Comments 1975
Афигенно! Автор, жги! * обновляет страницу, дабы насладится холиваром *
Динамическую типизацию зачем то придумал и мало того она жива до сих пор, обычно то что никому не нужно умирает на задворках истории.
Но удивительное дело в динамических появляются типы, а в типизированных val.
Такие дела.
Истина где-то рядом, наверно по середине.
И наверно не всех надо по одну гребенку.
Удивительный у автора талант писать статьи, которые вызывают эмоции от полного принятия до лютой неприязни.
val это не динамическая типизация, а лишь вывод типов. Вот почему то многие не понимают принципиальной разницы
Динамическую типизацию зачем то придумал и мало того она жива до сих пор, обычно то что никому не нужно умирает на задворках истории.
Как говорил один мой знакомый:
Так ведь значит же. Динамика это просто атавизм из 90-х, когда языки с нормальными системами типов делать не умели, а писать на вербозном говне не хотелось.
А ЯП с нормальными системами типов начали появляться относительно недавно.
Ни в коем случае не троллинг, действительно интересно.
Haskell (хотя 0xd34df00d щас опять будет ворчать, что выразительности не хватает), Idris, вроде бы Scala (хотя точно сказать не могу), с некоторой натяжкой — Rust.
- Динамика это просто атавизм из 90-х, когда языки с нормальными системами типов делать не умели
- Haskell, 1990 год.
- Python, 1991 год.
Как эти три вещи могут одновременно укладываться в голове? Видимо ваш знакомый не знает одной из них.
Не получится убедить, что Haskell — это подходящий язык для разработки, а Python — не подходящий.
Лучшее, что может быть — это типизация по требованию. Когда нужно, беру и использую. Когда не нужно — избегаю кучи бойлерплейта.
Все таки Haskell это полигон для экспериментов, который тем не менее дорос до прода, а активно вывод типов начал проникать в индустрию только в 10ых годах.
Ну так хаскель 90-го года и хаскель совеременный — это очень разные языки.
Лучшее, что может быть — это типизация по требованию. Когда нужно, беру и использую. Когда не нужно — избегаю кучи бойлерплейта.
Если бы она ещё работала… Потому что когда тебе нужно, а в апстриме не нужно — вылезай, приехали.
Swift
Не очень из-за дурацкого деления типов на структуры и классы.
Структуры и классы никак не делят типы и не мешают. Это лишь определяет reference type/value type и системе типов до этого нет никакого дела.
Есть дело мне при написании программ, потому что мне надо думать, где будет глубокое копирование, а где — поверхностное, где меняется аргумент, а где — его копия. И в дженериках подобное разделение обычно аукается.
Ну скорее всего придётся об этом думать, язык все-таки позиционируется как более менее быстрый и нежручий.
За мутабельные структуры компилятор всегда подскажет. Если один раз понять как работают reference type/value type в свифте и использовать их где нужно и как нужно, то никаких проблем не будет возникать, а компилятор в случае чего все-равно заботливо предостережет. Все четко и явно в этом плане. И не придется переживать за глубокое/поверхностное копирование.
А что не так с дженериками?
В самом простом варианте все по-умолчанию imutable, потому что компилятор не будет знать что именно туда придет, а для мутабельности можно и inout или var в нужном месте указать.
В случаях посложнее (generic constraints) у вас в протоколе все ограничения описываются, вплоть до указания что этот протокол только для классов.
Не знаю с какими проблемами вы сталкивались, но по этому поводу у меня голова ни разу не болела.
К сожалению он существует только в яблочной экосистеме.
К счастью, его можно поставить и использовать практически на все, кроме винды. На малинку вот поставил недавно.
6 лет назад было 50/50, как сейчас — не знаю, но думаю не в пользу винды.
87% windows на 2019 год.
87% это в целом по миру или в сфере разработки? Я видел винду только у тех разработчиков, которым по каким-то причинам было лень ставить линукс. Возможно страх перед неизведанным.
https://swift.org/blog/5-3-release-process/
Теперь и на винде будет.
Так исторически сложилось, что на свифт перешли все кто писал на ObjC, а он существовал в рамках эппловских операционок, поэтому большинство пишущих на нем — маководы. А так как язык молодой, то пока еще не успел выбиться из нативной разработки под MacOS/iOS (в плане популярности), хоть эппл и делает многое, чтобы он мог быть универсальным. Бекенды эти ваши давно уже можно писать, с ардуинками играться, TensorFlow переходит на него как на основной язык. Дайте малышу время)
хоть эппл и делает многое, чтобы он мог быть универсальным.А что именно он делает? Мне просто интересно. Компилятор предоставил? Так Objective C всегда был под разные платформы (стараниями Столлмана, правда, вопреке желанию Джобса… но был).
Каких-либо попыток сделать разумную среду, которую можно использовать вне экосистемы Apple я не наблюдаю… да неясно какой в ней мог бы быть смысл: Apple же нужно сделать так, всё-таки, чтобы «хомячки» не разбежались с его платформы, а не чтобы кто-то вне её творил…
TensorFlow переходит на него как на основной языкКто сказал? Откуда уверенность, что из этого не получится очередная стелла на известном сайте?
Про TensorFlow Google сказал, мол уходят с питона на свифт. Потому что быстрый, безопасный и: https://en.wikipedia.org/wiki/Differentiable_programming
Если появится очередная стелла, свифт от этого никак не пострадает. Но это не отменяет факта, что свифт уже не только язык для “хомячков” с платформ Apple.
Про TensorFlow Google сказал, мол уходят с питона на свифтГде, когда, а главное, кто? Те, кто его разработал? Там им свою разработку и внутри Гугла надо как-то продавать — ещё бы они не излучали оптимизм.
Если появится очередная стелла, свифт от этого никак не пострадает.Пострадает, конечно. Причём уже похоже, что не «если», а «когда». Итересно только — релиз успеют сделать или прямо из беты в небытиё?
Но это не отменяет факта, что свифт уже не только язык для “хомячков” с платформ Apple.Та же самая история, что и с Objective C, на самом деле: когда Objective C только появился — народ разработал GNUstep и были даже попытки куда-то это всё приспособить. Однако со временем всё заглохло и, насколько я знаю, Cocoa уже никто никуда портировать особо не пытался — так, кой-какие обрезки для игрушек.
То же самое и здесь: каждая неудача применить Swift куда-нибудь, кроме iOS и macOS будет подчёркивать «неразрывную связь»: Swift == Apple, Apple == Swift.
Слабо себе понимаю причину захоронения S4TF. Ребята из Google просто искали наиболее подходящий язык и выбрали Swift. Cделали форк языка и на его основе допиливают под нужды. В Colab уже добавили. FastAI, курсы начали переводить. Единственная проблема, крайне сыроват еще, но светлое будущее :).
Ребята из Google просто искали наиболее подходящий язык и выбрали Swift.Именно так: не «Google искал», а «ребята из Google искали».
В Colab уже добавили. FastAI, курсы начали переводить. Единственная проблема, крайне сыроват еще, но светлое будущее :).Где-то я это уже слышал… Chrome Apps, NaCl… Да собственно половина проектов из Google Graveyard когда-то были «сыроватыми, но со светлым будущим».
Слабо себе понимаю причину захоронения S4TF.То же самое, что и всегда: не оправдал надежд, не набрал критической массы… Посмотрим. Самый важный вопрос не в том, смогут ли они в Colab что-то добавить, а смогут ли они хотя бы один «большой» проект этим увлечь… и то может не помочь: NaCl использовался в App Engine, но ему это не очень помогло…
Вот это самое "кроме" такой немаленький минус. И подозреваю в обозримом будущем оно не войдет в Tier1 поддерживаемых ОС. Rust вполне неплохая альтернатива в данной ситуации.
Динамическая типизация переносит ряд возможных ошибок на время исполнения программы вместо времени компиляции.
Как по мне оптимальна гибридная типизация, ибо иногда просто хочется расслабиться и что-то наклепать на коленке, не задумываясь о типах, но в серьезных проектах на том же PHP строгая типизация просто необходима по причинам, которые я описал выше. Причем я понял что словами это не объяснить, с этим нужно сталкиваться чтобы оценить все преимущества.
P. S. Это еще ладно, я еще и после этого с MySQL на PostgreSQL перешел (который тоже строготипизирован), теперь он меня обругивает каждый раз если по какой-то причине в строку суется число (а это может быть следствием какой-то очень серьезной проблемы, ибо почему возвращается число там, где должна возвратиться строка, например, array_search не нашел какое-то значение в массиве, хотя должно, что означает что этот массив сформирован неверно). Очень сильно выручало уже, хотя я не так давно пользуюсь всеми ее преимуществами.
писал на PHP, пару лет назад понадобилось прочно влезть в яву (более строго-типизированного языка я в жизни не видел)Это не та ли система типов, которая считает null объектом любого типа?
В РНР эту «особенность» умудрились не повторить, кстати.
Наверное, просто потому что null в PHP появился чуть ли не раньше чем сама Java появилась (шутка, она старше на пару месяцев) и изначально был отдельным скалярным типом, когда объектов ещё даже в проекте не было
заругается если аргумент имеет другой тип данных
Нуда, только его ругание попробуй еще перехвати, приходится статический анализатор гонять
ЗЫ на самом деле Php начинает нервировать, ятоже много лет на нем пишу, и у меня все более отчетливое желание писать на jsp или на чистой Java
TypeError обычное исключение. Обычно его и особо перехватывать не нужно, так же как любое необработанное.
Хороший пример: когда тон чего-то сказанного в начале убивает желание вообще продолжать смотреть на дальнейшие какие-то рассуждения или аргументы, не важно правильные или неправильные.
Приблизительно как начать общение в таком духе: "слыш, ты, послушай что я тебе сейчас скажу об этом говне...",
что там дальше уже не особо важно.
-А холивар то где???
P.S. После фразы «адское говнище» не читал.
В PHP добавляют строгую. А про джс можно подробнее?
Тот, кому первому пришла в голову идея назвать рантаймовый контроль типов «типизацией» — будет вечно гореть в аду за обман джуниоров.
Типизация — не контроль типов?
Не согласен. Типы — информация о том, как интерпретировать то или иное значение. А где она хранится и как и когда проверяется — детали реализации.
Лучше поздно, чем никогда, нет?
Как по мне, то если контроль типов есть, то это типизация.
Ваша программа станет типизированной.
Большинство источников используют "динамическая типизация" без подобных огооврок.
Строго говоря можно даже говорить о том, что все языки с динамической типизацией — суть языки со статической типизацией, в которых есть ровно один тип (и других создать невозможно). Ну или (как в JavaScript) — их несколько, но их фиксированное число и они все описаны в документации.
Однако в виду полной абсурдности такого подхода обычно от языков со строгой типизацией требуется, чтобы свои типы в них, всё-таки, можно было создавать.
Но нет, позднее связывание не делает язык нетипизированным. Даже если в каким-то месте про тип и нельзя ничего сказать (как в Java, когда вы получаете
Object), но в других-то можно!назвать типизацией наличие проверок на корректный доступ к элементу массива
Тем не менее в Паскале длина массива именно что входила в определение типа.
(ещё до программирования)
Если вы имеете в виду математические типы в стиле введенных Расселом, то он ведь тоже не уточнял, в какое время их надо проверять.
Поэтому ваше утверждение
которое на программирование отображается как статические проверки
достаточно спорно.
Если уж на то пошло, то и статическая, и динамическая проверка типов вообще не относятся к типам, как таковым — типы просто существуют, а является скорее помощью человеку, который не может не делать ошибок и не путать данные разные типов в процессе программирования или выведения логических формул.
Не только конструктивное, но даже конструктивистское. Т.е. вполне пригодное для практического построения системы типов и ее использования.
Типы в ЯП до формализации примерно так и строились.
Должна ли операция «удалить первые N символов» быть в определении строки?
Может быть, но не обязательно. Она не слишком аксиоматическая, что ли.
Если у вас питон с типа строгой динамической типизацией, то, получается, «abcde» и "" — разные типы?
Непонятно, почему вы пришли к такому выводу. Операция эта будет определена как функция отображения строки в строку, т.е. тип объекта не изменится.
Может быть, но не обязательно. Она не слишком аксиоматическая, что ли.
То есть вместо строгого определения имеем: "Вроде как нет, но если надо, почему бы и не да".
некоторые выражения не имеют смысла, не «вычисляя»
Вы все равно вычисляете — ведь это знание не дано свыше, а требует тех же символьных манипуляций. Просто в данном случае есть более короткий способ вычисления — как некоторые интегралы можно посчитать в символьной форме, а не численно. Но в общем случае вычисления все равно придется проводить полностью.
выделить массив ровно такой длины
Насколько я помню исходный виртовский Паскаль — нет. Массивы там были вообще не динамические, а в их тип входили тип элементов, тип индексов и диапазон индексов.
А для передачи массива в процедуру приходилось определять формальный аргумент, прибегая к чему-то вроде any: ARRAY OF INTEGER, например, вместо полного типа ARRAY[1..10] OF INTEGER.
Хотя бывают разные ассемблеры. Почитайте документацию на TASM. У них там объекты были.
Целочисленный add, применённый к float значению, выдаст хурму на выходе.
елочисленный add, применённый к float значению, выдаст хурму на выходе.Недоумённо смотрит на свой код из релизнутого продукта. А вы точно в этом уверены?
А вот эту статью вы когда-нибудь видели?
Разумеется, какие-то целочисленные операции можно применять к float зная формат и ожидаемый результат.
Я же говорил, что сложив 1+1 вы получите не 2, а 1.7014118346e+38
Точно так же, перепутав знаковое и беззнаковое деление результат может быть неверным.
Я же говорил что сложив 1+1 вы получите не 2А почему вы, собственно, должны получить 2? Вы и без всяких
floatов можете получить чушь, если в одной переменной у вас 1 и в другой 1, только в одной — это метр, а в другой дюйм.Проверено экспериментально.
Процессор не сделает преобразование типов за вас. К чему вот было это ваше «а можно плавать и со штангой»?
>> А почему вы, собственно, должны получить 2?
Потому что я хочу получить 2, наверное?
Потому что я хочу получить 2, наверное?
Интересный аргумент. А если я хочу получить 3, то должно получаться 3?
1+1=3? Cтранное желание, но как хотите.
Ещё, слышал, бывали процессоры, у которых переменные содержали поле с типом.
У типа есть очень формально определённое значение
Много определений типа в программировании. Некоторые ещё тянут в программировании определения типов из математики.
"У типа есть очень формально определённое значение".
Я знаю про несколько определений типа из нескольких разных теорий типов. Не считая определений из прикладных языков программирования, который возникли раньше тапла и из других предпосылок. Какое же из них верное?
Понятие типа в контексте STLC
1. Система типов из «лямбда-исчисления с типами» не единственная система типов, а только одна из.
2. Системы типов в современных мейнстримных языках (как со статической типизацией, так и с динамической) — это очень далеко не STLC и я подозреваю, что их авторы строили их на несколько других основаниях (и не только формальных).
3. Да, можно натянуть сову на глобус (что и делает тапл) и вывести одно из другого, но это вообще не означает, что определение типа из STCL единственно верное или валидное для языков программирования.
4. То что система типов красиво формализуема еще не означает, что она хорошо подходит для промышленной разработки людьми, которым важно получить результат здесь и сейчас, а не формально верифицировать корректность программы.
А в каких других теориях типов это не статическая классификация?
Ну есть, например, такая «Gradual Type Theory». Правда я с ней недостаточно знаком, чтобы внятно ее обсуждать.
По остальным пунктам — а о чём мы спорим-то?
Я спорю с утверждением, что «типы — это не рантайм-метки рядом с другими ячейками в памяти, а что-то, что проверяется компилятором статически», и утверждаю, что если «статическая типизация = типы проверяются компилятором статически», то так же правомерно говорить «типы проверяются рантаймом динамически = динамическая типизация».
automath какой-нибудь возник сильно до любого из ныне существующих языков программирования.
Я думал, что тут разговор о языках программирования, а не доказателях теорем.
А как называются рантайм метки более коротко? И какое название у описания того, что можно делать с некоторой штукой вне зависимости от того, рантайм это или дизайн тайм?
Мне кажется, такой подход к терминологии менее ортогонален.
Ну так и называются, метки.
А кем они так называются? Есть ли какая-то реализация которая называет их не типом?
Например, в вашей любимой IDE при отладке тип переменной и тип значения переменной называются по разному? Один тип, другой метка?
Ээ, не знаю, это какой-то слишком общий термин для меня.
Ну вы в обычной речи слово тип не употребляете?
С моей точки зрения в книжке терминология интересна но неудобна, все говорят "тип" для общего, никто не использует выражения "рантайм метка" а статика тесно связана с динамикой.
С моей точки зрения в книжке терминология интересна но неудобна, все говорят «тип» для общего, никто не использует выражения «рантайм метка»
А зря. На мой взгляд, создаёт неправильные ожидания.
Зря или не зря — это уже больше философский вопрос. Факт в том, что «динамическая типизация» по отношению к языкам программирования используется именно в таком смысле, и причины, по которым так сложилось, здесь не важны.
лишний раз указать на принципиальное различие между типизацией и рантайм-проверками
То, что вы называете типизацией, — всего лишь проверки до рантайма.
Это лишь ваше убеждение :)
От задач зависит. Популярность языка, стэка обеспечивает масштабируемость разработки для бизнеса и наличие рабочих мест для программистов.
Извините, но вы соответствие Карри-Говарда проигнорировали. Избирательное зрение?
Надеюсь теперь всем ясно, что это — тролль?
Они, впрочем, обычно обладают крайне развитым навыком «переноса ворот» (как вы это уже тут видите), потому важно им всячески помогать, но ни в коем случае не брать на себя никаких обязательсв, если они не скрплены «подписями и печатями».
Даже если вам за выполнение чего-то сказанного мимоходом и нигде не зафиксированного обещают кучу плюшек и всяких благ. Лучше прослыть «ничего не понимающим в бизнесе», чем оказаться крайним, когда очередной такой персонаж будет на вас пытаться повесить свои косяки.
Типы же первичны? Ошибся в типе, описал функцию как минус. Когда писал реализацию функции, IDE мне сказала, чувак тут надо "-" судя по типу, ну я и исправил на "-", хотя по тз там плюс.
но ведь ты тоже проигнорировал, как соответствие карри говарда поможет от неправильно поставленной/понятой/решенной задачи?
Почему ты допускаешь что в функции ошибиться можно, Но в тоже время уверен что в типах ошибиться нельзя, перенеся потом эту ошибку в реализацию?
или понятой задачи не поможет вообще ничего. Вообще
Я так и сказал.
Едиственно в чем мы расходимся это
Но это не логическая ошибка.
Особенно если не доводить до абсурда, типа
вас попросили автопилот для машины, а вы сделали автопилот для самолёта
Что ж тогда логическая ошибка, функция хочет число, а мы даем ей строку?
Проверить входит ли в диапазон доступных значений номер кредитной карты, типы допустим могут. Но кому от этого проще, если программист неверно вбил этот диапазон в определение типа, а не в рантайм проверку в функции?
А если мне сказали закодить биржевого бота, который будет торговать на какой-нибудь азиатской бирже только в рабочие дни, то, например, если я неправильно скопирую список праздников (или нагуглю список не для той страны), то типы едва ли это помогут отловить, конечно. Но как это отлавливать — вообще непонятно.
Хуже. Список рабочих дней может как в России определяться в предыдущем году по решению Правительства. Или как с "нерабочими" днями. По ходу дела.
Вообще удивительно, что только 0xd34df00d реально вернулся к истокам. Все это программирование — это не код ради кода, а код обработки данных. А все данные типизируются. А код — это просто функции превращения одного в другое.
у него большая проблема: многое из того что он говорит базируется не на научном подходе, а на религиозных предпочтениях/взглядахНу хоть с тем, что ЯП со статической типизацией убирают множество проблем с ошибками типов вы согласны?
однако надо помнить (и это исследовал ещё Ларри Уолл), что большинство проблем с ошибками типов связаны с тем, что в языках некорректно сдизайнены операторы сравнения и математические операции.А ещё нужно помнить, что когда эта «глыба», эта «гора», этот «гений» решил создаить что-то на основе своих идей… то получился высер такого микроскопического размера, что о нём даже как о мыши-то говорить смешно.
и чем крута динамическая типизация: что программист больше думает об алгоритме, нежели занимается обрядами вокруг его реализацииСерьёзно? И потому как только вам требуются реально серьёзные алгоритмы (распределённые базы данных или хотя бы SQL-базы, компиляторы, операционные системы и всё такое прочее) — так прям все на динимических языках начинают программировать? Вы это сейчас серьёзно?
Знаете — весь этот ваш пафос был бы слегка более уместен если бы подверждался опытом. И вы могли назвать хотя бы одну систему, где динамически типизированный язык — это не «пенка» на базисе из модулей на статически типизированных языках, а что-то, что сущесвует само по себе. Хотя бы.
Уж не говоря о том, что если бы динамически типизированные языки были бы так круты, как вы описываете, то именно они должны были бы формировать базис, а на статически типизированных языках люди бы писали что-то, ошибки в чём были бы не так опасны.
и это путь решения тех же проблем но на дороге динамической типизацииЭто махание руками. Давайте ближе к практике:
1. Реализация динамически типизиванного языка на динамически типизованном языке же: ___
2. Операционная система на этом самом динамически типизованном языке: ___
3. База данных на таком же языке: ___
4. Процент рынка, который вот всё это заняло в ___ году: ___
Вот как заполните пропуски — так сможете лить в уши сказки про преимущество динамической типизации в деле реализации алгоритмов. А до тех пор — это всё рассказы условного «таджика» умеющего неплохо строть туалеты и двухтажные домишки дендрофекальным метордом о том, что у оного метода есть масса преимуществ перед сталью и бетоном, а что какие-то идиоты из говна и палок даже не пытаются строить мосты и небоскрёбы — так это потому что у архитекторов и инжинеров-строителей умишко слабенький и нет того опыта строительства туалетов, что «таджика»…
назовите три полезных программы на Расте/Хацкеле стоящие на большинстве компьютеровНазовите хоть одну такую на Raku для начала. Или вам можно выбирать языки, а мне нельзя? Вы же сами тут поёте песни про крутизну Ларри — ну вот покажите… на практике.
динамически типизированные языки — это скриптовые языки, прежде всего.Внезапно как, а. А почему так, не расскажите? Почему языки, в которых «программист больше думает об алгоритме, нежели занимается обрядами вокруг его реализации» не применяются там, где алгоритмы сложны и о них действительно приходится думать — но всё больше там, где алгоритмы тривиальны и думать о них не нужно?
затем попробуйте удалить Perl и Bash. и посмотрите на результатИ много вы алгоримов на Bash написали? Я как-то писал топологическую сортировку банальную — то ещё равлечение было. В Android, кстатати, нет ни Perl, ни Bash. И ничего — работает как-то.
А вот попробуйте оттуда удалить модули, написанные на C…
Вы хотите сказать что языки со строгой/статической типизацией все находятся в стадии «бета» (== «ещё не доделан»)?Я хочу сказать, что с идиотами, записывающими в языки с динамической типизацией C и Java разговаривать бессмысленно. Хотя вас я идиотом не считал, но… теперь вижу._
Статически типизированный язык, между прочим
Да, предствьте себе — даже такая слабая типизация, как в C, и даже при такой ужасной культуре кода, как в openSSL (поговорите с теми, кто внутрь смотрел) всё равно снижает количество уязвимостей. В каком-нибудь NGINX — их меньше на порядок. В Chrome — да, побольше будет… но вы когда-нибудь сраванивали по объёму Drupal и Chrome? Сравните как-нибудь на досуге.
поэтому языки вроде C, C++, Java (и прочие языки традиционно ориентированные) — это языки, которые я противопоставляю высказываниям сектантов.У… как всё запущено. Что такое вообще «традиционно ориентированный язык»?
именно строгую типизацию сектанты вроде 0xd34df00d противопоставляют тестам.Серьёзно? У вас всё с логикой настолько плохо?
Извините, но я нигде и никогда не слышал, чтобы 0xd34df00d говорил о том, что типами нужно заменять тесты. Он всегда говорит о том, что можно — и да в Idris это попроще, а в C++… ну на спор, наверное, тоже можно, но в реальной программе — не получится.
Вопрос того, что нужно выражать ограничениями на типах, а что лучше оставить в виде тестов — он совершенно отдельный от вопросов принципиальной реализуемости того или иного подхода.
Давайте теперь Вы назовите пару монополистов, имеющих аудиторию в миллиард людей, чтобы их основной язык был со строгой/статической типизациейВы издеваетесь или как? Ну пусть будет Google и Microsoft, если уж так хотите. Только не рассказывайте сказок про то, что Microsoft меньшая монополия, чем какой-нибудь Facebook: в китае без Facebook отлично живут, а без Window — таки не обходятся. Ну или Apple возьмите — да, это не монополия… но денег она зарабатывают больше, чем Facebook и Mail.Ru вместе взятые.
то FaceBook — это PHP.Нет. PHP такую махину не потянет. Facebook — это Hack. И да — он статически типизирован.
На Java. Какой смысл уходить на Python для такой нагруженной задачи?
(распределённые базы данных или хотя бы SQL-базы, компиляторы, операционные системы и всё такое прочее) — так прям все на динимических языках начинают программировать?
Однако же поверх всех этих замечательных программ тут же возникают динамические языки — шеллы или тот же SQL. SQL сильно типизирован?
Совпадение? Не думаю.
Так никто вроде бы и не спорит, что в качестве glue code для одноразовых задач динамические языки вполне себе работают.
Совпадение? Не думаю.Нет, конечно. Как только вы решаете, что вам не нужен качественный код, но нужны дешёвые программисты — так динамические языки становятся, вдруг, резко осмысленными.
Программисты на PHP получают меньше, чем программисты на C++, а администраторы («программисты на bash») — ещё меньше.
В некоторых случаях возможна и обратная ситуация (финансовый аналитик, пишущий только программы на каком-то простеньком язычке, но никак не на C++ — может получать и больше программиста на C++), но в этом случае они получают столько не за то, что умеют лихо писать программы на Python, а за что-то совсем другое.
Где-то тут уже приводил: в Киеве разница между PHP и Javaсеньорами порядка 5% всего. Это во столько бизнес оценивает надежность статической типизации (забудем про то, что часто Java и быстрее)?
к чему тогда пассажи про "нужны дешёвые программисты — так динамические языки становятся, вдруг, резко осмысленными. Программисты на PHP получают меньше, чем программисты на C++"
У меня есть цифры, что эти "дешевые" лишь на 5% дешевле, а разница в качестве, вроде как, качественная, если верить адептам статики.
У меня есть цифры, что эти «дешевые» лишь на 5% дешевлеНет у вас таких цифр, извините. У вас есть информация про кое-что другое.
Разница между дешёвыми и дорогими программистами лишь слегка кореллирует с зарплатой.
Более того — в некоторых случаях программист, получающий более высокую зарплату может оказаться дешевле.
Подумайте над этим.
а разница в качестве, вроде как, качественная, если верить адептам статики.Разница качественная — но не между динамикой и статикой.
А между продукцией «дешёвых» и «дорогих» программистов.
Я это уже показывал на примере CVE.
И да, разница между зарплатами — гораздо меньше, тут вы, что забавно, тоже правы.
> В языке «ться» и «тся» не различаются, они различаются лишь на письме, которое представляет собой условность. Потому, собственно, их и путают на письме.
В языке у них разная роль, что можно увидеть, например, по тому, что для некоторых глаголов вместо "-ться" получается "-тись": нестись, пастись…
(это как раз о типизации;))
В фонетике, да, они сливаются — но уже после этого.
И если мы обсуждаем преимущества разных видов типизации, то, ИМХО, лишний раз указать на принципиальное различие между типизацией и рантайм-проверками, которое по-хорошему должно быть определено даже в терминологии, вполне себе стоит.
Так никто не против указывать на различия статической и динамической типизации. Более того, никто вроде не отрицает, что с некоторой точки зрения правильнее эти две альтернативы называть по-другому. Но для того, чтобы как можно больше людей, связанных с программированием, вас сразу без дополнительных пояснений правильно понимало, нужно использовать именно «статическая типизация» и «динамической типизация» — это устоявиеся названия классов языков. Можно для себя их называть как угодно, но все (?) официальные документы по динамически типизированным языкам программирования используют слова «тип» и «динамическая типизация»/«динамическая проверка типов» — например python, js. То же верно и для обсуждений этих языков на практике. Поэтому смена терминологии привнесёт только путаницу на этом этапе.
В моей IDE для хаскеля вообще нет рантайм-меток (да, я за всю практику пользовался Typeable в своём коде ровно один раз). Да и дебаггером я там не пользуюсь.
Если вы им не пользуетесь это не значит что его нет. Я посмотрел — оно умеет как-то определять тип в рантайме.
Кстати, определите до конца термин "рантайм метка" он не отражает метка чего именно.
В моей IDE для плюсов их тоже не особо много для рантайм-поведения.
А что у вас за IDE для плюсов? У вас там нет cимволов и RTTI? в окне watch нет колонки type для переменных? Или там написано что-то типа "рантайм метка относящаяся к набору операций которое можно совершать со значением"?
А зря. На мой взгляд, создаёт неправильные ожидания.
Какие и у кого?
Не обязательно. В том же хаскеле в общем случае после того, как вы проверили типы, вы можете их стереть и не иметь вообще ни намёка на них в рантайме.
Я хаскель знаю очень поверхностно. Мне трудно с этим поспорить.
С моей точки зрения, терминология, которую вы предлагаете требует введения разных слов для одного и того же и необщепринята, т.е. никакой выгоды от нее нет.
прекрасный термин, и никого не обманывает
Скорее не линтерами, а статанализаторами. Да, если использовать все возможности языка на полную, не помогая анализатору тайпхинтами и аннотациями, то много ошибок типов будет как ложно положительных, так и ложно отрицательных, но тем не менее как современные IDE, так и отдельные статанализаторы широко используют информацию о типах из исходников.
