Comments 41
В бинарных сетях результатом работы должно быть бинарное значение.
Собственно так здесь и есть: выход сети, т. е. 3-го слоя — выход логической ДНФ функции. Она своим результатом имеет два значения: true или false. Или можно трактовать их как соответственно 1 или 0.
Почему только третьего? Почему сигналы не у всех слоев true/false?
Сейчас это похоже под адаптацию классических нейронных сетей под двоичные данные.
Сейчас это похоже под адаптацию классических нейронных сетей под двоичные данные.
Постановка задачи такая:
на входе сети — произвольные данные, т. е. любые действительные числа (в терминах языка программирования тип double);
на выходе сети — бинарные данные, т. е. числа которые принимают только два значения: 0 (false) или 1 (true) (в терминах языка программирования тип bool)
НС никому не обязана внутри себя иметь только двоичные данные.
Чем она отличается от классических НС я описал, как мне кажется, достаточно подробно.
на входе сети — произвольные данные, т. е. любые действительные числа (в терминах языка программирования тип double);
на выходе сети — бинарные данные, т. е. числа которые принимают только два значения: 0 (false) или 1 (true) (в терминах языка программирования тип bool)
НС никому не обязана внутри себя иметь только двоичные данные.
Чем она отличается от классических НС я описал, как мне кажется, достаточно подробно.
Следовательно, никакого обучения нейронов в рассматриваемой НС производить не нужно
, что делает возможным обучение в широком спектре приложений.
Они не склонны к переобучениюТак есть там обучение или нет?
Также, о последнем слое рассказано очень мало. Не понятно в чем его суть и зачем он нужен.
Есть обучение у 1-го слоя: построение функций распределения вероятностей для каждой входной переменной.
Есть обучение у 3-го слоя: построение минимальной ДНФ функции (подробнее об этом по ссылке на предыдущую мою статью).
Обучение у 2-го слоя нет: Необходимо только один раз сгенерировать случайные веса у нейронов и рассчитать коэффициент w0.
Есть обучение у 3-го слоя: построение минимальной ДНФ функции (подробнее об этом по ссылке на предыдущую мою статью).
Обучение у 2-го слоя нет: Необходимо только один раз сгенерировать случайные веса у нейронов и рассчитать коэффициент w0.
Есть обучение у 1-го слоя
Есть обучение у 3-го слояКак оно происходит? Как обычно, через backpropagation?
построение минимальной ДНФ функции (подробнее об этом по ссылке на предыдущую мою статью).Мне пока не нужно подробнее. Объясните вкратце, как о предыдущих двух объяснили, пожалуйста.
Обучение 1-го слоя сводится к нахождению функций распределения вероятностей входных переменных. Для этого можно применять какие угодно методы, которые описаны в математической литературе. В моей реализации весь диапазон значений входной переменной разбивается на интервалы, в которых подсчитывается кол-во попавших в них отчётов N(i) и затем вероятности попадания в интервалы P(i)=N(i)/N. Далее нарастающим итогом вероятности P(i) попаданий в интервалы суммируются, в результате чего получается функция от номера интервала. В первом приближении это и есть функция распределения вероятностей.
нахождению функций распределения вероятностейСложно назвать обучением в данном случае, но понятно.
Согласен. Поэтому в тексте я употребляю фразу нахождение (построение) функции распределения вероятностей
Кстати, я правильно понимаю, что для функции первого слоя можно выбрать тот же Sign? И это будет уже ближе к тому, что mpakep хочет.)
Нет, не правильно. Нелинейное преобразование входных данных нужно для того, чтобы равномерно распределить точки по пространству N-мерного единичного куба. Функция sign во входном слое «схлопнет» все исходные значения элементов вектора X всего лишь в два значения — 0 или 1. Это значит, что после преобразования все точки будут находится в углах N-мерного единичного куба. Внутри куб будет пустой. Всего таких точек-углов очень ограниченное кол-во. В результате все M нейронов будут выдавать небольшое кол-во состояний, что существенно ограничит возможности нейронной сети.
