкретной скриптухи. В данном случае раста.
Во-первых, скриптуха сама определяет что и как называть. Никакой "официально принятой терминологии нет". Во-вторых — меня не должно волновать то как адепты очередной скриптухи что-то называют. Это должно волновать только других адептов.
Это настолько удивительно, что каждый адепт очередной скриптухи пытается убедить кого-то в том, что этот кто-то должен принять его веру?
Ну и вообще в аналогичных случаях сразу раскрывать свою мысль. Меньше же потом объяснять придётся.
Читать нужно — "я сел в лужу и попытался нелепо оправдаться", типа "я сразу не понял, что ты дурак, но ты дурак".
Так как в общепринятом смысле слова "адептом" чего бы то ни было я не являюсь, а используемое Вами значение слова мне неизвестно, первое высказывание для меня не имеет смысла. Более того, с большой долей вероятности оно не имеет смысла также и для остальных присутствующих в этом обсуждении, кроме Вас.
Если Вас не волнует, как называется какое-то явление в той среде, в которой оно существует, не стоит доказывать, что оно называется именно так, как Вы сказали, а не иначе ("это не макрос, а плагин компилятора"). Внутреннее противоречие (в данном случае — "мне это неважно, но я буду это доказывать") не помогает ни в каком случае, кроме намеренного введения в заблуждение.
Читать любое высказывание нужно в первую очередь дословно. Иначе есть большая вероятность додумать за собеседника то, чего он заведомо не мог предположить. Если, конечно, Вы не являетесь обладателем паранормальных способностей.
Так как в общепринятом смысле слова "адептом" чего бы то ни было я не являюсь
Любой адепт уверяет всех, что он не адепт. Это стоит ноль.
а используемое Вами значение слова мне неизвестно, первое высказывание для меня не имеет смысла. Более того, с большой долей вероятности оно не имеет смысла также и для остальных присутствующих в этом обсуждении, кроме Вас.
Оно имеет вполне очевидный смысл. Просто адепты пытаются казаться какими-то уникальными и независимыми. На самом деле у них одна методичка на всех, они все из одной секты. Там достаточно пойти полистать комменты.
Если Вас не волнует, как называется какое-то явление в той среде, в которой оно существует, не стоит доказывать, что оно называется именно так, как Вы сказали, а не иначе ("это не макрос, а плагин компилятора").
Ещё раз, явление в какой-то среде называет так только в рамках среды. Вы опять палитесь. То, что вы думаете, что ваша среда(читай учение о поклонение очередной скриптухи) может диктовать условия всем — это типичный сектантский паттер поведения.
Поэтому, я могу это называть как хочу. У меня есть тому основания, которые вы проигнорировали. У вас же никаких оснований нет, кроме ссылок на методичку какой-го учения.
Внутреннее противоречие (в данном случае — "мне это неважно, но я буду это доказывать") не помогает ни в каком случае, кроме намеренного введения в заблуждение.
Опять адепт пытается рассказывать о том, что несоблюдения догматов какой-то секты автоматически определяет твои суждения не верными.
Читать любое высказывание нужно в первую очередь дословно.
Не нужно.
Иначе есть большая вероятность додумать за собеседника то, чего он заведомо не мог предположить.
Есть вероятность того, что собеседник севши в лужу начнёт придумывать своим словам новые смыслы.
Если, конечно, Вы не являетесь обладателем паранормальных способностей.
Для этого ненужно паранормальных способностей.
Начну с конца:
Для этого ненужно паранормальных способностей.
Палитесь, товарищ. Впрочем, я сделаю вид, что по-прежнему считаю Вас человеком, но всё же — палитесь.
Собственно, на этом можно и остановиться (любые споры с высшими силами беспочвенны, поскольку они всегда правы, даже если их слова противоречат реальности, в чём я уже неоднократно убеждался). Но, как я уже сказал, сделаю вид, что палева не было.
Любой адепт уверяет всех, что он не адепт. Это стоит ноль.
В таком случае любое Ваше заявление стоит ноль, по дословно той же самой причине — Вы не можете доказать, что не являетесь адептом высказываемых Вами утверждений.
На самом деле у них одна методичка на всех, они все из одной секты.
Если официальную документацию называть "методичкой", то да, безусловно. И да, это объясняет, почему Вам наплевать на стандарт — Вы же не хотите, полагаю, быть "адептом из секты C++".
Ещё раз, явление в какой-то среде называет так только в рамках среды. Вы опять палитесь. То, что вы думаете, что ваша среда(читай учение о поклонение очередной скриптухи) может диктовать условия всем — это типичный сектантский паттер поведения.
Ну так и зачем Вы-то лезете в эту среду, в таком случае, со своими высказываниями? Никто же не говорил о подобном объекте где-то, кроме Rust, и тем более не утверждал, что там он должен называться так же, как и в случае с Rust.
Поэтому, я могу это называть как хочу.
Безусловно. Но либо в своей среде, либо при обсуждении общих понятий, которые от среды не зависят и в которых действительно нужен общий лексикон, а не навязанный ни Вами, ни нами.
Опять адепт пытается рассказывать о том, что несоблюдения догматов какой-то секты автоматически определяет твои суждения не верными.
Назвать специалистов по матлогике с их законом непротиворечия, гласящим, что "конъюнкция утверждения с его отрицанием ложна", "сектой" — это надо было постараться. Ни на что иное, кроме этого закона, я здесь не ссылался (а если ссылался — цитату в студию).
Отвечу сразу на тему плагина
В общем, поверх языка всегда надстраивались всякие левые правила для внешних инструментов, в том числе компиляторов.
Вначале это были просто всякие хинты в комментах. Но хинты на то и хинты, что они чисто декларативны. Это мета-аннотации.
Всякие макро-расширения уже позволяли производить логику. Ну вот в раст перепастили такой отдельный, левый макро-язык. Это вообще не раст.
Для языка это что-то типа комментов. Типичный макропроцессор из си. Правда в си он был изначально отдельной программой, но сейчас он по-сути часть компилятора.
И этот отдельный язык может инлайнится в файлы с раст-кодом. Это допустим как инлайнинг тестов.
Т.е. это код, код на внешнем языка, который исполняет компилятор. Это расширение логики компилятора. И семантически и с ТЗ реализации.
В расте объектная модель примитивная как топор. Там есть только структуры как в си(из llvm). Больше ничего нет. Нет методов, нет областей видимости, наследования и всего того, что и делает интроспекцию сложной.
https://godbolt.org/z/BMGSSU — это, конечно, вещь несоизмеримо более мощная. Но пример и подход тот же. Плагины писать сложно — поэтому реализуется dsl для удобной го написания правил. Но по-сути это расширение.
Я не удивлюсь тому, что кто-то уже реализовал инлайнинг этих правил в С++-атрибуты/комменты.
Так же, это на тему того о чём я говорил. Что делает это за пол дня. Из этого выхлопа можно сразу генерировать адептеры, а далее язык всё может сделать сам.
Да и, как я уже говорил, существует реализация рефлексии/интроспекции для С++. Реализовать там поиск поиск поля с нужным типом достаточно просто: https://godbolt.org/z/nGjMro
И это не плагин, это не макросня и не внешний язык. Это именно С++ код. Это такая же функция, которая вызывает обычные функции, получает обычные результаты. И может на порядки больше, чем убогая скриптуха/макросня из скриптухи.
Ух ты, и получили то (нифига не стандартизованное, правда)
Нет, кстати, здесь можно заметить типичную неадекватную логику.
что было в никому не нужном скриптушном хаскеле уже лет 17 (template haskell — ровно про это, чтобы обычными функциями оперировать представлением исходников).
Подождите, но ведь оно тоже не стандартное. И что, поломалось методичка?
К тому же, это полная чушь. Ничего этого в этой скриптухи нет. Адепт врёт. А колхоз-интроспекция уровня начальной школы, либо eval — этому уже лет 30 в скриптухи.
Опять адепт пытается кичиться общими(бесплатными) свойствами скриптухи выдавая их за свойства отдельной скриптухи.
Кстати, как насчёт того, чтобы с вашей макрухой считать файл и на базе него сгенерировать какие-то данные или типы? Смогёте?
Во-первых адепт не может мне рассказывать про смогёт, пока не ответит за прошлой смогёт.
Во-вторых — файлы это уровень скриптухи. В не скриптухи существует только код. Всё код. С файлами в пхп.
Это, кстати, типичный подход адептов скриптухи. Прибегают с какой-то ахинеей и начинают её требования. Сама ахинея ничего не стоит. Чтение файла в блоб реализуется за максимум те же пол дня. Почему никто не реализовал? Да потому что это нахрен никому здесь ненужно.
Кстати, это же методичка про интернет. Я потом линкану предыдущие рассуждения данного адепта. Там тезисы того же уровня, а может даже выше.
Это совершенно неважно.
Если это неважно, зачем адепт об этом пытается сообщить?
Опять «вывсёврёти». Ну вы бы хоть погуглили бы прежде чем так позориться.
Мне ненужно ничего гуглить. Я сказал — адепт поломался. Задача адепта скриптухи доказывать то, что в ней что-то есть. Я не занимаюсь поиском херни.
Задача показана — задача адепта воспроизвести, а не болтать.
Которую до сих пор даже в C++ не завезли, ага.
Опять какая-то чушь. Опять адепт пытается нести херню вида "почему самолёты летают так медленно — я вот вчера своё корыто затюнил в 2 раза". Потому что, адепт, это разные миры. То, что происходит в твоём колхозе — ничего не значит. Они не соответствует тем требованиям, что предъявляются тут. А то, что запросы у тебя нулевые — это лишь следствие твоих примитивных запросов.
То есть, код с вас, а отвечать должен за это я?
Какой код? Отвечать нужно за болтовню. Я дал задачу на демонстрацию диспатча и инлайна. Ваша задача воспроизвести. Не сможете — ты сели в лужу.
Это уже совсем трэш пошёл. Вот хочу я считать XML с описанием схемы сообщений, или HTML с ещё чем-то, да мало ли, что мне в C++ делать?
Я сразу сказал, что адепт начнёт эту историю про скриптуху. Никакой хмл, хтмл и прочие скриптушное нечто — ненужно.