Можно писать на Idris и эммитить код на PHP
Тот, кому первому пришла в голову идея назвать рантаймовый контроль типов «типизацией» — будет вечно гореть в аду за обман джуниоров.
А как по вашему это нужно называть?
Типизация в PHP как была динамической и слабой, так и осталась. И нет никаких предпосылок к изменению этого положения.
Контролем типовВроде это по определению делается во всех системах с проверками типов. Ну там Rust, Haskell. На другом этапе, конечно.
Я не понимаю отчаянного сопротивления применению определенного уважаемого термина к РНР и попыток его замены на какой-нибудь другой, не такой уважаемый.
Типизация в PHP как была динамической и слабой, так и осталасьКстати, вы будете гореть в аду
Тот, кому первому пришла в голову идея назвать рантаймовый контроль типов «типизацией» — будет вечно гореть в аду за обман джуниоров.
Если это не typing (типизация), то как сообщить другому человеку «Я придумал ЯП с динамическим blabla» и остаться понятым?
«Можно ли на этой переменной дёрнуть эту функцию?»Но если мы хотим донести, что эта переменная ведёт себя как string ибо помечена таковой средой выполнения, то нам придётся долго перечислять список функций (и всё равно можем не попасть, потому что у другого типа может быть такой же, но он к примеру несовместим со string). Нам же нужны обобщения.
вы придумали язык без статической типизации.Это можно, да. Термин взаимоисключающий.
Проблема в том, что всё это противоречит естественному языку как средству коммуникации. Лучше было бы придумать для формальных понятий другие слова, например «типоид» и «типоизация». Тогда можно было бы смело поправлять других «Вот это ни в коем случае нельзя называть типоидом по определению», «в этом ЯП не может быть никакой типоизации» и никто бы и слова против не сказал.
Я не знаю, как это было с исторической перспективы, но сейчас частичное пересечение узкоспециального термина с широким общим играет отрицательную роль для первого.
Но да, это не про питон.
Можно просто сказать, что вы придумали язык без статической типизации.
Это может быть и безтиповый язык типа популярных ассемблеров.
А джунам тем стоит взять JSP если уж на то пошло)
В "компайл-тайме" в клиентской коде мы не можем знать что загрузит автолоалер или какая имплементации интерфейса придёт. Вообще проверки не будет?
Компайл тайма нет. Проверка будет только при статическом анализе и канеш в рантайме. Поэтому индустрия пыха требует монструозного техпроцесса на нескольких стадиях.
Ну какой-то компайл тайм есть: преобразование в опкоды. В рамках одного класса можно было бы в нём что-то по минимум проверить, но вот весь проект проверить нереально, по крайней мере с доминирующей моделью автолоадинг классов.
С Java или С# о компиляции в байт-код говорить можем, а с PHP не можем?
А 8 с JIT уже есть https://github.com/php/php-src/blob/master/UPGRADING :)
Java на JIT, насчёт C# не могу сказать ничего. А 8 с JIT ещё только в альфе, первый релиз-кандидат вроде как только осенью будет, а сам релиз в декабре.
В пыхе компиляция пока что относится только к сборке самого бинарника руками) А наш с вами код интерпретируется, это сильно другой процесс.
В альфе, но есть :)
Тут о терминах можно спорить долго. javac запускает компиляцию в байт-код, который отдаётся виртуальной машине. Раньше она его просто интерпретировала, сейчас JIT везде или почти везде. php запускает компиляцию в байт-код, который отдаётся вирткальной машине. раньше она его просто интерпретировала, сейчас JIT в мастере. В чём качественная разница? В отсутствии файла с байт-кодом?
Вопрос ведь не в терминах, ну и не спорю, если грубо — то можно свести к фразе компилится.
Для меня лично компиляция — строго вне рантайма. Если код попадает в кучу когда пришли данные на обработку — интерпретация. Отсутствие файлика — огромная разница в процессе.
Ну и ещё у меня стойкое чувство, что вы меня стебете)
/ пошто пыхоиндуса обижаете? :( /
Ну вот JIT тогда не компиляция? Файлика нет же. :)
А если серьёзно, то в современной разработке грань между компиляторами и интерпретаторами размылась — слишком многое под капотом, на что программист никак повлиять не может обычно.
У вас слишком узкое представление.
PS На всякий случай подчеркну, это вопрос, а не утверждение.
Проверка типов происходит точно на рантайме, когда данные переданы в поток (то есть код уже в куче)
Если развернуто:
1. В зависимости от версии пыха и правил типизации (strict_types) проекта на этапе разработки (локально) доступны:
1.1. Анализ самого IDE в режиме реального времени
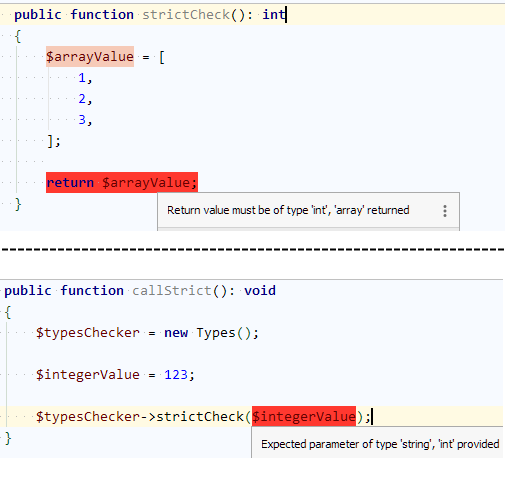
1.2 Встраиваемые пакеты для статического анализа codestyle
1.3 Встраиваемые пакеты для стат анализа codequality
2. Дальше в крупных проектах CI/CD, со стендами для предварительных тестов регрессии, интеграции, фича тестов и вероятнее всего 1.2 и 1.3 повторные.
3. Дальше, в зависимости от критичности проекта, может быть ряд canary продакшн серверов, на которых крутятся «свои» юзеры, которые выступают в роли кроликов-тестировщиков.
4. Ну и сам прод собственно. Тут вызывается код, интерпретируется в псевдокод для виртуальной машины (например нгинкс), выполняется до определенного адреса, там происходит ошибка и бросается исключение (от нотиса до фатала) — вот последнее это рантайм.
А так, по топику могу сказать одно.
Типизация нисколько не спасает от багов на проде.
Чаще всего прод на пыхе страдает от кривой логики реализации бизнес-процесса или не до конца протестированных юзкейсов.
Орут о величии строгой типизации над динамически типизированными языками в основном фронтендеры, которые пересели с js на ts и решили, что они не верстальщики, а программисты =)
Не так плоха динамическая типизация, как ее сочетание со слабой, js, php привет вам.
Вот это уже взрывная смесь по производству багов.
print((not None) + 7)Типичная слабая типизация.
Да, у Python отсутствует автоматическое преобразование число<->строка и возможности преобразования None ограничены. Но в остальном PHP может обеспечить более строгий контроль типов. Аннотации типов аргументов подпрограмм в Python не обеспечивают контроль типов — в отличие от PHP, в котором реализуется реальный контроль и типов аргументов (с возможностью отключения преобразования число<->строка), и типа возвращаемого значения.
Сначала None автоматически преобразуется в bool, потом bool автоматически преобразуется в int.
Типичная слабая типизация.
Оператор not возвращает True или False. Тип bool унаследован от int, поэтому в арифматическом смысле True всегда равен 1, а False всегда равен 0. У вас не получится сделать None + 1.
gaal@catalina monitoring % python3
Python 3.7.6 (default, Dec 30 2019, 19:38:26)
[Clang 11.0.0 (clang-1100.0.33.16)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>>
>>> print((not None) + 7)
8
>>> print(None + 7)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unsupported operand type(s) for +: 'NoneType' and 'int'Python 3.7.5rc1 (default, Oct 8 2019, 16:47:45) [GCC 9.2.1 20190909] on linux Type "help", "copyright", "credits" or "license" for more information. >>> not [] True >>> not "Oops" False
Операция «not» применима к чему угодно. То есть там «None» не преобразуется в Bool. А что
True/False — разновидности целых… это странно, но это Python унаследовал от C. Он ещё парочку странностей от него унаследовал…В моих книжках написано, что not (not x) = x для всех допустимых x, значит, None эквивалентно not (not None).
Ещё раз. У вас не получится сложить None и 1. Оператор not это логический оператор отрицания, который возвращает строго True/False. Двойное инвертирование True вернёт True и наоборот, эта цепочка из not not not [...] может быть бесконечной. Не понимаю, что мы обсуждаем?
Да, это всего лишь ещё один способ указать на unsoundness языка.
Ну, назовите это консистентностью языка. В целом проблемы нет, согласен.
Уже давно это не так.
Да, есть unsound-элементы, но они связаны с изначальными ошибками (или компромиссами) в дизайне системы типов, и о них думают, как бы их устранить.Лучше бы они подумали как «людям снаружи» дать доступ ко всему этому.
Либо объявите GHC «единственной правильной версией» (и тогда версии языка будут соответствовать резлизам GHC), либо сделайте уж, как в C++, регулярные релизы. А то официальной версии 10 лет, а что из бесконечного количества расширений и дополнений, доступных после этого, считать «официальной частью языка» — «снаружи» понять невозможно.
Далеко не у всех есть возможность следить за всей «движухой», если они хотят попробовать Haskell на примере задачи генерации какого-нибудь отчёта.
А с устранением косяков вопрос сложный, на самом деле: в Python считается идеоматичным не писать в
if всякие "== 0" или "== []" (хотя лично я это считают некрасивым как раз) из чего, как бы, очевидно следует, что и not должен работать со всеми типами — иначе будет нелогично.Де-факто это уже давно так.А как до этого догадаться? Захожу я на www.haskell.org (а куда надо было зайти?), открываю раздел с документацией — первым делом, первой ссылкой, меня отправляют на Learn You a Haskell for Great Good!, где есть прям целаю душешипательная история про то что Монада — это не Applicative. Ладно, это тьюториал, они часто не поспевают за развитием языка. Ищем описание языка… единственное, что там есть — это Haskell 2010. Если погуглить — можно на wiki найти информацию про Haskell'… ссылка ведёт на сайт, который не отвечает, а страничка на archive.org радостно сообщает, что Haskell Prime 2020 committee has formed — «свежая» новость от 2016го года.
Ну и куда мне идти, чтобы что-то узнать, а главное, как до этого догадаться?
Сравните с C++. Wikipedia отправляет на isocpp.org. Там есть анносы GCC 10.1 (релиз от 11 мая 2020го), есть ссылка на Core Guidelines, можно добраться до драфта (хотя было бы полезнее, если бы ссылка была бы поближе к корню isocpp.org, а так туда приходится идти через cppreference).
А где у Haskell-community что-то подобное?
P.S. У C++-комьюнити есть, правда, своя, особая фишка: бесконечные
draftы. Попытка найти хоть чего-нибудь отрелизнутое — обречена на неудачу. Нужно некоторое время «повариться», чтобы понять, что это — следствие бюрократии ISO, которое привело к тому, что все и всегда используют draftы. Релиз, типа-вроде-как окончательная версия, никого не интересует настолько, что если draft будет говорить одно, а релиз — другое, то реализуют именно draft: их используют разработчики компиляторов, программисты и вообще все, кто мало-мальски интересуется C++. А релизы? Ну их ISO за деньги продаёт, можно купить и положить на полочку. Всё. Больше в них никакого смысла нету. Да, этот «секрет Полишинеля» сходу, на web-сайте не найти…1 + "hello" => TypeError (String can't be coerced into Integer)А я говорю, что описание типов — и есть описание процессаЭ? Вообще-то описание _процессов_ — это функции/процедуры.
Код на динамических языках не только пишется легче, но и легче читается. Поэтому многие ошибки видны невооруженным глазом.
Но с определенного размера кодовой базы все связи уследить уже просто не возможно, и вот тут на помощь приходит статическая типизация.
В общем, для каждой задачи — свой инструмент.
Не совсем так. Динамически-типизированный код может вообще не отличаться от статически-типизированного, просто автоматический вывод.
function foo (string) : string { } // error В хаскеле сделано удобнее. Но это имхо и вкусовщина, не буду спорить если у кого-то другое мнение.
function f(a: number): string;попробуйте так
В Вашем варианте foo я понятия не имею, что за строку она от меня хочет, но стоит написать вот так:
function foo(userName: string): string;
И да, по-нормальному было бы вообще так:
function foo(userName: UserName): string;
Вобще-то даёт. Гуглите брендированные типы.
import {
$mol_data_nominal as Unit,
$mol_data_integer as Int,
} from "mol_data_all";
const Weight = Unit({ Weight : Int })
const Length = Unit({ Length : Int })
let len = Length(10)
len = Length(20) // Validate
len = 20 // Compile time error
len = Weight(20) // Compile time error
len = Length(20.1) // Run time error
let mass: typeof Weight.Value
mass = len // Compile time errorА Delpha/Pascal — это уже «закат эпохи». Когда теоретики заизолировались у себя в башне, а практики начали делать «удивительные открытия», известные теоретикам в середине прошлого века.
type UserName = string & { readonly tag: unique symbol };
type Password = string & { readonly tag: unique symbol };
const nameOf = (name: string) => name as UserName;
function stringOf(name: UserName): string {
return name;
}
stringOf(nameOf("bingo347")) // OK
stringOf("bohdan-shulha") // Argument of type '"bohdan-shulha"' is not assignable to parameter of type 'UserName'.
stringOf("hellowrld" as Password) // Argument of type 'Password' is not assignable to parameter of type 'UserName'.Вот я и говорю, что это не работает, любую строку можно просто привести к типу UserName без доказательства последнегоconst nameOf = (name: string) => name as UserName;
Я могу ошибаться, но вы именно о таком поведении писали в комментарии выше.
А как доказать, что строка, которая пришла с сервера, это действительно UserName, а не что-то иное?Проверить, что она соответствует всем ограничениям на тип UserName, если проверка успешна — я получу тип UserName, иначе получу ошибку. Другого способа получить тип UserName в программе нет, поэтому ему можно доверять. А вот типу, в который можно просто кастануть любую строку я доверять не могу, он для меня бесполезен.
Но я согласен с автором что «в продакшене» всё-таки лучше использовать языки со статической типизацией.
В плюсах же как раз есть пользовательские суффиксы.
Ну и, кроме того, всё уже сделано до нас: Boost.Unit
Писать много много оберток над тривиальными математическими операциями и сравнениями. Фактически копипаст. Нельзя просто сказать что вот этот int будет метры, этот секунды, а этот тугрики. Плюс взаимодействие сложных типов вышеупомянутое.
Там ограничения есть, например, для целого это всегда long long int, а зачем мне это, если я метры хочу только int32.
Другое дело, что можно все в классы обернуть… тогда точно, одно с другим не сложишь. Но это конечно дополнительно писать придется кода...
В C++ как раз сложишь, если оператор + переопределишь :)
И как так просто метры с миллиметрами сложить? Переопределить то можно… придется делать столько этих операторов, сколько типов собираетесь складывать.
Для такого есть std::ratio
Хорошо, Фаренгейты с Цельсиями.
температуру с температурой складывать нельзяВот у меня литр воды 20 градусов и 5 литров 50 градусов, как мне посчитать температуру смеси (пренебрегая теплопередачей посуде и воздуху)? Всегда думал что для этого нужно средневзвешенное значение находить (в кельвинах), а для этого множить на скаляры и складывать.
Фаренгейты и Цельсии изоморфны, можно перевести одно в другое и сложить.В том-то и дело, что они нифига не изомрфны. Сколько будет 1°C + 1°F? А фиг его знает: может быть 15⁄9°C, может быть -304⁄9°C. И без дополнительной информации вы это не узнаете.
Да, тут есть неоднозначность, каким должен быть тип результата, но это вполне может зависеть от вызывающего кода, и какой тип он там ожидает.Если бы речь шла только о типе результата — беды бы не было. К сожалению меняется ещё и значение этого самого результата.
Результаты, как несложно заметить, будут сильно разными.
Потому — только перевод в Кельвины (ну или, если очень приспичит, в Ранкины), потом что-то там можно считать…
Просто группа градусов как дельт действует (ну как в алгебре) на множестве градусов как температур с привязкой к абсолютному нулю или ещё чему-нибудь.Не совсем так. В отличие от времени для температуры ноль имеет чёткий физический смысл: это средняя квадратичная скорость поступательного движения молекул (вернее пересчитывается в неё через постоянную Больцмана. Потому для неё не нужны все эти сложности.
Но это только в Келвинах или Ранкиных.
Если же вы хотите что-то считать в Цельсиях или Фаренгейтах… то да, можно развести весь этот дуализм… но обычно не нужно. Ибо всё равно запутаетесь.
Вы как-будто в школе физику не учили. Первым делом в любой задаче было привести все параметры к СИ. С другой стороны это очень странная система, если вам приходится складывать такого рода значения. Но в целом проблема N+1 операторов существует. В соседней ветке предложили использовать Boost.Units для таких штук, но если я правильно понял доку, то там собственно все для единиц измерения СИ и его альтренатив вроде СГС. Если нужны будут свои собственные еноты на парсек в час, то кучу бойлерплейта писать все равно придется.
int meters = 1;
std::chrono::seconds seconds{1};
auto val = meters + seconds;А библиотеку обернуть:
int flib_mul2(int i){
return i * 2;
}
std::chrono::seconds mul2(std::chrono::seconds i){
return std::chrono::seconds{flib_mul2(i.count())};
}
int main()
{
std::chrono::seconds seconds{1};
auto seconds2 = mul2(seconds);
}
Haskell же!
{-# LANGUAGE GeneralizedNewtypeDeriving #-}
newtype Seconds = Seconds { getSeconds :: Int }
deriving NumRust же!
use derive_more::Add;
#[derive(Add)]
struct Seconds(u32);Например squants:
scala> val energyUsed = 100.kilowatts * (3.hours + 45.minutes)
energyUsed: squants.energy.Energy = 375000.0 Wh
scala> val energyUsed = 100.kilowatts + 3.hours
^
error: type mismatch;
found : squants.time.Time
required: squants.energy.PowerВ F# есть такая встроенная фича, называется units of measure. Очень удобная, в моём физическом коде пару ошибок помогла поймать.
Во многих других функциональных языках, в которых есть конструкции вида newtype, это также делается достаточно изящно.
(забавный факт: автор обсуждаемой статьи как раз тоже топит за F#)
В F# есть такая встроенная фича
Там степени только целые, а хотелось бы рациональные иметь.
Вроде в какой-то версии это допилили. У меня работает, например, такое:
[<Measure>] type cm
[<Measure>] type xx = cm ^ (1/3)
let a = 10<cm>
let b = 10<xx>(извините, хорошего примера я не придумал, и даже помню, как во времена введения этой фичи ломал голову — где она может понадобиться; ни одной физической величины, использующей такие единицы, мне в голову ни тогда, ни сейчас не пришло)
чем же js чист?
Несите нового!
Динамическая типизация — адское говнище
Погодите это про отсутствие типов а ля питон или разрешения типов компилятором в F# перед компиляцией?
Может все-же в некоторых ситуациях оно таки надо, м?
Да и те-же темплейты в C++ это шаг в сторону динамических типов…
Он шаг в сторону строгой типизации как раз
template <typename T>
class Summ
{
T x;
public:
Summ(T value): x(value) {};
Summ(): x(0) {};
Summ operator+(Summ const& rhs) const
{
Summ result ;
result.x += rhs.x ;
return result ;
}
};
Summ<int> sum0(0);
Summ<float> sum1(2.0f);
sum0 = sum0 + sum1 ; //Такое не проканает
int sum00(0);
float sum01(2.0f);
sum00 = sum00 + sum01 ; //а такое проканаетsum00 = sum00 + sum01 ; //а такое проканает
Предупреждение C4244: преобразование «float» в «int», возможна потеря данных
Warnings as errors и такое не проканает.
Это какой то специальный ворнинг, скорее всего с ключём диагностики, потому что GCC и Clang без ключей никаких ворнинга не дают. Это же не запрещено стандартом. Просто неявно тип катится к другому.
А так конечно со статическим анализатором можно все узкие места находить на этапе компиляции.
Для GCC есть -Wconversion
Естественно, что он не включён по умолчанию, так как обычно это ненужно.
Опции компилятора для того и есть, чтобы настроить под конкретные нужды. Компилировать без настроенных флагов, значит полагаться на дефолтные значения. Далеко не факт, что это те настройки, что требуются.
А каким образом темплейты — шаг в сторону динамики, непонятно.
Ну как-же. Вы ведь можете подставить в темплейт любой тип, или переменную, т.е. строгого типизирования нет. Понятно что с точки зрения компилятора все будет все равно типизировано строго, но с точки зрения программиста чем не «динамический» тип?
Собственно концепты и ввели чтобы изобразить что-то вроде типизирования для темплейтов.
any почти наверное означает, что где-то сделана ошибка
Либо что оно прилетело оттуда, где у вас нет власти
В играх ECS без std::any довольно сложно представить, особенно когда это дело еще из сети откуда-нибудь качается.
Если речь про примеры кода, то сходу едва ли. У нас используется для сериаизации-десериализации данных с нашей админки в основном. На основе json питонячий скрипт генерит шаблоны полей, магия макросв и бустовых лексеров и бустового же any (который собственно предок std::any) рождают на свет класс в который собственно грузятся данные с админки. Есть, конечно, альтернативы вроде того же protobuf с похожим пайплайном, но под наши задачи он не подходил т.к. для синхронизации шаблонов нужно было б делать правки полей в нескольких местах и перегенерациию также соотвественно в нескольких местах, а так в админке выставил галку на отгрузку, клиенту шаблон перегенерировал и пользуйся.
Как вариант могу предложить почитать расширеный вариант выступления разработчицы из chucklefish про переезд на Rust и собственно переходу к ECS архитектуре. Там есть кусок про AnyMap.
У вас же игровой движок — это по сути отдельная тьюринг машина со своим описаниям мира и мутациями над этим самым миром. Как там можно по-другому?
Неудивительно, что в тех же майнкрафтав на стандартных блоках умудряются вычислители собирать (ну, или на dwarf fortress)
Можно кучу лапши из классов, например. И если это не UE или Unity, то это довольно частое явление. Подсмотрите как делаются игры на каком-нибудь cocos2d-x или love2d, или новеллы на RenPy. Последним ECS редко нужна, например — там от того тьюринга только переключение экранов.
А что это она тьюринг машина? Может это просто лямбда-функция или декартово-закрытая категория (;
На хаскеле неплохо пишется ECS без std::any.
А много тех игр на хаскеле? Чтоб с графонием и грабить корованы можно было. Всякие шахматы и крестики-нолики в расчет, соотвественно, не берем. Использование ECS вне контекста игр тоже.
For science it worked flawlessly
Try using it for graphics
Write in C…
Какое количество требуется чтобы аргумент стал валиден?
Хотя бы штук 5 и суммарное количество игроков было хотя бы over 9000. Или хотя бы исходники размером с какой-нибудь battle fo wesnoth
Думаю у MagicCookies уже есть больше 9000 игроков. Плюс три игрушки только я сам написал. Думаю ещё одну можно найти.
А ссылки хоть на что-то можно посмотреть? Гугл выдает слишком разнообразную выдачу, включая мод на майнкрафт.
Я думаю можно просто пойти почитать реализацию ECS в хаскеле и посмотреть, что там используются вполне статические функции на типах, а не динамические касты.
Если я правильно прочитал, то вместо any у хаскела стирание типов происходит через Data.Proxy. Какие накладные расходы по памяти/процессору при этом возникают и возникают ли- для меня вопрос.
А вообще предложение почитать, что-то вроде
forall w m c. Set w m c => Entity -> c -> SystemT w m ()
довольно сомнительно. С синтаксисом хаскела знаком мало и гадать, что за однобуквенные параметры большого желания нет.
А ссылку на магические печеньки все же приложите.
Шаблоны в C++ это и есть, как сказал бы автор статьи, "адское динамическое говнище". И как раз в C++20 это попытались исправить так называемыми концептами.
Не понял, как темплейте и динамические типы вообще связаны? Темплейты наоборот — шаг в сторону строгой типизации… Каждый темплейтный класс — это новый тип. И по идее будет проблема, если вы будете их складывать, например, в случае складывания float с int.
template <typename T>
class Summ
{
T x;
public:
Summ(T value): x(value) {};
Summ(): x(0) {};
Summ operator+(Summ const& rhs) const
{
Summ result ;
result.x += rhs.x ;
return result ;
}
};
Summ<int> sum0(0);
Summ<float> sum1(2.0f);
sum0 = sum0 + sum1 ; //Такое не проканает
int sum00(0);
float sum01(2.0f);
sum00 = sum00 + sum01 ; //а такое проканает
Обобщенные, и динамические разные вещи. В обобщенную метод код будет подставлен все равно конкретный, с конкретным типом, где вы не сможете float сложить с int. Там будет либо float, либо int. И да, все это проверится компилятором, во время компиляции.
Не совсем так, если вы сделали условно обобщенный метод, который может считывать из файла float, или int. Откомпилировали программу с только float методом, так как предполагаете, что правильный файл всегда содержит только float и дали ему на вход int — он выдаст ошибку. А в вашем случае, любой файл подай на вход — он его обработает, только вопрос как?
Интересно, сможем ли мы зайти ещё дальше, и повсеместно взяться за формальную верификацию программного обеспечения? Ведь мало проверить соответствия типов — хотя, на мой взгляд, лучше, чем не проверять — в целях повышения надёжности было бы выгодно сделать невалидные состояния невыразимыми, и вообще, формально доказать, что софт работает корректно во всех возможных сценариях. К сожалению, сейчас такое экзотическое удовольствие дороговато.
Верификация дизайна намного проще, но для её использования требуется преодолеть культурный барьер. Думаю, ситуацию можно изменить. Двадцать лет назад автоматизированное тестирование и код-ревью были довольно экзотическими и нишевыми темами, но в конечном итоге стали мейнстримом.
— Почему люди не используют формальные методы? Хабр, 2019.
А в F# изобрели type providers. Которые, тем не менее, в продакшене пока встречаются нечасто.
Интересно, сможем ли мы зайти ещё дальше, и повсеместно взяться за формальную верификацию программного обеспечения?
Сможем, когда придёт время:
«Formal methods will never have a significant impact until they can be used by people that don’t understand them» (с) Types And Programming Languages
Не думаю, что время, о котором тут говорит Пирс, настанет.
Я не думаю, что оно настанет в обозримом будущем.
Это, ну, как программировать, не имея ни капельки алгоритмического мышления.
К слову, нужен ли какой-то бэкграунд в математике/теории типов чтобы более-менее продуктивно писать на каком-нибудь Идрисе, или можно всё покрыть документацией(или книжкой по языку)?
Как там, кстати, поживает SQL для создания отчётов теми же менеджерами?
Вполне нормально живёт, если не требуется высокой производительности или если нет строгих требований к форме. Типовые задачи, вроде управленческого учёта, закрываются готовыми инструментами. Там где нет готовых, колхозят на коленке на SQL или на Excel или даже на R.
Если предположить, что SQL "отменят", то для простого подсчёта данных и фильтрации придется писать программу для чтения файликов.
"Менеджеры" в наше время уж точно такого не пишут.
А в F# изобрели type providers.
Выглядит круто. Аж захотелось на F# перейти.
в динамических языках а-ля жабаскрипт или РНР — строгая типизация только помогает при работе с большой кодовой базой, где уже есть своя куча классов и их иерархия и т.д.
если кодовая база маленькая — строгая типизация только мешает, т.к. создает накладные расходы на то, что нужно писать эти типы и поддерживать и не дает всех преимуществ динамического языка/интерпретатора.
Я люблю динамическую типизацию в маленьких программах узкого предназначения т.к. она позволяет полностью использовать всю экспрессивность языка и писать код очень быстро и эффективно.
Автор — а как вы думаете почему игровую логику везде пишут на Lua? Вот дураки игроделы, ведь на плюсах типизация гораздо лучше и компилятор дает гарантии
в динамических языках а-ля жабаскрипт или РНР — строгая типизация только помогает при работе с большой кодовой базой, где уже есть своя куча классов и их иерархия и т.д.
Я ни один скрипт не стану писать без типов, если его будет кто-то читать(а его будет, кроме единственного случая, когда я хочу что-то сделать и удалить на локальной машине). В случае PHP хотя бы psalm(костыль, конечно, но что есть).
если кодовая база маленькая — строгая типизация только мешает, т.к. создает накладные расходы на то, что нужно писать эти типы и поддерживать и не дает всех преимуществ динамического языка/интерпретатора.
1. Накладные расходы чтобы прописать тип который в голове и так должен быть — серьёзно?
2. Типы нужно поддерживать и в динамическом языке. Поддерживать, проверяя что код рабочий и типы те что ожидаются, и в статически-типизированном языке эту работу за вас сделает компилятор.
а зачем? вы приводите к строке то, что вам пришло из $_POST['fieldname']?
в таком случае просто типизации мало, нужно еще очищать пользовательский ввод от потенциально опасных данных (инъекции, xss) и ограничивать его по длине.
Т.е. типизация это всего лишь один из инструментов для гарантии правильной работы и даже он не дает всех гарантий.
например вам пришло $_POST['number'] в пользовательском вводе, которое вы счастливо приводите к int. Потом делите на него и потенциально получите либо деление на отрицательное число (что может не соотв бизнес логике) либо на ноль (что вызовет рантайм ошибку).
Т.е. типизация не заменяет то, что данные в динамических языках соотв. логике, надо следить чтобы данные были в корректных диапазонах и т.д.
если вы хотите городить иерархии классов на каждое поле в бизнес логике это просто отнимает время и раздувает код как в яве. Эти фактори. которые порождают фактори, которые используют билдеры, которые порождают фактори и так на 20 уровней вниз по стеку
Это можно делать как своими классами, так и простыми if/else, но ведь if/else это же не типизация?
динамические языки тем и сильны, что помимо системы типов есть другие вещи которые гарантируют корректность структур данных, например те же регулярные выражения — позволяют выразить сложную грамматику на уровне текстов, которая посложнее чем просто приведение к string.