Обучение 3-го слоя сводится к нахождению минимальной дизъюнктивной нормальной формы. Это логическая функция от M бинарных переменных (выходов нейронов), где M-кол-во нейронов в скрытом слое. Для этого можно использовать любые методы, которые описаны в математической литературе. В моей реализации используется собственная разработка метода минимизации Квайна-Мак'Класки. В этом случае при построении минимальной формы логической функции на вход подаются Q образцов, каждый из которых является выходом M-нейронов. Q-количество образцов, которые используются для тренировки сети.
Смысл третьего слоя, для начала, можете объяснить в чем?
У него несколько смыслов. Но тот, который на самой поверхности в следующем:
всего в скрытом слое M нейронов. Соответственно на вход третьего (выходного) слоя поступает M бинарных переменных. Но на выходе сети должна быть только ОДНА бинарная переменная. Т. е. возникает проблема — M бинарных переменных необходимо преобразовать в ОДНУ! Как это сделать? Для этого и нужна логическая функция от M бинарных переменных, на выходе которой будет только ОДНА переменная — целевой бинарный отклик всей сети.
всего в скрытом слое M нейронов. Соответственно на вход третьего (выходного) слоя поступает M бинарных переменных. Но на выходе сети должна быть только ОДНА бинарная переменная. Т. е. возникает проблема — M бинарных переменных необходимо преобразовать в ОДНУ! Как это сделать? Для этого и нужна логическая функция от M бинарных переменных, на выходе которой будет только ОДНА переменная — целевой бинарный отклик всей сети.
Это как раз таки понять не сложно. В чем логичекая суть преобразования? В чем его особенности? Бинарную функцию N переменных можно придумать любую, но ведь не все из них подойдут?
Допустим на входе сети некоторый вектор X, заданный точкой в N-мерном пространстве. Тогда выход b каждого нейрона показывает с какой из сторон относительно его плоскости находится рассматриваемая точка. Т. е. каждый из нейронов делит исходное пространство на две части — что находится слева и справа от его плоскости. В совокупности все M нейронов своими плоскостями непредсказуемо расчерчивают исходное входное пространство на ячейки разного размера, конфигурации и положения. Следовательно, M значений b являются бинарными координатами точки в пространстве нейронов. Т. е. с помощью нейронов происходит переход из N-мерного пространства входных сигналов в M-мерное пространство нейронов с двоичной метрикой. Т. е. если рассматривать выход нейронов как двоичный код некоторого числа, то это получается номер ячейки пространства, куда попадает точка.
Суть логической функции в том, что она для каждой ячейки пространства нейронов с заданным номером ставит в соответствие признак 1 или 0. При этом делает она это не наобум, а в результате её обучения, т. е. построения или синтеза, которое в дискретной математике называется методами минимизации логических функций.
Суть логической функции в том, что она для каждой ячейки пространства нейронов с заданным номером ставит в соответствие признак 1 или 0. При этом делает она это не наобум, а в результате её обучения, т. е. построения или синтеза, которое в дискретной математике называется методами минимизации логических функций.
Чтобы переобучения небыло нужно чтобы вся сеть стала бинарной а не только результат одного из слоев.
Постановка задачи такая:
на входе сети — произвольные данные, т. е. любые действительные числа (в терминах языка программирования тип double);
на выходе сети — бинарные данные, т. е. числа которые принимают только два значения: 0 (false) или 1 (true) (в терминах языка программирования тип bool)
Если все данные внутри сети будут только бинарными, то не будет работать.
на входе сети — произвольные данные, т. е. любые действительные числа (в терминах языка программирования тип double);
на выходе сети — бинарные данные, т. е. числа которые принимают только два значения: 0 (false) или 1 (true) (в терминах языка программирования тип bool)
Если все данные внутри сети будут только бинарными, то не будет работать.