С++ куда мощнее и выразительнее для описания любых данных, текстовый мусор — удел скриптухи.
Единственное, почему С++ используется там, где есть этот мусор — это то, что скриптуха не может работать быстро и надёжно. Поэтому приходится приходить королю и разруливать.
А так, это задачи недостойные С++. А даже если кому-то это понадобиться — это реализуется за пол дня, как я уже говорил. Правда никому это ненужно, хотя может кому-то и нужно и там это уже есть.
Потому что в контексте плюсов это важно.
Нет.
Не, сорян, это так не работает. Не получится специально не гуглить, не ходить по ссылкам, а вместо этого закрыть уши и глаза и громко кричать «нету этого врёти адепты методички поломался задачу дал».
Нет, адепт не дал никакой ссылки. Адепт просто болтает. Всё, что болтает и на что нет пруфов и обоснований(хоть каких-то) — балабольство. Никто не просит болтуна идти и в стандарт — он всё ровно ничего не знает и не осилит его прочитать.
Нужно хотя-бы показать основания. Почему это так, а не иначе. Привести хоть какие-то доводы, а не бла-бла я так сказал.
А какие требования предъявляются тут?
Такие, почему адепт ваяет примитивное легаси-говно на С++, а не бороздит космос на хаскеле.
Которая не имеет никакого отношения к обсуждаемому предмету.
Имеет. Основания. Я их предоставил. Болтун нет.
Я воспроизвёл. Одним из наиболее удобных вариантов (т. к. там UB).
Во-первых адепт не доказал наличия там УБ и его нет. Во-вторых УБ ничего не значит и никого не интересует и никак болтуна от ответа не освобождает.
К тому же, болтун даже тут сел в лужу. Нельзя УБ как-то трактовать. Опять болтун где-то услышал какую-то чушь и повторяет.
Напоминает фанатов Go, у которых и дженерики-темплейты ненужно.
Чем же?
Да, кодогенерацией.
Нет. Опять позор нелепый.
Основания.
Методичка потекла. Я не обязан доказывать отсутствие чего-то — это задача адепта доказывать присутствие. В данном случае важности.
Ссылка была выше. Если она вам не нравится, то вопросы не к ней, а к вам.
Ещё раз ссылку, к тому же там говорилось не только о ссылке.
То есть, вы согласны с тем, что не знаете C++? Отлично, наконец-то.
С чего вдруг? Я лишь доказал в том, что мой оппонент ваяет примитивное легаси-говно, при этом заявляя себя как эксперта и заявляя то, что хаскель может заменить С++. При этом, почему-то легаси-дерьмо ваяет на плюсах.
Тут явные проблемы с логикой и методичкой.
Аналогично: если вам не нравятся доказательства, то вопрос не к доказательствам, а к вам.
УБ нет. Аналогично: если вам не нравятся доказательства, то вопрос не к доказательствам, а к вам.
Основания.
Задача адепта предоставлять доказательства заинтересованности.
Вот этим всем.
Т.е. ничем?
Во первых у вас (множественное число) в комментах смешался хаскель и раст. Как раз судя по статье в хаскеле не обязательно (поправьте если что я хаскель не знаю) указывать ограничение на типы аргументов функций и он может вывести их в некоторых случаях сам, а в раст обязательно. Допустим в статье хаскель понял что аргумент должен быть Foldable + Ord + Num.
Во вторых для завтипов есть вопрос, что все ограничения наверное будет сложно перечислять явно и лучше иметь функционал авто вывода этих ограничений, разве не так?
А как сделать такое на хаскель: функция принимает какой то общий тип, но потом в теле функции надо вызвать нужную перегрузку другой функции в зависимости от типа изначального аргумента?
Ну я пишу в определении внешней функции тип B или тип C, или их общий тип А, а то из дискуссий не понятно как она работает, буду рад для общей картины чуть подробнее увидеть пример.
А как работают orphan rules/специализации? В расте с этим знаю есть определенные сложности.
А если это const generics? в расте к сожалению перегрузка по ним не работает.
Т.е. перегрузка не только по типу но и по какому-то значению типа factorial(3) сработает?
В расте ведь точно так же реализовано. into() и parse() например по результирующему типу подхватывают нужную функцию.
Например могу ли я сделать для аргумента равного 3 одну реализацию а для равного 10 другую если аргумент известен в компайл тайм и является результатом вычисления других функций? Вот это был вопрос.
Upd; даже не так, а еще для остальных n определить рекурсивно через 3 и 10 (например).
Но конкретно в хаскеле у вас (пока что) будет отдельная функция для рантайм-вычислений, и отдельная — для компилтайм (вернее, для вычислений во время тайпчекинга)
ну хотелось бы писать компайл тайм функции так же удобно как рантайм т.е. чтобы арифметические операции как обычно хотя бы были. Один из примеров это какой-то ручной unroll зависящий от каких-то констант и функций от них. Или пример навеянный докладом Александреску, у нас есть какие то структуры мы знаем их размер или другие характеристики далее хотим в зависимости от этого подогнать параметры quick sort т.е. сделать перегрузку функции сортировки.
Вообщем-то интересно разобратся как это все формализовать иначе какие-то одни обрывки.
Ну и собственно есть ли альтернатива тому как это сделано в С++ когда все разбирается по ходу дела?
Например с одной стороны мне нужно знать одно и то же Foo<f(10)> и Foo<g(3)> — я могу пойти вычислять это всё, но с другой стороны чтобы вычислить мне надо про тайпчекнуть f и g, а если внутри f или g есть какой-то Foo<?>, как избегать таких ситуаций?
Ну а с другой стороны если допустим я перенесу это на другой уровень и скажу ладно компайл тайм функции пишем через какие то стремные типы как сделано в typenum в расте через например тупли вида (1, (0, (1, 0))) = 10. Что это будет значить для этой надстройки над языком, будут ли там такие же такие гарантии как и в самом языке или мы в некотором смысле обходим тайпчекинг?
Речь не про длину данных, а про размер одного элемнта. Или например можно навесить аттрибут на тип про то насколько дорогая функция сравнения двух элементов. Но не так существенно для моего вопроса — я это детально не изучал.
Наткнулся кстати
Any language that provides some kind of pattern-matching on types (e.g., template specialization in C++) automatically introduces ad-hoc polymorphism. Ad-hoc polymorphism is also possible in Haskell through the use of type classes and type families.
https://bartoszmilewski.com/2014/09/22/parametricity-money-for-nothing-and-theorems-for-free/
С вашего позволения продолжу вопрос про перегрузки. Для конкретного типа (например Foo<int>, Foo<float>) понятно как делать специализацию потому что есть однозначность. Но в том что я имел ввиду про Foo<f(10)> и Foo<g(3)> — тут например конкретный тип не известен пока не вычислим f(10) и g(3). Или например перегрузка по неким трейтам ака enable_if. Я вижу проблему в том что как узнать какая имплементация более узкая а какая более широкая, как узнать могут ли эти множетсва одного instance и другого instance перекрываться. Как это проблема решается?
Upd. поправил код который съел хабр
Простая задача, самый базовый вариант https://godbolt.org/z/5F5mt9 — повторите.
Сорь, у вас там UB, поэтому эта программа может делать всё, что угодно, включая ничего.
Где? Почему лозунги я слышу, а оснований нет?
Так что я выбираю «ничего».
Читаю как "я не могу даже распарсить это, не что повторить". Я правильно прочитал?
Если вдруг кому-то ещё будет интересно, я с радостью напишу, но до той поры — попробуйте сами.
Сомневаюсь, если честно, что тов. selrorener будет что-то искать, а поучиться находить UB всегда полезно, так что буду признателен, если поясните, где оно здесь. С ходу не углядел, но у меня и опыта явно недостаточно.
Не уверен, что это здесь применимо, но попадалось упоминание, что uint8_t может определяться как синоним unsigned char. В этом случае тоже алиасинг помешает? char * же, насколько я помню, алиасить как раз можно с чем угодно? Понятно, что это будет опорой на конкретную реализацию в конкретном компиляторе, просто пытаюсь полнее понять происходящее.
upd: перечитал — кажется, дошло: по идее, если там на самом деле char — мы не можем его читать как uint16_t (но можно было бы наоборот).
правильный, но все же напишу. char, signed char и unsigned char — три разных типа, и алиасить может только первый.
Сходил тут недавно в цирк. Что-то меня накрыли флешбеки с клоунам, не знаю почему. Вроде тут их нет. А вдруг?
If a program attempts to access the stored value of an object through a glvalue of other than one of the
following types the behavior is undefined:58
(11.1)
— the dynamic type of the object,
(11.2)
— a cv-qualified version of the dynamic type of the object,
(11.3)
— a type similar (as defined in 7.3.5) to the dynamic type of the object,
(11.4)
— a type that is the signed or unsigned type corresponding to the dynamic type of the object,
(11.5)
— a type that is the signed or unsigned type corresponding to a cv-qualified version of the dynamic type
of the object,
(11.6)
— an aggregate or union type that includes one of the aforementioned types among its elements or non-
static data members (including, recursively, an element or non-static data member of a subaggregate or
contained union),
(11.7)
— a type that is a (possibly cv-qualified) base class type of the dynamic type of the object,
(11.8)
— a char, unsigned char, or std::byte type.
— a char, unsigned char, or std::byte type.
Ой, поломалось что-то? Ну бывает.
Cerberuser я жду оправданий, сомневатель.
Смотрим, как сектанты минусуют. Их брат по вере сел в лужу, они врали. Теперь же они пытаются просто минусовать неугодное.
я жду оправданий, сомневатель.
Оправданий не будет. Но благодарю за доставленное приятное удивление, предыдущие Ваши высказывания формировали существенно худшее мнение о Вас.
Ну я и не просил оправданий — я просил меньше веры (возможно?)братьям по вере.
А так я нашел терминальный пруф: enum class byte : unsigned char {}; На этом можно закончить с историей. Я и забыл про него. В целом и люди, которые работают с байтами и люди, которые пишут стандарт — знают как байты должны выглядеть. Наши мнения сошлись.
А на вторую часть (по идее, если там на самом деле char — мы не можем его читать как uint16_t (но можно было бы наоборот)) ответ будет?