Мне кажется типизация это не панацея, нужна культура кодинга где все данные проверяются на корректность максимально строго — именно это и дает в итоге правильно и безопасно работающие программы
Нужно еще поверх типизации, например кастования к int еще и проверять на корректный диапазон значений (чтобы не было отрицательного кол-ва товаров в корзине например).
Ну во первых вам никто не мешает создать свой «wrapper» для любого примитивного типа, который будет вам автоматом гарантировать что вы всегда находитесь в корректном диапазоне значений.
А во вторых в динамической типизации вам это точно так же надо делать. То есть никакого преимущества динамическая типизация вам здесь не даёт.
например те же регулярные выражения — позволяют выразить сложную грамматику на уровне текстов, которая посложнее чем просто приведение к string.
А с чего вы решили что регулярные выражения существуют только в языках с динамической типизацией?
Например, пусть в функцию суммирования прилетают два числа с ограничением
0 < Int < INT_MAX & Int <> 42. Что будет корректным типом для результата? Чтобы вывести, компилятор должен знать кое-что о целых числах, свойствах операции сложения и, возможно, переполнении.Реальный код, как правило, будет еще чуть более сложным, чем эта функция сложения. Даже если математика сойдется, то вы вряд-ли будете довольным временем, которое тратится на компиляцию.
И что-то я сомневаюсь что в языке с динамической типизацией вы найдёте решение проблемы которое будет сильно проще. Ну или как вы там будете складывать два таких числа и что получите в результате?
Ну или этой проблемы в динамической типизации быть в принципе не может? Или она там решается как-то более элегантно?
написал вам возможный вариант её решенияПока я увидел лишь отвлеченные размышления. Покажите примеры кода, где вы использовали на практике предложенный подход.
Если у вас такие проблемы встречаются часто, то вы можете перейти на язык со статической типизацией и они будут решаемы. Или вы можете показать мне ваши примеры кода из языка с динамической типизацией, где вы как-то по другому решаете эти проблемы. Более элегантно. Или более перформантно. Или ещё как-то по другому, но «лучше» чем мой вариант.
Или у вас таких проблем тоже нет и вы их просто решили высосать из пальца в попытке придумать пример с которым не справится язык со статической типизацией? Или как понимать вот этот ваш комментарий?
Должна была всегда возвращать bool, а стала возвращать то bool, то None. Или вообще строку из перечисления.
И отследи потом возде в коде все вызовы, чтобы не было сюрпризов в рантайме.
P.S. Кофе еще не работает. написал комент как минус динамической типизации. Хотя автор вроде за нее и не агитирует.
Насчёт примеров и простых случаев — в языке, на котором я пишу по работе, отсутствует Option/Maybe и почти все типы по умолчанию nullable. Сделать Optional на уровне типов — примитивщина, в разы проще тех же dependent types, но профит от неё огромен.
Собственно, мой поинт — у статик типизации есть sweet spots, где она не выливается в необходимость писать математические пруфы и позволяет реально улучшить качество и надёжность кода. Вполне возможно, со временем эта планка будет меняться и те же не отрицательные числа на уровне типов будут мейнстримом.
динамические языки тем и сильны, что помимо системы типов есть другие вещи которые гарантируют корректность структур данных
Простите, я искренне не понял — а в статических языках эти «другие вещи» отсутствуют?
Проблема, которую я лично вижу в статик типизации — слабые системы типов не всегда позволяют развернуться и приходится городить очень много кода. Однако, это не делает плохой статик типизацию per se.
проблема которую я вижу — в статической типизации — нужно перекомпилировать программу, или активно использовать рефлексию, чтобы добиться чтобы один метод работал с разными типами. А рефлексия это по сути и есть динамическая типизация. Ну и много кода получается, да.
в динамических языках не надо изменять код, там все это встроено. Код проглотит любой тип которые ему дали. Неважно строка вам прилетела, или число, если вы в итоге после всех проверок засовываете это в базу — он просто возьмет и запишет переменную. Что конечно не отменяет что нужн проверять данные на соответствие, но я могу эту задачу переложить на базу данных, если захочу.
присутствуют, но в виде уродливых темплейтов или менее уродливых дженериков.
Какие именно «другие вещи гарантирующие корректность структур данных» вы имеете ввиду? Конкретный пример можно?
Ну и желательно чтобы они были «не уродливее дженериков». Ну и неплохо было бы ещё увидеть объяснение в чём конкретно заключается и измеряется эта самая «уродливость».
проблема которую я вижу — в статической типизации — нужно перекомпилировать программу
Зависит от области, конечно, но в вебе, с которым я работаю, это не вызывает проблем. В чём именно ишью с компиляцией программы?
Код проглотит любой тип которые ему дали
Приведите пример такого кода и таких проверок, плз.
if (a > b) {
}Визуально данные норм, и на соседней странице все отрабатывает верно.
Вобщем оказалось на вход подаются строки, а не числа, в итоге «90» больше «80», «120» больше «110», а вот с «110» и «90» конфуз выходил.
«090» и «120» снова будут сравниваться как положено.
Причём написан многими людьми за пять лет.
Мне очень, очень хочется получить статическую типизацию для него, потому что сейчас каждое изменение кода это шаг в неизвестность. Я пристально гляжу на Haxe (у него есть целевая платформа lua), но пока не уверен, что переход себя оправдает.
Правильно говорить динамическая типизация в JS — говно. А не просто динамическая типизация — говно.
А так да, правильно, к одному ЯП надо прикрутить другой ЯП который бы проверял что прога написанная на первом ЯП -ок. Ну а потом еще один который бы проверил что то что проверяет второй ЯП это именно то что надо проверять а не что то другое. Ну а потом четвертый который всё то же самое сделает для третьего.
Система типов это фактически ЯП внутри ЯП. А что если проверять что то что написано на ЯП тем же ЯП? Получится TDD и отсутствие новых сущностей. Что есть гуд. А если программисту (т.е. нежелезному болвану) нужны какие то там подсказки к IDE — ну прикрутите их сбоку! Железный болван и без них сделает все что от него просят.
На разных языках решаю разные задачи, где то удобно со статической типизацией, где то с динамической.
А вы можете привести пример, где действительно удобнее применять динамическую типизацию?
Задача:
С порносайта сайта открытой библиотеки скачать все сочинения Ленина. Все кнопки скачивания помечены классом .button, везде в onclick заинлайнен обработчик.
Решение:
Array.from(document.querySelectorAll('.button'))
.map(a=>a.onclick.toString().match(/https:\/\/[^']+/)[0])
.join('\n')Полученный список url'ов скармливаем скриптику:
xargs -a library-lenin.urls -L1 -P8 wgetЗадача:
Посчитать время, потраченное на разработку нескольких формочек
Решение:
a = `5:11 2:41 1:31 3:8 1:6 2:31`.split(' ').map(a=>a.split(':').map(Number))
h = a.reduce((s,a) => s + a[0], 0)
m = a.reduce((s,a) => s + a[1], 0)
h += (m / 60) | 0 // float to int **magic**
m %= 60
console.log(`${h}:${m}`)Задача:
Полоучить строку из ASCII кодов.
Решение:
[97,67,101,123,114,99,84,84,101,104,95,116,48,121,125,116,53,52,115]
.map(a => String.fromCharCode(a))
.join("")PS. Под рукой всегда открыт браузер. И задачки решаются в одну строчку. На питоне их решать надо в несколько...
Задача:
С порносайта сайта открытой библиотеки скачать все сочинения Ленина. Все кнопки скачивания помечены классом .button, везде в onclick заинлайнен обработчик.
Тут показаны преимущества готового API в браузере, а не динамической типизации как таковой. Но удобно, да.
С остальными примерами, извините, не убедили:
Задача:
Посчитать время, потраченное на разработку нескольких формочек
Haskell:
totalTime s = (hours + minutes / 60, minutes % 60)
where
parsed = map (map read . splitOn ":") . unwords $ s
hours = sum . map head $ parsed
minutes = sum . map (!! 1) $ parsed
main = putStrLn . formatted $ totalTime "5:11 2:41 1:31 3:8 1:6 2:31"
where formatted (h, m) = show h ++ ":" ++ show mRust:
fn main() {
let parsed: Vec<Vec<u32>> = "5:11 2:41 1:31 3:8 1:6 2:31"
.split(' ')
.map(|s| s.split(':').map(|n| n.parse().unwrap()).collect())
.collect();
let mut h = parsed.iter().map(|nums| nums[0]).sum::<u32>();
let mut m = parsed.iter().map(|nums| nums[1]).sum::<u32>();
h += m / 60;
m %= 60;
println!("{}:{}", h, m);
}Задача:
Полоучить строку из ASCII кодов.
Haskell:
main = putStrLn . map toEnum $ [97,67,101,123,114,99,84,84,101,104,95,116,48,121,125,116,53,52,115]Rust:
fn main() {
let s = [97,67,101,123,114,99,84,84,101,104,95,116,48,121,125,116,53,52,115]
.iter()
.map(|&n: &u8| n as char)
.collect::<String>();
println!("{}", s);
}Я бы не сказал, что это сильно сложнее.
С экспрессивностью и удобством хаскеля для такого рода задач я спорить не буду, прекрасный язык)
Тут показаны преимущества готового API в браузере, а не динамической типизации как токовой.
Позвольте, .onclick, как и .match(..)[0] могут вполне неиллюзорно выкинуть undefined, и писал бы я на ts, обязательно пришлось бы его убеждать, что я понимаю что происходит с помощью as. В данной задаче я просто знаю о данных больше, чем о них знает исполнитель. Именно в этом доверии к моим умозаключениям и заключается удобство — я знаю лучше и мне не надо никому это доказывать, тем более глупой машине.
Вы же во всех примерах с растром именно занимаетесь тем, что доказываете что лучше его знаете данные (.parse().unwrap(), sum::\<u32>). А ещё вы напрямую сталкиваетесь с самой системой типов — руками говорите, где u8, потому что другие беззнаковые нельзя просто так скастовать к символу, не встретив угрюмую морду rustc.
Конечно, к этому постоянному доказательству, что ты не верблюд, привыкаешь. Но лично мне легче за 3 секунды написать однострочник, который через следующие 3 секунды канет в лету, без явного объявления, что я хочу отстрелить себе ногу, потому что я знаю что не отстрелю.
Ну и ещё один плюс, почему я привёл примеры на js, а не на питоне например — alt + tab, f12 намного быстрее нажимается, чем подождать пока загрузится текстовый редактор и ещё подождать пока rustc выругается на тебя кучей предложений по тому как код писать красивее и правильнее, хорошо если скомпилирует ещё.
Ну и ещё один плюс, почему я привёл примеры на js, а не на питоне например — alt + tab, f12 намного быстрее нажимается, чем подождать пока загрузится текстовый редактор и ещё подождать пока rustc выругается на тебя кучей предложений по тому как код писать красивее и правильнее, хорошо если скомпилирует ещё.
Я тоже IDE не запускал, я просто play.rust-lang.org открыл.
Ну и я не про ide говорил, а про редактор) Но согласитесь, это ожидание, что ты где-то забыл что map работает со ссылками, или что он не выведет сам collect остаётся даже когда ты достаточно много писал на расте. Эдакое ощущение что сейчас тебя учитель будет ругать за то что в хорошем сочинении таким корявым почерком написал все. Хотя может такое глубинное ощущение испытываю только я при компиляции на любом языке… Зато в динамических получишь как Цезарь без объявления войны нож в спину, а иногда и несколько ножей)
Мой изначальный тезис состоял в том, что в задачках, где ты все решение 10 строчек кода, использование типов является излишней работой, ведь ты сам контролируешь все. И отрицать существование такого класса задачек к сожалению не получится.
Позвольте, .onclick, как и .match(..)[0] могут вполне неиллюзорно выкинуть undefined, и писал бы я на ts, обязательно пришлось бы его убеждать, что я понимаю что происходит с помощью as
Если Вы уж так уверены, что там точно нет ни одного undefined/null, то на ts добавится всего 2 символа:
Array.from(document.querySelectorAll('.button'))
.map(a=>a.onclick!.toString().match(/https:\/\/[^']+/)![0])
.join('\n')
Хотя гораздо безопаснее все же написать так:
import {fromNullable, andThen, map, unwrapOr} from '@lambda-fn/option';
import {pipe} from 'ramda';
Array.from(document.querySelectorAll('.button'))
.map(a => pipe(
andThen(fn => fromNullable(fn.toString().match(/https:\/\/[^']+/))),
map(matched => matched[0]),
unwrapOr('')
)(fromNullable(a.onclick))
)
.filter(url => url !== '')
.join('\n');
Реклама хацкеля удалась, зачет )
Крутой пример решения, и задачка интересная. Всегда любил такие простые но экспрессивные примеры на хаскеле. К сожалению задача не входит в тот класс задач, что показывал я. Да и система типов тут не очень то и роляет. Тут роняется наличие оператора паттернметчинга (в принципе вполне заменяемого на switch в js) и самое главное генераторов списков.
А можете припомнить время, за которое нужно было 2к-ты элемент найти? Я бы хотел попробовать решить такую задачку.
N = 2000;
start_ijk = {
i: 0,
j: 0,
k: 0
};
list = {
v: start_ijk
};
list_last = list;
nums = {};
nums_count = 0;
function getNum(v) {
return Math.pow(2, v.i) * Math.pow(3, v.j) * Math.pow(5, v.k);
}
function expand(v) {
if (nums[getNum(v)] == undefined) {
list_last.next = {
v: v
};
list_last = list_last.next;
nums_count++;
}
nums[getNum(v)] = true;
}
while (nums_count < N) {
expand({
i: list.v.i + 1,
j: list.v.j,
k: list.v.k
});
expand({
i: list.v.i,
j: list.v.j + 1,
k: list.v.k
});
expand({
i: list.v.i,
j: list.v.j,
k: list.v.k + 1
});
list = list.next;
}
let max_in_loop = Math.max.apply(null,
Object.keys(nums).map(Number)
);
while (list) {
if (getNum(list.v) < max_in_loop) {
expand({
i: list.v.i + 1,
j: list.v.j,
k: list.v.k
});
expand({
i: list.v.i,
j: list.v.j + 1,
k: list.v.k
});
expand({
i: list.v.i,
j: list.v.j,
k: list.v.k + 1
});
}
list = list.next;
}
nums_array = Object.keys(nums)
.map(Number)
.sort(function(a, b) {
return a - b;
});
//console.log(nums_array);
console.log(nums_array[N]);Работает менее секунды, однако не факт, что решено правильно. Ответ получился 8153726976.
Я бы вместо объектов для проверки решенности воспользовался бы Set, он обещается побыстрее быть особенно на моменте приведения строковых ключей к чиселкам.
Да и я вот пока думал, кажется совершенно необязательным одновременно во все стороны из каждого состояния идти.
Ну и ещё тут у вас ошибка с next, который почти всегда будет указывать только на увеличение k.
N = 5000;
start_ijk = {
i: 0,
j: 0,
k: 0
};
list = {
v: start_ijk
};
list_last = list;
nums = {
1: true
};
nums_count = 0;
function getNum(v) {
return Math.pow(2, v.i) * Math.pow(3, v.j) * Math.pow(5, v.k);
}
function expand(v) {
if (nums[getNum(v)] == undefined) {
list_last.next = {
v: v
};
list_last = list_last.next;
nums_count++;
}
nums[getNum(v)] = true;
}
while (nums_count < N) {
expand({
i: list.v.i + 1,
j: list.v.j,
k: list.v.k
});
expand({
i: list.v.i,
j: list.v.j + 1,
k: list.v.k
});
expand({
i: list.v.i,
j: list.v.j,
k: list.v.k + 1
});
list = list.next;
}
let max_in_loop = Math.max.apply(null,
Object.keys(nums).map(Number)
);
while (list) {
if (getNum(list.v) < max_in_loop) {
expand({
i: list.v.i + 1,
j: list.v.j,
k: list.v.k
});
expand({
i: list.v.i,
j: list.v.j + 1,
k: list.v.k
});
expand({
i: list.v.i,
j: list.v.j,
k: list.v.k + 1
});
}
list = list.next;
}
nums_array = Object.keys(nums)
.map(Number)
.sort(function(a, b) {
return a - b;
});
//console.log(nums_array);
console.log(nums_array[N - 1]);Всё так-же меньше секунды. Сколько ест не скажу, в браузере запускал.
Сколько на 5000 оно работает и сколько памяти ест?А что за проблемы вообще в это задаче? Тут даже Python ест какие-то копейки, пишется за минуту, работает секунду.
N = 5000
numbers = [1]
mt = 1
while len(numbers) < N or numbers[N-1] > mt:
numbers = sorted(list(set(numbers +
[n * 2 for n in numbers] +
[n * 3 for n in numbers] +
[n * 5 for n in numbers])))
mt += mt
print numbers[N-1]
P.S. Ленивость, кстати, в Python есть. Но это будут уже монстры как у Druu или samrrr… Зачем?
Чет жесть. Это же простой обход графа в ширину:
const next = (lst: number[]) => [...new Set([lst[0] * 2, lst[0] * 3, lst[0] * 5, ...lst])].sort((x, y) => x < y ? -1 : 1).slice(1);
const loop = (lst: number[], i: number): number[] => i === 0 ? lst : loop(next(lst), i - 1);ну или он же если перформансом упарываться:
function binarySearch(lst: number[], val: number) {
let m = 0;
let n = lst.length - 1;
while (m <= n) {
const k = (n + m) >> 1;
if (val > lst[k]) {
m = k + 1;
} else if (val < lst[k]) {
if (k === 0 || lst[k - 1] < val) {
return k;
} else {
n = k - 1;
}
} else {
return k;
}
}
return -m - 1;
}
const insert = (lst: number[], val: number) => {
let i = binarySearch(lst, val);
if (i < 0) {
i = lst.length;
}
if (lst[i] !== val) {
lst.splice(i, 0, val);
}
};
const next = (lst: number[]) => {
const fst = lst[0];
insert(lst, fst * 2n);
insert(lst, fst * 3n);
insert(lst, fst * 5n);
lst.shift();
};
const loop = (i: number) => {
const lst = [1n];
while (i > 0) {
next(lst);
i--;
}
return lst;
};хз как на js быстрее, там уже рядом начинаются тормоза splice/slice и бигнумов
Хз, у жс свои взаимоотношения с массивами. Если на списках переделать (но тогда бинарный поиск работать не будет), то 3n*(средний_бигнум + указатели) выделено и мало в пике (размер списка очень медленно растет, на 1кк он что-то вроде 20к элементов).
Бтв решение samrrr с оценкой как я понимаю допиливается до константы (просто формулой считаем ответ :))
Соответственно, это можно считать в сильно сублинейной памяти
Я не про память, я имел ввиду, что в принципе, кажется, можно посчитать нужное число аналитически.
Потому что интересно же решать задачу так, чтобы она малой кровью работала с как можно большими порядками величины!Совершенно необязательно. Если мне задачу нужно решить один раз и получить ответ, то важным для меня будет время написание + время прогона. И для чисел до нескольких тысяч «наивное» решение достаточно.
В любом случае, это на полтора порядка больше, чем эмпирически необходимые ~30 мегабайт в случае с сублинейной памятью выше.Согласен. Вопрос только том, как часто такие задачи, удачно ложащиеся на ленивость, возникают на практике.
Платить-то за это приходится всегда, а вот прибыль получить… ну вот Вы, вроде бы, писали что-то реальное на Haskell. Как часто вас ленивость спасала? В реальных задачах, не в задачах с собеседования?
В любом случае, это на полтора порядка больше, чем эмпирически необходимые ~30 мегабайт в случае с сублинейной памятью выше.
30мб это сколько элементов списка имеется в виду?
Каждый раз, когда надо распарсить лог или бинарный файл на десяток-другой гигов и что-то там подсчитать. Делать это за константную память автоматически и не сильно об этом думая очень приятно.
Ну тут-то ленивость вообще не при делах.
Переписал ваш пример для читаемости
function generate(maxValue) {
const nums = new Set(), vecQueue = [ [0, 0, 0] ]
let maxInLoop = false
for(let [i, j, k] of vecQueue) {
const num = (2 ** i) * (3 ** j) * (5 ** k)
if(maxInLoop && num > maxInLoop) continue
if(nums.has(num)) continue
nums.add(num)
if(!maxInLoop && nums.size > maxValue) {
maxInLoop = Math.max(...nums)
// = 186264514923095700000
console.log('Max in loop:', maxInLoop)
console.log('Queue:', vecQueue) // length: 15_001
}
vecQueue.push([ i + 1, j, k])
vecQueue.push([ i, j + 1, k])
vecQueue.push([ i, j, k + 1])
}
console.log('Full queue: ', vecQueue) // length: 46_162
return Array.from(nums)
.sort((a, b) => a - b)
// .slice(0, maxValue)
}
console.time('test')
var values = generate(5000)
console.assert(values[1999] === 8062156800)
console.assert(values[4999] === 50837316566580)
console.log('Values:', values) // length: 15_387
console.timeEnd('test')0xd34df00d, время выполнения ~150ms, количество всех объектов подписано в коде. Вывод Node.js по памяти:
RSS: 22.6 MB (22634496)
HeapTotal: 12.9 MB (12890112)
HeapUsed: 5.9 MB (5918300)
External: 856.7 kB (856689)Я под ночь плохо представляю себе этот ряд полностью, но кажется что EQ не будет никогда и это вполне себе dead code.
В данном конкретном случае получить число 10 мы можем только вектором 1,0,1 (2^1 3^0 5^1). Может я не очень понимаю что-то про expand, но в такой вектор система может придти только однажды, вроде
2^i*3^j*5^k <=> (i,j,k)
10 <=> (1,0,1)
15 <=> (0,1,1)
Значит разные наборы ijk создадут разные числа и наоборот.
Но туда рантайм Haskell даже без программы не влезет, так что смысла в Haskell не будет точно.
Я придумал как решить эту задачку. Решается она все же больше математически чем программированием. Завтра днём покажу. Сразу скажу что Решать собираюсь графом… Ну и решается она к сожалению нифига не за линейное время...
import heapq
import itertools
def sequence(start=1, factors=(2, 3, 5)):
nums, prev = [start], None
while True:
if (current := heapq.heappop(nums)) != prev:
prev = current
for k in factors:
heapq.heappush(nums, current * k)
yield current
pos = 2001
print(next(itertools.islice(sequence(), pos, pos + 1)))8 строчек питона против 9 строчек хаскеля, считая саму функцию.
Даже корявая плюсовая реализация
int64_t get_nth(size_t pos) {
std::priority_queue<int64_t, std::vector<int64_t>, std::greater<int64_t>> nums;
nums.push(1);
int64_t prev = -1;
while (pos) {
int64_t top = nums.top();
nums.pop();
if (top != prev) {
prev = top;
for (auto k : {2, 3, 5}) {
nums.push(top * k);
}
pos--;
}
}
return prev;
}содержит всего лишь 13 осмысленных строчек.
Только вот сам пример не очень, потому что он демонстрирует решение ad-hoc задачи уровня "смотри как могу". В этих 9 строчках недостаточно когнитивной нагрузки чтобы статическая типизация начала помогать лучше понимать код и недостаточно практической применимости чтобы статическая типизация дала измеримый выигрыш в скорости.
Профиты типизации начинают появляться когда ты пишешь переиспользуемый код в котором ты должен быть уверен, и в который ты должен очень быстро въехать увидев его впервые или через 3 месяца после написания. Собственно именно поэтому в питоне более менее серьезные проекты обмазывают всё тайпингом.
А так, если стоит задача быстренько посчитать что-то здесь и сейчас — динамические скриптовые языки вполне удобны. Каждой задаче — свои инструменты.
p.s. а статика, конечно, лучше динамики для проектов на 1к+ строк кода.
А, хип импортируете…Тут, всё-таки, речь идёт про стандартную библиотеку, против стороннего модуля… но это уже всё к статике/динамике уже совсем никакого отношения не имеет.
Тогда можно было бы не писать mergeUniq руками, а взять что-то такое из уже готовых библиотек, и было бы две осмысленных строки хаскеля.
var a = "5:11 2:41 1:31 3:8 1:6 2:31".Split(' ').Select(x => new int[]{ int.Parse(x.Split(':')[0]) , int.Parse(x.Split(':')[1]) });
var h = a.Sum(e => e[0]);
var m = a.Sum(e => e[1]);
h += m / 60;
m %= 60;
Console.WriteLine(h + ":" + m);И никакой magic.
3 задача C#:
Console.WriteLine(
(new []{97,67,101,123,114,99,84,84,101,104,95,116,48,121,125,116,53,52,115})
.Select(e => (char)e)
.ToArray()
);.Select(e => (char)e)Разве Cast<char> не эквивалентен?
Cast<TResult>return (TResult)(object)x;А что случается после попытки анбоксинга в неправильный тип, думаю всем известно.
Условно говоря Cast несмотря на своё название вообще ничего не кастит, а лишь удостоверяется, что все элементы коллекции имеют нужный тип.
Круто! Ещё бы можно было писать просто parse, с последующим автоматическим выведением типов, как в расте, и все стрелочные функции заменить на выражения с it, как в котлине, и вообще пальчики оближешь)
Console.WriteLine("5:11 2:41 1:31 3:8 1:6 2:31".Split(' ').Select(i => TimeSpan.Parse(i)).Aggregate((s, i) => s += i));bytearray([97,67,101,123,114,99,84,84,101,104,95,116,48,121,125,116,53,52,115]).decode('ascii')
Задача:
Получить строку из ASCII кодов.
Решение:
val a = "5:11 2:41 1:31 3:8 1:6 2:31".split(' ').map { it.split(':').map(String::toInt) }
var h = a.fold(0) { s, a -> s + a[0] }
var m = a.fold(0) { s, a -> s + a[1] }
h += m / 60
m %= 60
println("$h:$m")Чуть упрощенная версия:
var (h, m) = "5:11 2:41 1:31 3:8 1:6 2:31"
.split(' ')
.map { it.split(':').map(String::toInt) }
.reduce { s, a -> listOf(s[0] + a[0], s[1] + a[1]) }
h += m / 60
m %= 60
println("$h:$m")Задача:
Посчитать время, потраченное на разработку нескольких формочек
Решение:
arrayOf(97,67,101,123,114,99,84,84,101,104,95,116,48,121,125,116,53,52,115)
.map { it.toChar() }
.joinToString("")Количество приведений типов даже меньше (отсутствует float to int **magic** ;) )
Сделать класс контейнер в который возможно добавлять функции с любым количеством аргументов, после вызывать их по индексу из контейнера.
Например так:
void foo(int a) {}
void bar(std::string str1, const std::string &str2) {}
int main()
{
list_function_t list_function;
list_function.push(foo);
list_function.push(bar);
list_function[1]("Hello, ", "world!");
return 0;
}
Что делать, если по соответствующему индексу другая функция?
Это хороший вопрос, к сожалению если мы хотим получить return от функции, то место для обработчика ошибок будет занято return`ом. Есть не красивый вариант использовать объект list_function дальше для проверки
list_function.is_error();Ошибки мы можем получить разные, количество аргументов не верное, невозможно сопоставить типы аргументов между собой. Как вы понимаете если бы у нас был объект с динамической типизацией, мы бы могли выполнять проверки на типы на лету.
Но зачем это делать-то?
Одним из случаев может быть сервер/клиентский обмен пакетов с игнорированием сериализации/десериализации, которую мы делаем ручками. Мы просто получим send с множеством аргументов. В данном примере никакой статической проверки типов в рамках C++ невозможно.
Отмечу сразу что существует очень много подводных камней у этого примера.
Приведу еще один хороший пример, кстати последний случай моего использования контейнера функций.
Это просто работа с графом. Перебирать рекурсивно граф не очень удобно, поэтому я перебросил его на коллбек.
typedef graph_t<int> int_graph_t;
void test(int_graph_t *graph)
{
print_space(graph->level);
if (graph->is_root)
{
printf("is root ");
}
printf("%d %d %d parent value: %d parent index: %d\n", graph->level, graph->get_value(), graph->index, graph->parent->get_value(), graph->parent->index);
}
int main()
{
int_graph_t graph = 0;
graph.push(100);
graph.process_function["base"] = test;
graph.start_process();
return 0;
}
Если потребуется передать аргумент через start_process() в test(int_graph_t *graph), я просто это сделаю. Это насаживается на классы. Если мне потребуется реализовать новый вид функций, то я легко это сделаю добавив в process_function еще что-то.
Например JavaScript. :) Если смотреть с точки зрения рантайма, то благодаря динамической типизации экономится куча времени на старте программы, которую бы в противном случае приходилось делать браузеру для анализа корректности программы при каждой загрузке скриптов.
С позиции разработчика — формулы в Excel, bash, lua и прочие встраиваемые сценарии — где полезный эффект будет ничтожным по сравнению с трудозатратами на дополнительные церемонии с типами.
Если смотреть с точки зрения рантайма, то благодаря динамической типизации экономится куча времени на старте программы, которую бы в противном случае приходилось делать браузеру для анализа корректности программы при каждой загрузке скриптов.
А представьте, сколько времени можно сэкономить, не проверяя постоянно типы в рантайме!
экономия на типах не даёт никакого профита.
Угу, и именно поэтому V8 старается перевести JavaScript в типизированный код. Как и LuaJIT. И потому же PyPy выдаёт производительность сильно лучше CPython.
большинство программ 99.99% времени проводят в ожидании действий пользователя.
Но это не отменяет того класса задач, в которых программы не проводят 99.99% времени в ожидании пользователя.
А представьте, сколько времени можно сэкономить, не проверяя постоянно типы в рантайме!Проверка типов на старте программы это дополнительные секунды, когда пользователь результат не видит. Есть ненулевая вероятность, что большая часть поанализированного кода вообще не будет востребована на странице. В вебе идет борьба за микросекунды, поэтому все что можно отложить, откладывается до того момента, пока оно реально не понадобится. С дальнейшей оптимизацией хорошо справляется JIT.
Если вам нужен анализ кода и AOT — делайте это на сервере, один раз во время сборки для продакшена. Тащить все вот это в браузеры ваших пользователей нет ни какого смысла.