Уже работает. И в такой сети действительно нет переобучения.
Как работает какая-то другая сеть ничего сказать не могу, т. к. я её не видел.
Не обращайте внимания. У mpakep своё понимание слова «переобучение», которое отличается от общепринятого, а также своё представление о бинарных сетях, которые он долго и неудачно пытается пиарить на хабре и в ods.ai.
Правильно ли я понимаю, что нелинейное преобразование входных данных нужно только для того, чтобы равномерно распределить точки по гипер-пространству?
А оно в свою очередь нужно только для того, чтобы минимизировать количество нейронов в скрытом слое, так как они равномерно делят пространство.
А сами эти нейроны по сути — элементарные детекторы с бинарным выходом, и фактически могут быть заменены на совершенно другие.
И в итоге весь интеллект сосредотачивается в алгоритме, который строит логическую функцию.
У Вас обширный код, есть ли этот алгоритм в обособленном виде? Чтобы можно было ему скормить массив бинарных векторов + выход и получить логическую функцию.
Пробовали распознавать, допустим, какие-нибудь элементарные изображения?
А оно в свою очередь нужно только для того, чтобы минимизировать количество нейронов в скрытом слое, так как они равномерно делят пространство.
А сами эти нейроны по сути — элементарные детекторы с бинарным выходом, и фактически могут быть заменены на совершенно другие.
И в итоге весь интеллект сосредотачивается в алгоритме, который строит логическую функцию.
У Вас обширный код, есть ли этот алгоритм в обособленном виде? Чтобы можно было ему скормить массив бинарных векторов + выход и получить логическую функцию.
Пробовали распознавать, допустим, какие-нибудь элементарные изображения?
Правильно ли я понимаю, что нелинейное преобразование входных данных нужно только для того, чтобы равномерно распределить точки по гипер-пространству?Правильно.
А оно в свою очередь нужно только для того, чтобы минимизировать количество нейронов в скрытом слое, так как они равномерно делят пространство.Нет. Равномерность в единичном гиперкубе нужна для того, чтобы максимально использовать его пространство. Иначе, если все исходные точки будут транслироваться в какую-то небольшую область куба, то может так получиться, что нейроны просто «незаметят» их.
А сами эти нейроны по сути — элементарные детекторы с бинарным выходом, и фактически могут быть заменены на совершенно другие.Да, нейроны это детекторы с бинарным выходом, которые показывают с какой стороны относительно их плоскостей располагается конкретная точка.
И в итоге весь интеллект сосредотачивается в алгоритме, который строит логическую функцию.Да, от логической функции многое зависит. Соответственно, алгоритм минимизации (построения) очень важен с точки зрения нахождения оптимальной функции.
У Вас обширный код, есть ли этот алгоритм в обособленном виде? Чтобы можно было ему скормить массив бинарных векторов + выход и получить логическую функцию.habr.com/ru/post/424517
habr.com/ru/post/328506
Или можете в представленном к статье исходнике взять всё, что находится внутри
namespace LogicFunc {… }
Пробовали распознавать, допустим, какие-нибудь элементарные изображения?Вообще, представленная сеть работает с одномерными векторами. Поэтому напрямую с изображениями она работать не может. Но если доработать…
Нет. Равномерность в единичном гиперкубе нужна для того, чтобы максимально использовать его пространство. Иначе, если все исходные точки будут транслироваться в какую-то небольшую область куба, то может так получиться, что нейроны просто «незаметят» их.Именно это я и имел в виду. Чтобы точки не кучковались. Если они будут плотно лежать в какой-то области пространства, а разбиение плоскостями всего пространства равномерное, то потребуется очень много плоскостей, чтобы разбить этот плотный участок. При этом на разряженные участки будет бессмысленно потрачены нейроны. То есть, равномерность позволяет уменьшить необходимое число нейронов. Поэтому я и назвал это «минимизацией».