Спасибо, что поправили (хотя удивлён, что вы сослались на стандарт — на него же всем плевать, включая вас).
Опять какие-то нелепые потуги. Мне на него плевать, но когда где-то какой-то клоун пытается что-то мне сообщать — я не против макнуть его в лужу при помощи стандарта.
А так, очевидно, мне на него насрать. А всякие клоуны ссылаются на стандарт только потому, что 1) ничего о нём не знают и надеяться на то, что никто там ничего искать не будет. И обычно никто не ищет, да и я бы не пошел искать. 2) ничего более ответить не могут.
Я дал задание — адепт не смог. Начались мазы. Адепт даже с мазами сел в лужу. Ничего нового.
Я не умею разрешимо пруфать наличие UB кодом, извините.
Пруфцевать нужно кодом не УБ, а балабольство про инлайнинг и разницы нет.
А УБ нужно пруфцевать стандартом и обоснованием, каким образом данный пример соотносится с процитированным(которого нет).
enum class U: T порождает тип, отличный от T, к слову.
Нет, в целом даже эти нелепые потуги не работают. Потому как стандарт явно декларирует эквивалетность std::byte и unsigned char.
К тому же, опять адепт позорится. Тип и тип данных — разные вещи. Опять же рассуждения того, кто ничего не понимает ни в матчасти, ни к крестах.
Ну и что-бы окончательно похоронить эту клоунаду:
For an enumeration whose underlying type is fixed, the values of the enumeration are the values of the
underlying type
Значение енума с типом unsigned char являются значением типа unsigned char по стандарту.
Вы, похоже, запутались, что вам нужно пруфцевать.
С чего вдруг?
Что выведет эта программа?
Зачем вы позоритесь? Я дал цитату из стандарта, где написано тоже, что говорю. А то, что вы нагуглили is_same — ничего не значит. Это разные категории типов. Советую почитать букварь по С++.
const int и int — тоже разные типы, но тип данных один. Тоже самое с, допустим, volatile.
А вот это странно, что aliasing не симметричный. Т.е. что угодно можно читать как char* но char* нельзя читать как что то другое. Скорее всего так сделано потому что не только алиасинг но еще и выравнивание. Хотя выравнивание зависит от платформы так что это неким общим документом боюсь не опишешь. Иначе у меня вопрос как писать SSE инструкции? Это скорее всего исключения типа char*.
Стираю. Попробуйте запустить эту функцию без аннотаций. Либо получить оригинальный тип. Вы не сделаете ни того ни другому. Потому как тип стёрт внутри функции.
Пожалуйста, используйте термины по назначению.
Стирание типов — это то, что происходит с параметрами дженериков в Java и с любыми типами в Typescript. А то, о чём пишете вы, называется как-то по-другому.
Давайте отделять мух от котлет т.е. прод от технологий и брать последний релиз компилятора за общий знаменатель.
auto fmap(auto f, auto v) {
return v | transform(f) | to<std::vector>();
}
Так и все же… какой тип-то будет у этой ф-ции? Что-то отличное от: any -> any -> any или этим все и ограничивается?
Так и все же… какой тип-то будет у этой ф-ции? Что-то отличное от: any -> any -> any или этим все и ограничивается?
У этой функции нет типа. Это множество функции, которые существуют только для типов удовлетворяющих её телу. Её не описать такими any -> any -> any примитивными сигнатурами. Этого недостаточно для выражения системы типов С++.
Каждая функция из множества сохраняет типы переданных в неё параметров(там есть кое какие нюансы, но это издержки лоулевел работы с памятью(и не только). Чего в том же хаскеле/f# и прочем — нет).
Допустим, в случае в случае https://godbolt.org/z/MAGPqV
Тип будет примерно следующим:
auto fmap(f:auto, v:auto) [
f:auto = boost::hana::placeholder_detail::plus_right<int>,
v:auto = ranges::experimental::shared_view<std::vector<int, std::allocator<int>>>
]Возвращаемое значение там не написано, но оно будет std::vector.
Это можно проверить так: https://godbolt.org/z/EnfTRJ
Если убрать конвертацию в вектор — будет так: https://godbolt.org/z/Bj9wca
void f(auto:16) [with auto:16 = ranges::transform_view<ranges::experimental::shared_view<std::vector<int> >, boost::hana::placeholder_detail::plus_right<int> >]
Если упростить — С++ для каждой возможной комбинации типов создаёт свой вариант программы. Таким образом типы никогда не затираются(если это не делается специально). Поэтому типичный для других языков подход с типом функции — для С++ не применим.
Каждый тип — это отдельная программа с уникальной логикой.
У этой функции нет типа. Это множество функции, которые существуют только для типов удовлетворяющих её телу. Её не описать такими any -> any -> any примитивными сигнатурами. Этого недостаточно для выражения системы типов С++.:-))) Честно говоря, я даже не знаю, что вам на это ответить. Вы просто не понимаете, о чем рассуждаете, или это просто такой тонкий троллинг? Не надо так…
Предположу, что вы просто не знакомы со «стрелочной нотацией». Так вот… «примитивный» тип any -> any -> any — ко всему прочему — включает в себя и любую ф-цию двух аргументов — внезапно, это тоже «множество» :-)
И тип этой fmap — в любом случае — можно описать как any -> any -> any. Вопрос в том, можно ли его описать, скажем так, чуть строже? :-)
P.S. Яж правильно понимаю, что «удовлетворяют её телу» наши аргументы или нет, можно узнать только на этапе компиляции?
Если я правильно понял, в той же многословной java это будет:
class Fmap {
static <A, B extends A> Collection<B> fmap(Function<A, B> f, Collection<A> a) {
return a.stream().map(f).collect(toList());
}
}
и из церемоний тут:
1. описание явной сигнатуры метода (да, громоздко)
2. обернуть все в класс и объявить как static (т.к. функций первого порядка нету, но есть статик импорты)
Без сомнения, у хаскеля система типов мощнее и кода пишется меньше. Но сложность этого кода для понимания на порядок выше. Учитывая, что программист тратит 60-80% времени на чтение кода, в случае со столь сложной системой типов необходимо приложить колоссальные усилия, чтобы разобрать пусть небольшой но невероятно сложный код. С точки зрения поддержки и командной работы над проектом – вся команда должна будет состоять из очень одаренных людей. Увы, таких людей очень мало.
Кстати, та же декларация на TypeScript:
const fmap = <A, B extends A>(f: (A) => B, a: Array<A>): Array<B> => a.map(f);
И на JS:
const fmap = (f, a) => a.map(f);
Верно. Правда, в данном конкретном случае вы написали конкретно для списка, а код выше работает для любых маппящихся вещей (см. F<A> вместо Collection<A>).
Кстати я не уверен, что часть с B extends A — верна.
Без сомнения, у хаскеля система типов мощнее и кода пишется меньше. Но сложность этого кода для понимания на порядок выше. Учитывая, что программист тратит 60-80% времени на чтение кода, в случае со столь сложной системой типов необходимо приложить колоссальные усилия, чтобы разобрать пусть небольшой но невероятно сложный код. С точки зрения поддержки и командной работы над проектом – вся команда должна будет состоять из очень одаренных людей. Увы, таких людей очень мало.
Да нет там никаких "на порядок выше". Не считая немного странного для стороннего наблюдателя ML-синтаксис всё предельно просто. Концепции там сильно проще, чем какой-нибудь сборник банды четырех, которую в ООП мире считают мастхевом. Гением как раз надо быть, чтобы без сигнатур во всем разобраться. Я вот — не могу, мне нужно чтобы комплиятор мне подсказывал: что я могу делать с некоторыми структурами, что не могу, что они умеют, а чего — нет.
А сигнатуры которые дают больше информации как раз читать проще, чем те, которые её не дают. В вашем примере я из
const fmap = <A, B extends A>(f: (A) => B, a: Array<A>): Array<B>
=> 1000 строк нечитаемого кодаМогу понять намного больше, чем из
const fmap = (f, a)
=> 1000 строк нечитаемого кодаМогу понять намного больше, чем из
Что врядли сильно сигнатура поможет понять, что делается в «1000 строк нечитаемого кода». Ладно бы 10, 100, но в 1000 строк наверняка попутно делается намного больше из заявленного сигнатурой. Т.е. если Вы напишете свою реализацию в 10 строк, то наверняка она не будет обладать тем же поведением, что и 1000 строк (всякие побочные действия)
Ибо 1000 строк простыни — это почти всегда очень дурно.
Что врядли сильно сигнатура поможет понять, что делается в «1000 строк нечитаемого кода».
В хороших системах типов — кроме сигнатуры больше ничего не надо. Собственно это товарищ 0xd34df00d и показывал в статье.
Но даже с учетом дичи которую может делать функция в ТС это намного проще.
Ладно бы 10, 100, но в 1000 строк наверняка попутно делается намного больше из заявленного сигнатурой. Т.е. если Вы напишете свою реализацию в 10 строк, то наверняка она не будет обладать тем же поведением, что и 1000 строк (всякие побочные действия)
Да не, можно же написать чистую функцию в тыщу строк. Ну да, она будет сложная, но и что?
Ибо 1000 строк простыни — это почти всегда очень дурно.
Понятно же, что это пример. Ну пусть будет 50 или 100, это же непринципиально. Вопрос в одном — могу ли я прочитав одну строчку понять всё, что мне нужно знать о функции, или мне надо лезть и смотреть что же на самом деле она делает.
Вопрос в том, что в ФП "что" и "как" — разделены. Вы можете знать "что" совершенно не зная "как". В динамике всё наоборот, вы не знаете ничего, и чтоб понять "что" нужно прочитать "как".
В мейнстрим статических языках что-то среднее. Но я бы не сказал что это золотая середина, скорее ни рыба, ни мясо.
Т.е. принцип «код делает только то, что понятно по сигнатуре» и простыня на 1000 строк — практически несовместимы.
Хорошо, пусть будет в вашем примере не 1000 непонятных строк, а 5 *очень* непонятных строк с черной магией и прочим.
Что-то видимо у меня не получилось донести ту мысль, что в сигнатуре очень мало информации для столь огромного количества строк кода, и этот код наверняка делает много больше заявленного, либо не делает ничего (индусский код).