В вебе идет борьба за микросекунды, поэтому все что можно отложить, откладывается до того момента, пока оно реально не понадобится.Только какие-то не за те микросекунды там борются. Потому что перед тем, как на страничке появится первая буква, зачастую исполняется кода больше чем в каком-нибудь Turbo Pascal 7.0 в принципе. А это, так-то, была цела интегрированная среда со встроенным компилятором и дебаггером.
Тащить все вот это в браузеры ваших пользователей нет ни какого смысла.Ага. Зато 100 копий библиотек — тащить имеет смысл. Современный Web — это самое продорливое и тормозное изобретение человечества. У него много достоинств, но малое потребление ресурсов и отзывчивость — это не сюда.
Веб работает начиная с допотопных телефонов, телевизоров и вплоть до мощных ПК.Вы пробовали хотя бы вот эту вот статью открыть на «допотомном телефоне» или «телевизоре»? Попробуйте. У меня где-то Nintendo DS есть с модулем Opera, если что.
Наши бекендеры если время поджимает то и дело норовят перетащить куски логики на фронтенд потому, что тут разрабатывать в разы проще и быстрее.И это назвается «мы боремся за миллисекунды» и «допотопные телефоны»?
Не смешите мои тапочки: эпоха «лёгкого веба», который действительно стремился экономить ресурсы (потому что на сервере был мощный SGI или Sun, а на клиентах мог и 80386й оказаться с парой мегабайт памяти), давно прошла.
Сегодняшний веб транжирит ресурсы просто чудовищно и решает тривиальные задачи криво и плохо. Какой-нибубь «порхающий листик» (типа того, что в Windows 95) тормозит на компьютере с несколькими ядрами и гигабайтами памяти. Про «допотопных телефоны» и «телевизоры» лучше вообще помолчать…
Инженерные задачи от абстрактно логических отличаются там, что решаются всегда в ограничениях.Совершенно верно. Только нужно понимать какие именно ограничения у вас имеются и как вы с ними боретесь. И эти ограничения — это нифига не «допотопные телефоны» (про них уже все забыли давно и никакой веб там давно не работает) и не «миллисекунды» (если бы они были важны — то решения были бы тоже совсем другими).
Ограничение — это отсуствие качественного, грамотного, персонала, способного, как раз, сделать что-то работающее на допотопных телефонах (привет, Java ME) и «экономящих миллисекунды» (для этого есть C++, Rust, в некоторых случаях, возможно, Haskell, но ни javaScript с Babel'ем, ни Web вообще для этого не предназначены). Про WML, который действительно пытался что-то в этом направлении сделать, все уже давно забыли (да и негодная это была попытка изначально, если честно).
Такая потребность была всегда — и решение было тоже всегда (если вы, конечно, не аксакал, помнящий эпоху до JOSS).
Посмотрите на статьи про ретро-компьютеры: на Микроше был бейсик, на БК — ФОКАЛ.
Но никто нигде не пытался заявить, что они используют эти инструменты ради «экономии миллисекунд». Все понимали, что даже если программа, написанная на скомпилированном языке, будет запускаться чуть больше (на пару секунд даже) — это всё равно будет лучше для пользователя.
Я сам лично писал верификатор, который обрабатывал 150-250MB в секунду. Если у вас кода — несколько мегабайт, то он отрабатывает, с точки зрения пользователя, многовенно. А если уж вы грузите на клиента сотню мегабайт (неважно каких — JS или скомпилированного кода), то вас уж совершенно точно не будут волновать те 1-2 секунды, которые ваша программа стартует…
Бэйсик для Микроши позволял напрямую раотать с памятью и вызывать подпрограммы по адресу. Эти возможности часто использовались для "экономии миллисекунд" в том числе ассемблерными (вернее прямо в машкодах) вставками
Но это всё — уже следствие изначального выбора. Знаете, я регулярно общаюсь с людьми, которые «оптимизируют» свои решения на PHP, Python, да даже javaScript (хотя там сегодня уже реально можно делать вещи, которые будут «тормозными», а не «дико тормозными»). И, как правило, после того, как удаётся-таки получить реальные числа получается так: они подставляются в табличку, даётся прикидка «на пальцах» и «достижение», в 9 случаях из 10, превращается примерно в следующее: «мы смогли организовать умную схему базы и систему кеширования и теперь наш 64-ядерный сервер с SSD держит такую же нагрузку, как какой-нибудь одноядерный Pentium!!! на 1GHz начала века с HDD».
После чего остаётся только переспросить: «А вы точно уверены, что в вашей архитектуре главное — это „масштабируемость“, „эффективность“ и другие модные слова? Или, может быть, всё-таки зарплата людей, которых вы нанимаете на работу — важнее?».
И, заметьте, в ответе «да, нам нужны дешёвые и, соотвественно, тупые, программисты» я не вижу ровным счётом ничего зазарного: это — нормальный бизнес-подход. Нанять «таджиков» для копки погреба под три кадки с огурцами — вполне нормально. Но не нужно после этого заявлять, что два вас самое главное — соблюдение параметров проекта и санитарных норм. Не для этого вы «таджиков» нанимали, ведь согласитесь?
И да, в программировании, как и в строительстве, попытки нанять слишком неквалифицированную рабочую силу выходят боком… но это уже зависит от проекта.
С зарплатой мне как-то сложно судить. По опыту (PHP, JS/TS) с ФОТ порядка 5000$ нанять можно самых разных программистов. Одни шаг влево-вправо от любимого фреймворка и загребаются на несколько дней, другие плюют на фреймворк и пишут 10 строк "ванильных"
Незначительно больше, не настолько чтобы мотивировать меня переключиться с PHP на Java из-за денег.
Сложно сказать. Может у вас на Java пишут только вещи, которые на PHP написать сложно, а то и практически невозможно, а у нас то же что на PHP большей частью. Я вот у наших джавистов то, что видел на Sзring MVC кажется — большей частью можно копипастить в Symfony, убрать типы, синтаксис немного поправить и должно работать.
Вот, кстати, забавно, да. И PHP и Java по сложности практически одинаковы (кроме многопоточности, но, справедливости ради, отсобеседовав порядочно джавистов претендовавших на синьёра с большими деньгами, знания в этой области были даже не у каждого второго).
Да, вход в PHP попроще и наговногкодить там легче. Но если смотреть на задачи и требуемое качество от мидла и выше, то разница нивелируется. Мало того, дейстивтельно сложные задачи на джаве решаются легче и требуют меньше знаний. Т.е. синьёр на пыхе зачастую знает свой язык лучше, чем синьёр. на джаве. А зарплаты ровно наоборот. Мистика.
Звучит так, что изучить мне многопоточность и синтаксис, и можно на java сеньора подаваться :)
А с зарплатами может быть дело в том, что Java это не только веб, но и десктоп с мобайлом (не знаю на встраиваемых она ещё применятся или нет) и хорошо спеиалиста переманить больше желающих.
Звучит так, что изучить мне многопоточность и синтаксис, и можно на java сеньора подаваться :)
Можно, да не возьмут. Обязательно об опыте спросят :)
Но за годик, настрофигачив большое портфолио, вполне. Синьёр — это же не про синтаксис, а про принципы, архитектуру и опыт скорее. Так-то все ООП языки(с автоматическим управлением памятью) — близнецы братья.
Вот, кстати, забавно, да. И PHP и Java по сложности практически одинаковы (кроме многопоточности)
Ну, как уже написали выше, Java это ещё и куча десктоп-приложений и там есть своя специфика. Плюс многопоточность это не такая уж и мелочь.
Т.е. синьёр на пыхе зачастую знает свой язык лучше, чем синьёр. на джаве. А зарплаты ровно наоборот.
Ну так вопрос не в том кто там насколько хорошо что-то знает, а скорее в том что он с этими знаниями может. То есть что он в принципе может написать за приложения, как быстро он пишет код, насколько хорошо этот код работает, как выглядит с багами и дальнейщей поддержкой. И т.д. и т.п. И я не настолько хорошо знаю PHP чтобы с уверенностью говорить что он в этом плане хуже той же Java, но почему-то у меня такое впечaтление.
И если например сравнивать в этом плане Java и C#, то сами по себе языки более-менее одинаковы. Но вот если мы возьмём имеющийся тулинг, количество имеющихся open source пакетов и их доступность/простоту использования, то я бы сказал что C# всё-таки выигрывает.
Даже если целевая платформа Linux? Я знаю про .Net Core, но вот насколько тулинг и библиотеки представлены? GUI есть десктопный?
И как бы .Net Core вроде как бы и под линуксом работаeт. Есть та же Avalonia UI например и я ради прикола дома запускал Avalonia UI/.Net Core 3 приложения на линуксе. Но пока это всё ещё очень сыровато. И как минимум нам тогда проще на джаве сделать.
Ну вот именно Core работает вроде уже нормально. А вот насколько вся экосистема готова...
И лично я сейчас однозначно не буду делать что-то в продакт на .Net Core под линукс. Особенно учитывая что в этом-следующем году будет .Net 5 и там опять всё может поменятся. Ну или точнее я надеюсь что там многое поменяется в лучшую сторону :)
дешёвые и, соотвественно, тупые, программистыПо-моему, не стоит ставить знак равенства. Даже в одной и той же сфере с одинаковыми технологиями нет равенства из-за личных особенностей. В разных сферах будет играть всё больше рыночный фактор относительно используемых технологий и самой области применения.
В разных сферах будет играть всё больше рыночный фактор относительно используемых технологий и самой области применения.Собственно именно наличие рынка и должно приводить к тому, что дешёвые программисты будут тупыми. Рассчитывать на высококвалифицированных фанатов своего дела, готорых работать «за похлёбку риса» — неконструктивно.
Забавно, у меня на куда более слабом железе и Firefox последней версии всё нормально работает
При этом, так-то, Chrome ничуть не менее популярен, чем Firefox, «отмазаться» тем, что разработчики про него не знали не получится.
У вас нет «когнитивного диссонансса» во всей этой истории?
У меня, как ни странно, нет претензий ни к писателям на JS, ни даже к владельцам Хабрахабра: у них другие заботы, экономить чужие ресурсы они ни разу не обязаны.
Но ради бога, если вы «специалист по дендрофекальному методу строительства», то не рассказывайте никому о том, что вы выбираете этот метод за качество результата и можете построить хоть многокилометровый мост, хоть телебашню.
Аминь!
П.С. А ведь скрипты на хабре на .js =)
console.time(); $(':focus'); console.timeEnd()На этой странице выполняется 130мс. На каждое нажатие клавиши.
Boomburum пользователи страдают.
И язык тут — дело второстепенное, с тем-же JS можно прекрасно юзать статический анализ и тайп-линтинг с аннотациями в JSDoc. Типы — это вопрос архитектурный и пылать праведным хейтом стоит, разве что, в адрес плохой архитектуры но никак не стека и самой возможности использовать динамическую типизацию.
Нет, язык тут дело первостепенное.
Все попытки впилить статические проверки сбоку в языки без статической типизации обречены быть костылём.
Потому что эти типы не будет поддерживаться синтаксисом языка, потому что комьюнити динамических языков к ним в принципе будет настроено скептически, потому что это будет отдельный инструмент а не компилятор, и большая часть кода по прежнему будет без каких-либо типов.
Ну вот как-то в PHP нормально относятся к phpdoc аннотациям типа. Другое дело что сейчас бывают споры, а нужны ли они, если в язык добавили средства почти полностью их заменяюшие.
Как к этому относится какая-то ненавистная вам часть комьюнити — совершенно не важноЭто важно как минимум потому, что это самое комьюнити пишет код, с которым придётся взаимодействовать, и типы в нем либо будут указаны, либо нет.
В компилируемом языке вынос проверки типов в отдельный инструмент будет костылем, в скриптовом — нет.Во первых он будет костылём потому что он не сможет ничего гарантировать если часть кода будет писаться без типов.
Во вторых, если язык не поддерживает синтаксис для типов и всего что с ними связано, появляются сомнительные вещи в виде указывания типов в комментариях, а потом появляются эти комментарии в разных форматах для разных анализаторов.
В третьих, никакие стат. анализаторы рядом не стоят по удобству и надежности с компиляторами статически типизированных языков.
скепсис к типам — это ваша личная выдумка, напротив, все больше разработчиков начинает использовать подобные инструменты в обязательном порядке.
Нет, это вздор хотя бы потому что мы говорим о разработчиках которые уже выбрали динамические языки. Линтеры и подсказки IDE это не подобные инструменты.
Ваши личные эмоции тут не аргумент.
Аргументы вы почему то решили «не заметить».
Аргументы вы почему то решили «не заметить».
И я до сих пор их не вижу. «будет костылём», «рядом не стоят» — это все ваши эмоции.
Еще раз: в скриптовых языках дистрибуция происходит на более раннем этапе чем обработка в среде исполнения.
Это никак не оправдывает неудобство от динамики и не делает её удобнее.
И я до сих пор их не вижу. «будет костылём», «рядом не стоят» — это все ваши эмоции.
Тогда попробуйте наконец прочитать мой предыдущий комментарий полностью.
А то что вы ставите статическую типизацию в один ряд с необязательными линтерами для js'а говорит лишь о том что вы не понимаете о чём пишете.
Поэтому проверка типов и должна производится отдельно, ДО компиляции. Если говорить о веб-платформе — то там еще и большая сегментация самих сред, что добавляет
Тайпскрипт и другие компилирующиеся в js языки вполне себе показывают что веб-платформа и компиляция с тайп-чекером могут успешно сосуществовать.
Например когда работаешь с рефлексиями(что само по себе тоже не особо рекомендуется) или скажем с СОМ-объектами или c результатами динамических LINQ-запросов.
Но никому же не придёт в голову весь свой С# код перевести на динамическую типизацию.
ЕМНИП в .NET её завезли для более удобных поддержки динамически-типизированных языков и работы с COM'ом. Т.е. никакую отдельную задачу в шарпе dynamic не решал, а нужен был для интеропа.
В платформу .NET могли и завести, а в язык C# зачем?
Не сосем понимаю вопроса. Почему я сказал .NET а не C#? Не знаю. Может потому что dynamic добавили на уровне платформы, а не только языка.
Видимо неправильно понял без вашего контекста. Для меня звучит типа: платформе нужна была поддержка динамически типизированных языков и COM, поэтому добавили динамический тип. Ну и между делом в C#, раз уж в платформе уже есть. Для меня COM и прочие OLE только с C/C++ ассоциируются, что на C# кому-то с ними может понадбиться работать как-то в голову не приходило, хотя казалось бы...
Не подумайте, что «удобство» в данном смысле заменяет «правильно». Любое взаимодействие нуждается в проверке (и типизации, чаще всего).
Медленные тулы, потому что написаны на JS, а он к сожалению пока проигрывает компилируемым языкам. А "нормальные IDE для js" медленная только одна — WebStorm, потому что написана на Java, VSCode причём по-шустрее будет, и написан он на js (ts).
В общем, да, задумывались и знаем почему, удивляться тут нечему.
Я думаю тулы настолько медленные не столько от языка, а от того как они написаны.
От программы зависит. Как минимум V8 активно использует JIT c оптимизацией по типам.
Часто все упирается в ассимптотическую сложность, во всяких сложных тулах это особенно часто бывает.
Грубо говоря, неправильный алгоритм даст не в 10 раз просадку, а во все 10^n раз.
А если задача не cpu-bound, то основные тормоза как раз работа с io дает.
JIT может в каких-то случаях отбросить проверку, когда типы можно вывести статически.
Сейчас же function f(a,b){return a+b;} в JS не оптимизируешь.
Нет, совсем проверку типов он не сможет выкинуть, то есть он может запустить по быстрой ветке, но ему никто не дает гарантий, что в каком-то случае вместо int не прилетит string
Любой вызов внешней функции из такого цикла
f(i) = i^2
res = 0
for i in 1:1000
res += f(i)
endдолжен без проблем оптимизироваться нормальным JIT.
Любая функция, ходящая через границы сред исполнения, которую невозможно заинлайнить, ну например какие-нибудь built-in браузерные функции или любые нативные вызовы из nodejs.
Хорошо, а если она возвращает значение, как компилятор может доказать, что оно всегда int например? Никак, вот и обломинго с оптимизацией.
Фиксирован, но ведь js не знает об этом, внешняя функция может и не всегда один и тот же тип возвращать, типизация ведь динамическая, а если такая гарантия есть, то тогда мы приходим к типизации статической.
function f(a,b){return a+b;}
sum=["", 1, " thing ", 12, " things"].reduce(f);
console.log(sum);а jit скомпилирует две реализации функции f — f(string, string) и f(string, int).
И получатся шаблоны из С++. В таком случае это уже статическая типизация и есть.
Ну так этот пример JIT может оптимизировать ещё и лучше, чем статический компилятор (если он вообще сможет такой код скомпилировать).
С помощью С++ и магии шаблонов скомпилится, и будет работать быстрее. Так как будут проверятся id типов, а не строковые названия типов.
Ничего не мешает jit'у после некоторого количества итераций, когда соберётся статистика по типам с которым вызывается f()
Это не позволит обогнать C++, так как в C++ будут заранее созданы эти варианты и не придётся постоянно считать, сколько раз и с какими аргументами вызвана функция.
Статическая типизация в смысле c++ здесь никак не поможет, ведь во время компиляции вообще неизвестно, что в массивеВ массиве всегда будет ограниченный набор типов, не бывает так, чтобы хранилось неизвестно что. Но никто не мешает сделать std::variant по всем типам используемым в массиве.
Если jit начнёт создавать варианты одной функции, оптимизированные под конкретные типы, то выйдет тоже-самое что и делают сейчас шаблоны в C++.
Насколько я знаю с++, шаблоны специализируются только по compile-time типу. Но за всякими новыми добавками после с++11 не слежу, может туда уже полноценную динамику ввели :)
Не стану высказывать здесь своё мнение. Все знают, что в Erlang динамическая типизация. Но вот (к сожалению не вспомнил, где об этом прочитал), Джо Арстронг, автор Erlang, как-то посетовал, что жалеет, что в Erlang изначально не предусмотрели статическую типизацию, и что был проект по её внедрению в него, но когда он был готов на 95%, оказалось, что оставшиеся 5% реализовать невозможно.
Нашёл другое интервью с Армстронгом https://www.infoq.com/interviews/Erlang-Joe-Armstrong/, где он ратует за статическую типизацию и признаётся в любви к Haskell.
Тут пожалуй полезно будет потом их собирать в доходчивые F.A.Q. Чтобы была прямо удобная выжимка.
намного выгоднее.
Но, кажется для вас эта информация и так известна:
«Внутренности вордовских файлов: просто ужас»
«Привет из мезозоя»
Одни из самых популярных ваших статей, и они прям разжигают) Да, тоньше чем это сделал fillpackart, но принцип-то тот же. И судя по тому, что в эту статью я зашел из топа за сегодня, количеству ее оценок и т.д. — разжигать толще тоже можно, просто запас кармы нужен)
Это уж точно лучше, чем быть «серьезным взрослым человеком», составляющим свое Очень Важное Мнение по паре фраз, не читая весь текст)
Вы ведь тоже вряд ли читаете бульварные сайты, надеясь случайно найти там шедевры духа или чтобы быть уверенным, что ничего не пропустили.
Что же касается меня, то я, ценя литературные таланты автора, прочитал данную статью целиком и вынужден констатировать, что она несколько ниже его обычного уровня.
Я же всего лишь имел в виду, что подобная статья привлечет скорее любителей развлечений (типа холиваров), чем профессионалов.
Если тебе просто важнее самоутвердиться, то конечно, а вот практической пользы больше все же от фака, его меньше холиворить будут, но читать точно станут.
> писать, что ты идиот
>> аргументированное
И какой вывод для себя тут можно сделать?
Так это же вполне себе решаемая проблема.
Какое решение порекомендуете?
The goal is to define a datatype by cases, where one can add new cases to the datatype and new functions over the datatype, without recompiling existing code, and while retaining static type safety (e.g., no casts).Так, что она напрямую связана со статической типизацией.
К сожалению, разница в том, что 20 часов ты ищешь баг УЖЕ с деньгами за проданное ПО, а вот 5 часов думаешь над типами ЕЩЕ без денег. И это самое бабло решает все.
П.С, У меня вот тут почему-то код на perl не работает, может кто поможет?
$??s:;s:s;;$?::s;;=]=>%-{<-|}<&|`{;;y; -/:-@[-`{-};`-{/" -;;s;;$_;seeЯ в своей практике сталкивался только со стартапами, а они по неустойкам не платят, максимум — возвратят деньги.
Я думаю риск довольно разумный — все таки ты держишь деньги в руках, а как оно там дальше пойдёт — вдруг повезёт?)
Кроме того, бэклог по багам есть всегда. Понять что из-за типизации их там на 30% меньше, с учётом того что ты НЕ видишь как оно могло бы быть, для менеджера ( Читай бизнеса ) не представляется возможным.
А вот цена и срок MVP — величина конкретная.
П.С. Для чувства риска и адреналина можно в рулетку сыграть.
Абсолютно точно, именно такой подход. Только на совещаниях надо говорить «Полный Agile с максимальным учётом пользовательского фидбека». Ну или не работать в стартапе, если тошнит. Но мы к сожалению идём туда прямым ходом, и вероятно это единственно верный подход в высококонкурентном капиталистическом мире
вероятно это единственно верный подход в высококонкурентном капиталистическом мире
Ну это вы прям загнули :) Программирование в стольких сферах применяется, что выбор огромный. И это именно выбор — никто не заставляет выбирать конкретный путь, и более того — его можно спокойно менять с одного на другой.
Скорость исправления ошибок в основном зависит от того, насколько просто человеку разобраться в проблеме и локализовать изменение. Мудреные решения не всегда этому способствуют, скорее даже наоборот. Самое накладное в поддержке большого проекта, на мой взгляд, это knowledge sharing. Поэтому, чем проще решение — тем лучше
Коммерческая разработка — это в первую очередь про длительную поддержку тем самым маньяком, который знает, где вы живёте.
Может владеет, но:
а) их установка и настройка займёт время
б) их использование займёт время
в) (опционально) переделывание существующего кода займёт время
И вот мы проект развивается и мы имеем наш index.html и спагетти в app.js. Я согласен, что не нужно палить из пушки по воробьям, но попадать в ловушку «время/качество» тоже не стоит. Проф. за меньшее время со сложным инструментарием сделает то, что средний спец. с небольшим набором инструментов. Ну, тут уже вопрос цены. Да, можно рискнуть качеством.
Во всяком случае я с javascript «близко познакомился» после того как относительно долгое время писал на java/c#. И мне в javascript компайлера и статической типизации дико нехватало. Особенно поначалу.
И я бы сказал что у меня основная проблема была в отсутствии интерфейсов. И в базирующихся на этом отсутствии проблемах с контрактами/«состыковкой» кода, разрабатываемого разными командами/фирмами.
Отдельный микросервис для либы?
Если у меня есть интерфейс, то я точно знаю что я получу. И если кто-то вдруг решит поменять контракт на «своей стороне», то он просто не сможет этого сделать.
Но если есть возможность исключить какие-то варианты или хотя бы снизить наносимый ими ущерб, то почему бы это не сделать?
. Вы же не будете спорить, что объявления типов — это лишние затраты?
Ещё как буду. Это не такие уж и большие затраты и они на мой взгляд однозначно не лишние.
Например потому что обычно позволяют избежать кучи других затрат. На дополнительный тестинг, на разбор чужого кода, на дополнительные проблемы при саппорте, правке багов и дальнейшем развитии/поддержке кода.
"Лишние" тут, видимо, в смысле без типов этих затрат нет, а что они позволяют избежать — это их эффективнотсь.
Но затраты по-любому.
Но затраты по-любому.
Угу, вот только у вас откуда-то там ещё взялось слово «лишние».
И зависит он от решаемой задачи, требований к результату, доступных ресурсов
Угу и когда кто-то озвучивает свою ситуацию и говорит что ему хотелось бы определённую фичу языка, которая бы позволила исключить нарушения контрактов, то неужели логичным ответом будет вот такое:
Налажать можно и не меняя контрактов.
?
Но разве сам факт необязательности делает их автоматически лишними? На мой взгляд «лишние» здесь всё таки неподходящее слово.
Да, это всё лишние затраты с точки зрения получения конечного результата. Но эти затраты могут окупиться. Окупаемость некоторых из них уже принята за аксиому, но холивары по многим из них не стихают десятилетям.
аксиома в том, что введение строгой типизации ничего кроме удорожания разработки не даёт.
Какое сильное и при этом ничем не обоснованное высказывание.
Вот есть, например, nalgebra, это библиотека на Rust для линейной алгебры. В ней есть тип Matrix, который параметризован, в частности, числом строк и колонок. За счёт этого, например, операция умножения там определена только для матриц с совместимыми размерами, а операция транспонирования и обращения матрицы определены только для квадратных матриц. Как вы на это будете писать тесты?
Учитывая аналогичную поправку для тестов, получаем, что их количество будет расти уже не как O(e^n), а как O(e^e^n), что ли?
Это как? Мне представляется только случай, когда человек неверно понял техзадание и начал делать что-то другое (от этого ничего не спасёт). Типы выбираются, чтобы иметь свойства нужные для реализации алгоритма. Нужно очень прецизионно ошибиться, чтобы неверный тип имел точно такой-же интерфейс как и верный, но делал не то что нужно.
Собственно потому так смешён, нет, по настоящему смешён этот спор между
Если вам нужен код, который работает гарантированно и всегда — статическая типизация ваше всё, а то может и в Ada/Idris может повезти поиграться. Собственно тот факт, что сегодня не существует ни одной операционки, ядро которой было бы написано на динамически типизированном языке, равно как нет и браузеров, написанном на динамически типизировнных языках, да и даже какой-нибудь PyPy, который, типа «интерпретатор Python, написанный на Python», если чуть-чуть поскрести, то выяснится, что нет, там нифига не Python, там restricted subset of Python that is amenable to static analysis.
А вот если вам нужно тяп-ляп и «как-нибудь, пусть оно хотя бы что-то хоть как-то на демонстрации заказчику отрисует» и тот факт, что закрытие одного бага создаёт пять новых… тут к вашим услугам и GUI и динамически типизированные языки и куча всего ещё. И тут, действительно, вам статическая типизация будет сильно мешать: потребуются более квалифицированные кадры, а скорость закрытия тасков — упадёт (новых станет тоже меньше, но если у вас всё равно почасовая оплата, то это для вас скорее минус, чем плюс).
Так что… если ваша цель — это решение некоторой задачи, которую вы можете сформулировать — то статически типизированные языки незаменими. Если вам нужен процесс (с почасовой оплатой и демонстрацией «достижений» заказчику) — динамические языки прекрасны.
Заметьте, кстати, что между этими двумя типами программ нет жёсткой границы. Например у нас почти весь код написан на на C++ плюс всякие анализаторы, и прочее… но если и генераторы кода на Python. Потому что вот там как раз важно, чтобы оно на том ровно файле, который у нас есть породило бы разумный выхлоп… и всё — больше ничего не нужно. Совсем. «Заказчики» тут мы же сами — но требования у нас такие же, как у всех: делать этот код надёжным как скала — не нужно.
Сейчас правда есть идея переписать все эти генераторы на чём-нибудь другом (рассматривается Go), но то такое: Python2 больше не поддерживается, код всё равно переписывать, а поддержка Go встроена в билд-систему Android и всё-таки лаконичнее, чем на C++.
Если бы не это — ещё 10 лет бы никто ничего не переписывал.
Бывает, например, еще поисковый процесс — когда вы не знаете, что писать, и только ищете. Нетиповая задача.
Или те же генераторы. Если сам генерируемый код меняется каждый день, нет никакого смысла писать генератор на компилируемом языке.
Или те же генераторы. Если сам генерируемый код меняется каждый день, нет никакого смысла писать генератор на компилируемом языке.
Какой-то неочевидный вывод
Поэтому вы сделаете какой-то шаблонизатор, который в зависимости от требований постепенно превратится в язык, полный по Тьюрингу, как это обычно и бывает. И тогда вы снова получаете динамический язык, только кривой и самопальный, т.е. то, что могли бы гораздо проще сделать сразу на динамическом.
Вы же не будете каждый раз перекомпилировать программу при смене шаблона, если это происходит часто?
Буду перекомпилировать.
А вы используйте не текстовые шаблоны, а структурированные. И внезапно статическая типизация начнёт вам подсказывать, что в атрибут datetime надо вставлять время, а не рубли.
Простите, что
Вы напрасно ограничиваете процесс для динамического языка почасовой оплатой.Если вас интересует общее количество времени, потраченного на проект — динамические языки проигрывают (народ недаром с Python на Go переходит и даже в самом Python пытается типы как-то добавить). Если вы хотите уменьшть время, затраченное на «закрытие таски» (и вас не волнует сколько это закрытие новых породит) — выигрывает динамика.
Потому при почасовой оплате динамика выигрывает без разговоров: и денег больше получите и объяснить за что вам их нужно оплатить проще. В остальных случаях… всё весьма непросто.
Если сам генерируемый код меняется каждый день, нет никакого смысла писать генератор на компилируемом языке.Почему нет? Если компилятор достаточно быстрый (как в том же Go) то время запуска отличается от динамических языков несущественно.
Не вся разработка ведётся в рамках проектного управления, "под ключ". Достаточно много её идёт в рамках продуктовой разработки с постоянно меняющимися требования, где для бизнеса основная метрика эффективности его команд разработки — time-to-market, время от появления бизнес-гипотезы до выкатки её в продакшен. Сами же разработчики работают на окладе и может быть и рады бы писать не то что статически типизируемый, а вообще формально верифицируемый код, но любое увеличение времени разработки воспринимается бизнесом в штыки, его нужно этому бизнесу "продавать".
любое увеличение времени разработки воспринимается бизнесом в штыки, его нужно этому бизнесу «продавать»Было бы еще это желание.
Нужно просто отдавать себе в этом отчёт, а не пытаться рассказывать сказки, что вам не нужна типизация, потому что у вас тесты или потому что у вас «такая команда».