Вообще, представленная сеть работает с одномерными векторами. Поэтому напрямую с изображениями она работать не может. Но если доработать…Есть идея простого детектора (типа направленной On/Off клетки в сетчатке) — просто бить изображение на две части случайным образом (как на картинке у Вас в примере), считать яркость обеих половин и выдавать бинарный ответ: «ярче ли левая половина?».
Вы этот подход разрабатываете «самостоятельно», или отталкиваетесь от каких-то биологических исследований? Спрашиваю, потому что, во-первых, массив элементарных детекторов — это то, с чего начинается обработка в живых нейронных сетях. И во-вторых, у нейронов далее по тракту обработки обнаруживаются логические функции.
Именно это я и имел в виду. Чтобы точки не кучковались. Если они будут плотно лежать в какой-то области пространства, а разбиение плоскостями всего пространства равномерное, то потребуется очень много плоскостей, чтобы разбить этот плотный участок. При этом на разряженные участки будет бессмысленно потрачены нейроны. То есть, равномерность позволяет уменьшить необходимое число нейронов. Поэтому я и назвал это «минимизацией».Действительно, я не понял. В этом смысле всё правильно
Есть идея простого детектора (типа направленной On/Off клетки в сетчатке) — просто бить изображение на две части случайным образом (как на картинке у Вас в примере), считать яркость обеих половин и выдавать бинарный ответ: «ярче ли левая половина?».Не очень понял причём здесь НС, если можно напрямую подсчитать два значения яркости и сравнить их как два числа.
Вы этот подход разрабатываете «самостоятельно», или отталкиваетесь от каких-то биологических исследований? Спрашиваю, потому что, во-первых, массив элементарных детекторов — это то, с чего начинается обработка в живых нейронных сетях. И во-вторых, у нейронов далее по тракту обработки обнаруживаются логические функции.Данная НС вообще никак не привязана к мозгу или каким-то другим биологическим объектам. Для меня это чисто математическая абстракция — алгоритм. Упоминание здесь нейронов — только дань исторической традиции: так уж повелось в машинном обучении, что такие бинарные конструкции называются нейронами, а их совокупность — нейронной сетью. Я успешно применял данную НС в анализе финансовых рядов и показателей, т. е. в области далёкой от биологии. То что в биологических объектах есть похожие конструкции — ничего удивительного, т. к. всё во вселенной функционирует в соответствии с математическими законами.
Обобщение возникает в результате того, что точки внутри ограниченной плоскостями области отображаются в одну и ту же вершину гиперкуба, так? Логическая функция же как бы «собирает» эти области, где результат равен true, отбрасывая остальные. Вершина гиперкуба — это индекс/идентификатор ограниченной области. То есть, как альтернатива логической функции — просто список идентификаторов этих ограниченных областей / вершин куба.
Если сеть на тестовых данных выдала ошибку, то как делать дообучение? Я так представляю надо эту область, в которую попала «ошибочная» точка бить дополнительной партией плоскостей на более мелкие области и уточнять логическую функцию. Вы этот вопрос как-то решаете с дообучением, я так понимаю, это требует введение новых нейронов?
Если сеть на тестовых данных выдала ошибку, то как делать дообучение? Я так представляю надо эту область, в которую попала «ошибочная» точка бить дополнительной партией плоскостей на более мелкие области и уточнять логическую функцию. Вы этот вопрос как-то решаете с дообучением, я так понимаю, это требует введение новых нейронов?
Обобщение возникает в результате того, что точки внутри ограниченной плоскостями области отображаются в одну и ту же вершину гиперкуба, так? Логическая функция же как бы «собирает» эти области, где результат равен true, отбрасывая остальные. Вершина гиперкуба — это индекс/идентификатор ограниченной области. То есть, как альтернатива логической функции — просто список идентификаторов этих ограниченных областей / вершин куба.Не уверен, что полностью понял сообщение, но поводу логической функции думаю верно — она действительно пытается укрупнить, т. е. «собрать» в единое целое смежные ячейки пространства, которые были рассечены плоскостями нейронов и в которые попали точки только одного класса (0 или 1).