Почитайте статью что я скинул. У вас НЕТ способа сделать ничего кроме заявленного, ни в тыщу, ни в миллион строк. Если система типов достаточно нормальная, конечно. И вполне хватает мейнстрим языков (та же скала или раст), где это выполняется точно, и есть чуть менее сильные языки (C#/Java/TS), где это почти наверняка так.
Например, приведенный код точно не делает никаких асинхронных запросов, потому что тогда бы результат был завернут в промис. Нет, конечно, можно :) Но такие вещи должны запрещаться линтером просто, поэтому кейс "мы заблокировались на асинхронном вызове" предлагаю не расматривать.
Т.е. принцип «код делает только то, что понятно по сигнатуре» и простыня на 1000 строк — практически несовместимы.
Я могу показать вам вполне чистую функцию на тыщу строк легко. Первая на 300 не очень информативна (потому что делает IO), но вот вторая — получше: https://github.com/Pzixel/Solidity.Roslyn/blob/master/Solidity.Roslyn/SolidityGenerator.cs#L342
Она вполне себе чистая и делает только то, что заявлено — принимает аргументы и гененирует соответствующий MethodDeclarationSyntax
Ну так посмотри на доку любой JS/python либы там идет описание на пару строчек а дальше перечисление какого типа какой аргумент. А зачем так делать если это можно написать в сигнатуре и автоматом получить проверку аргументов на соответствие нужным типам и дополнительные подсказки компилятору для оптимизаций.
Может дело в том, что обычно дискуссии идут не в области чистой теории, а применительно к конкретным задачам, коммерческим и близким к ним, где не к мейнстрим языкам отношение, скажем так, предвзятое, где первый вопрос к предложению сменить язык "где мы возьмём специалистов и сколько они будут стоить?"
Церемонии JS — это одна строчка с именем функции и аргументов, мы ведь специально не рассматриваем тело. Если можно это упростить, то, пожалуйста, покажите как.
var consume = function (source, quantity) {
if (!source) {
return [];
}
if (quantity <= 0) {
return source;
}
var first = source.shift();
return consume(source, quantity - first);
}
Но ведь строка var consume = function (source, quantity) {, а всё остальное (серое) мы не сравниваем, потому что у автора не было цели оптимально реализовать функцию, более того, он прямо пишет "я не особо пишу на ЖС и точно можно лучше".
Один из вариантов более симпатичного тела функции:
var consume = function (source, quantity) {
let s = 0;
const index = source.findIndex(x => (s += x) >= quantity);
return index < 0 ? [] : source.slice(index + 1);
}Взяли и заквадратили алгоритм… Не надо так делать, пожалуйста!
И да вся история про «автовывод типов» очень хороша, когда у вас под рукой инструмент, который вам если что подскажет какой тип у данного выражения, но когда вы смотрите код на каком-нибудь гитхабе, то бывает очень «весело» угадывать этот самый тип.
Что опять складывание чисел?
Ну предложите что-то другое. Я вон деревья грузил по ресту — тоже мне говорили что задача не та.
И опять игнорируют тот факт, что за «магией» скрывается нетвиальная мат теория, которую следует знать, потому что очень быстро можно столкнуться с «ой, а почему тут за меня не вывели тип? а что надо было явно указывать?».
Какую мат. теорию нужно учить для правила "если тип не вывелся (хотя у меня такое только в скале было, причем это как раз вызвано тем, что язык поддерживает ООП сабтайпинг) — то написать его руками"?
И да вся история про «автовывод типов» очень хороша, когда у вас под рукой инструмент, который вам если что подскажет какой тип у данного выражения, но когда вы смотрите код на каком-нибудь гитхабе, то бывает очень «весело» угадывать этот самый тип.
Когда вы читаете код на гитхабе, то вам обычно достаточно понимать общий принцип того, что происходит, если вы смотрите чужую репу. Если вы смотрите PR в собственном проекте, то обычно дифф не превышает несколько сотен строк кода, и их типы держать в голове вполне можно, тем более, что обычно они очевидны из названий переменных и функций которые над ними работают.
Ну и в любом случае информации не меньше, чем в PR в JavaScript репозитории.
Что до трейдофов, то между удобством людей которые читают в код в гитхабе и людьми которые читают код в IDE предпочтение стоит отдавать вторым. Если у вас типы помогают читать код в гитхабе, но в IDE только мешают — лучше бы их не писать.
Так на, например, тайпскрипт переходят для того, чтобы код был лучше чем на джаваскрипте. И даже если тайпскрипт и ИДЕ тип могут вывести, то он может оказаться семиэтажным и нечитаемым совсем.
Самое забавное, что когда начинают типизировать уже существующие динамические апи, то все их косяки начинают просто вопиюще выпирать. Ну например, надо было мне небольшой сервис на ноде запилить, и мне нужно было использовать fetch API. Ну не вопрос, только мне нужно было авторизационный токен пропихнуть. Ну ок, иду, смотрю как в хедеры значение добавить а там:
type HeadersInit = Headers | string[][] | Record<string, string>;
interface Headers {
append(name: string, value: string): void;
delete(name: string): void;
get(name: string): string | null;
has(name: string): boolean;
set(name: string, value: string): void;
forEach(callbackfn: (value: string, key: string, parent: Headers) => void, thisArg?: any): void;
}То есть хэдеры — это либо просто мапа стринги на стрингу, либо двумерный массив, либо вообще объект со своими методами. Или вот моё любимое:
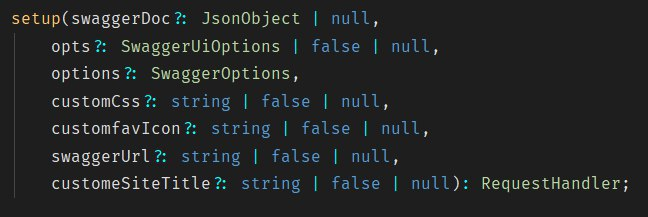
Тип поля: string | false | null. Не bool, а false. Вот такие вот завтипы.
Такую наркоманию в типизированном языке никогда бы не сделали. А когда типы неявные и подразумеваются, получается вот так.
Тип поля:string | false | null. Неbool, аfalse. Вот такие вот завтипы.
А что не так? значение | не используется | не указан. Абсолютно адекватный, понятный тип, написанный здоровым человеком, понимающим суть вещей и без идолопоклонничества в голове.
Ну, "не указан" лучше бы было как undefined указывать, тем более что внутри эти параметры всё равно в string | false | null | undefined превращаются из-за своей опциональности.
"не указан" лучше бы было как undefined указыватьАбсолютно не согласен. «Не указан» в данном контексте — это пустой, null, void, если хотите. Ну и, кроме того, в здоровом API, которому не нужен специальный клиент на JS, — undefined немного не в чести.
Обратите внимание на "вопросики": эти параметры можно реально не указать, и тогда там будет undefined. Зачем тут ещё и null?
«Не указан» в данном контексте — это пустой, null
А false тогда что означает? :-)
- false означает «указан, игнорировать», как я написал в первом комментарии;
- null означает «указан, значение: пусто» (nullnull — означает дубль пусто-пусто. Кхм. Простите :)
- string означает «указан, вот значение»;
- отсутствие параметра означает «не указан».
Вас послушать, так там все 3 случая обрабатываются по-разному, хотя на самом деле значения false, null, undefined и даже пустая строка означают одно и то же.
То есть хэдеры — это либо просто мапа стринги на стрингу, либо двумерный массив, либо вообще объект со своими методами.
Не всё так плохо :-)
Хэдеры — это всегда объект со своими методами, но в некоторые места API для простоты можно передать мапу или двумерный массив.
Вполне нормально для API, написанного исходя из удобства использования, а не удобства реализации.
API, написанного исходя из удобства использования, а не удобства реализации
Угу. Вообще, за API, написанные, исходя их удобства реализации / сопровождения — надо гнать мокрыми тряпками из профессии.
И где тут простота использования? Мне пришел вот такой объект, и мне теперь нужно паттерн матчиться, чтобы понять, то ли мне массив создавать, то ли в мапу добавлять, то ли метод append дергать. Ну вот из моего кода:
export class BaseClient {
private configuration: ClientConfiguration;
constructor(configuration: ClientConfiguration) {
this.configuration = configuration;
}
protected transformOptions(options: RequestInit): Promise<RequestInit> {
const headersToInsert = [["Authorization", this.configuration.bearer]];
// ???
return Promise.resolve(options);
}
}Вот как мне теперь вставить этот хэдер? Нужно проверить все варианты что за RequestInit и действовать соответствующе. При чем тут удобство реализации? Этим пользоваться неудобно.
Код выше — это реализация. Пользоваться этим будет тот, у кого есть объект типа BaseClient.
В моем случае наследники это генереные тулзой классы, которые по сваггеру генерируются. И они могут мне подсунуть один из трех вариантов в transformOptions.
Но это мало на что влияет. Я должен написать код в знаках вопрос не делая предположений о том, как меня будут использовать. Код просто должен всегда корректно отрабатывать, для этого нужно обработать 3 возможных варианта.
Ну да. Не вижу вообще никаких проблем. Ваш код — это, очевидно, имплементация. Которая должна делать максимально хорошо вызывающему коду. Насколько вам будет сложно это реализовать — это не проблема шерифа.
Вы когда-нибудь библиотеки общего назначения писали? Они внутри могут быть сколь угодно громоздкими, но должны обеспечить комфорт для вызывающего кода. Чтобы там не приходилось из файла в файл копипастить приведение списка строк к объекту и т. п. Что есть — то в интерфейс и засунул.
В чем тут комфорт-то? Вот в сишарпе хэдеры это просто Map. Какие проблемы из-за этого могут возникнуть? Чем такой интерфейс удобнее?
Ваш код — это, очевидно, имплементация. Которая должна делать максимально хорошо вызывающему коду. Насколько вам будет сложно это реализовать — это не проблема шерифа.
Видимо проблема в том, что у меня 50% кода — имлементация, и 50% — использование таких имплементаций.
Чем такой интерфейс удобнее?
Понятия не имею. Наверное, тем, что этот setup вызывается из мест, где хедеры — это список строк.