Нет, вам не нужна типизация, потому что вам не нужен код без багов. И всё. Отдайте себе в этом отчёт — и всем станет резко проще и легче.
Поэтому ваше противопоставление смысла не имеет.
В программах на С++ багов полно и обычно куда более серьезных, чем рубли в поле даты, иначе бы не требовались в дополнение к компилятору разные статические чекеры и отладчики.Гениальная логика. Плащ от дождя защищает не лучше, чем футболка, а иначе — к нему не требовались бы ешё и галоши.
Поэтому ваше противопоставление смысла не имеет.Имеет-имеет. Типичный web-сайт содержит десятки миллионов строк кода в ядре, SQL-сервере, массе разнообразных утилит и прочем. И небольшое количесто кода на динамических языках типа PHP или JS. Примерно на порядок, а то и на две меньшее, чем вот всё вот это вот, написанное на C/C++.
Тем не менее в 9 случаях из 10 взлом происходит через тонкую прослойку, написанную на динамических яыках, а не через кучу кода, написанного на статически типизированных языках.
Даже C и C++ (по современным меркам — ужасно ненадёжные и «опасные») содержат на два-три порядка меньше ошибок (в пересчёте на миллион строк кода), чем месиво на динамических языках, которое исполняется «сверху».
Всё может быть проще: надёжно работающий код нужен, но не такой ценой как смена языка. Это и на уровне компании/продукта/проекта работает, и на уровне отдельного разработчика.
Как определить что нужны типы? Когда смотришь на функцию как эта и задаешь вопросы:
function (duration, divider)function (dration: {start: Date, end: Date}, divider: number): [{start: Date, end: Date}]По опыту самые частые ошибки, что в JS (динамический слабый), что в C (статический слабый), что Java (статический сильный) — это соответвующие вариации NPE (вроде как из Java само понятие). А вот в PHP (динамический слабый с опциональным усилением) всё реже и реже встречаются.
Это потому, что PHP не строгий начальник, а добрая бабушка, которая не бросает NPE, а максимум тихо пожурит нотифаем и печально продолжит работать дальше, оперируя не валидными данными. ;)
То есть "статическая типизация" в подобных статьях следует читать как "статическая типизация в некоторых языках, в которые не входят все(почти? Не знаю что там с сабжем в C#) мэйнстрим языках" или "я бы не начинал новый проект в 2020 на мэйнстрим языке, если он не от MS"?
(почти? Не знаю что там с сабжем в C#)
Opt-in nullability таки завезли и можно пользоваться, правда она местами косячно работает: требует shut-up операторов, неудобно работать с nullable value types, которые появились раньше. Однако, польза всё равно заметна.
chersanya
В F# — нет null (в 99% случаев, на практике он может прилететь из того же C#). Но, к сожалению, F# и не мейнстрим язык.
Приходите к нам в Rust и расскажите, что нужно иметь один единственный способ конкатенации строк.
Большинство примеров, которые демонстрируют недостатки динамической типизации обычно относятся не к ней, а к слабой, к неявному приведению типов в частности. Даже по таким косвенным признакам как использование в примерах JS и PHP без тайп-хинтов, а не, например Python или Lisp :) можно это предположить. Я вот в частных холиварах показываю примеры PHP с type hint vs Java, когда оба падают в рантайме, но первый с TypeError, а второй с NPE и вопрошаю "в чём сила, брат? В статике или строгости? "
Отсюда и мифы, что typescript от чего то там спасет. Но вот от кривых рук писателей библиотек он не спасает… Как и не делает ни малейшей попытки спасти от кривых рук пользователей библиотек у которых нет ts…
А какая в Java типизация? На мой взгляд, сильная статическая номинативная. Вроде как большинство с этим согласно.
От каких-то ошибок типов он всё-таки спасает, особенно с настройками построже.
Ну не надо Java пинать, у неё-то как раз система типов довольно кривая.
2. разделяем числовое и строковое сравнение
И теперь невозможно написать обобщённый код, опирающийся на операции сравнения.
Сумма в массиве и в массиве строк? Но это 1 частный случай, и ради него создавать проблемы в куче других мест глупо.
1. с чего вдруг?
Потому что для того, чтобы сравнивать значения, нужно сначала посмотреть, какой тип имеют элементы.
2. сравнения строк и чисел — разные по своей природе. и именно попадание строки вместо числа и числа вместо строки вызывает максимум проблем в языках где недоделана динамическая типизация (например python, javascript)
В Perl, получается, тоже недоделана:
my $var = "13";
if ($var == 13) {
print "equal";
}Выводит equal.
И теперь невозможно написать обобщённый код, опирающийся на операции сравнения.
все намного хуже. Операция сравнения для символов в общем виде не определена. Не надо только про юникод. IJ — это то же самое, что ij? Или вовсе IJ? Честно — сравнение строк нужно, чтобы их алфавитно упорядочивать. А это в разных языках (локалях) разные правила.
Операция сравнения для символов в общем виде не определена. IJ — это то же самое, что ij?
По такой логике и сравнение между числами не определено. Возьмём повсеместные для floating point +0 vs -1, NaN vs NaN и другие. Да даже формально определённые -1 vs +1, 10.5 vs 10 — иногда их полезно считать одинаковыми, так же как вы пишете про ij vs IJ.
Возьмём повсеместные для floating point +0 vs -1, NaN vs NaN и другие
вся работа с FP производится согласно стандарту. Т.е. ученые мужи сели и договорились. Как оно должно быть. А потом уже весь софт и даже оборудование работает по этим принципам. Но вообще — да, иногда логика работу с FP бывает… загадочной.
Со строками же проблема вроде как до сих пор не решена (?).
крайне маловероятно что неудачный merge приведёт к замене килограммов на доллары.Как было бы хорошо, если это действительно так.
крайне маловероятно что неудачный merge приведёт к замене килограммов на доллары
Легко, достаточно смело поменять порядок аргументов функции, в другой ветке сделать новый вызов функции, который соответственно не исправлен при смене.
Я регулярно влетаю в boolean blindness и аналоги для других примитивных типов. И это при живом-то newtype! Сначала лень, а потом приходится исправлять конечно.
А уж сколько багов NonEmpty отловил!
def call_bar(bar):
bar.call()
class Foo:
bar = None
def op(self, bar):
self.bar = bar
def call_bar(self):
call_bar(self.bar)
foo = Foo()
foo.send_bar() # упали
foo.op(object)
foo.send_bar() # не упали
Типичная ошибка на самом деле по опыту использования софта на ряде нестрогих ЯП.
В чем тут проблема: контекст, когда вызов foo.call_bar() валиден, а когда невалиден, находится в голове программиста. Неявная сцепленность с контекстом, о котором должен знать программист. Юнит-тесты это не ловят, увы.
Неявная (она существует, но только логически, в голове у программиста) сигнатура call_bar принимает только Bar. А мы ей передаём сумму None|Bar.
Если писать всё логически корректно (без неявной зависимости совместимости от контекста), то получается строго типизированный код, но без меток типов. Проставить эти метки — дело небольшого времени, если речь не о трех строчках кода на выброс.
Еще с явными типами намного легче ловить ошибки при изменении контрактов (сигнатур). Это вторая или первая по распространенности причина багов. Юнит-тесты далеко не всегда покрывают полностью интеграцию кода.
Чтобы разгребать не только логические ошибки, но и ошибки несоответствия типов?
И это ведь не специфичный кейс. Обобщенные алгоритмы частенько требуют выполнения специфических условий объектом поданным на вход. Да простейший бинпоиск требует сортированных данных.
Будете писать в начале функции
if(notSatifyCondition(array)){
throw Exception()
}?
Может лучше все же объявить сигнатуру как search(arr: SortedArray) и обойтись без if и рантайм ошибок? Сейчас действительно 20й год 21 века, а вы такие проблемы предлагаете решать не автоматически за счет компилятора, а вручную подпихивая костыли.
вопрос какой оператор сравнения вы хотите
Тот, который предоставляет пользователь, когда вызывает сортировку.
Вот есть у меня Enum, и мне очень захотелось по нему что-то упорядочить. А еще есть объект содержащий Response от сервера — и я хочу упорядочить ято-то другое по информации из этого Response. И при этом хочу запретить пользователю сравнивать Response и Enum — это же бред, как сравнивать слона и шкаф. Ваши динамически типизированные действия?
В бизнес-требованиях может быть, что enum должени сортироваться и не по символам, и не по числам, например OPEN должен быть на первом месте, CLOSE на втором, и т. п. по важности для пользователя. Причём в разных юзкейсах разная важность.
Вот вам задача. Практическая, не какое-то теоретическое занудство.
Пишем менеджер задач. Там есть процессы. Активные, на паузе, завершенные и не начатые.
Хочу чтобы юзер мог их сортировать и умел сам задавать порядок сортировки произвольным образом. UI часть писать не надо — только модель.
Условие номер 2: хочу чтобы я не смог сломать ваш код, используя его неправильно. Представьте что у вас в команде зеленый разработчик, который будет завтра писать к вашей модели UI, а послезавтра — вам выкатываться в прод.
Я похожими вещами раз в месяц-два занимаюсь точно, так что, судя по всему кейс весьма распространенный. Ну, с продом через 2 дня, я конечно загнул, но и такое бывало.
Можете хоть к числам приводить, хоть к строкам, хоть вообще ENUM не пользовать. Накидаете решение? Я в ответ на него скину свое.
Как говорится, болтовня ничего не стоит — покажите мне код)
Прямо спасибо, прекрасный пример, наглядно демонстрирующий, что люди, которые топят за типы, крайне редко понимают, зачем они вообще нужны, и как их имеет смысл использовать.
Тут типы только навредят. Функция sort/3 должна принимать два любых элемента и функцию двух аргументов. Если эта функция вернула не boolean — отказ (это бизнес-логика, тут каждый сам решает, я бы в лог ворнинг бросил и обработал, как если бы вернулось true), если true — первый выше второго, если false — наоборот. И все.
Такой код не сломать неправильной реализацией сортера, и если завтра нужно будет сравнивать по хитрому запросу в базу — весь код готов. А с типами тут придется чуть более, чем все — переписать.
Единственная проверка типа, которая тут имеет смысл — это проверка возвращаемого сортером значения на boolean. Но вокруг хайп, и куча неглупых людей как заговоренные повторяют нелепую мантру про «типы помогают при рефакторинге» — поэтому горе-разработчики тут нагородят типов и обломятся ровно на следующем нестандартном требовании к сортировке.
Так, может быть, проблема не в статической типизации (раз она тут, пусть и по мелочи, но всё же поможет), а в этом самом "хайпе"?
Не очень понял вопрос; я никогда и нигде не заявлял, что со статической типизацией есть проблемы. В некоторых случаях — она вполне уместна.
Проблема даже не в хайпе, а в том, что люди считают ее панацеей, что люди не по делу обижают динамическую типизацию, а также в том, что особо одаренные особи умудряются найти полноценную статическую типизацию в тайпскрипте.
Функция sort/3 должна принимать два любых элемента и функцию двух аргументов.
А вот это смешно. Потому что у вас тут есть тип. Я его в хаскель формате не напишу — слабо. Но очевидно, что сигнатура функции высшего порядка (которой является sort/3) вполне конкретно определяется. Как и сигнатура композируемой функции.
это проверка возвращаемого сортером значения на boolean.
Только эта проверка должна быть на этапе компиляции, а не в рантайме. Т.к. сортер должен быть определен изначально.
Вам это смешно, потому что вы не понимаете, что такое тип.
На Хаскеле такое не написать, потому что там нужен завтип. На Идрисе можно. А у меня там просто паттерн-матчинг в динамически типизованном эрланге.
эта проверка должна быть на этапе компиляции
Конечно. А при чем тут типы, стесняюсь спросить?
Завтип там потребуется просто когда в список завезут задачи разных типов, то есть вчера.
сделайте, пожалуйста, ровно n запросов в базу перед вызовом сортера
Да сделаю я, сделаю. Я один запрос сделаю, а не n даже, которые вам подарила волшебная система типов (но не уберегла от говнокода, правда, но это случайно, я уверен). Пример не очень удачный, но ведь пуговицы — это единственное, к чему тут можно прицепиться.
На каждый вызов сортера?
При чем тут вызовы вообще? Я указал, где тип важен, нужен, интересен.
[...] что я делаю не так
Экстраполируете свой опыт на нужды всего человечества, например.
любой другой удачный пример, где вам внутри компаратора нужно будет делать нечистые вычисления
Нечистоту тут придумали вы, я ужа сказал: пример неудачный. Чистые, или нечистые — на тезис вообще никак не влияет.
когда и где вы это проверять собрались?
Я не собирался ничего проверять. Я сказал, где оно уместно. Чтобы подчеркнуть, что во всех остальных местах — неуместно, и даже вредно.
Вы живете в башне из словой кости, глядя на мир вокруг через призму своей религии. Это очень хорошо видно по этому комментарию.
Завтип там потребуется просто когда в список завезут задачи разных типов, то есть вчера.
На хаскеле это можно решить, например, в таком духе:
data Task = TaskA | TaskBВот серьезно — я неуч. Я даже на хаскелле только пару Helloworld писал. В основном под мобилки пишу — котлин там, или свифт…
И я хочу код, который сверхтупой и очень рассеяный я может сломать минимальным количеством способов. Ошибки на компиляции — ок, а в рантайме — хуже, а если можно сломать все так, что оно еще и не упадет, а тихо будет работать неправильно — это вообще абзац ибо может и в прод попасть.
Представляю как ограничить тупого и неаккуратного себя типами. Не знаю как это делать без них. Вы вроде рассказать попытались, но у меня картинка не до конца сложилась. Приведите пример, пожалуйста) Вдруг я все делаю неправильно.
Ошибки на компиляции — ок, а в рантайме — хуже, а если можно сломать все так, что оно еще и не упадет, а тихо будет работать неправильно — это вообще абзац ибо может и в прод попасть.А при такой постановке задачи это и в принципе невозможно. Ну вот вам «операция сравнения» (извините, на псевдокоде, тут язык неважен):
Compare(x, y) {
return sha512(x + y) & 0x1;
}Удачно усортироваться, Просто аж до опупения.Тот факт, что вам тут требуются очень, на самом деле, жёсткие, ограничения не на функцию сортировки, а вовсе даже на то самое «это бизнес-логика, тут каждый сам решает»… только усугубляет проблему.
Потому что «эффективные манагеры» — этого точно не поймут и если их не ограничить — напорождают самой разнообразной чуши. А вам — потом это расхлёбывать. Вам оно надо?
Функция сортировки превращается… превращается… В элегантный решатель ограничений!
Но мне показалось, что основная мысль топ коммента все же в том, что нельзя запретить ломать вообще все. Что-то все еще можно выломать, пусть и приложив большие усилия)
А так да, если у вас есть место куда можно запихать функцию, то туда можно запихать все что угодно. Хоть результаты работы обезьянки, которую пнули для сортировки вашего массива вручную.
Если вы типизируете Compare — шанс того, что кто-то запихает туда два не comparable объекта — будет меньше, чем если не типизируете. Все еще можно объявить Compare(Any, Any), но это надо сначала сделать и только потом у вас появится возможность сломать код таким образом.
И первых и вторых ошибок я видел прилично. Код который уменьшает их количество занимает 4 строки. Я пишу их в перерыве между первым и вторым глотком кофе. В разрезе моих трат на времени на проект — эта привычка не стоит ничего. А вот десяток подобных ошибок с дебагом на полдня стоит проекту дорого.
Fail Fast)
часть ошибок с типами связана с некорректным дизайном математики/сравнений в языке
Соответственно он предложил разделить
математические операции
строковые операции
то есть разделить операции над примитивами базовых типов языка.
Что значит разделить?
Это означает, что мы:
- Запрещаем складывать строки и числа на уровне типов — сразу ошибка компиляции (слева и справа от сложения должен быть один тип или явное приведение)
- Делаем отдельный оператор + для чисел, ++ для строк и т.д.
Не вижу смысла заводить отдельные операторы. Под капотом — да, они все равно будут разными кусками кода, разными функциями. Но с точки зрения программиста — да пускай будут одним оператором. Как и сделано в С++. Перегрузки и все такое.
А еще лучше тогда вообще отказаться от операторов. Пускать будут функции с нормальными названиями. Потому что тогда в операторах самих ценности нет. С функциями же я могу делать что угодно. Композиции всякие и все такое. Синтаксис только немного непривычный. Ну, к этому привыкнуть можно
Все что надо знать — что мы можем сделать однозначное отображение из целых в рациональные… А вот обратное… Ну, вы поняли
Множество рациональных числе — счётное, то есть, есть отображение однозначное из целых в рациональные и наоборот.
Нет. Все не так. Переход из целых в рациональные — тривиальное. Обратное — нет. Как Вы превратите вполне рациональное число 3/5 в целое? Однозначным способом? Никак!
Вполне себе «как» — через «канторовский номер». Парам чисел сопоставляется одно число — например, нумеруя с 1:
1,1 -> 1
2,1 -> 2; 1,2 -> 3
3,1 -> 4; 2,2 -> 5; 1,3 -> 6
… (идём по диагональным линиям открытого с двух сторон квадрата, каждая следующая линия на 1 длиннее предыдущей)
Теперь пройдёмся по парам чисел в том же порядке, но выбирая из всех пар в том же порядке только взаимно простые (НОД=1; (1,1) входит сюда).
Если пара n,d обозначает число n/d — всё, мы нарисовали 1:1 соответствие натуральных и рациональных, исключая дублёры типа 3/5 = 6/10 =…
Если же не пропускать сократимые, то дублёры включатся — это только вопрос стиля.
Расширение этого на 0 и на отрицательные — домашняя работа для первокурсника.
Признаю, не прав. Но с точки зрения практической ценности в информатике — это ничего не меняет. Может есть какая-то задача, где это может пригодиться. Но… Это точно не то, что я имел в виду ) В обычном мире какие-нибудь 1.5f ты можешь превратить в целое 1, 2 или округлить к ближайшему целому (есть три преобразования). И при таком преобразовании, понятное дело, теряется информация. Безвозвратно.
P.s. Плюсанул бы, да статьи у Вас нет (((
float, да, рациональные в компьютерном представлении со спецификой (знаменатель только степень 2 или 10). Но и такой переход неоднозначен. 16777217 не представим в обычном float32, несмотря на то, что оба соседних целых представимы… это тут уже вроде вспомнили.
Поэтому я и возразил формально-математически.
> P.s. Плюсанул бы, да статьи у Вас нет (((
Идеи есть, может, сподвигнусь :)
Ваша проблема в том, что вы абсолютизируете скриптовые языки. Не нужно на них пытаться сложные веб-проекты. Не предназначены они для этого. Но … школота любит. А почему? Потому что думать не надо — извините, хуяк-хуяк и в продакшен. Для PoC это допустимо. Но вот даже MVP уже стремена так делать. Вообще оставьте скриптовый языки скриптам — то, для чего они нужны. И их предел — 10-20, ну, макс 100 строчек, которые можно отревьюить глазами. И, да, даже в скриптах БЫВАЮТ проблемы. Скажем, когда вызываете внешнюю утилиту. Никогда логи nginx не парсили, например? Когда вроде бы ожидаешь, что данные будут в 5-м столбце, разделенном пробелами, а вот от компьютера приходит белиберда или данные смещены, потому что формат не учли? Или версия зависимостей поехала?
Но … школота любит. А почему? Потому что думать не надо — извините, хуяк-хуяк и в продакшен.
Вы реально так думаете? Вот чем принципиально отличается количество "думать" над задачами которые на PHP решаются https://github.com/oroinc/crm/blob/master/src/Oro/Bundle/AccountBundle/Entity/Account.php и если решать на Java
например абсурдно пихать типы в скриптовые языки
Почему?!
Но можно же устроить кеширование (как Python, кстати и делает, всё равно), так что да — вполне небессмысленно.
Если вывод типов автоматический, как в Haskell, это даже на объём кода не очень повлияет.
так они стартующие быстро, работающие — нет
Потому что проверка типов перед стартом программы занимает времяКмк минимальное…
Причём как раз языки, которые обладают достаточно развитой системой типов, чтобы ею заменить вообще любые тесты — имеют весьма и весьма немаленькое время компиляции.
Haskell же, например, вполне себе компилирует простые алгоритмы достаточно быстро для того, чтобы его можно было в качестве скриптового языка использовать… но на нём и выразить любой тест типами нельзя…
языки, которые обладают достаточно развитой системой типов, чтобы ею заменить вообще любые тесты — имеют весьма и весьма немаленькое время компиляцииКак по мне, то для скриптового ЯП достаточно такой системы типов, которая бы проверяла на корректность только сами данные (работу с ними). Поэтому там большой задержки при загрузке скрипта быть не должно.
слева double справа int — не возникает неоднозначностей же. компилятор всегда справлялся.
откуда неоднозначность будет слева строка справа строка?
возможна операция строки и строки? выполняем её
невозможна? бросаем исключение
Да что строки, это верно для любой групповой операции, независимо от её природы.
неоднозначности возникают обычно между матрицами и числами.
Почему? потому что матрицы состоят из чисел.
разделение операторов для матриц и чисел на разные позволяет компилятору понять что конкретно хочет пользователь.
Моя мысль простая: если доводы против использования оператора "+" (или "*") для строк и для матриц одинаковые, то и решение должно быть одинаковое — либо в обоих случаях можно такой оператор брать, либо в обоих нельзя. Ну а отказываться от обычных операторов для матриц явно контрпродуктивно. Вместо «матрицы» здесь можно много чего ещё поставить — значит, обычные операторы нужно разрешать использовать для произвольных пользовательских типов. Раз так, то запрещать для одного конкретного типа — строк — выглядит очень странно и непоследовательно.
матрицы не являются базовыми типами языка, а обычно реализуются объектами и библиотеками
Вы считаете это такой фундаментальной разницей — какие типы решили ввести в стандартную библиотеку, а какие нет? Если что, много языков имеют матрицы (массивы) в стандартной библиотеке.
умножение массива на число. например возьмем Python:
Не знаю, где вы в питоне в стандартной библиотеке нашли массивы. Согласно документации то, что вы привели в пример — это список. Де-факто стандартные массивы — это numpy. И в нём (со своими недостатками, но всё же) используются стандартные операторы — т.е. ваше утверждение неверно:
поэтому нет «обычных операторов для матриц» в языке
очевидно что массив и матрица — разные понятия. совершенно разные
Абсолютно неочевидно.
Википедия говорит, что
In mathematics, a matrix is a rectangular array of numbers, symbols, or expressions, arranged in rows and columns.и я с ней согласен.
ага это разница фундаментальная:
Ваше субъективное мнение я понял, но снова абсолютно не согласен с ним. Ничего не мешает в стандартную библиотеку языка ввести матрицы, или не вводить строки.
Не знаю, где вы в питоне в стандартной библиотеке нашли массивы
а я об этом и говорил — что их нет в базовых типах. и сказал что то что есть не является матрицами.
То есть, вы взяли из стандартной библиотеки что-то, не являющееся массивом, и показываете что оно не является матрицей. Хорошо, кто б спорил-то.
ну и вводите. Вам же и легче будет от разделения операторов.
Причём здесь разделение операторов? Я считаю удобным использование * для чисел, строк, матриц и многого другого — и это никак не мешает и не создаёт ошибок, т.к. есть проверка типов.
а вот когда к строке применяют чисельный оператор сложения — тут возникает двусмысленность. И именно эта двусмысленность наиболее частая ошибка типов.
Есть ли какое-то обоснование этого утверждения? В моём опыте это точно не самая частая ошибка, очень далеко от этого. Вообще не так и часто конкатенация строк нужна на самом деле — пользуйтесь форматированием.
$ python3
>>> print(3*2)
6
>>> print('3'*2)
33
Хм…
ну, логично, потому что второе это не умножение )))
А скорее «повтори-ка мне строчку N раз»
Нет коммутативности. Это скорее как сложение списков. Т.е. это по сути другое сложение, чем у чисел.
Да даже у операций над плавающей точкой нет коммутативности, представляете
Ну, если так рассуждать, то ее нет и у целых чисел — вот получили мы переполнение и резко вдруг a+b+c+d сломалось по дороге. Все-таки мы работаем с моделью. И если не выходить за ее ограничения, то условные 1.0+2.0 будут равны 2.0+1.0.
Ну, если так рассуждать, то ее нет и у целых чисел
Ммм, так сходу не вижу, где переполнение ломает коммутативность. Понимание int как вычислений по модулю 2^32 полноценно описывает всю арифметику с переполнением, и сложение тут явно коммутативно.
Но это всё детали — основное же в том, что отсутствие коммутативности никак не противоречит тому, что операция математическая. Откуда это пошло я вообще не понял :)
Понимание int как вычислений по модулю 2^32 полноценно описывает всю арифметику с переполнением, и сложение тут явно коммутативно.
Засчитываю аргумент. Но тогда это не совсем та арифметика, о которой мы говорили изначально
плюс — другая математическая операция
Нет. Плюс — символ, обозначающий некую операцию, разную в разных контекстах.
соответственно с векторами (матрицами, комплексными числами) можно поступать так же
это попросту опасно. Ну, скажем [1,1,1]+[1,1,1,1] — ваш ответ? [2,2,2,1]? Ничего, что это очень неявное поведение будет?
та же история с целыми и флоатами. Проще вообще не приводить их друг к другу, а заставлять программиста конвертировать в явном виде. Не?
был язык на котором можно было изложить алгоритм
этот язык обложили ритуалами (пометками типов) так, что временами за ритуалами не видно в чем цель.
Ну а моё мнение, например, абсолютно противоположно вашему: указание типов преимущественно помогают. Конечно, для этого нужно брать язык, который хотя бы не требует их явного указания _везде_.
То есть, вы снова пытаетесь выдать своё мнение за истину.
Т.е. Что-то подобное, как в С++?
Псевдокод:
int a = 10;
auto b = a+5; // OKВ принципе, имеет право на жизнь
auto variable;
variable=10;
variable=20.0f; // что здесь должно произойти? Ошибка сборки?Просто в таком случае мы обрекаем себя на определенные правила работы с автовыводом. И вопрос — будет ли это удобнее и понятнее, чем везде расставлять типы.
очень уж громоздкие записи типов кроме совсем тривиальных случаев
там проблема не с типами как таковыми, а с шаблонами, когда начинается месиво из скобочек и буковок. Ехал шаблон через шаблон. Даже пришлось << разрешить в шаблонах вместо < <, иначе компиляторы криво парсили
В C++20 добавилась новая хохма с этим — где-то рядом писали — «X<...,operator<=>» — ломается парсинг — это spaceship или <= и скобка закрытия?
В общем, не делайте так в своём языке ;)
А с типами там проблемы от порядка записи типа void (*f)(int (*)(float)) вместо type f = func (func(float):int):void. Частично решают, но основу уже не поменять.
А с типами там проблемы от порядка записи типа void (f)(int ()(float)) вместо type f = func (func(float):int):void. Частично решают, но основу уже не поменять.
Мы во времена С это решали так:
typedef int (*kolbasza)(float);
typedef void (*f)(kolbasza);Ну вы понели ))))
Но это уже следствие изначальной
Спасибо за уточнение. Все попутал. Старый стал ((
А с типами там проблемы от порядка записи типа void (*f)(int (*)(float)) вместо type f = func (func(float):int):void. Частично решают, но основу уже не поменять.Дык:
using f = auto (auto (*)(float) -> int) -> void;
есть множество решаемых программистом задач — AДопустим.
есть множество задач B — где есть проблема приведения double к int и наоборот
и вот поскольку множество B радикально меньше множества A, то делать ради множества B менее удобный синтаксис — плохое решение.Как вы очень любите говорить: «здесь ошибка».
Я, к сожалению, не знаю что вы там имеете в виду под «множеством A» и множеством B", но у всех виденных мною программистов на успешных проектах (про неуспешные не будем, потому что какой смысл обсуждать неудачников?) «множество B» — это всегда отлов и исправление ошибок. И чем успешнее проект — тем больше класс задач B доминирует на классов задач A. И чем успешнее проект — тем более странными и загадочными являются ошибки.
Пока вы — единственный пользователь вашего проекта ошибки, обычно, являются простыми. Когда у вас миллиарды пользователей, которые используют ваш код с миллионами программ… то ошибки становятся всё более… странными. Что-нибудь типа «что это за программа с названием „Keep-Alive“ и почему она регулярно вызывает падение библиотеки, которую вы поддерживаете»… это притом, что согласно правилам наименования пакетов такое имя вообще не должно существовать — и менеджер пакетов это проверяет?
Так вот чем дальше вы отходите от «задача только для себя» и ближе к «программа с миллиардом пользователей» — тем больше шансов на то, что вы нарвётесь на эту самую проблему приведения
double к long long или наоборот.Есть и другие шкалы: одно дело — если падение программы это всего лишь «поправил строчку и забыл», другое — если это врезавшийся в Луну космический аппарат или миллион долларов убытка из-за потери биржевого дня.
И нет, тесты тут не панацея, потому что если Cherry Mobile использует какую-то хрень от Yehuo, то у вас просто фантазаии не хватит, чтобы вообразить — чего ещё они туда понапихали.
Типы позволяют отловить вещи, которые вы просто не догадаетесь покрыть тестами — потому что не думаете об этом.
double позволяет точно работать с числами до 8998403161718783. А вот 17996806323437567, внезапно, превращается в 17996806323437568 и потому 17996806323437567 — 1.0, внезапно, даёт в результате 17996806323437568 — с выходом за границы.И ваша программа, внезапно, «рассыпается», когда объём данных, с которыми она работает, превышает 16PiB!
Не бог весть какие объёмы, по сегодняшним меркам, но вы уверены, что вы про это не забудете? И тест напишите? Я вот — не очень.
Вот отсюда у всего этого ноги и растут.
Чем больше цена вашей ошибки (и чем дороже её обнаружение и исправление) — тем важнее для вас типы и связанные с ними проверки.
Но если язык не требует сверхусилий для их указания (они выводятся автоматичнски как в Go или Haskell), то нет смысла ими не пользоваться даже и в скриптах.