Если сеть на тестовых данных выдала ошибку, то как делать дообучение? Я так представляю надо эту область, в которую попала «ошибочная» точка бить дополнительной партией плоскостей на более мелкие области и уточнять логическую функцию. Вы этот вопрос как-то решаете с дообучением, я так понимаю, это требует введение новых нейронов?На этот вопрос нет неоднозначного ответа. Наличие ошибок на тестовых или обучающих выборках это нормально. Зависит от того, что хотите получить из НС. Если хотите превратить НС в устройство памяти, которое идеально воспроизведёт обучающую выборку, то можете поступить так, как написали. Но не стоит удивляться потом, если НС на других тестовых данных не сумеет вообще ничего угадать. Вы же создали элемент памяти обучающей выборки, а не устройство, которое выявляет закономерности в данных. В реальности же из любой закономерности бывают исключения и они могут встречаться в обучающей выборке. Важно, чтобы НС не подстроилась под эти исключения и тогда она подстроится под общую закономерность в данных. А то, что для небольшого количества исключений из закономерности НС выдаст ошибку — это не страшно. Наоборот, эту ситуацию можно использовать в свою пользу: 1. НС нашла закономерность в данных; 2. Она нашла точки, которые не попадают под эту закономерность. Двойной профит так сказать.
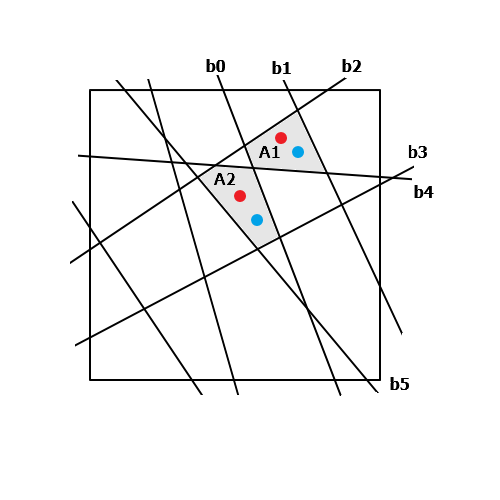
Хочу всё таки прояснить пару моментов. Вот условный набросок разбиения пространства плоскостями. Каждой плоскости соответствует свой нейрон. Допустим у нас в обучающей выборке только две точки — показаны красным цветом. Они попадают в две ограниченные плоскостями области — A1 и A2.
Область A1 ограничивается нейронами: b0, b1, b2, b4. Область A2 — b0, b2, b3, b4, b5. Соответственно каждая область кодируется/адресуется:
A1 — 000..010111
A2 — 000..111101
Логическая функция «складывает» обе эти области в одну.
Под обобщением я понимаю, что любая другая точка (показаны синим цветом) в области A1 даст тот же самый код: 010111. И сеть выдаст результат: 1/true.
Области, в которые не попали точки из обучающей выборки сеть не «распознает», выдаст 0/false. То есть, к примеру, на точку в близко примыкающей к A1 и A2 области, ограниченной b0, b2, b4 сеть выдаст 0.
И под дообучением я имел в виду следующее. Если в процессе работы выяснилось, что синяя точка в A2 не должна давать положительный ответ, то следует добавить новый нейрон и разбить область A2 пополам между новой точкой (синяя) и ранее обученной (красная). То есть, «доработать напильником» ограничительный объём.
Область A1 ограничивается нейронами: b0, b1, b2, b4. Область A2 — b0, b2, b3, b4, b5. Соответственно каждая область кодируется/адресуется:
A1 — 000..010111
A2 — 000..111101
Логическая функция «складывает» обе эти области в одну.
Под обобщением я понимаю, что любая другая точка (показаны синим цветом) в области A1 даст тот же самый код: 010111. И сеть выдаст результат: 1/true.