Вот в сишарпе хэдеры это просто Map.
Высокоуровневая HTTP имплементация в корке языка (если это действительно так, лень ходить проверять) — это уже ужасное архитектурное решение, тут даже говорить дальше не о чем.
Понятия не имею. Наверное, тем, что этот setup вызывается из мест, где хедеры — это список строк.
Если нет примеров, где это удобнее, но есть примеры, где неудобно (я вам один уже показал), то так делать не надо.
Высокоуровневая HTTP имплементация в корке языка (если это действительно так, лень ходить проверять) — это уже ужасное архитектурное решение, тут даже говорить дальше не о чем.
Что тут высокоуровневого? Это просто набор ключей и значений.
У меня нет примеров, потому что мне неохота смотреть в исходный код на нелюбимом языке. У авторов, я уверен, их есть вагон и маленькая тележка.
Что тут высокоуровневого?
Как бы Map — это прямо очень высокий уровень для HTTP протокола.
У меня нет примеров, потому что мне неохота смотреть в исходный код на нелюбимом языке. У авторов, я уверен, их есть вагон и маленькая тележка.
Зачем лезть? Вы можете придумать кейс где двумерный массив лучше? Или где хоть одна из функция интерфейса Headers удобнее обычной хэшмапы?
Как бы Map — это прямо очень высокий уровень для HTTP протокола.
Речь не про HTTP протокол, а про одну из его частей — заголовки.
Так вот заголовки — это буквально набор ключей-значений, по спецификации. А наборы ключей-значений в языках представляются обычно хэшмапами. Ну или каким-то другим типом данных со схожими свойствами. Одним типом, а не тремя разными.
Вот как раз генерённые тулзой классы — самое то место, где надо бы преобразовать HeadersInit в Headers. Если тулза этого не делает — ну, такая тулза :-(
Но, вообще говоря, преобразование-то довольно простое выходит:
protected transformOptions(options: RequestInit):Promise<RequestInit>
{
const headers = new Headers(options.headers);
headers.set("Authorization", this.configuration.bearer);
return Promise.resolve({ ...options, headers });
}Ну, если программисты на Javascript как-то справляются вообще без статических типов, то и хаскелисты как-нибудь на гитхабе код посмотреть смогут...
Тут описаны не те церемонии, которые и правда раздражают.
Вот то что раздражает даже C#-программистов:
public interface IRequest
{
Guid Id { get; }
Guid AuthorityId { get; }
Guid UserId { get; }
// ещё 30 свойств
}
public class Request : IRequest
{
public Guid Id { get; set; }
public Guid AuthorityId { get; set; }
public Guid UserId { get; set; }
// ещё 30 свойств
public Request(IRequest other)
{
Id = other.Id;
AuthorityId = other.AuthorityId;
UserId = other.UserId;
// ещё 30 присваиваний
}
}
public class ImmutableRequest : IRequest
{
public Guid Id { get; }
public Guid AuthorityId { get; }
public Guid UserId { get; }
// ещё 30 свойств
public ImmutableRequest(IRequest other)
{
Id = other.Id;
AuthorityId = other.AuthorityId;
UserId = other.UserId;
// ещё 30 присваиваний
}
}Ну, это уже к автору оригинальной заметки. То, что вы говорите, это скорее от недостатка мощности системы типов. То есть убрать церемонии в сишарпе как в вшарпе например можно, а вот сделать такую штуку не получится, по крайней мере в языке её мы вряд ли дождемся.
С другой стороны обычно такие вещи решаются макросами, в сишарпе это анализатор на рослине, соответственно, который во время сборки будет по IRequest генерировать соответствующие классы. Примерно так:
public interface IRequest
{
Guid Id { get; }
Guid AuthorityId { get; }
Guid UserId { get; }
// ещё 30 свойств
}
[Implement(typeof(IRequest), readonly: false)]
public partial class Request
{
}
[Implement(typeof(IRequest), readonly: true)]
public partial class ImmutableRequest
{
}То, что неизменяемость — свойство типа а не биндинга, это конечно печально.
При первоначальном наполнении здорово облегчает жизнь ctorp от решарпера, хотя добавить ещё одно поле всё равно придётся руками.
Та причина по которой я накатал себе генератор кода. С partial классами заходит на ура.
"Но на самом деле всё еще хуже. Код выше работает только с int массивами. А что, если мы хотим использовать long?
Нам придется написать еще одну перегрузку:"
Как бы шарпы в дженерики умеют
Ловко автор всех обманул
И какой дженерик вам позволит написать сложение произвольных чисел? Можно пример? И почему разработчики STD либы такие глупые что не сделали этого?

Невнимательно прочитал всю задачу, прошу прощения.
Потому что в отличие от того же раста, где оператор это просто сахар для вызова метода интерфейса, в шарпах операторы это такие статические хрени висящие сбоку. А к статическим методам интерфейс написать нельзя.
А так работает
public static IEnumerable<T> Consume<T>(this IEnumerable<T> source, dynamic quantity) {
if(source == null) yield break;
dynamic accumulator = 0;
foreach(T i in source) {
if(quantity <= accumulator) {
yield return i;
}
accumulator += i;
}
}Не похоже:
var result = new[] {1,2,3}.Consume("Hello").ToArray()
// RuntimeBinderException: Operator '<=' cannot be applied to operands of type 'string' and 'int'а что ожидалось?
Что компилятор скажет что тут происходит дикость и не даст скомпилировать.
Nullable кстати тоже не будут корректно отрабатывать.
Ну если определить соответствующие операторы для string и int то такой код может быть корректным, а так конечно это не в ту сторону по шкале движение, в том смысле что статический контроль типов наоборот подавлен dynamic, там можно еще поиграть, например обявить T quantity, тогда ваш пример будет падать уже при компиляции, не знаю можно ли в с# как то форсировать проверку наличия оператора для дженерик типа..., так это переносится в рантайм.
Но я не хочу подавлять контроль типов.
Ни в одном серьезном проекте на сишарпе новее 2010 года вы dynamic не встретите. Это фича сдлеанные давным давно для совместимости с COM и грудами легаси. Во многих проектах он просто под запретом.
Вынос проблем в рантайм — это не решение.
Ну если определить соответствующие операторы для string и int то такой код может быть корректным
Но я не могу залезть в std и добавить операторы для string и int. Да и даже если бы мог, я бы такой оператор писать не стал — какая для него логика должна быть? Никакого разумного в голову не лезет.
не знаю можно ли в с# как то форсировать проверку наличия оператора для дженерик типа..., так это переносится в рантайм.
В этом и суть — что никак. А в языках с более мощными системами типов (Rust/Haskell/F#/Scala) — можно.
Все равно автор неправ для целых типов можно не делать полные перегрузки, как в статье.
public static IEnumerable<T> Consume<T>(this IEnumerable<T> source, T quantity) where T : IConvertible {
if(source == null) yield break;
long accumulator = 0;
long qLong = Convert.ToInt64(quantity);
foreach(T i in source) {
if(qLong <= accumulator) {
yield return i;
}
accumulator += Convert.ToInt64(i);
}
}Наверно можно написать и более "дженерик вариант", если еще потребовать от T поддержку IComparable и использовать достаточно широкий аккумулятор, чтоб не попасть на переполнение или потерю точности, впрочем с плавающей точкой это не решается и в "правильном" варианте, надо знать что там внутри у метода
Ну интерфейс IConvertible вообще отвратительный, половина методов просто бросают исключения:
var result = new ulong[] {ulong.MaxValue}.Consume(1UL).ToArray();
var result2 = new double[] {((double) long.MaxValue) + 1}.Consume(1UL).ToArray();
var result3 = new string[] {"Hello"}.Consume("World").ToArray();Ну нет в языке способа сказать "есть операция сложения". Можно придумать что-то достаточно хорошее, что особо не будет ломаться, но единственный способ сделать всегда рабочую функцию — пойти её копипастить. Что и сделано в std.
Сделать на стороне компилятора исключение для этого кейса не кажется сложным.
Интересно, в чем все таки причина отсутствия соответствующей функциональности? Банальное неуважение разработчиков языка к своим пользователям? Или объективные причины?
Скорее всего
- сначала не подумали
- потом было поздно (ломать обратную совместимость)
В C# 10-11 сделают наконец тайпклассы, тогда это всё сделать будет можно.
Мне кажется то некоторое количество избыточного кода добавляет читаемости и лёгкости понимания. Правильный баланс сложно найти, особенно индивидуальный. В том же хаскеле написать можно изящную конструкцую, но прочитать её изящно очень сложно, даже автору, особенно через пару месяцев после написания.
ИМХО лучше иметь возможность написать изящную конструкцию, чем не иметь. С тезисом что разработчика нужно заставить много писать и страдать, что он пока пишет понял, что он делает — я не согласен (хотя есть люди которые так считают).
Если есть простой способ что-то сделать и сложный — лучше сделать просто. Но если есть способ сделать что-то используя абстракцию (например, итератор), и не используя (руками расписать все циклы), то почти всегда первый — лучше. Хотя, опять же, некоторые считают иначе, но есть авторы которые со мной согласны.
Во-первых потому что это оригинальный значок сишарпа который рекомендуется использовать когда можно
The name "C sharp" was inspired from musical notation where a sharp indicates that the written note should be made a half-step higher in pitch. This is similar to the language name of C++, where "++" indicates that a variable should be incremented by 1. The sharp symbol also resembles a ligature of four "+" symbols (in a two-by-two grid), further implying that the language is an increment of C++.
Due to technical limitations of display (standard fonts, browsers, etc.) and the fact that the sharp symbol (♯, U+266F, MUSIC SHARP SIGN) is not present on the standard keyboard, the number sign (#, U+0023, NUMBER SIGN) was chosen to represent the sharp symbol in the written name of the programming language. This convention is reflected in the ECMA-334 C# Language Specification. However, when it is practical to do so (for example, in advertising or in box art), Microsoft uses the intended musical symbol.
Во-вторых парсер хабра в режиме markdown (а я всегда пишу в нем) считает решетки началом заголовка и съедает их.