Android вот систему сборки с коллекции Make (нетипизированный язык) на Soong (написанный на Go) переходит.
но цена за это — снижение читабельности код и высокий ритуальный оверхед.Не пишите бреда, пожалуйста. Читать программу, где указаны типы — читать настолько удобнее, что они даже в подавляющем большинстве пакетов на Perl и Python указываются. Да, в комментариях к функциям, не в коде… но это нифига не принципиально.
Вот писать — да, тут не всё так просто. Именно из-за этого в современных языках и появляются системы автовывода типов.
соответственно с векторами (матрицами, комплексными числами) можно поступать так же
Как «так же»? Даже умножение одинаковых типов, например двух одинаковых матриц A*B, неоднозначно: матричное умножение или поэлементное? Тут решение ровно такое же, как и со строками: авторы языка или библиотеки приходят к соглашению, какими операторами какие операции они обозначают, и всё.
Таким образом, в рамках конкретного языка/библиотеки неоднозначности нет.
Плюс — это не операция, а форма ее записи. Как цифры — форма записи чисел. Есть и альтернативные. ¾ — это ведь тоже запись числа. И π+1 тоже. Но это если докапываться.
Да даже у операций над плавающей точкой нет коммутативности, представляете.
Вы хотели сказать, ассоциативности. Коммутативность-то есть.
Точнее можно переставлять, если их два — но даже сложение для большего количества чисел некоммутативно.
??
Коммутативность определена только для пары. И сложение чисел коммутативно.
То, что a + (b + c) может быть не равно (a + b) + c для чисел с плавающей точкой (и некоторых других) — это отсутствие ассоциативности.
Перестановка из (a + b + c) в (a + c + b) при фиксированном порядке вычисления слева направо — это применение ассоциативности и коммутативности: (a + b) + c -> a + (b + c) -> a + (c + b) -> (a + c) + b
Сложение и умножение с NaN'ами тоже коммутативно. А вот с ключом -ffast-math оптимизатор может поломать коммутативность, да.
Сложение и умножение с NaN'ами тоже коммутативно.Не. Нифига. Я и с этим тоже повоевать успел. Если вы складываете два NaN'а, то результатом является первый (на самом деле там есть ещё разница между QNaN и SNaN). И да — у нас от этого тесты посыпались.
Да, тут уже начинаются если-то. Если мы не будем определять эквивалентность как равенство в смысле IEEE 754, а будем её определять как… и т.д.
Но идеи, я думаю, понятны.
конкатенация в математике записывается другим математическим знаком.
Конкатенация в математике обычно записывается отсутствием знака, типа uv — конкатенация строк u и v. Так же, как и умножение чисел, например. То есть, по вашей же логике как раз нужно использовать один и тот же оператор "*" для арифметики и для конкатенации.
Точнее будет: непонятный символ используется в разных контекстах, то как математический оператор, то как строковый оператор.
С каких пор * используется в математике для умножения?
За счёт требования одинаковости типа и отсутствия неявных конверсий — нет обычного для Perl/JS/etc. конфликта смысла '+'.
Но последствия, да, что '*' даёт реплицирование строки.
в тот же Python их вводят в виде объектов (и я кстати не знаю языка где они из коробки есть, то есть в языке а не stdlib).
Fortran, APL, R, Julia
а вот сериализация данных используется в львиной части программ
А это-то тут вообще причём?
а в обычном программировании матрицы нужны в дробных долях процентов случаев от всех задач программирования.
Если обычное программирование — это скриптование, кодирование CRUD’ов и формошлепство, то я соглашусь (сарказм)
а в обычном программировании матрицы нужны в дробных долях процентов случаев от всех задач программирования.
У меня и у многих других массивы чисел в программах встречаются часто. И часто они двумерные (т.е. матрицы).
а вот сериализация данных используется в львиной части программ
Причём тут сериализация вообще? Стандартная сериализация в питоне — это pickle, и как оно относится к матрицам или строкам я никак не понимаю. Во многих других языках ситуация такая же.
Оне сериализуют в строчки )
Json-сосисон и поехало
2. Вы принципиально не отвечаете на вопросы?
я очень хорошо понимаю (мне кажется) цель с которой Вы задаёте этот вопрос. она не коррелирует с той темой которую мы с Вами обсуждаем и я не хочу чтобы дискуссия ушла в сторону.
Я задал вопрос просто потому, что вы очевидно делаете неверный вывод:
У меня и у многих других массивы чисел в программах встречаются часто
Вы — программист, программирующий что-то совсем-совсем редкое.
Причём ваш ответ:
по числу скачиваний библиотека numpy вполне популярна, только это не означает что средний программист где-то её прямо использует.
не менее странный. «Средний программист» это вообще кто такой?
В любом случае, ваше мнение что «массивы» это «что-то совсем-совсем редкое» конечно же неверное — что подтверждается даже вашим же согласием с популярностью numpy. А уж если к нему прибавить всякие tensorflow и что там ещё…
ну на число: зачем в последний раз Вы умножали матрицу на число?
Да хотя бы усреднить поэлементно A и B: 0.5*(A+B). Вот вам сразу и сложение, и умножение.
Отшкалировать изображение из диапазона 0-1 в 0-255 — тоже умножение.
Куча всего.
собираем в кучу например 5000 программистов mail.ru или яндекс или google или случайных компаний выставляющих вакансии скажем на hh.ru. и смотрим сколько из них умножает матрицы, а сколько из них нет.
И сколько? Раз вы говорите, что массивы — это «что-то совсем-совсем редкое», то наверное получится 0.1%, не больше (хах).
массивы в математическом смысле или массивы в смысле «списки»?
Массивы в математическом смысле, т.е. как минимум с арифметическими операциями. Уж сложить пару массивов явно во многих задачах требуется.
решал дифуравнения
Если в уравнение входят координаты, т.е. вектор из 2 или 3 чисел, то даже прям удивительно что вам матрицы нигде не встретились.
Мне очень интересно (и это не стёб) что Вы делаете?
Конкретно я занимаюсь в программировании многим разным: и обработка/анализ изображений, и решение уравнений (изредка — дифуров), и простая геометрия, и signal processing, и подгонкой моделей под данные. Во всех этих пунктах массивы просто на каждом шагу. И это я ещё не делаю всякий там машинлёрнинг, который нынче популярный — там тоже массивы!
создают они его, а дальше умножают? складывают?
зачем они его создают?
На глаз какая-то арифметика там есть, более детально разбираться не хочется — можете посмотреть сами и написать вывод.
Вообще numpy & pandas для аналитики — прямо огонь. Наши аналитики используют вовсю. rsync конечно скажет — нафига и где там двумерные массивы и почему бы это все не Экселем крутить, но для пакетной обработки данных вполне нормально. Да, ребята сидят в своих джупитер ноутбуках и ваяют. Потом на выходе графики для ЛПР и рекомендации что делать. Поэтому этот код никогда ни в какие публичные репозитории не попадет
формируют ли какие-нибудь полезные матрицы абелеву группу
Очевидный пример: представление группы поворотов плоскости вокруг фиксированной точки.
а в С никто не жалуется на сложение float и int.
Потому что результат может быть разный
Может быть условно float + float (каст из Инта) и int (округление по какой-то методе) + int. И последнее точно отличается от float + float + отбрасывание дробной части
а в С никто не жалуется на сложение float и int.Вот с тех пор, как это стало можно сделать ошибкой компиляции жаловаться и перестали.
До этого жаловались — и довольно активно.
в программировании не возникает двусмысленностей когда программист пишет умножение целого и флоата.
Вообще-то возникает. Если перемножается 64-битное целое и 64-битное с плавающей точкой, то вроде бы ясно, что нужно целое кастовать к дробному… Вот только очень большие целые числа могут в double не влезть. И что теперь делать?
int64 * double — к чему приводить будем? К int64, чтобы потерять дробную часть, или к double, чтобы потерять точность на больших числах?
к числу дающему бОльший диапазонО как. То есть 4611686018427387903 + 0.0 будет 4611686018427387903 (целое,
long long), а вот 0 + 0.5 будет 0.5 (double).Идея настолько «гениальна», что не реализована ни в одном, известном мне языке. Ни со статической, ни с динамической типизацией. Потому что можно же рассмотреть 4611686018427387903 + 0.5… и тогда что мы должны получить в результате, извините?
PS: мне столько раз написали про проблему int64 + double. Намекая на переполнение/потерю точности.Ась? Кажется вы не настолько «альтернативно одарённы», как мне только что паказалось. Нет — это не про «переполнение/потерю точности». Это просто про потерю точности.
long long и double имеют один размер (8 байт), потому существуют как числа, представимые в виде long long и не представимые в виде double — так и наоборот.но проблема переполнения существует и на банальномВ этом банальном коде нет неоднозначности. Нам не нужно знать какую именно информацию мы хотим потерять. Если результирующий тип совпадает со входным — то это определяется однозначно: что «влазит» — оставляем, что «не влазит» — выкидываем. А вот когда мы кладываем гетерогенные объекты — возникает неоднозначность.int+int,long+long,int64+int64
Причём, что характерно — ровно того класса, что и при сложении строк и чисел: мы можем превратить строку в число — и получить один результат… можем превратить число в строку — и получить другой. Оба будут, в некотором смысле, верными — и непонятно какой нам был нужен.
То же самое и при сложении
long long и double: могут быть два результата и нет никакого способа (без телепатического компилятора, способного прочитать мысли программиста), узнать — какой из них «правильный».то вопрос:
можно ли решить все двусмысленности случаев
если на месте a или b окажется матрица?
Можно таким (и только таким) же образом, как и со строками, и с числами: явным образом договорившись об определённом поведении.
со строками и числами так и не решили двусмысленности
Так и с числами не решили (см. обсуждение выше), и с векторами, и с матрицами. Объективно правильного и единственно верного решения нет, во всех этих случаях просто вопрос договорённости в конкретном языке. Причём между языками эти (как минимум, некоторые) договорённости отличаются.
Намекая на переполнение/потерю точности
Вы путаете переполнение и потерю точности. Первое — в зависимости от алгоритма можно либо заигнорить (если нас это устраивает и у нас какая-то условная криптография), либо ловить эксепшен (кстати, rust вроде так умеет?). Второе — компилятор должен страховать программиста и явно уточнять что он имел в виду
важно что двусмысленности в этом коде так же нет
Двусмысленности нет при сложении long + long: без переполнения тут не обойтись; то же со сложением double + double. А вот long + double даёт двусмысленность: либо возвращается long и теряется точность на малых значениях, либо double и теряется точность на относительно больших.
двусмысленность — это когда по тому что написал пользователь мы не понимаем что он имел ввиду. сложение? конкатенацию?
Допустим. Только вот при использовании оператора "+" для чисел и строк нет никакой двусмысленности: оба аргумента числа => арифметика, оба аргумента строки => конкатенация, иначе => ошибка.
Ещё пример с комплексным числом: «a» + (1 + 2im).
Продолжать?
Их не нужно разделять в этом смысле. Ваш мир будто распался только на строки и на числа. А чего — давайте для каждого встроенного и не встроенного типа определять свои операторы… Как 0xd34df00d и завещал
https://habr.com/ru/post/500926/#comment_21612206
а других базовых примитивов в языках обычно и нет!
Выкиньте свои языки на помойку. Как минимум есть и другие примитивы — указатели (Си, Паскали), списки (лист, функциональщина), списки-словари (питоны) и многое другое в базе
И чем это пользовательские классы хуже, чем встроенные?
а других базовых примитивов в языках обычно и нет!
Мда, печально жить в мире, где только такие языки и есть :)
обычно != всегда
почему Вы всегда всё абсолютизируете?
Хах, абсолютизируете здесь как раз вы, вот прямо в этой цитате. Я же нигде не писал, что на самом деле есть только такие языки — просто сказал, что печально жить в мире, где это так.
Ну а серьёзно — во-первых, как раз обычно в языке есть и другие примитивы кроме чисел и строк. Во-вторых, принципиальной разницы между чем-то что решили включить в стандартную библиотеку, и решили не включать, нет. Питон заметно не изменился бы, если бы условный dict был в отдельном официальном пакете.
почему Вы называете адекватным язык, допускающим двусмысленности в операторах?
Потому, что двусмысленности тут никакой нет — она только в вашем представлении. Оператор "+" выполняет операцию сложения над двумя его аргументами. Обычно под сложением понимают: для обычных чисел — арифметическое сложение, для матриц — поэлементное, для строк — конкатенация. А вот что понимать под сложением строки и числа, которое вы приводите, я не знаю. Обычно (почти всегда?) такая запись говорит о явной ошибке, и язык должен эту ошибку выдать.
а вот когда компилятор видит сложение числа и строки возникает двусмысленность: неизвестно что хотел бы пользователь — сложеение числел? конкатенацию?
Да, конечно — эта операция стандартного смысла не имеет и должна приводить к выдаче ошибки! Потому, что конкатенация — это операция над строками и число ей передавать нельзя, а арифметическое сложение — операция над числами, и строку ей передавать нельзя.
тогда Вы не сможете например с вводом пользователя работать
Аргумент не аргумент. Просто если дальше мыслить, то какая разница — откуда пришли данные — из ввода пользователя или по сети, или из файла? Очевидно, что типизированные языки позволяют строить программы с вводом, иначе они были бы не нужны. Продолжайте в том же духе, пожалуйста. Попкорн у меня еще не закончился.
Просто если дальше мыслить, то какая разница — откуда пришли данные — из ввода пользователя или по сети, или из файла?Вы простой истины не понимаете: Дуглас и Стругацкие ошиблись. Первый считал «ответ на главный вопрос жизни, вселенной и всего такого» это 42. Вторые — что венец творения рюмка коньяка с ломтиком лимона. А на самом деле венец творения — это великий и ужасный документооборот. Он же — «ответ на главный вопрос жизни, вселенной и всего такого».
Поймите эту простую истину, которую несёт вам rsync — и больше таких вопросов задавать не будете.
ввести не цифры он не может (браузер не даёт).
Чего вы на браузере зациклились? И как будто не может быть ручки в апихе, где может прилететь мусор. А еще — пользователь же может не вводить, а скопипастить ввод из третьего места, а на копипаст по ошибке разраба фильтрация не применяется. Что за детсад?
алгоритмы надо программировать а не глупые исключения и типы и ошибки компиляции
Чушь. Смотря что понимать под «программировать» и «кодировать». Если цель — рабочий продукт — нужно писать и исключения, и типы, и тесты писать.
ноль он там ввёл. поделили на ноль — должен получиться ноль.
и пофиг на вашу математику что на ноль делить нельзя.
Ахахаха. Очень надеюсь, что вы к программированию серьёзных систем не приближаетесь. Так и вижу:
> Ваш долг 1000000 рублей. Какую сумму будете вносить в месяц?
> 0 рублей
> Вам осталось 0 месяцев. Благодарим за своевременную выплату кредита!
снова абсолютизирование детектет
Это вы писали?
делим на это число по какой-то причине.
ноль он там ввёл. поделили на ноль — должен получиться ноль.
и пофиг на вашу математику что на ноль делить нельзя.
Конечно, если речь про какую-то неважную свистелку — там как угодно можно писать, если от результата ничего особо не зависит. А в реальных системах другой разговор.
при чём тут документооборот?Прочитайте ваши три строки ещё раз. Вы вначале задаёте вопрос «причём тут документооборот», потом разворачиваетесь и тут же приводите пример ровно оттуда. Не устройства какого-нибудь. Не скрипта, которых хотя бы веб-сайты скачивает и как-то обрабатывает (как другие участники дискуссии). А сразу: «спрашиваем у пользователя число — и обязательно в браузере» (чтобы браузер за вас проверил что это число и там, скажем, нету двух точек, ага).
спрашиваем у пользователя число. он его вводит.
ввести не цифры он не может (браузер не даёт).
ноль он там ввёл. поделили на ноль — должен получиться ноль.Ещё один пример из «великого и ужасного документооборота»? Потому как я вам легко кучу примеров накидаю, из других областей, где такой подход слезьми окончится.
и пофиг на вашу математику что на ноль делить нельзя.
алгоритмы надо программировать а не глупые исключения и типы и ошибки компиляцииНу да. В мире документаооборота, а особенно в мире бумажек, которые нужны только для того, чтобы людей занять (и неважно что внутри бумажек чушь написано) — это и нормально.
Но, слава богу, в мире существуют и другие применения для компьютеров…
при чём тут документооборот?Притом, что вы, почему-то, приводите всё время примеры только и исключительно оттуда. Числа у вас проверяет браузер, ошибки в документах, если что-то пойдёт не так, вообще человек может заметь (а у него, знаете ли, здравый смысл есть, это штука помощнее даже типизации), то есть реально-то ваши программы почти не сталкиваются с данными, которые кто-то активно может портить в попытке взлома.
вот например я сейчас пишу этот текст и со мной общается бек хабра. когда я нажму кнопку «отправить» он получит мой ввод
И абсолютно ничего не мешает писать бэкенд на статически сильно типизированных языках — более того, это часто и делается!
и много Вы знаете сайтов написанных на этом?
Достаточно. Попробуйте и вы пользоваться гуглом или хотя бы википедией — много нового сможете узнать.
en.wikipedia.org/wiki/Programming_languages_used_in_most_popular_websites
и что это принесёт кроме геморроя?
Преимущества статической типизации в написании сайтов те же самые, что и в написании других приложений: надёжность, меньше проблем при поддержке/рефакторинге, удобство разработки и IDE.
Бекенд — легко. Бекенд != сайт
Например Java
https://www.quora.com/What-are-some-famous-websites-written-in-Java
у Вас в голове совсем контекст «о чём идёт речь» не держится?Нет. Не держится. Потому что никто его там и не думает держать. Для человека, умеющего в логику, дважды два — всегда четыре. И неважно — продаём или покупаем.
А вот если для вам это важно, и дважды два равно три при покупке и пять при продаже — вот тогда вам и нужен «контекст».
Ну это если совсем на пальцах.
это проблема.Мне вот интересно — вы действительно не понимаете, что над вами тут, практически в открытую, издеваются… или делаете вид?
надо тренироваться!
как вариант — попробуйте по вечерам мелкие предметы поперебирать.
Вот вы тут, наверное, видели такое «слово смишное»: монадки. Его 0xd34df00d очень любит. Так вот открою вам страшную тайну: они, как раз, и нужны, для того, чтобы «работать в контексте».
Так что про возможность «удержания в голове контекста», разумеется, все ваши собеседники осведомлены… но он должен быть объвлен явно.
А если про него ничего не сказано — значит его и нету.
Это нужно, чтобы в споре можно было вообще хоть до чего-то доспориться.
Но вы-то спорите не для этого. В принципе. Вы же сами написали, что общаетесь в основном либо с дураками, либо с идиотами — которые не знают даже чего они хотят. Которых всего лишь нужно убедить, в том, что они неправы. Не доказать, а всего лишь убедить.
Именно и только с такимии работает подход: когда приходит понимание бизнеспроцесса до конца, во первых — приходит и понимание как это в разы проще запрограммировать, как попутно решить ещё другие их задачи, что-то и им и нам упростить итп. И в итоге у меня получается 150 строк кода там где «эксперт» который не хочет вникать в язык заказчика потом пишет 1500.
Вы не допускаете даже мысли о том, что ваш собеседник может, фантастика какая, иметь представление о том, о чём он говорит.
Вы не рассматриваете, в принципе не рассматриваете, вариант, что человек, о боги, может понимать даже что-то — и произносить слова, которые значат, фантастика, то, что они значат.
Вы, автоматически, исходите из предположения, что всё, о чём говорят с вами оппоненты — это чушь, лажа полная, никакого смысла там нет… и нужно всего лишь показать это оппоненту — и он «сломается» и признает, что вы лучше его знаете о чём он говорит… а то что вы тоже говорите чушь — так это неважно, важно, чтобы она была более красивой, чем чушь, произнесённая другими.
Но вы забываете о том, что хотя дурак — самый ценный ресурс общества потребления, но, всё-таки, не все в этом мире идиоты.
Потому что кому-то же нужно и двигатель сделать такой, чтобы он не взорвался, и программу написать такую, чтобы спутник на нужную орбиту попал.
P.S. Заметьте, я много дней назад написал — что, как и зачем я буду с вами делать. А вы — даже этого не поняли. Даже не осознали, что все эти разговоры, якобы с вами — они не для вас вообще. Они для тех людей, которые на всё это смотрят со стороны и периодически ставят плюсики и минусики — и, очевидно, ухохатываются, потому что вся дискуссия уже давно перешла стадию, когда её можно было бы, в принципе, воспринимать серьёзно. Когда вы начинали — вас кое-то реально вомпринимал всерьёз. А сейчас — уже даже ваш «якобы защитник» chapuza не пытается уже вставать на вашу сторону во всех этих обсуждениях. Он пытается, независимо уже совершенно от вас пытается, показать — в чём проблемы статической типизации. И тоже не понимает, что всё что он показывает — есть не проблемы статической типизации, а проблемы понимания задачи. Есть у вас задача, которую вы можете, строго математически, сформулировать — нет проблем: берём типы, описываем её в них — и поехали. Решение пишется — и за вполне вменяемое время. Нет у вас задачи, которую вы можете сформулировать — значит статическая типизация вам не нужна, задачу вы не решите (так как у вас её и нету), всё, что вы можете получить — кучку дерьма, над которым будут виться мухи. И дальше, конечно, всё зависит только от вашего красноречия и умения убедить заказчика в том, что вот именно эта кучка дерьма — это и есть конфетка, о которой он «всю жизнь мечтал».
он в это время пока ты в эти два примитива втупливал изучал как пятерых снобов работать заставить правильно, чтоб эффективность выше была, агаЭффективность чего извините? Перекачивания денег со счёта фирмы в свой карман?
меня всегда как раз коробит когда людей другой специальности называют дураками и идиотамиНет. Дураками и идиотами я называю людей, которые употребляют термины, которых они в упор не понимают. И которые не понимают чем они, собственно, занимаются. В теории — это разные люди, но на практике — там корелляция, близкая к 100%.
Я встречал менеджеров, которые не понимали моих терминов. А я — не мог разобраться в тех, которые использовали они. Требовалось некоторое время на то, чтобы найти «общий язык», дальше — ставилась задача, решалась и всё было хорошо. И там не возникало вопросов о том, что они просят не того, что им нужно. Они чётко понимали чего они хотят, вопрос был лишь в том, чтобы перевести это на понятный мне язык.
У вас же… Вот прочитайте ваши же, блин, слова:
приходит понимание бизнеспроцесса до конца, во первых — приходит и понимание как это в разы проще запрограммировать, как попутно решить ещё другие их задачи, что-то и им и нам упростить итп. И в итоге у меня получается 150 строк кода там где «эксперт» который не хочет вникать в язык заказчика потом пишет 1500.
Это кто написал? Вы или я? Что такое, вообще, «приходит понимание бизнеспроцесса до конца»? Это значит, что вы разобрались в этом самом бизнесс-процессе (за день, неделю, месяц — неважно) лучше, чем этот самый «дядя Вася», который этим бизнесс-процессом занимается, извините, не один год. До такой степени лучше, что можете понять, что этому самому Васе нужно — лучше самого Васи.
Тут возможны, извините, только два варианта:
1. Дядя Вася — обычный человек, а вы — гений, способный во всём разобраться «быстрее и лучшее», чем те, кто занимаются этим долгие годы.
2. Дядя Вася — идиот и вы успешно «вешаете ему лапшу на ушу». Он либо никогда не понимал чем он занимался, либо вы ему впариваете то, что ему, на самом деле, не нужно — но убеждаете в оратном.
Из того, что вы тут пишите, уж извините, вариант #1 никак «не вытанцовывается».
Мне вот интересно, зачем продолжать диалог с человеком после того, как он почти прямым текстом признал, что весь этот диалог с его стороны нужен исключительно для троллинга автора статьи, а мы все просто под руку попались?
Ну муравей-то считат, что да: у них язык такой, на запахах устроенный. Феромонные метки.
Но на самом-то деле ваш собеседник, обычно, это ваш знакомый, вместе с которым вы ухохатываетесь над потугами этого самого муравья.
P.S. И да, я в курсе того, что rsync считает, что он «троллит автора статьи». Но я вам умный вещь скажу, только вы не обижайтесь: если вы считаете, что вы кого-то троллите, но этот кто-то ваши тексты даже не читает… то вовсе не факт, что тут троллят именно его… и ещё более не факт, что троллите тут вы…
P.P.S. Чтобы не было непонимания: мы с 0xd34df00d не общаемся параллельно в приватном чате, чтобы скоординировать наши действия. rsync достаточно смешон и без этого.
мне нравится смотреть как 0xd34df00d тут пытается терминами сыпать вообще не понимая что они значатА мне можно. Можно мне? Ну позяя...?
Где конкретно 0xd34df00d употребил термины настолько неудачно, что стал противоречить самому себе, его, как котёнка в лужу, в это ткнули, и он начал вопить «ну надо же учитывать контекст»?
А то я видел в этой дискуссии персонажа, который этим занимался… но это был не 0xd34df00d…
Так я запутался, что важнее — массовость той или иной программы или массовость решаемой задачи?Слушайте, вы так доберётесь до всяких идиотских идей, типа закона противоречия или даже, не дай бог, закон исключённого третьего.
Нельзя так делать: чтобы эффективно продать вашу программу «эффективным манагерам» (которые готовы верить в десять вещей, каждые пара из которых невозможна одновременно — если это увеличит их банковский счёт, конечно) — нужно мыслить примерно как они. Ну чтобы написать её, конечно, придётся несколько «урезать осетра», но в пару-тройку противоречащих друг другу вещей вы поверить можете? Вооот. А как поймёте — так, наконец, и осознаете, почему дурацкие языки, в которых подобное невозможно мешают писать программы.
P.S. Лишь наполовину сарказм, на самом деле. «Эффективные манагеры» действительно начинают обижаться, когда ты объясняешь им, что то, чего они хотят — в принципе невозможно реализовать. Всем известная история ведь не на пустом месте родилась. И меня всегда интересовало — как выглядят люди, способные с ними работать… вот, увидел. Лучше бы не видел, честное слово.
Т.е. работаем в парадигме чисто стандартной командной управленческой системы? ХОЗЯЕВА сказали — ты пошел — нет, побежал исполнять. Даже если это явная чушь. Даже если это противозаконно. Потому что ты всего лишь шестерка и на твое мнение тупо насрать. Ну, удачи жить дальше в такой же системе!
Как будто мы в мире победившего бюрократизма…
Как будто мы в мире победившего бюрократизма…В мире победившего паразитизма. В мире, где больше половины населения заняты имитацией работы люди, не умеющие в логику, типа rsync — могут прекрасно существовать.
Они с радостью берутся за задачи с противоречивыми требованиями или даже принципиально нерешаемые и… успешно решают их. Квадрируют круг, удваивают куб — нет ничего невозможного. Главное — чтобы заказчик тоже занимался имитацией работы.
Наша же программа сказала что 3.3 * 3.3 будет 10? Значит так оно и есть.
Нормальные люди, умеющие в логику, и пытающиеся сделать что-то, что, вообще, как-то работает — за ними никогда не угонятся.
Но есть проблема. Этот подход — не работает, когда подобная программа сталкивается с какими-то математическими требованиями. Физика-то ладно: там, всё-таки, всегда есть непоторая неточность и это только задача для хорошо подвешенного языка — убедить, что ваш прибор с точностью в три знака, на самом деле выдаёт, после обработки, данные с точностью пять знаков.
Заказчик всё равно ни физики и математики не знает, если там не реактор — работать как-то будет… пока не сломается.
А вот математика — тут такие фокусы не выходят.
Документооборот же стерпит вообще всё. Потому что большая часть его — это порождение бумажек, которые никто даже читать не будет. Какая вообще разница что в них написано? Важно чтобы заказчик верил, что там всё хорошо — а для этого, в общем-то умение писать правильные программы и мыслить логически не нужно и даже вредно. Если ты сам понимаешь, что чушь несёшь — «заговаривать зубы» становится сложнее…
а остальной бред про имитацию — это зависть никчёмного человека, так и не смогшего взглянуть на задачи которые решает со стороны.
Это выглядит смешно. В чем измеряется успешность человека? В пользе приносимо обществу? Общим удовлетворением им жизнью? Или в количество вечнозеленых, которые он сгребает к себе в карман? Так вот — количество денег и польза вообще могут не иметь прямой корреляции
В чем измеряется успешность человека?Количеством денег да банковском счету, конечно. Если вы можете доказать какую-то там гипотезу Пуанкаре или спроектировать самолёт- то это, разумеется полная фигня. Вот если вы или за первое или за второе получите несколько миллионов долларов… ооо… тогда вы герой.
Но только в этом случае.
Так вот — количество денег и польза вообще могут не иметь прямой корреляцииЭто ересь. Для людей типа rsync, по крайней мере.
по хорошему в куче случаев даже при делении на ноль хорошо выдавать в ответе ноль
И получать мусорные данные?
10К всяких координат/полигонов передадут нормально и где-то в серединке бэмс! и прилетела широта «37.12345» вместо 37.12345
Это такого же рода ошибка, что и подача «abc» вместо вашей широты. С автоматическим парсингом строк в число куча проблем, даже кроме того что эта идея сама по себе бредовая и бесполезная. Будете ли вы считать числами всё перечисленное дальше? «12,3» «12 345,6» «12⎖345.6», «12٫3», "π", «1/2», «XXI», «2+3i», «2+2», «0b11101», «0x1FF» и т.п.
и где-то в серединке бэмс! и прилетела широта «37,12345» вместо 37.12345
$ nodejs
> parseFloat('37,12345')
37
> +'37,12345'
NaN
 Упс…
Упс…строка преобразуется в число (если это не возможно — исключение) и складывается с числом.
если сложение двух строк — обе преобразуются в число.
По-моему это такой бред, что уже все языки от этого поведения отходят.
Каким образом?
Вот строка «15». Что она означает — число 15, число 13, число 21 или что-то ещё?
Вы предполагаете считать, что это строка всегда означает число 15? А на самом деле оказалось, что это h323-disconnect-cause, которое принято даже в тексте передавать в шестнадцатиричном виде.