Области, в которые не попали точки из обучающей выборки сеть не «распознает», выдаст 0/false. То есть, к примеру, на точку в близко примыкающей к A1 и A2 области, ограниченной b0, b2, b4 сеть выдаст 0.
И под дообучением я имел в виду следующее. Если в процессе работы выяснилось, что синяя точка в A2 не должна давать положительный ответ, то следует добавить новый нейрон и разбить область A2 пополам между новой точкой (синяя) и ранее обученной (красная). То есть, «доработать напильником» ограничительный объём.

НС нашла закономерность в данныхЕсли всё происходит так, как я выше описал, то, честно, не вижу у сети способности поиска закономерностей (предсказательности). Её и не может быть, так как выход бинарный. Сеть не может сказать «очень похоже, что эта новая точка близка к обучающим». Даже если она стоит почти впритык к обучающей точке, но между ними есть разделяющая плоскость. Здесь нет аппроксимации как у классических НС. Поэтому я бы назвал её сложным детектором. То есть, простые детекторы, которые стоят в начале обработки, ограничивают пространство примитивным способом. Но в комплексе все вместе могут «вырезать» из пространства кусок любой замысловатой формы. При этом точность/грубость/приближение этой фигуры ограничивается только количеством нейронов. Это практически как широко известный метод ограничительных объёмов из расчётов в 3D-графике. Но использование его таким способом в ИНС мне не встречалось. Кстати, рекомендую с ним ознакомиться, так как возможно позволит Вам улучшить алгоритм, многократно ускорить расчёт. К примеру, для всех точек, что лежат левее плоскости b5, можно сразу дать ответ 0, не уточняя область.
Хочу всё таки прояснить пару моментов. Вот условный набросок разбиения пространства плоскостями. Каждой плоскости соответствует свой нейрон. Допустим у нас в обучающей выборке только две точки — показаны красным цветом. Они попадают в две ограниченные плоскостями области — A1 и A2.Логическая функция «складывает» смежные области (можно назвать домены), которые отличаются в коде только одной позицией. Например, ниже они отмечены зелёными оттенками. Области A1 и A2 не являются непосредственно смежными, но потенциально в результате минимизации функции на каком-то шаге они могут стать смежными и будут объединены. Всё зависит от окружающей обстановки.
Область A1 ограничивается нейронами: b0, b1, b2, b4. Область A2 — b0, b2, b3, b4, b5. Соответственно каждая область кодируется/адресуется:
A1 — 000..010111
A2 — 000..111101
Логическая функция «складывает» обе эти области в одну.

Под обобщением я понимаю, что любая другая точка (показаны синим цветом) в области A1 даст тот же самый код: 010111. И сеть выдаст результат: 1/true.Понятно. Логическая функция предполагает, что в каждой элементарной области, будет находится только одна точка, имеющая признак 0 или 1. Если в областях A1, A2 или любой другой находятся одновременно точки с разными признаками и 0 и 1, то это аномальная ситуация для логической функции и здесь можно:
Области, в которые не попали точки из обучающей выборки сеть не «распознает», выдаст 0/false. То есть, к примеру, на точку в близко примыкающей к A1 и A2 области, ограниченной b0, b2, b4 сеть выдаст 0.
И под дообучением я имел в виду следующее. Если в процессе работы выяснилось, что синяя точка в A2 не должна давать положительный ответ, то следует добавить новый нейрон и разбить область A2 пополам между новой точкой (синяя) и ранее обученной (красная). То есть, «доработать напильником» ограничительный объём.
1. Проанализировать точек какого типа больше в данной области и оставить в этой области только одну точку такого типа, которых больше. Такой подход применяется в моей реализации. Он проще.