Статья подразумевает, что церемонии, это плохо. Но разве это так? Вот цитата которая однажды мне понравилась. Правда, она про другое, но мораль та же самая:
– Храбрость без ритуала ведёт к бунту. Правдивость без ритуала ведёт к грубости. Верность без ритуала ведёт к подхалимству, – ответил Учитель...
Вот цитата которая однажды мне понравилась.
Да, но цитата про баланс. Так же и тут. Церемонии важны, но важны не сами по себе, а когда они часть чего-то большего. Если их можно пропустить ничего не потеряв — это благо. Жаль учитель не сказал про ритуал без наполнения. Но там всё тоже самое.
Но разве это так?Да.
Необходимость исполнять ритуалы вполне может привести и к бунту, и к грубости.
С другой стороны, отсутствие «церемоний» — не всегда хорошо. Явное указание типов в интерфейсе является single source of truth: по нему можно сразу определить, что неправильно — реализация функции или ее использование. Вот например:
let add a b = a + b
printf "%A" (add 1 2)
printf "%A" (add "a" "b")
In the face of ambiguity, refuse the temptation to guess.
Ну в фшарпе компилятор немного глуповат, да.
В хаскелле он верно все выводит. Но в хаскелле вторая строка не сработает потому что для строк не определен +, конкатенация там — отдельная операция.
С другой стороны, отсутствие «церемоний» — не всегда хорошо.
Это правда. Но суть скорее была показать, что они как правило необязательны. Хотя, как выше я уже комментировал, я предпочитаю всегда декларировать топ левел функции. Занимает это времени чуть, зато компилятор после этого становится другом, а не гадалкой пытающейся оказать медвежью услугу.
Ну в фшарпе компилятор немного глуповат, да.
Он пытается соответствать рантайму, который ожидает генерик функцию. Но в рантайме такого констрейна на генерик типы нет, поэтому в такой записи компилятор выведет не генерик тип, а конкретный по первому использованию.
Но если использовать SRTP, то можно юзать констрейны, которых в рантайме нет, но такие функции не могут доехать до рантайма, поэтому их надо инлайнить.
let inline add x y = x + y
И все заработает.
PS
Так выглядит полностью динамический но при этом типизированный код на TS )
type Document = any
type Result = any
public async reduce(
filter: (doc: Document) => boolean,
reducer: (doc: Document, result: Result) => void,
result: Result
): Promise<Result> {
...Для энтерпрайза самый красивый язык, по моему мнению.
В сравнении с чем? Со скалой? F♯? erlang? go? COBOL? Haskell? Idris? Agda?
У вас интересный выбор энтерпрайз-языков, особенно Go, Idris и Agda.
если забыть про многопоточность и много чего еще
Разбор динамического Json — это восемь часов на написание библиотеки (если 100500 существующих почему-то не подошли) и MyJson.parse везде после этого. Какое это отношение имеет к энтерпрайзу, где без многопоточности и много чего еще — вообще шагу не ступить в современном мире, не очень понятно.
Спасибо, рад, что нравится.
Что до TypeScript — то с ним действительно довольно приятно работать. Хейлсберг — большой молодец
Так выглядит полностью динамический но при этом типизированный код на TS )
Ну, откровенного говоря не особо это типизированно. Мне вот в Express еще такое понравилось, так сказать, интерфейс "что-то с чем-то".
interface MyInerface {
[key: any]: any;
}2. Если не хочется церемоний c классами, ничто не мешает писать что-то вроде:
var myObject = new MyClass() { name = "Имя", id = 1 };Или даже:
var myObject = ( name: "Имя", id: 1 );Получается странный парадокс. Сначала одни программисты принимают правило, что везде нужны интерфейсы, конструкторы, жеттеры, сеттеры и прочие формальности ООП а потом другие программисты пугаются лишнего кода.
Вопрос — насколько часто приходится делать подобного уровня абстракции функции для чисел?
А они и не для чисел. Ну самый жизненный пример — хотел бы я иметь такой интерфейс:
interface IParseable<T> {
static T Parse(string text);
}А его сделать нельзя. А вот эта штука мне бы везде пригодилась, где Json/Xml/… у меня используются.
Поэтому если вопрос "часто ли нужны тайпклассы" — да, часто.
Если не хочется церемоний c классами, ничто не мешает писать что-то вроде:
Не понял, тут вроде церемоний ровно столько же
Или даже:
Вопрос только дальше, что с этим делать. Чтобы вернуть его из функции (и не потерять информацию) придется всё это описывать в сигнатуре. И тогда получаются такие вот хрени:
private static (string name, int id) GetMyObject() {
return ( name: "Имя", id: 1 );
}И тогда получаются такие вот хрени:Честно признаться, в длинных и нудных прикладных алгоритмах, с которыми я обычно работаю, я так и делаю:
private static (string name, int value) GetSomeResult() {
return ("Имя", 1 );
}Если класс нужен только в одном месте кода, достаточно «описать» его один раз в сигнатуре функции. Если позже оказалось что описание нужно повторять, тогда заменяю на класс (или структуру), в котором только public поля без конструкторов, жеттеров, сеттеров.
Я к тому, что по ничто не мешает писать на C# в стиле близком к минимальному, как в JS.
Сути проблемы с IParseable не понял, но бог с ней.
Программист сначала пишет типы, а по типам соответствующая им программа генерируется полуавтоматически.
Ведь типизация — это всего лишь система ограничений, причем чем жестче мы хотим ограничить наши компоненты (strong cohesion и все такое), тем гибче и сложнее должны быть ограничивающие механизмы, чтобы каждого ограничить точно по фигуре (тайпклассы, завтипы и т.д.).
Это действительно почти всегда так, но это, на мой взгляд, неверный подход.
Выше я писал про С++ и про то, чем он отличается от привычного во всех остальных языках(мб там за исключением пары) подхода. В С++ типизация нужна для консистентности, а не для ограничений.
Т.е. С++ предполагает подход, в котором код пишется по-сути динамически, но каждый когда ему нужно и как он хочет описывает требования. И язык следит за тем, что-бы нигде не возникало противоречий.
От части на уровне выше типизация для того и нужна — для консистентности. Просто обычно контекстом является какая-то одна функция, а не программа в целом. И этого невидно.
При этом мы исходим из гипотезы, что чем жестче ограничен каждый компонент, тем надежнее система в целом.
Поэтому не обязательно исходить из этой гипотезы. Зачастую, как я уже говорил выше, все подобные тезисы являются обманом. Попыткой скрыть тот факт, что язык и его система типов не может работать без "ограничений на каждый компонент".
Типы — они всегда для пользователя. Компилятору и так норм. Собственно, когда приходит понимание, что типы пишутся для того чтобы их читать, а не для того чтобы компилятор отвял (или там соптимизировал что-то), тогда и познается дзен.
Собственно, пока писал портянку — появились именно те тезисы, о которых я говорил. Люди живут в своём мире, другом. Не в том, в котором живут статические языки(хотя их почти нет).
Эти люди не понимают, что типы это не только "у меня тут any — хочу ограничить тип "для пользователя"". Типы — это такая же логика, как a + b. И пишется она в первую очередь для компилятора, как и обычная логика. А уже далее появляются какие-то пользователи. Если код не реализует нужную логику — абсолютно неважно то, насколько он читаем. И типы — это такой же код, но только НЕ в языках с описательной типизацией.
но насколько понимаю, в языках без рантайма типы изначально вводились для необходимости знать точный размер данных на этапе компиляции, а совсем не для безопасности, выразительности, и т.д.
Ну примерно так. Хотя в том же си почти не было типов изначально. Просто везде по умолчанию инт, а потом уже к этому прикрутили аннотации типовые. В основном типы — это агрегаты.
Поэтому типы именно как типы появились в статических языках в связи с необходимостью. Параллельно существовала скриптуха, но у неё был рантайм и типы там не нужны особо.
Далее в скриптуху начали пихать что угодно, назвав это статический типизацией. Хотя её там нет, очевидно. Почти все проблемы типизации в скриптухи решал и решает динамический диспатч, который для статического языка попросту не применим.
От этого в статических языках типизация не особо развилась, чем и воспользовалась скриптуха. Но не развивалась она в силу своей природы, как я уже говорил выше. В сишке же дыры в типизации затыкались руками, на что до сих пор последователи скриптухи триггерятся. Не понятия, что никакой разницы нет.
Но а если обобщить, то даже там это всё имело то же назначение — согласованность. А так же, что очевидно, диспатч операции по типу.
Если эти вещи четко разделить — типы для компилятора и типы для пользователя — тогда, похоже, половины кровавых споров можно избежать.
Ну да, поэтому я уже давно выступаю за то, что "статическая типизация" несостоятельное понятие. Сейчас это уже понятно многим, когда "статическая типизация" пошла в пхп/js/python. Просто нужно понимать, что какая-то типизация прикрученная поверх рантайм-типизации не является статической, хоть так и называется.
Я предлагаю называть такую типизацию описательной. Она может вообще никак не влиять на логику, а может влиять. Ключевое тут то, что определяющим является рантайм, а не типы.
Статическая же типизация в статическом же ЯП предполагает обратное. Вся логика определяется типами, т.е. не существует такой ситуации, когда для какого-либо объекта не определён однозначно его тип. При этом никакие сумтипы и прочее типами не являются и являться не могут. Так же, здесь так же могут быть опциональные включения описательной типизации.
И здесь сразу становится понятно почему появляются тезисы "типы для безопасности" и прочее. Они берутся именно из описательной типизации. И проблема в том, что её адепты никогда отпустят своё первородство.
Поэтому мы и можем видеть всякие совсем нелепые тезисы. Допустим "С++ не может вывести тип". Откуда такой тезис относительно статического языка, в котором тип попросту не может не вывестись? Правильно, из логики описательной типизации.
Вот мы и получаем. Эти люди сами себя объявили евангелистами типизации, назначили себя судьями. Начинают кидаться лозунгами вида "если не как у нас — то никак". Выучили пару базвордов и кнопку "минус". Вот и организуют набеги, вместо аргументации.
В очередной раз спорить я начинаю. Последователи фп-первородства набегают, аргументация их хромает, декларации их слабы. Аргументы кончаются — начинаются набеги.