А в другом месте вроде бы должно быть десятичное, но написано 15h, и что я вижу?
$ perl -e 'print 0+"15h","\n";' 15
Почему вдруг 15h стало 15?
А в третьем месте у меня 000123, потому что тут положено писать ведущие нули, и включился автомат для понимания в восьмеричной системе, хотя никто его не просил.
А в четвёртом согласно европейским традициям десятичная запятая, а не точка, поэтому я получаю:
$ perl -e 'print 0+"1,234","\n";' 1
И вообще, к слову:
$ perl -e 'print 0+"z,yx","\n";' 0
Понимаете мой консёрн (как говорят тут коллеги по отделу)? Когда у вас неявная конверсия — она может быть только одного типа: вы ею не рулите. Вы не в состоянии указать при этой конверсии: тип значения, его формат, локаль (культуру), и кучу прочих параметров, которые могут быть критичны.
Вот потому в рассказе про Turkey test в рекомендуемом коде надо указывать, как именно мы переводим из строки в число: нет универсальных правил.
> если это не возможно — исключение
Когда вы не можете задавать правила возможности и критерии этой невозможности — получается, что ваш код заточен на одну-единственную ситуацию, что может быть и почему. Для Javascript это парсинг JSON, со всеми его жёсткими ограничениями. Больше он ни на что не годен. Ну так давайте напрямую читать JSON соответствующими функциями, а зачем остальных ровнять по нему?
> резко упрощаются всякие десериализаторы (которые часто и приводят к ошибкам типов)
Десериализатор — та часть, которая должна быть чисто библиотечной. JSON? ok, import json; result = json.loads(input_string) — и полетели дальше работать, если исключение не всплыло. А так вы весь язык построили вокруг одного десериализатора… ну хорошо, только на это он и годится. И то не всегда. Пока в перловом YAML::Dumper не сделали заглядывание в реальный тип объекта (строка или число) через B::svref_2object, оно, например, выгружало в YAML телефонный номер 012 как число 12.
Это зависит от принятой системы типов
Вы про ассоциативность и коммуникативность?
int влазит в double — ладно, пусть будет double, можно считать, что неоднозначности нет.Но когда вы складываете
long long и double вы чего больше хотите? Точных результатов на больших целых или на маленьких нецелых?Компиляторы не зря могут диагностировать эту ситуацию как ошибку, если бы это не вызывало проблем — подобных опций бы в компиляторы C никто бы не добавлял.
Если рассматривать как черный ящик — вообще пофиг. Лишь бы семантика сложения для типа черного ящика соблюдалась. Так плюсисты и делают. Но вот со строчками — Вы правы. Сложение строчек это принципиально другая операция именно в терминах множеств, чем сложение чисел
Если не рассматривать как черный ящик — мы же пришли к консенсусу, что пускай у каждого типа будет своя функция, которая делает сложение. И не принципиально как она называется (?)
Но кто мне запретить в рантайме передать в функцию
def exp(a):
return a**2строку, типа такого
exp('hello')
И вот если не вводить понятие статического типа, проверяемого компилятором, а просто ввести разные операторы для работы со строками и работы с числами — то проблем не будет (потому что работа вот с этими двумя конкретными вещами синтаксически отличается, а стало быть ничего перепутать случайно невозможно).
Типа «гениальная» идея Ларри. Воплощённая, в частности, в Perl.
Perl, кстати, пошёл ещё дальше и разделил ещю и списки и кой-какие другие объекты синтаксически (массивы, ассоциативные массивы)… результат мы видим: Perl успешно головится вылететь-таки из 20 (на GitHub уже вылетел). Во-многом — именно из-за этой своей «идеи фикс».
Потому что со строками и часлами и даже, круть какая, массивами — Perl справляется. А вот как только у вас структура данных становится чуть-чуть нетривиальной (ссылки там появляются, всё такое), то сразу синтаксис Perl превращается в такую кашу, что работать с этим могут только отдельно выдрессированные мазохисты.
Убойный синтаксис — второй (и тут вопрос не в разделении операторов, а, например, в $a->{b}{c} (и это уже с тонной сахара) вместо a.b.c.).
Третий — умолчание типа «ключа хэша нет — даём undef».
У нас веб на перле, я эти страдания регулярно наблюдаю :)
(опечатка: наблюадю — очень в тему)
Я не знаю, когда там Гугл его взял на вооружение, но мой основной питоновский компонент ведётся с 2003 года (самое смешное, что на Python его сделали после неудачного старта на C++).
И да, пришлось чуть доказать, что это лучше, чем перл.
> миграция на питон с перла или с питона на пхп или с обоих на руби — НИЧЕМ кроме моды не объясняется.
Я уже объяснил преимущества Питона. Грубо говоря, с ними те же усилия программиста нужны для поддержания в рабочем состоянии кодобазы не в 1000, а в 30000 строк.
> Говорить «я перешёл на питон/пхп/руби» потому что стало проще делать ХХХ, обоснованно нельзя.
Увы, обоснованно. Чисто практический факт, на сравнении с мучениями соседей.
Ссылка на старые новости (архив).
Python is my programming language of choice. I've been using it since 1998.
I am a member of the Python Software Foundation and previously served on its Board of Directors. In 2007 and 2008, I was the organizational administrator for the Python Software Foundation's projects in the Summer of Code.
I've given numerous Python-related talks from local meetups to keynoting PyCon Taiwan in Jun 2012.
Но тем не менее, столкнувшись с трудностями при разработке и отладке, он сменил язык разработки на Java и переписал его весь.
нет, мода погнала людей на питон до того как типизация в питоне появилась.
Это как так? Типы в питоне с самого начала были, и типизация всегда была сильнее, чем в джаваскрипте (про перл не знаю, но видимо по сравнению с ним тоже).
а так, питон — это язык в котором существенно больше всяких __хаков__ и недоделок
В питоне как языке куча своих недостатков — но вот что-то, а типизация там сделана явно лучше, чем в каком-нибудь js или php (хотя современный php не знаю, может уже поправили).
Вы же прекрасно понимаете что я о тайпхинтинге который появился ЕМНИП в 3.5.3 по моему.
Только речь-то была не про тайпхинтинг, а про типизацию. В питоне она явно более сильная, чем в js.
то что в одном случае один язык бросает исключение, а другой нет — не говорит о том что тут типизация сильнее
Как раз именно это и говорит.
можно найти исключение которое бросит первый язык но не бросит второй и наоборот
Я не встречал, но если таких примеров сопоставимое количество, что и обратных — готов согласиться, что в питоне типизация не сильнее.
Вывалится исключение TypeError или что там у Python и выполнение программы не продолжится с неожиданным результатом
Пару недель назад. По формуле было надо. А что не так-то?
я кстати не знаю языка где они из коробки есть,
APL и его потомки
True — это не строка, а булево. Следовательно, по Вашей логике, надо запретить сложение булевых и чисел? А во втором кейсе разработчик возможно хотел скастовать 3.14 в строку и получить «3,1427» (ага, еще вопрос с каким разделителем). Поэтому давайте не будем додумывать за разраба, ок? Пускай он пишет большой и вербозный код как на Джаве, зато нет вопросов
по моей логике если человек написал «плюс» — он хочет сложить числа, и если где-то почему-то он указал не число — попытаться его извлечь и использовать извлечённое.
И получится javascript или php. Я очень рад, что никакой язык на котором я пишу так не делает.
по логике адептов типов — тут надо бросать исключение.
Полностью согласен, true + 10 не должно работать. Бросать исключение или выдавать ошибку на этапе компиляции — это уже детали.
Есть нюанс с булевым, в одних языках он равен -1, в других — +1
с одним уточнением: математические операции над матрицами в программировании встречаются сильно реже обычной арифметики и строковых операций.
Арифметические операции над массивами в программировании встречаются не сильно реже конкатенации строк. Особенно, если говорить о питоне, после введения f-strings.
в связи с этим уточнением матричные операторы в сам язык вводят крайне редко
Мы там про питон говорили, да? Так вот, __matmul__ уже в самом языке, даже не в stdlib!
Ларри сказал: «тут неоднозначность связана не с типами, а с неверным применением математического знака „плюс“.А вот и нет! Здесь неоднозначность как раз и связана с тем, что нет разделения на типы. А уже как их разделять: задавая их явно, или применяя к ним разные операции — дело второе.
Тестами Вы можете выявить более широкий класс ошибок (ошибки сводимые к типам — сильно меньшее множество всех ошибок)
Пройденный тест — это всегда лишь гарантия того, что тест проходит. Не больше не меньше.
Иными словами, чтобы покрыть тестами те ошибки которые я покрываю типами мне нужно написать тесты на все варианты и всегда их поддерживать в актуальном состоянии, после добавления еще одного варианта. Я для такого слишком ленивый и рассеянный.
И да, суть не в том, чтобы не видеть «TypeException». Таких ошибок мало. Суть в том, что всякие IllegalArgument, NullPointer и прочие — могут быть покрыты типами вместо тестов.
если вы разделите возвращаемые типы — вы потратите X усилий
если Вы типизируете Compare — то потратите ещё Y усилий
при этом вы сократите вероятность ошибки (не сведёте ее к нулю) определённых классов.
В том-то и дело, что типы помогают гарантировать отсутствие определённых ошибок. Пример с матрицами я уже приводил. Ещё пример: с помощью типов мы можем гарантировать, что код обрабатывает только экранированные данные и потому не подвержен SQL-иньекциям. Или вот ещё пример: с помощью типов мы можем гарантировать, что, если вам выпало несчастье оборачивать библиотеку с глобальным состоянием, мы корректно вызываем функции, которые это состояние модифицируют. Как вы собирайтесь на это тесты писать?
Представляю как ограничить тупого и неаккуратного себя типами.
Нет, не представляете.
умел сам задавать порядок сортировки произвольным образом
Сие подразумевает, что компаратор пишет зеленый юнец. Вам там уже подникидали пример, наглядно поясняющий за бессмысленность типов в таком варианте. Ну вот как без типов:
@spec sort(
any(), any(),
((any(), any()) -> :lt | :gt | :eq) :: boolean()
def sort(e1, e2, comparator) do
case comparator.(e1, e2) do
:lt -> true
:eq -> true
:gt -> false
other ->
warn("Comparator has returned unexpected #{inspect other}")
false
end
endЭто сортировка. Мир не рухнет, если я отсортирую что-то неверно, поэтому мы не отказываемся продолжать работу.
dialyzer не позволит джуну вернуть из comparator что-то, отличное от :lt|:eq|:gt, спеки эрланг выведет сам, но компиляцию это пройдет (!) и когда вам потребуется загрузить обновленный код здесь и сейчас, без остановки процесса, этот код выполняющего (кэши, миллионы соединений, то-се) — вы сможете загрузить другой компаратор (hot code upload), который умеет сравнивать вновь появившиеся во фронтенде «отложенные задачи», сортируя их в конец. Хотя они вполне себе совершенно другого типа.
И да, “Fail Fast” придумал Джо Армстронг, который (помимо внушительного вклада в CS вообще) преимущественно известен созданием языка с динамической типизацией.
Мир не рухнет, если я отсортирую что-то неверно, поэтому мы не отказываемся продолжать работу
А может и рухнет — заранее это никто не может знать.
Мир не рухнет, если я отсортирую что-то неверно, поэтому мы не отказываемся продолжать работу.Ну вот, собственно, в этом и заключается отличие статики от динамики. Если у вас «мир не рухнет», если вы отсортируете что-то неверно (а что фирма обанкротится — так вам и неважно если вы денежки уже успели в оффшоры вывести) — тогда подход один. Если «мир не рухнет» (а рухнет всего лишь самолёт) — подход другой.
Я про это уже много раз говорил: если вам не нужна программа, которая работает, а нужна просто программа, которая «что-то делает»… да, динамика — наше всё.
И да, “Fail Fast” придумал Джо Армстронг, который (помимо внушительного вклада в CS вообще) преимущественно известен созданием языка с динамической типизацией.А потом он машину времени изобрёл, чтобы в 1985й слетать и рассказать об этом Джиму? Этот принцип появился, вообще-то, тогда. И является, я бы сказал, полной противоположностью только что написанному вами коду…
The dialyzer is a static analysis tool that identifies software discrepancies, such as definite type errors.
Я из этого сделал вывод что Dialyzer сам проверяет ошибки типов при компиляции. Ну это конечно именно тот кейс динамической типизации который мы обсуждали. Я говорил о том, что проверки на типы — неплохая штука. Вы сказали мне, что я ничего не понимаю и вообще не прав, а в доказательство притащили код, который конечно написан на динамическом ЯП, но при этом использует тулу статического анализа делающую проверку на тип. Это какая-то странная аргументация…
И да, мне все еще не нравится возможность сравнивать слонов и бегемотов, если мое требование — невозможность сравнить слона и бегемота. Уверен, что на эрле можно и это организовать — но в чем тогда разница, кроме небольшого отличия в способе объявления этого требования и верификации?
Если что, мой код выглядел бы как-то так (писал на котлин, поэтому шума многовато, но думаю суть ясна):
enum class ComparationResult {
LESS, EQALS, GREATER
}
fun <X> ((X, X) -> ComparationResult).toCollectionComparator() = Comparator { f: X, s: X ->
when (invoke(f, s)) {
ComparationResult.GREATER -> 1
ComparationResult.EQALS -> 0
ComparationResult.LESS -> -1
}
}
sealed class State {
object NotStarted : State()
object Paused : State()
object Active : State()
object Completed : State()
}
interface HasState {
val state: State
}
fun List<HasState>.sortByState(compareFunction: (HasState, HasState) -> ComparationResult): List<HasState>
= sortedWith(compareFunction.toCollectionComparator())
fun comparatorFromOrdering(vararg order: State): (HasState, HasState) -> ComparationResult = { f: HasState, s: HasState ->
when {
order.indexOf(f.state) < order.indexOf(s.state) -> ComparationResult.LESS
order.indexOf(f.state) > order.indexOf(s.state) -> ComparationResult.GREATER
else -> ComparationResult.EQALS
}
}
fun sortExample() {
val sortedList = arrayListOf(object : HasState {
override val state: State = State.Paused
}, object : HasState {
override val state: State = State.NotStarted
}, object : HasState {
override val state: State = State.Active
}, object : HasState {
override val state: State = State.NotStarted
}, object : HasState {
override val state: State = State.Completed
}).sortByState(comparatorFromOrdering(
State.Completed,
State.Active,
State.Paused,
State.NotStarted
))
}
К сожалению, здесь мне пришлось перенести ответственность по реализации компаратора правильно на клиент. Но если бы я писал самолет, я бы убрал и эту возможность из заставил гарантировать передачу всех типов стейтов в функцию создающую компаратор из порядка элементов. И взял бы другой язык, а не Kotlin)
Основная разница в том, что dialyzer позволит мне описать функцию compare, принимающая что угодно, но возвращающую :lt|:gt|:eq. А это, в свою очередь, позволит мне обновить серверный код, не останавливая процессы.
Без завтипов, которых нет даже в Хаскеле, вам это реализовать не удастся. А бизнес.правило «сортируем по дате, а если у элемента даты нет — то по имени» — вполне себе имеет право на существование.
Ну и когда я говорил про «не понимаете» я имел в виду, что вы отсекли один тип ошибок, а не все ошибки. И принесли ограничения, которые часто с бизнесом не живут.
Фанатики типа khim могут до бесконечности повторять чушь про самолеты, но джун скорее в знаке ошибется, чем в типе. И сортировка в GUI не должна останавливать весь мир, я оговаривался, что речь про конкретную задачу. Так-то dialyzer можно засунуть в CI, и тогда оно даже до тестов не дойдет.
Без завтипов, которых нет даже в Хаскеле, вам это реализовать не удастся.
Я в хаскеле только поверхностно разбираюсь, но что сложного такое реализовать? Создаём enum с тремя элементами, и требуемая функция будет иметь шаблонный тип «T -> этот enum» для любого T.
На завтипах свет клином не сошёлся. Не надо их приплетать куда ни попадя. Это не всё решающая магия, а довольно тупой формализм со своими границами применения.
Связи между возможностями проверки типов и обновлением без остановки нет. Это совершенно разные вещи, перезагрузку кода можно сделать и с C (и делается, почитайте про `telinit -u`).
Это был основной аргумент за такую типизацию?
(Да, надо учитывать и преобразование формата данных, включая сообщения, зависшие между процессами в момент апгрейда. Так что общая картина чуть сложнее. Но это тоже не требует динамической типизации внутри кода компонентов, только на их границе.)
> но джун скорее в знаке ошибется, чем в типе.
У меня тут в отделе есть джуны. Продукт на Python. Наблюдаю ошибки типов чаще, чем в знаке. Часто также вариант «потерял ещё одно место вызова метода», при том, что IDE отказывается анализировать код — не понимает, где реальные места вызова, а где одноимённый метод у совсем других классов.
> Так-то dialyzer можно засунуть в CI, и тогда оно даже до тестов не дойдет.
И далеко не всё на нём можно сформулировать. Простые ошибки, да, мы им вылавливали.
почитайте про telinit -uОбязательно. Про что еще мне почитать? USR1?
Это был основной аргумент за такую типизацию?
Нет.
Связи между возможностями проверки типов и обновлением без остановки нет.
Но это тоже не требует динамической типизации внутри кода компонентов, только на их границе.
Так требует, не требует, или «немного беременна» не считается?
И далеко не всё на нём можно сформулировать. Простые ошибки, да, мы им вылавливали.
Э-э-э… Наверное. Где мне нужно построже, я использую pattern-matching. Да, я слышал, что в процессе компиляции — лучше, мне даже показывали бенчмарки, где такая рантайм проверка отжирает целых две наносекунды.
Для общего кругозора — можно. Для данной темы — уже нет смысла.
> Так требует, не требует, или «немного беременна» не считается?
Для вас, например, парсинг октетного потока в HTTP перед его переводом во внутреннюю форму — уже «беременна», или ещё нет? Считайте, тут такой же случай.
> Э-э-э… Наверное. Где мне нужно построже, я использую pattern-matching.
У нас было недостаточно — очень многие вещи передавались как proplist и было важно, какие элементы в каком составе. Переводить на структуры было дороже.
Давно у нас открытые юнионы перестали быть типами?
Цитаты:
«Данные по распространённости ошибок несоответствия типов приведены в таблице 3. Из таблицы видно, что доля отчётов, посвящённых именно ошибкам несоответствия типов, для некоторых проектов превышает 8 %.»
«При этом необходимо учитывать, что тема значительной части отчётов (более 90 %)………… не дефекты, а логические ошибки, которые обнаружить автоматическими средствами невозможно»
«Таким образом, отчёты об ошибках несоответствия типов составляют для некоторых проектов большинство отчётов об ошибках, которые можно найти автоматически.»
- Автор статьи вроде как предлагает прежде всего статическую типизацию. Да, она обычно построже динамической, но это, по идее, лишь корреляция.
поэтому люди часто (целых 8% случаев) сталкиваются с проблемой несоответствия типовВы не не до конца прочитали это исследование — «отчёты об ошибках несоответствия типов составляют для некоторых проектов большинство отчётов об ошибках, которые можно найти автоматически».
И статическая + строгая типизация — это принципиальное решение этой проблемы, а «устранение базовых коллизий из языка» здесь костыли.
О да! Достался мне тут в доработку один "сложный алгоритм" на питоне. Прежде чем хотя бы приблизительно понять, что там откуда и куда, пришлось три дня убить на расстановку типов.
Подходит она для очень большого круга задач: на PHP, JS и Python решено и решается множество задач от "формошлепства" в вебе до задач в области ИИ и системного софта.
Python будет прочно сидеть в качестве второго языка для простых разработок. А в остальных областях посмотрим. Но описанное выше замечание все равно будет работать.
А что, С/С++ — уже не статически типизированные? Или в данном случае важно не "статика-динамика", а "слабая-сильная"?
Собственно это всё и объясняет: если у вас в голове каша и с формальной логикой вы не дружите — то динамические языки это ваше всё. И с этим, я в принципе, согласен и везде это повторяю.
Только не тешьте себя иллюзиями о том, что вы сможете что-то «большое и светлое» на этом построить. Это так не работает. Дендрофекальный метод (и его разновидность в виде динамически-типизированных языков) имеет свои ограничения.
это где она была закреплена?В жизни
Вот например что такое «Rocket Science»?Это разработка больших и крутых систем, куда динамические ЯП не подпускали и близко.
Большинство нейросетевых приложений пишется отнюдь не на Хацкеле/Расте/etcА при чем здесь ФП?
А, да-да, на банальных Python/Java/etc а низкий уровень на банальном С/С++А Java и С/С++ это уже динамические языки???
Это разработка больших и крутых систем, куда динамические ЯП не подпускали и близко.
Как насчет Erlang?
Как насчет Erlang?А он что, широко распространен?
А он что, широко распространен?
А где я говорил, что он широко распространен? На нем написаны крутые штуки, которые держат довольно большую нагрузку. Facebook, Whatsapp используют Erlang, это из того что сразу вспомнилось. И при этом у него динамическая типизация.
На заре массового промышленного программирования ЯП с динамической типизацией сыграли свою полезную историческую роль. Но в будущем их ниша — это вспомогательные, простые, с коротким циклом разработки вещи.
UPD
С меня +1 в карму
Привет, питонщики! Объясните мне, есть ли хоть один профит от такого архитектурного решения? Чем руководствовался ван Россум и как это согласуется с дзеном питона? Явное лучше неявного, ведь так?
Как по мне, так тот, кто это придумал, как честный человек, должен выстрелить себе в голову :)
Пишу попеременно то на Ruby, то на Java, то на Python, то на Go — везде себя хорошо ощущаю. У всего есть свои плюсы и минусы. Автор пусть вентиллятор на себя развернёт и сам своё говно нюхает
Во-первых, в питоне нет проверки типов и честной типобезопасности: невозможность пресловутого 10 + '10' обеспечивается проверками в int.__add__ (насчёт конкретно int не уверен, мб и в коде CPython/PyPy, но для не-встроенных типов точно так). Вполне можно написать свой числовой тип, который умеет складываться со строками, датами и чёртом в ступе; ван Россум просто справедливо решил, что встроенным типам это не нужно.
Во-вторых, свойства объектов (и типов (которые тоже объекты)) можно менять в рантайме. Если какой-нибудь my_type.__eq__ или my_type.__len__ может в самый неожиданный момент поменять семантику, то строгая статическая типизация не имеет смысла. Любые утверждения о том, какие у типов могут быть значения и какие над ними возможны операции, приобретают ссылочку мелким шрифтом "если только пользователь не залезет куда не надо".
TL;DR Питон довольно убедительно изображает строгую типизацию (особенно на встроенных типах), но вообще-то у него нестрогая.
Во-вторых, свойства объектов (и типов (которые тоже объекты)) можно менять в рантайме. Если какой-нибудьmy_type.__eq__илиmy_type.__len__может в самый неожиданный момент поменять семантику, то строгая статическая типизация не имеет смысла.
Это ещё очень забавно сочетается со номинативной типизацией классов.
После этой стадии все задалбливаются писать в начале функции if type(str) == type(var)
В любом случае будет дерево ифов
Вообще-то эта проблема свойственна не только языкам с динамической типизацией — аналог instanceOf почти везде есть. И если дошло до проверки типа, то беда не столько в типизации, сколько в архитектуре.
И если дошло до проверки типа, то беда не столько в типизации, сколько в архитектуре.
Не согласен. Как только проект вырастает из «я написал на коленке» в «2 разраба и гитхаб» уже пора вводить строгую типизацию. Иначе в итоге когда дойдет даже до «10 товарищей пишут ос» вы начнете проклинать разраба, которые не проверил тип. Я уж молчу про security.
По-нормальному, так никто не пишет.
Это может быть можно в каких-то точечных участках, но это единичные случаи.
Ну и к тому же duck typing никто не отменял. Жив и здравствует во многих языках.
Смотря с какими целями вы ставите проверку типов. Что покрывают некоторые языки с динамической типизацией в рантайме (опустим сторонние станализаторы) без if/switch/..., навскидку:
- явное приведение типов
- неявное приведение типов
- type error
Philipp Ranzhin
Король разработки
Ну что-ж, если король сказал, наверное, так и есть.
«Серьезно? Серьезно? Нам лень писать символы? Братан.» — и вот это всё.
Ну так в русском языке в большинстве случаев (не считая, конечно, специально сконструированных) "вывод типов" работает вполне однозначно, разве нет?
Короче, попытка в исходном комментарии хорошая, но, увы, устаревшая лет на 30 (или когда там Хиндли-Милнера изобрели)А мне понравилось, прямо в точку. Хиндли-Милнер выводит общие типы. Инструмент для графоманов, чтобы налить в текст больше воды и абстрактных рассуждений. Но ведь порой так хочется конкретики.
Когда вы писали свою статью, почему вы перед каждым словом не проставили его часть речи, чтоб избежать омонимии?
Потому что если вдруг читатель неправильно поймёт эту самую часть речи у отдельных слов, то ничего страшного не произойдёт. И даже если автор статьи ошибётся в грамматике/синтаксисе языка, то ничего страшного не произойдёт. Даже если из-за этого отдельные слова/предложения/абзацы будут нечитаемы или плохо читаемы.
А вот если такое произойдёт при исполнении вашего кода в продакте, то наверное последствия будут не особо приятные. Или я ошибаюсь?

[ источник ]
(картина в разных источниках примерно одинаковая)
На мой взгляд, ошибаетесь. Мир массово использует динамические языки в продакте, и мы пока ещё живы.
Естественно живы. Но во первых это «живы» требует дополнительной работы в виде аннотаций, проверок, дополнительных тестов или времени, которое тратится на понимание чужого кода. А во вторых «неприятные последствия» это же не обязательно «смерть».
(картина в разных источниках примерно одинаковая)
И что это должно доказывать? Что основная масса человекочасов сейчас требуется в вебе? И что вы этом самом вебе уж так исторически сложилось что в основном пользуются JavaScript?
Ну и потом вот эта строчка «JavaScript» это исключительно «чистый JavaScript» или она всё-таки в себя включает и какой-нибудь TypeScript и/или всевозможные фреймворки?
А Java вообще не честно, потому что если бы не Android.
А C# вообще не честно, потому что если бы не Windows и Unity.
А Python вообще не честно, потому что если бы не ML и наука.
и т.д.
Любая экосистема, завязанная на язык, не даёт этому языку умереть.
Что, в общем, иррелевантно моему изначальному аргументу — мир массово использует динамические языки в продакте, и мы ещё живы.
В браузере чисто написать ПО полноценное на C# не реально.
А DOM, в свою очередь, нужен для того, чтобы ваша информация была доступна через Google и Yandex.
Что самое забавное: до недавнего времени это было не так, был ещё и другой такой. ActionScript. Тоже динамический, впрочем, так что хрен редьки не слаще.
Но пока известно кто не устроил «священную войну» — был вполне себе конкурентом JavaScript в Web.
Статическая проверка типов удобна для разработки, но зачем ее тащить в продакшен? У популярных сайтов десятки миллионов посещений в день. Каждый пользователь загружает один и тот же код. Выполнять в браузерах пользователей такие проверки по сто раз на дню это бесполезная трата ресурсов и лишние секунды для старта страницы. Отдавайте валидный код.
Написать альтернативный рантайм, который будет кроссплатформенным, быстрым, безопасным и удобным для разработки это крайне сложная инженерная задача. В эпоху продвижения аплетов, флеша и сильверлайт сообщения о критических уязвимостях выходили чуть-ли не каждую неделю. Долгая компиляция и проблемы с отладкой кода так же играли не в пользу таких решений. Про кроссплатформенность то и дело сочиняли анекдоты.
Сейчас вы можете писать код практически в любой парадигме, транслировать результат в JS, с большой долей уверенности, что он будет выполнен везде. Хотите берите местные решения: Closure, TypeScript, PureScript, Elm и т.п. Не хотите, можете попробовать LLVM.
По моим наблюдениям, в веб хорошо живется текстовым протоколам и открытым решениям. Бинарные заняли какие-то свои узкие ниши, но остаются маргиналами в этой среде.
Серьезно, корпорации были готовы вкладывать большие деньги в технологии и маркетинг. Но чисто экономически от нативной поддержки второго, третьего и так далее языка в браузере поверх того же рантайма нет ни какой пользы.
Извините, но нет. На мой взгляд единственная причнина почему это не сработало это то, что каждая фирма пыталась протолкнуть какое-то своё собственное решение. Если бы договорились на каком-то одном общем, то не было бы никаких проблем. Вон тот же флэш вполне себе «взлетел» хотя обладал всеми описываемыми вами недостатками.
Написать альтернативный рантайм, который будет кроссплатформенным, быстрым, безопасным и удобным для разработки это крайне сложная инженерная задача.
Если вы его хотите сделать идеальным, то да. А если просто лучше имеющегося, то это вполне себе реализуемая задача.
Да даже если просто JS переписать с нуля, то это будет лучше того что мы сейчас имеем.
Да даже если просто JS переписать с нуля, то это будет лучше того что мы сейчас имеем.Вот и вопрос, почему это никто не смог сделать.
А все тянут оделяло в свою сторону и договариваться не хотят.Там вполне себе консенсус. И «топят» все альтернативы все вполне себе успешно и независимо.
Уж сколько было этих альтернатив! NaCl, Asm.Js, Wasm, Dart… неизменным остаётся отдно: полный консенсус разработчиков всех браузеров на тему того, что перед тем как ребёночка выпускать в свет — нужно обязательно ему ручки-ножки то переломать. А то ведь неровён час альтернатива JS появится. Какой-нибудь NaTcl.
P.S. На самом деле, что самое смешное, там даже сговора-то нет. Просто тот факт, что JS имеет прямой синхронный доступ к DOM настолько в печёнках у всех разработчиков браузеров, что делать такой же доступ для чего-то ещё — они просто категорически не хотят. Но в сухом-то остатке что? Кривая, косая, раздолбанная арба с колёсами и куча прекрасных, великолепных, разноцветных, разномастных автомобилей — принципиально без оных. Удивительно ли, что все продолжают кататься на «раздолбанной арбе»?