2. Более сложный вариант — дообучить или «доработать напильником», как предложили Вы. Например, добавить плоскостей-нейронов. Как показано на рисунке, это плоскость С1. Сам по себе, как мне кажется, этот подход «тянет» на отдельную подсистему, которая может оказаться сложнее, чем рассматриваемая здесь НС.
Если всё происходит так, как я выше описал, то, честно, не вижу у сети способности поиска закономерностей (предсказательности). Её и не может быть, так как выход бинарный. Сеть не может сказать «очень похоже, что эта новая точка близка к обучающим». Даже если она стоит почти впритык к обучающей точке, но между ними есть разделяющая плоскость. Здесь нет аппроксимации как у классических НС. Поэтому я бы назвал её сложным детектором.Если точки в пространстве единичного куба занимают устойчивое или фиксированное положение, то данная сеть подстраивается под этот «образ» и выдаёт правильный результат. Если же точки в пространстве куба хаотически перемещаются и не дают устойчивой картинки, то НС в этом случае бессильна.
Другими словами с позиций математики — если входной процесс является стационарным, то НС даёт хороший результат. Если же входной процесс нестационарный, то никаких закономерностей в исходных данных НС, конечно, не найдёт.
Отсюда, кстати, нужно особо тщательно подходить к подготовке исходных данных для обучения и работы сети. Обязательно проводить их предварительную обработку, например, нормирование.
Ещё вопрос для уточнения.
Для наглядности разграничил регулярной сеткой. Красные точки с признаком 1, синие с признаком 0.
Алгоритм (я бы назвал его методом кластеризации) «соберёт» только те домены (закрашены серым), в которые попали «единичные» точки из обучающей выборки? Или соберёт все домены, что на рисунке ограничены красным контуром?
Для наглядности разграничил регулярной сеткой. Красные точки с признаком 1, синие с признаком 0.
Алгоритм (я бы назвал его методом кластеризации) «соберёт» только те домены (закрашены серым), в которые попали «единичные» точки из обучающей выборки? Или соберёт все домены, что на рисунке ограничены красным контуром?
рисунок
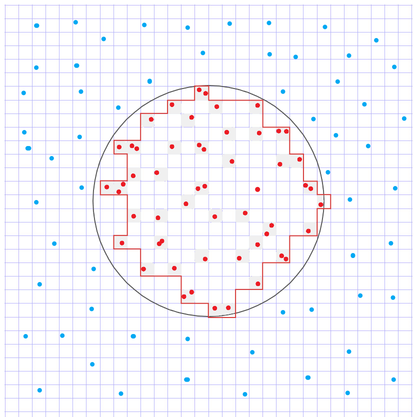

Очень хороший вопрос. Если будете пользоваться классическим методом минимизации логических функций Квайна-Мак'Класки, то не соберёт. В моей доработанной реализации этого метода все домены, ограниченные красным контуром, будут объединены в единую область. В этом его преимущество перед классическим методом, но из-за этого он работает несколько дольше.
А насколько быстро он работает не в режиме обучения, а в режиме распознавания? Мне интересно можно ли этот алгоритм применить для вычисления принадлежности точки фигуре из вокселей. То есть, нужно вычислять принадлежность домена к ограниченной контуром области. Функционально ответ — да, можно. Но вопрос в быстродействии.
Когда логическая функция после режима обучения, т. е. её синтеза из обучающих векторов (выходов нейронов) и соответствующих им бинарных признаков, найдена, то в рабочем режиме расчёт бинарного выхода функции по одному входному вектору фактически происходит мгновенно. Т. е. затраты времени при обучении на порядки больше, чем в рабочем режиме.
UFO just landed and posted this here
Проверка на MNIST пока только в планах. Но уверен, что работать будет с хорошим результатом, т. к. в данной парадигме обучению (минимизации) подлежит только выходная логическая функция — она же функция кластеризации. А этот процесс хорошо исследован несколькими поколениями математиков и работает без сбоев.
Sign up to leave a comment.
Пришествие бинарных нейронных сетей на основе случайных нейронов и логических функций