Посмотрим, ответит ли очередной С++-эксперт за "не может", либо опять растворится в тумане, перейдя в другую статье кидать тезисы "не может".
Это проблема, наличие крайне религиозным, агрессивных последователей "истины" от типизации. Кровавых споров же на тему типизации вне набегом этих последователей — я не видел.
Статическая же типизация в статическом же ЯП предполагает обратное. Вся логика определяется типами, т.е. не существует такой ситуации, когда для какого-либо объекта не определён однозначно его тип. При этом никакие сумтипы и прочее типами не являются и являться не могут. Так же, здесь так же могут быть опциональные включения описательной типизации.
Уж простите что влезаю в ваш разговор. Но что тогда для вас тип? Можете дать определение со своей стороны?
Но что тогда для вас тип? Можете дать определение со своей стороны?
Я бы не сказал, что тип вообще требует какого-либо определения в том плане, в котором его обычно определяют. Тип — это просто какой-то идентификатор. Всё. Далее на него каким-либо образом, прямо или косвенно — навешиваются всякие свойства. Далее каждый объект аннотируется этим идентификатором, тем самым объект наследует свойства типа.
На самом деле каждый объект можно наделять свойствами отдельно, а сама типизация просто некое развитие. Общие свойства множества объектов выносятся отдельно и им даётся имя/идентифактор. Это просто упрощает определение нового объекта с аналогичным набором свойств.
А далее уже появляется какая-то логика работы с этими свойствами. Классификация и прочее.
Я бы не сказал, что тип вообще требует какого-либо определения в том плане, в котором его обычно определяют.
К сожалению, требует. Иначе будет непонятно, о чём мы с вами говорим. И непонятно, какие сущности языка считать типами, а какие — нет.
Тип — это просто какой-то идентификатор. Всё.
Согласно вашему определению, в выражении int foo = 0; типами можно назвать и int, и foo. Но это ведь не так, правда?
Далее на него каким-либо образом, прямо или косвенно — навешиваются всякие свойства.
Вот тут уже интересней. Что это за свойства, откуда они берутся?
Если я понял вас правильно, то int вы типом считаете — исходя из вот этой вашей фразы:
Ну примерно так. Хотя в том же си почти не было типов изначально. Просто везде по умолчанию инт, а потом уже к этому прикрутили аннотации типовые.
Какие у этого типа будут свойства? Или, если это не тип, что это тогда?
Далее каждый объект аннотируется этим идентификатором, тем самым объект наследует свойства типа.
А тут мы с вами должны дать определение объекту и процессу наследования. Может, пока остановимся на типах?
На самом деле каждый объект можно наделять свойствами отдельно, а сама типизация просто некое развитие.
Так всё-таки, чтобы наделять объект свойствами (?) типы не нужны?
Чуть выше вы сами пишете:
Поэтому типы именно как типы появились в статических языках в связи с необходимостью.
Пока не совсем понятно, какая необходимость заставила статические языки (С?) вводить типы. Если для наделения объекта свойствами типы не нужны.
Общие свойства множества объектов выносятся отдельно и им даётся имя/идентифактор. Это просто упрощает определение нового объекта с аналогичным набором свойств.
Т.е. если я правильно понял, для вас тип — какое-то соглашение?
А далее уже появляется какая-то логика работы с этими свойствами. Классификация и прочее.
Чтобы что-то классифицировать, и чтобы появлялась логика работы, надо определиться — с чем мы имеем дело. Давайте начнём с этого?
К сожалению, требует. Иначе будет непонятно, о чём мы с вами говорим. И непонятно, какие сущности языка считать типами, а какие — нет.
Нет. К тому же определение я дал и оно очевидно.
Согласно вашему определению, в выражении int foo = 0; типами можно назвать и int, и foo. Но это ведь не так, правда?
Нет, не согласно. Язык разделяет идентификаторы типов и не типов.
Вот тут уже интересней. Что это за свойства, откуда они берутся?
Неважно.
Если я понял вас правильно, то int вы типом считаете — исходя из вот этой вашей фразы:
Какая-то не внятная попытка. Я не совсем понял её смысл.
Какие у этого типа будут свойства? Или, если это не тип, что это тогда?
Свойства ему определяет язык. Самой базовое свойство в си — sizeof.
А тут мы с вами должны дать определение объекту и процессу наследования. Может, пока остановимся на типах?
Почему? К тому же, опять же неверно. Объект никакого отношения к наследованию не имеет.
Так всё-таки, чтобы наделять объект свойствами (?) типы не нужны?
Не нужны.
Чуть выше вы сами пишете:
Опять какие-то невнятные попытки.
Пока не совсем понятно, какая необходимость заставила статические языки (С?) вводить типы. Если для наделения объекта свойствами типы не нужны.
Ещё более невнятные попытки. Там всё понятно. Надо просто мыслить не так узко и не пытаться меня поймать, что заранее обречено. Типы не нужны в смысле не необходимы. Вы так же можете прожить хлебая баланду, но значит ли это, что еда отличная от баланды вам ненужна? Нет.
Т.е. если я правильно понял, для вас тип — какое-то соглашение?
Нет, тип — это идентификатор. Всё.
Чтобы что-то классифицировать, и чтобы появлялась логика работы, надо определиться — с чем мы имеем дело. Давайте начнём с этого?
Уже всё определено. Ничего более определять ненужно. Есть свойства — они биндятся на идентификатор. Этот идентификатор биндится на объект — далее объект наследует свойства объекта привязанные к типу.
Давайте совсем для дошкольников. Есть свойство — sizeof. Это свойство типа, свойство привязанное к идентификатору. Допустим, в каком-то случае к int привязывается свойство sizeof == 4. Далее объект аннотируется типом и наследует(это не то наследование, о котором вы подумали) этот sizeof.
Всё остальное работает по тому же принципу. В тип так же может быть забинжены какие-нибудь операции над объектом данного типа. И не только.
Ну хорошо, возьмём ваше определение.
Тип — это просто какой-то идентификатор. Всё.
Далее на него каким-либо образом, прямо или косвенно — навешиваются всякие свойства.
С тем, что такое тип, определились.
Но тогда меня немного смущает ваша фраза из контекста выше:
При этом никакие сумтипы и прочее типами не являются и являться не могут.
Есть такая занятная штука как std::variant, которая позволяет хранить в одном и том же оъекте (?) какие-то значения одного из двух или более других типов. Т.е. это реализация тех самых типов-сумм для С++. Вы говорите выше, что это не тип. А потом даёте такое определение типа, под которое std::variant попадает на 100%. Так всё-таки, это тип или нет? Мне правда интересно.
А тут мы с вами должны дать определение объекту и процессу наследования. Может, пока остановимся на типах?
…
Почему? К тому же, опять же неверно. Объект никакого отношения к наследованию не имеет.
Ну давайте так. Определение давать надо, чтобы не путаться, кто что сказал. У меня в голове есть какие-то определения, но давать я их не буду — чтобы не запутывать дискуссию. Дайте пожалуйста ваше определение, чтобы мы с вами друг друга правильно понимали. И таки немного странно, что объект получает свойства от типа путём наследования, но никакого отношения к нему не имеет.
Если я понял вас правильно, то int вы типом считаете — исходя из вот этой вашей фразы:
…
Какая-то не внятная попытка. Я не совсем понял её смысл.
Попытка, простите, чего? Не понял.
Так всё-таки, чтобы наделять объект свойствами (?) типы не нужны?
…
Не нужны.
Тогда получается, что в языке (С/С++?) можно создать объект какого-либо типа (или вообще без типа) и наделить его какими-то свойствами по ходу дела? Получается та самая "скриптуха"? Или приведите пожалуйста пример, если я вас неправильно понял.
Опять какие-то невнятные попытки.
Ещё более невнятные попытки. Там всё понятно.
… и не пытаться меня поймать, что заранее обречено.
Так и не понял, попытки чего. Пока я только честно пытаюсь вас понять.
Надо просто мыслить не так узко
А вы объясните доступным языком. Может я как раз хочу расширить мышление, да знаний не хватает.
Давайте совсем для дошкольников. Есть свойство — sizeof. Это свойство типа, свойство привязанное к идентификатору. Допустим, в каком-то случае к int привязывается свойство sizeof == 4. Далее объект аннотируется типом и наследует(это не то наследование, о котором вы подумали) этот sizeof.
Ок. Пусть будет sizeof. Что это свойство для вас определяет? Почему оно равно именно 4? Если это не то наследование (уже спросил выше), то какое?
Всё остальное работает по тому же принципу. В тип так же может быть забинжены какие-нибудь операции над объектом данного типа. И не только.
Ведь не всякие же свойства. Или вообще любые? Или есть какие-то правила, какие свойства и операции могут быть ассоциированы с типом?
К тому же, выше вы говорили, что свойства и операции могут быть ассоциированы непосредственно с объектом. Можете показать? Я правда о таком не слышал.
Есть такая занятная штука как std::variant, которая позволяет хранить в одном и том же оъекте (?) какие-то значения одного из двух или более других типов. Т.е. это реализация тех самых типов-сумм для С++. Вы говорите выше, что это не тип. А потом даёте такое определение типа, под которое std::variant попадает на 100%. Так всё-таки, это тип или нет? Мне правда интересно.
Хорошо, если интересно. Вариант не является сумтипом — вариант является типом. Если проще — вариант не может дать доступ к общим свойствам типа — вариант может дать доступ только одному из нескольких типов. К тому же — этой семантики нету на уровне языка. Не нужна путать семантику языка и системы типов и какую-то внешнюю логику реализованную на этой базе.
Ну давайте так. Определение давать надо, чтобы не путаться, кто что сказал.
Ну хорошо. Просто объект не нуждается в определении, к тому же это базовое понятие в си. Оно вполне соответствует моему. В целом можете воспринимать его как значение, либо кусок данных который представляет значение.
У меня в голове есть какие-то определения, но давать я их не буду — чтобы не запутывать дискуссию. Дайте пожалуйста ваше определение, чтобы мы с вами друг друга правильно понимали. И таки немного странно, что объект получает свойства от типа путём наследования, но никакого отношения к нему не имеет.
Хорошо. Здесь подойдёт и словарное определение объекта. Это не то, о чём нужно заботиться. Просто ненужно думать, что определение из какой-то ооп-скриптухи является каким-то общепринятым, либо оно вообще что-то да значит. Это определение специфично для отдельной области.
Попытка, простите, чего? Не понял.
Я вижу попытку найти противоречия в моей логики, а не попытку её понимания. И не вижу проблем у вас с её пониманием. Ваша мотивация читается как "не согласен — хочу показать, что кто-то не прав".
Тогда получается, что в языке (С/С++?) можно создать объект какого-либо типа (или вообще без типа) и наделить его какими-то свойствами по ходу дела?
Не получается. Хотя в си смешанная схема. Свойства навешиваются не только через типы, но и прямо на объекты(~= переменные/значения).
Накидывать свойства на каждый объект — неудобно. Поэтому и существуют типы. Давайте совсем на уровне "для детей". Вот есть лошадка и зайчик. Можем ли мы для каждого писать свойства? Да. Но удобно ли это? Нет. У зайчика и лошадки много общих свойств.
Поэтому мы выделяем эти общие свойства в группы/классы и уже описываем свойства для них. А далее зайчика/лошадку приписываем к этой группе.
Получается та самая "скриптуха"? Или приведите пожалуйста пример, если я вас неправильно понял.
Не получается. Скриптуха это тогда — когда все свойства объекта не известный, либо известны не полностью. Абсолютно неважно где и как определены свойства — если они доступны — это не скриптуха.
Хотя я определял скриптуху не через это, но это одно можно назвать различием так же.
Ок. Пусть будет sizeof. Что это свойство для вас определяет?
Абсолютно неважно. Что определяет свойство "цвет" у лошадки? Это глупый вопрос. Это не задача системы типов. Есть то, что наделяет. И есть то, что это свойство интерпретирует. В данном случае его интерпретирует "язык", а не пользовательский интеретатор. Но может быть наоборот.
Почему оно равно именно 4?
Почему цвет лошадки чёрный? Это неважно.
Если это не то наследование (уже спросил выше), то какое?
Обычное. На примере лошадки выше объяснил.
Ведь не всякие же свойства. Или вообще любые?
Любые.
Или есть какие-то правила, какие свойства и операции могут быть ассоциированы с типом?
Это уже нюансы каждого свойства. К делу отношения не имеет.
К тому же, выше вы говорили, что свойства и операции могут быть ассоциированы непосредственно с объектом. Можете показать? Я правда о таком не слышал.
Я не говорил такого. К тому же, показать что? Здесь нечего показывать. Я говорил о том, что типы не являются необходимостью и можно задавать свойства напрямую. Но в связи с тем, что это не удобно — это никто не делает.
Но, как я уже говорил, в си смешанная схема. Вы можете посмотреть это там. Допустим, тот же alignas — это свойство объекта.
В любом случае, схема "накидываем всё на объекты" — не удобна, поэтому в чистом виде не используется. О чём я говорил выше. Ключевое здесь то, что типы — про удобство, а не про необходимость.
А то, что я говорил о необходимости и си — это уже было в контексте си, где типы уже есть. Поэтому это нужно воспринимать как необходимость свойств, а не необходимость типов.
Посмотрите на профиль товарища — специально зарегистрировался чтобы в этой теме нести чушь. Не думаю, что вы от него сможете добиться какого-то адекватного диалога.
Посмотрите на профиль товарища — специально зарегистрировался чтобы в этой теме нести чушь.
Основания.
Не думаю, что вы от него сможете добиться какого-то адекватного диалога.
Только почему-то вы все быстро убежали из темы, нагнав сюда табуны минусаторов. А чего же так? Неужели настолько слабые? Чего же вы чушь одну генерируете?
Ну, расскажите мне про раст, С++. Куда вы все разбежались? Ничего не можете? Ну это типичная ситуация.
Просто это не первый профиль товарища. В других околоязыковых темах уже появлялся персонаж с такой же риторикой (вы все адепты с методичками, а я – С++-д'Артаньян) и характерными оборотами («никакого ХХХ не существует»). Никнейм не помню, но при надобности поищу.
Я даже начал писать комментарий на тему, но понял, что это бессмысленно. Там какая-то совершенно адская каша из рантайма, динамического диспатча, статического анализа и тому подобных вещей, разбирать это аккуратно долго и непонятно, зачем.
Как там с С++ и прочим? Совсем всё печально?
Если честно, да, печально. Что-то устал я, пропал былой запал, навернуть что-то на темплейтах-констекспрах всё ещё весело, но уже не так.
Судя по вашим ответам — это крайне сомнительно. Даже человек совсем из дремучего си с классами легаси и слабыми познаниями должен как минимум столько, что-бы глупости вида "не могут", "слабая система типов" и прочее не говорить.
Вы вот мне объясните. Ну разводите вы неофитов перепастой хелвордов с SO — разводите дальше. Всё равно никто про хаскель/идрис ничего не знает и впаривать там можно что угодно.
Но в С++ вы зачем лезете? Оставьте его в покое. Ведь как минимум приду я, либо ещё кто-то. Но судя вашему поведению — никто обычно не приходит.
Добавляйте всегда приписку "нету в С++(под С++ я понимаю си с классами и человека, пусть будет, с обычными способностями)". Никто на вас нападать не будет.
Я всё думаю, может действительно статейки пописать, кармы набрать и глушить всё это постоянно. даже 20-30 кармы адепты из чатиков не команде не перебьют. Скорее всего в этом году займусь этим.
так как мы начинаем спорить о значении слов «статическая», «скриптуха» и т.д. Зачем такое жесткое противостояние?
Это противостояние нужно не мне. Проблема в том, что существуют нечестные личности. Они обманывают неофитов, обманывают комьюнити. Выдавая себя, допустим, за эксперта по С++, при этом находять где-то на уровне джуна уровня си с классами. А далее подобные люди рассказывают про систему типов С++, про возможности С++. И люди верят этому.
Я конечно, не говорю о том, что такие подлецы здесь есть. Но всё может быть.
Если есть кто-то, кто выдаёт себя неправомерно за какую-то группу — истинный член данный группы первое, что должен сделать — отделить группу от лжецов. Для этого и нужно разделение.
В противном случае получается, что есть С++ и есть С++. И оба говорят разные вещи. Это путает людей. К тому же, подлецы обычно очень активные, фанатичные и являются адептами других группы. Используя адептов для набегов тех, истинных членов.
И как-то в ходе дискуссий забыли про определения. Надо исправлять. Итак:
Тип данных — множество значений и операций над ними. Т.е. кучу данных мы разбиваем на группы (числа, строки, структуры) и определяем операции для них. Именно благодаря типу мы знаем, что вот эти 4 байта — это дробное (float) число, а не целое (int), и без указания типа эти данные для нас бессмысленны, а операции — не определены (1+2 это 3 или 12 или 10.0?). Заметьте, включение в данное определение операций также важно, поскольку для каждого типа свои операции (могут совпадать, могут не совпадать). Т.е. вообще без типов мы не сможем написать даже hello world (да, даже в машинных кодах)
Далее — типизация может быть статическая (типы заданы при обьявлении и более не меняются) и динамическая (тип определяется при присваивании). Внимание, не более того! В этом определении нет даже понятий «компиляция», «рантайм», а потому так много ошибок в суждениях тех, кто здесь видит эти понятия.
Для размытия границ используется приём вывода типов (неявное, но все же однозначное указание типа), и зачастую не очень очевидное, что и сбивает многих с толку.
Далее, типизация бывает сильная (строгая) и слабая, различие их в том, возможно ли (неявное) приведение одного типа к другому. Тоже скользский момент, потому что часто свойство сильной\слабой относят к статической\динамической, а также часто расходятся во мнениях, приведение типов невозможно вообще или только неявное приведение.
И еще одна характеристика системы типов — способ разделения на типы — тоже подпадает под раздачу в термины «статическая\динамическая», хотя и сильно зависит от первых двух характеристик и варьируется несколькими факторами. Это ООП\ОП\прототипная\утиная типизация.
Таким образом, заданы важные вопросы:
Значение (переменная\поле\обьект...) как правильно интерпретировать? (число, строка или что-то еще?)
Как с этим работать? (складывать, присваивать, хранить, взаимодействовать с другими данными)
Относится ли значение к одной группе? (можно ли одно положить в другое?)
В какой момент времени мы можем это знать? А также, сколько информации останется в момент выполнения? (имеется ввиду возможность получение описания значения, т.е. это зона рефлексии\шаблонов\генериков)
Возможно ли в принципе, и, если да, то как корректно значение одного типа присвоить другому, или использовать одно вместо другого? (присваивание, наследование, расширение)
Для динамической типизации — есть ли возможность изменение структуры сложного значения (такое, как добавление новых полей к обьектам)
Таким образом, у места-значения (переменной\поля\...) есть 3 базовых свойства:
имя (идентификатор, адрес в памяти)
тип (формат, структура, размер, простое\сложное, набор операций — как встроенных в язык, так и программно, т.е. методы обьекта)
текущее значение (возможно константное)
и эти свойства, как, впрочем, и все определения выше, универсальны для любого языка с любой типизацией; без этих определений нет смысла.
и самое важное: в этих определениях нет указаний ни на внутреннее содержание (тип — это не только «физическое» разделение число-строка-структура-..., оно может быть и более, и менее строгим, например, «значение конечного множества (любого из)», «положительные целые четные числа от 1 до 100» ), ни на форму описания (в статье «церемонии»)
более того, строгость требования (обязательно указывать тип\может быть выведен\будет известен в момент выполнения) также вариативна, и удобна от задачи к задаче.
еще более того, лично у меня не отваливаются руки «лишний раз» написать типы, а кодогенерация и современные языки позволяют уменьшить количество бойлерплейта — не нужно ругать всю типизацию из-за неудачного применения в конкретных языках.
и вот за что смело можно минусовать — удивительно, но проектировать (писать частично рабочий код и смотреть, какие решения идут удачно, какие нет) лично мне неожиданно удобнее на таком простигосподи языке с такой же х… орошей статической типизацией и бойлерплейтом, как java, а не на чудных kotlin-scala-python-ruby и т.д.
Статическая типизация не обязательно требует церемоний