TypeScript заявляется с возможностью прозрачного перехода с JavaScript, но на практике это не работает :(
На моей практике везде, где пытались постепенно переходить на TypeScript, приходили к одному из двух выводов: или останавливаем плановую разработку и переводим всю или почти всю кодовую базу на TS, или отказываемся от него. Причём форсировали поднятие вопроса именно инициаторы перехода. В частности им надоедало, что а) появляется новый код на js или меняется существующий так, что написанные для него d.ts перестают работать б) те, кто переходил на TS из под палки писали на нём много any, as, тайпгварды с return true, игнорировали наличие в языке дженериков, алгебры типов и т. п. В общем техдолг по переходу рос быстрее чем переход происходил.
.ts) — есть.Да, это действительно так: польза от статической типизации управляется всё тем же Закон Меткалфа, а вот «лишние» затраты — определяются размером границы между статически типизированным миром и динамически типизированным.
Если у вас есть люди, стремящиеся эту границу постоянно увеличить… то вы вполне может попасть в ситуацию, когда вреда будет больше, чем пользы.
На мой взгляд есть. Или нужно тратить время на описании типов на границе TS и JS, или any и ко будет проникать повсюду в TS код, сводя на нет плюсы статической типизации, но заставляя платить за неё.
Люди могут быть не стремящиеся уменьшить границу, просто решающие задачи наиболее эффективным на данный момент способом.
Люди могут быть не стремящиеся уменьшить границу, просто решающие задачи наиболее эффективным на данный момент способом.
Люди могут быть не стремящиеся уменьшить границу, просто решающие задачи наиболее эффективным на данный момент способом.Вообще не проблема. Простенький linter, не дающий коммитить код с «any и ко» без аппрува со стороны конкретных людей, которые дают его раз в день — и эффективным резко становится разумный способ.
Время разработки тогда увеличивается в разы.
На моих проверках результат обратный. Решение сделать проект на 3-4 месяца (стабильная оценка JS) на TS на базе существующего JS кода при всех включенных настройках мало того, что приводит к бОльшим оценкам у команды, так и ещё и стабильно недостаточной. Один проект просто закрыли, когда с оценкой на JS дали 3 месяца, но потом продали TS и с оценкой в 6 месяцев, в 9 не уложились.
Это дает дополнительные очки.Какие же, интересно? Какие проблемы это вам создаст — все знают: так как вы понятия не имеете какими именно будут эти скрытые типи, то вы легко пожете создать код, где V8 будет промахиваться — и скорость резко упадёт. На порядок, а то и на два.
Если «прикопать» такой код, а потом резко его «исправить» — то можно получить премию. Но то такое — с такими навыками нужно в цирке выступать, а не код писать.
Какой-нибудь реальный выигрыш — можно?
JIT выводит типы (hidden classes) на основе реальных данных, а не каких-то абстрактных описаний.Ага — и теперь вам нужно угадать какие типы вам JIT куда навесит, заметить, что JIT это сделал неверно и, если нужно, исправить.
Нет, если вам нравится решать ребусы — то это, так-то, интересная деятельность. А вот если вам нужно эффективно решать задачи…
Не встраивались прямо в страницу, написать в блокноте код было недостаточно.
Как тогда быть с тем же TypeScript? Какое он тогда вообще имеет право на существование? Ведь по этим критериям он точно так же «объективно вчистую проигрывает» JavaScript.
Ну смотрите, в контексте веба доминируют скриптовые языки: JS, PHP, Ruby, Python. Совпадение?
А доля компилируемых стала расти, субъективно, когда пошёл переход к SPA, когда сайты начали превращаться в веб приложения с толстым клиентом, а серверы стали отдавать XML, JSON и вообще бинарные потоки.
Ну смотрите, в контексте веба доминируют скриптовые языки: JS, PHP, Ruby, Python. Совпадение?
Конечно нет. Просто как вы сами нап написал, на заре веба когда закладывались стандарты и выбирались пути, от языков в вебе особо много не ожидалось.
Логика была простая и обычно влезала на страничку-две.
Потом логика начала пухнуть и понадобились другие решения. Но веб «застрял» на скриптовых языках и попытки что-то поменять/добавить можно сказать блокировались. Кем и почему это вопрос отдельный и по нему можно книгу наверное написать.
Ну, про фронт может и можно сказать, что "блокировались", но вот с бэком как? Вот совсем недавно искал работу в качестве лида и большинство релевантных предложений было "набрать команду для нового проекта на PHP (Symfony или Laravel), MySQL (тоже слабая типизация, между прочим, по сравнению с тем же Postgre) и React (TypeScript не упоминали, но не факт что можно было бы его использовать) и реализовать его". Есть подозрение, что стэк выбран не с потолка, а имеет экономическое обоснование.
Ну а так часто выбор технологии для проекта зависит не от самих технологий, а скорее от имеющихся обстоятельств. Например от того какое know how уже имеется на фирме/в команде.
Различная статистика показывает, что не просто такие языки доминируют, а PHP конкретно по количеству инсталляций.
Мой пример не такой случай — команду с нуля набирать, а в компаниях либо вообще технарей нет (может CTO, который для проведения техсобеса по веб-технологиям собирается привлекать сторонних специалистов), либо наоборот, полно всякой экспертизы — лидеры транснационального аутсорс/аутстафф рынка.
Просто сравнение «сферических технологий в вакууме» это одно и в такой ситуации я вам скажу что на мой взгляд тот же TypeScript лучше чем JavaScript.
А если надо выбрать технологию для проекта и набрать людей, а на рынке 100500 специалистов по JS, и ни одного по TS, то…
Различная статистика показывает, что не просто такие языки доминируют, а PHP конкретно по количеству инсталляций.Ну дык тут та же проблема, что и с доступом к DOM: PHP оказался единственным языком, позволяющим запускать скрипты разных пользователей в одном Web-сервере без разделения прав на уровне процессов.
Можно долго рассуждать — почему так получилось, но вот так вот вышло. Разработчики PHP это сделали, а кроме них — никто.
Сегодня это уже, на самом деле, и неважно… но армия разработчиков на PHP продолжает влиять на рынок. Дешевле же писать на языке для которого можно нанять одного из тысяч (миллионов?) индусов, чем на чём-то другом.
PHP оказался единственным языком, позволяющим запускать скрипты разных пользователей в одном Web-сервере без разделения прав на уровне процессов.
Это вы про что конкретно?
Дешевле же писать на языке для которого можно нанять одного из тысяч (миллионов?) индусов, чем на чём-то другом.
С одной стороны, особой разницы в цене разработчиков на мэйнстрим языках в веб-разработке я не вижу. По крайней мере такой, что мотивировала бы меня, как PHP-разработчика, сменить стэк :) С другой, "индусы" уж Java и C# успешно освоили точно.
Это вы про что конкретно?mod_php, safe mode, дешёвые хостинги.
Да, сегодня он выпилен «с концами»… да и не нужен уже. Но свою роль — оно таки сыграло.
Иногда лучше казаться, чем быть:
safe mode никогда не был особо «safe», но он был достаточно «safe» для того, чтобы его использовать и зарабатывать на этом деньги… а остальное — уже история.С другой, «индусы» уж Java и C# успешно освоили точно.Дык они и более популярны, чем PHP. Но не в Web, надо полагать. Инерция.
Есть подозрение, что стэк выбран не с потолка, а имеет экономическое обоснование.
Естественно. На такой стек найти команду можно гораздо быстрее (раньше старт, раньше выхлоп) и дешевле. И, немаловажно, херак-херак и в прода MVC делается быстрее.
Не поймите неправильно, я PHP очень люблю и уважаю, но зачастую здоровенные проекты оказываются написаны на нём исключительно потому, что прототип взлетел и надо ускоряться — сейчас забросаем железом а потом, как-нить перепишем по уму. (тут притча про техдолг)
Ну смотрите, в контексте веба доминируют скриптовые языки: JS, PHP, Ruby, Python. Совпадение?
Обсуждение идет в теории динамика vs статика. А в качестве примера почему-то конкретные языки.
А какие у них альтернативы в мире статики, чтоб разница была практически только в параметре «статика — динамика», 10-15 лет назад, на чем можно было нафигачить homepage человеку с нуля? для js даже серверов не надо было поднимать, если исполнять его на клиете, вот люди и писали на нем падающие снежанки да дергающийся текст, открывая в браузере и радуясь.
hello world на питоне пишется вот так
$ python
Python 2.7.17 (default, Apr 15 2020, 17:20:14)
[GCC 7.5.0] on linux2
Type «help», «copyright», «credits» or «license» for more information.
>>> print «hello, world»
hello, world
>>>
Статическая типизация у мейнстрим языков,
1)c++, ну это в расчет не берем, чтобы выучить c++ за 24 часа как известно надо по быстрому выучить квантовую физику, изобрести машину времени и вернуться назад на несколько лет, чтобы выучить язык к моменту «сейчас + 24 часа»
2)C# только под виндой запускался, тоесть на дешевый vps за 5 долларов его не запихнешь.
3)java, тоже не самый низкий порог вхда, слишком многословна, требует IDE для разработки
У каких из них есть возможность писать в обоих стилях?
JS — TS, ну так многие люди и переходят на TS, потомучто для начала его можно настроить не строго.
python с тайпхинтами и mypy? опять же, люди стараются по моим наблюдениям писать с тайп хинтами, но необязательность этого действа часто сводит на нет наличие такой сущности в языке.
Сейчас есть например GO, который вполне себе конкурент скриптовым и динамическим языкам в вэбе. очень простой синтаксис, простая настройка среды. Низкий порог входа.
.net core позволяет начать писать на c# f# под линукс, а на сколько я знаю, стандартные шаблоны проектов идут с Dockerfile файлами для сборки вашего проэкта в образ докера, что позволяет очнь просто деплоить и запускать такой проект.
Вобщем мое мнение, эти скриптовые языки раскрутились не благодаря динамической типизации, а благодаря простоте и низкому порогу входа и вопреки динамической типизации. Они просто заняли нишу.
Опять же человеческая сущность такова, что если все вокрут тебя фигачат на PHP, python, js, а ты новичек и хочешь влиться в мир web разработки, то наверно следует на них посомтреть, а эти люди вокруг, подскажут в случае чего.
Если отойти чуть в торону от конкретных языков. И рассмотреть только динамика vs статика, то почему аннотация типов должна сильно усложнить разработку.
fn summ(a,b)
{
return a+b
}или
fn summ(a:int,b:int) -> int
{
return a+b
}щас конечно набегут люди, котоыре скажут, «да ты же только целые складываешь», ну так в стат языках это решается при помощи дженерикови интерфейсов.
Вобщем мое мнение, эти скриптовые языки раскрутились не благодаря динамической типизации, а благодаря простоте и низкому порогу входа и вопреки динамической типизации.Нет. Они раскрутились как раз благодаря динамической типизации. Потому что 15-20 лет назад никто даже не пытался решать задачу «как сделать веб-сайт, который будет тяжело взломать и увести данные кредиток». Никто об этом даже не думал. Когда Web-только начинался — народ активно пользовался генераторами номеров кредитных карт, чтобы разные вещи покупать! Потому что Web-сайты даже не проверали валидность карт, только чексуммы считали!
И вот в этом мире, когда вам неважно, насколько правильно работает ваш веб-сайт, когда его кто-то атакует, но важно, чтобы он ну вот хоть как-то, в принципе, работал бы — притом, что создаёт его человек, вообще не имеющий представление о том, что такое программирование… динамические языки имеют преимущество.
Ну а потом, когда у вас Web-сайт уже есть… вы ж не будете его выкидывать и переписывать с нуля на другом языке! Смешно же!
Звучит так, как будто статическая типизация защищает от логических ошибок.Звучит так, будто кто-то не умеет думать.
Подождите, если кто-то не проверил валидность карты — это точно проблема динамической типизации, а не кодера?Если кто-то даже не пытается проверять валидность карты и принимает любой мусор без проверок — то на другие типы ошибок, весьма вероятные, при использовании языков с динамической типизацией — ему тем более наплевать. Ему инвесторов нужно убедить бабла дать, а не ошибки править… и с borrow checker'ом бороться.
Звучит так, будто кто-то не умеет думать.
Звучит так, будто кого-то не научили хорошим манерам при общении.
Если кто-то даже не пытается проверять валидность карты и принимает любой мусор без проверок — то на другие типы ошибок, весьма вероятные, при использовании языков с динамической типизацией — ему тем более наплевать.
А если бы этот «кто-то» писал бы на условной Java — то сразу же догадался бы проверять валидность карты? Оукей, видимо дальнейший диалог смысла не имеет.
То есть грубо говоря вы можете заставить их написать эту самую функцию для валидации. Правда «качество» этой функции всё ещё остаётся под вопросом и чтобы его проверять уже нужны какие-то код ревью.
У меня было 2 функции. дебит и кредит. первая требовала список и положительных чисел, вторая из отрицательных. Но я ошибся в обоих типах и по совпадению ошибка произошла в входных данных.
В итоге у клиента должен был быть расход в 100р и доход 100000р, а из-за двойной ошибки вышел не доход, а вышли к нему кредиторы за задолжностью. Как тут спасли типы от логической ошибки.
Я даже больше скажу, можно даже в типах не ошибаться, пусть у нас везде положительные числа, просто в функцию дебит передали массив с расходами а в кредит массив с доходами(да, у нас другая бухгалтерия в этот раз везде положительные величины).
11 футболистов заработали 11млн рублей, значит каждый из них заработал в среднем по 11*11, а не 11/11. Типами описывающими логику принципиально невозможно защититься от логической ошибки. потому что логическая она не с точки зрения математики а с точки зрения человека. От логических ошибок принципиально невозможно защититься ничем.
ошибка типов — я описал функцию как фунцию 2х int, но передаю туда 2 str.
логическая ошибка — я описал функцию как функцию 2х int, и передают туда 2 int, но хотел складывать, а из-за ошибки вычитаю.
Мне нравится стат типизация и все такое, но это какой-то фанатизм — верить, что в реализации функции ошибиться можно, а вот в описании типа нельзя и потому они все проверят.
Это не фанатизм, а cоответствие Карри — Ховарда. Тип может быть доказательством соответствия программы спецификациям. Правда, системы типов в большинстве языков слишком слабые для этого.
Поэтому еще аккуратнее сказать, что для повышения надежности требуются все доступные средства с учетом их стоимости, эффективности и накладываемых ограничений для конкретного проекта.
Никакой серебряной пули, увы, не существует.
- Типы могут заменить часть тестов.
- В некоторых случаях автоматическое доказательство может заменить ещё некоторую часть тестов.
- Ошибки в тестах возможны ровно в такой же степени, в какой они возможны в типах.
Какой из этих тезисов не соответствует Вашим знаниям?
Но, это не проясняет сути, какое из течений, ортодоксально: господствующая религия или секта.
Для этого потребовался, скажем там, «другой способ познания мира».
И становится немного иногда страшно из-за того, что «секты» и «годсподствующие религии» пытаются в XXI веке взять реванш.
Потому что ведь у них может и получиться — а это просто будет концов всей техногенной цивилизации.
Ибо она ни на «господствующие религии», ни на «секты» не может опираться — проверено…
Я ремарку сделал для того, чтобы показать, что обзывать кого-то в технической дискуссии, «сектантом», это, как-бы самого себя выставлять, как представителя «религии». А в таких технических дискуссиях, «религиозное мышление», считается неверным. В каком-то смысле, это и понятно. Ведь, предмет познания религии совсем другой, нежели типизация языков программирования.
ну это кто как умеет писать.Ух ты, какая у нас необычайная гибкость появилась. А как же ваши стадия «испытывать» есть у всех приносящих пользу программ абсолютно?
Не связано ли ваше неумение (в котором вы, извините, сами признались) с вашей любовью к динамическим языкам?
Потому как у меня — вполне были такие программы, которые «испытывать» — бессмысленно. А у вас, внезапно, не было.
Мне вот интересно: вы вообще, в принципе, программы, связанные хоть каким-то боком, с безопасностью, писали? Их — вы тоже «испытываете»?
например спокойно релиз можем выкатить в прод 31-го декабря и спокойно праздновать Н.Г не переживая что пользователи которые весь Н.Г нашим сервисом активно пользуются нос где-то о креш разобьютАга. После испытаний-то вместо доказательства правильности.
Типизация вообще не про поиск ошибок. Она про описание того, чем вы оперируете в ваших программах. Отказываясь от статической типизации вы открываете для себе новые виды ошибок, для обнаружения которых вам нужно писать дополнительные тесты. Только и всего.
Перекладка проверки на компилятор даёт сокращение цикла разработки. Чем сложнее писать и запускать тесты — тем больше это сокращение.
Где-то была максима «цена ошибки: 1$ у автора, 10$ на автотестах, 100$ на ручных тестах у QA, 1000$ у пользователя». Даже если цифры чуть другие — у меня вот на текущем проекте, мне кажется, это 2-3 раза — за это стоит побороться.
Каким образом?
Вы серьезно? На таких же серьезных щах можно утверждать, что тесты писать лениво — они же не нужны и удлиняют цикл разработки.
от того что мы написали sum(a: int, b: int) питон не выделил меньше памяти. не стал быстрее работать итп.
Это не тесты. Вы съехали с темы
для Perl например у меня был perl critic, который находил больше проблем в коде чем pylint, mypy, flake8 вместе взятые. И язык рантайм работал в разы быстрее.
Ну, выкиньте вы труп перла наконец-то. И раз уж так, то Вы опять съехали с темы. Одно дело тесты, другое — DAST, SAST, Linter’ы и все прочее. Да, я не отрицаю — ОНИ ТОЖЕ ПОМОГАЮТ ловить ошибки в коде. Но… тесты не нужны, по-Вашему?
типов которые заявляют "типы наше всё, поэтому тесты не нужны".
нет. Эти «типы» только лишь утверждают, что правильная система типов улучшает качество кода и снижает необходимость в тестах, т.к. часть тестов можно попросту не писать. В случае условного python, Вам в тестах необходимо учитывать каким-то образом ТО ЧТО прилетает, либо покрывать код ассертами. Оба аспекта — удлинение цикла разработки по Вашим словам. А если бы сразу писали типы на нормальном языке — этого «удлинения» не происходило.
если Вы почитаете мои коменты, то я постоянно спорю с адептами типов которые заявляют «типы наше всё, поэтому тесты не нужны».
Не скажу за «постоянно», но конкретно в этой ветке вы спорите вообще не с этим — такого утверждения здесь просто не было. Вы же пытаетесь спорить с тем, что типы позволяют рано поймать большое количество ошибок, причём иногда таких ошибок, которые тесты спокойно пропустить могут.
от того что мы написали sum(a: int, b: int) питон не выделил меньше памяти. не стал быстрее работать итп.
либо просто ложные:
<если указывать в коде типы, то>
надо писать много [ненужных] заклинаний.
Алгоритм под ритуалами тонет, читабельность страдает.
Следовательно больше ошибок — длиннее цикл разработки (пока их все разгребёшь)
А нам нужен fillpackart?
у меня утверждения не менее обоснованные чем у оппонентов.
Смешно это читать, когда сразу на строку ниже:
кроме того — я имею опыт работы с обоими парадигмами, а мои оппоненты, увы — не имеют
снова ложное утверждение.
кроме того — я имею опыт работы с обоими парадигмами, а мои оппоненты, увы — не имеют
Очередное необоснованное мнение. Как минимум khim & 0xd34df00d
прекрасно разбираются в Си/C++. А следовательно — должны мочь в обе парадигмы.
и им это помогает стоять в позиции "динамическая типизация — чепуха паршивая?"
Философский вопрос — обязательно ли понимать, что нечто дрянь полная, или обязательно нужно собрать грабли на своем опыте? Или собственный опыт в смежной области и опыт хождения по граблям других людей недостаточен?
Наблюдениями за собой, когда я не мог поддерживать написанный мной же код больше 50 строк.У меня было веселее. Был у меня скриптик на пару тысяч строк на
bash. Со всякими приколами типа рекурсии (вы знаете, что bash поддерживает рукурсию? ну… теперь знаете, я полагаю). Я его мог вполне поддерживать (не уверен что сейчас смогу… но пять лет пока он был нужен — он работал без сбоев).Но надо было видеть ужас который охватывал вот тех самых «системных администраторов», когда им нужно было исправить, они его открывали и пытались понять… А ведь никаких особо сложных алгоритмов там не было. Самое сложное, вроде как — топологическая сортировка.
Я вижу (с высоты птичьего полета) серьезную проблему любой такой дискуссии вот в чем. Есть разные задачи. Для них существуют разные инструменты. Шуруп в стене в среднем держится крепче, но забор собирают на гвоздях.
В любом месте, где собираются тори и виги, сразу возникает отчуждение по классу задач. С левой стороны громадного, заполненного кипящим дегтем, рва — орут: «Инверсия списка!», с другой: «Пользовательский ввод!».
Как только я слышу «строгая типизация лучше в вакууме», мне хочется ушатать кричащего динамической пращой. Потому что Голиаф со всеми своими доказательствами — прекрасен, спору нет. Но история (хоть и не из книги банды четырех — вы, кстати, никогда не задумывались, что Евангелие — по сути — тоже книга банды четырех? — я тоже нет; простите, отвлекся) — намекает нам, что иногда и ущербненький Давид может победить.
Я часто упоминаю fault-tolerance в такого рода дискуссиях. Бывает так, что алгоритмически задача не из самых сложных, но на любом этапе что-то может пойти не так. По независящим от нас причинам (память сбойнула, крысы сетевой кабель сгрызли, поставщик данных вдруг прислал бинарный мусор вместо курса валюты). Код, который без костылей элегантно отработает все такие сценарии проще всего написать на платформе, которая была разработана с учетом всего этого враждебного мира.
С типами ли, без — вопрос тридцать пятый.
Сначала надо типизировать саму задачу. И выяснится, что для некоторых строгая типизация языка принесет ощутимую пользу. Для других — мало что изменит. Третьим — навредит.
В прошлом году нам потребовалось написать парсер/валидатор XML/XSD. Там счетное количество XSD, постоянно пополняемое, по которым нужно валидировать XML, потом его элегантно менять, снова валидировать и пересылать дальше. Насколько мне известно, полная реализация спецификации XSD, проходящая тесты консорциума, до этого существовала только на джаве, и апачи ее писали командой чуть ли не полгода. Я написал свою за месяц. Там триста строк кода. Мы ее скоро откроем в OSS.
Реализация такая: по XSD генерируются структуры, по сути — типы, которые отвечают за все в пределах своей видимости. Для Pain001 формата — это 1900 разных структур. Гарантирующих, что если в рантайме туда пытаются положить значение — оно правильно приведется к ожидаемому по XSD спецификации типу, или мы накопим человекочитаемую ошибку, проигнорируем эту ветку и пойдем дальше.
Скоро мне потребуется поделиться реализацией с RnD, которые понемногу уходят с R на Julia (питон мы никогда даже не рассматривали). Авторы Julia сумели сделать AST как надо — поэтому я просто транслирую AST эликсира в джулевский, и оно заведется из коробки. Буквально, прочли файлик — получили многоуровневую структуру с правильными типами внутри. 1900, повторю, разных вариантов.
В общем, типы хороши. Иногда. А иногда — нет. Человеческий доступ к AST иногда гораздо важнее. А иногда — нет. И пока мы не договорились, какой тип задач мы обсуждаем — любые утверждения о том, что хорошо, а что плохо — чушь.
Мы ее скоро откроем в OSS.Ну вот когда (и если) её начнут использовать — тогда и будет видно, насколько ваши триста строк кому-то полезны. И насколько полны тесты — тоже.
Потому что весь этот пафос про «платформу, которая была разработана с учетом всего этого враждебного мира» — хорош, когда вы работает с одним-единственным XSD, который вот вам лично нужно обработать. Если вам потребуется обрабатывать тысячи этих самых XSD — вот тогда вы и узнаете, почему этот парсер Apache писали месяц.
Хотя скорее всего не узнаете: тот факт, что всего один XSD парсер прошёл тесты говорит, скорее, не о том, что эти тесты так уж сложно пройти, а о том что это — никому особо и не нужно.
И если вам парсер никто так и не попытается использовать… то вы так и будете оставаться в святой уверенности, что решили ужисть какую сложную, почти неразрешимую, задачу.
Авторы Julia сумели сделать AST как надо — поэтому я просто транслирую AST эликсира в джулевский, и оно заведется из коробки.Знаете, вы, как бы, превзошли даже rsync (хотя я считал, что это невозможно). Он, хотя бы, реализовал свой любимый «документооборот» (ну, по крайней мере, так он утверждает… и вот в этом месте я ему верю).
Вы же рассказываете про преимущества динамической типизации на примере, которого у вас ешё даже нет (хотя вы верите, что он будет)…
Уж извините — но это, как бы, немного за гранью.
Вот реализуете, появятся у вас пользователями, пройдёт ваша система «проверку боем» — можно будет о чём-то говорить.
весь этот пафос про «платформу, которая была разработана с учетом всего этого враждебного мира» — хорош, когда вы работает с одним-единственным XSD
Это я про OTP.
Вы же рассказываете про преимущества динамической типизации
Ткните-ка пальчиком, а, где это я рассказывал про преимущества динамической типизации?
Уж извините
Нормально. Я на неумных людей не обижаюсь.
можно будет о чём-то говорить
А с чего вы решили, что у меня есть желание с вами говорить? Или что мне хоть как-то интересно ваше мнение?
Дональд Кнут никогда не заморачивался созданием надежного, качественного, изменяемого ПО.
А в своих книгах, когда вопрос практической реализуемости не стоял, он реализует свои алгоритмы вообще на ассемблере, так как это единственный способ to indicate how machines actually compute.
Не знаю, что я делаю не так, но списки с элементами разных типов мне не приходилось сортировать ни разу.
На одной прошлой работе тоже по XSD генерировалисьструктурытипы (template haskell вполне неплох) для сетевого взаимодейтсвия, и потом всё отлично тайпчекалось.
Спецификация XML, описываемая XSD, определяет, помимо прочего, сортированные списки с элементами разных типов. sequence называется. Я так понимаю, за вас их тот второй чувак сортировал, да? Вы только стратегией занимались?
Нет, спору нет, на C/C++ — это вообще ад. Ну так вы бы еще с ассемблером сравнивали по легкости сопровождения.
Слышал, да. Я почитываю разную беллетристику.
Не очень понимаю, правда, как тип-сумма поможет в ситуации, когда нужно валидировать группу типа sequence, в которой может быть (0..∞) элементов типа choice (строка вот с таким регэкспом для валидации, или целое в диапазоне 0..3), за которыми следует два или три элемента типа строка с необязательным атрибутом foo, типа enum (и так далее).
Но я допускаю, что конкретно с этим примером мне просто не хватает бэкграунда, чтобы описать это правильными типами.
struct MyEnum
foo::Union{Nothing, ...}
end
Vector{<:Union{String, Int, MyEnum}} # это тип вашей последовательности
если правильно распарсил (про foo не факт что понял как задумывалось).
Или, с учётом того что потом-то явно разные элементы по-разному будут использоваться, сразу разбирать в такую структуру:
struct Data
strs_1::Vector{String}
ints_1::Vector{Int}
strs_2::Vector{String}
foo_enum::MyEnum
end
Union не годится из-за потери очередности, Vector не годится из-за арности элемента, валидации просто забыты, и все это про простейший пример с всего двумя элементами для одного из почти двух тысяч типов.
Угадайте, убедительно ли в контексте всего этого прозвучало «Я уверен, что это можно и полностью записать в типах».
Возможно, вы пропустили этот кусок почти в самом начале:
но это ведь необязательно. Даже если часть ограничений типизирована, это уже существенно помогает в написании/тестировании/рефакторинге.
Вы исходите из естественной посылки, которая является, тем не менее, неверной: вы считаете, что спецификация XSD описывает нечто, что является внутренне непротиворечивым и, соответственно, реализуемым. И тогда, разумеется, можно вот это описать в типах. Сложно ли, просто ли — другой вопрос.
На самом деле спецификация XSD описывает «невоможный объект», чушь. Нечто, что в принципе невозможно реализовать. А поскольку все типы описывают нечто непротиворечивое — то и описать её в типах вы не сможете. Никак.
Что можно сделать — так это разработать, для себя, некоторую другую спецификацию, которая будет похожа на оффициальную… и реализовать уже именно её.
А дальше возникает вилка: мы уже, извиняюсь за выражение, «похерили спицификацию» — нафига нам пытаться корёжить вот то, что мы придумали. чтобы пройти эти дурацкие тесты, которые столько же кривы, как и спицификация — и ешё и противоречат ей?
Обычно после этого на тесты «забивают» и получают парсер, которым и пользуются.
Но люди, не умеющие в логику, но знающие что маркетологам будет небесполезна галочка на продукте «а мы проходим и все XSD тесты» эти сомнения немыслимы: они успешно реализуют нечто, что может вообще очень слабо сочетаться со спецификацией, работать криво и неправильно… но зато оно пройдёт все тесты!
Сколько я историй услышал общаясь с людьми, заведующими вот этом вот небольшим набором тестов… ни в сказке сказать, ни пером описать…
Fin в известной статье. Даже в C++ делается. Было бы желание. Другое дело, что практически этим может оказаться неудобно пользоваться… но это уже второй вопрос.Но эту кодировку делаете вы как программист, и компилятор её вообще никак не проверяетПроверяет-проверяет. Там же пример был.
ничему не мешает вообще, и компилятор это не поймает и ловить не будет.Дык через
memcpy вы тоже можете сделать всё, что угодно и «сломать об колено» в C++ любую типизацию. А уже через asm-вставку можно словать вообще всё и везде.Тем не менее, если вы просто заведёте себе
template<std::size_t... parameters> class FancyClass; с некоторым количеством специализаций и скажите, что всё вообще в программе делается через него, однако при этом новые специалиации заводить запрещено — вы сможете поверх этого сделать любую типизацию. Да, Вы, фактически, тем самым создаёте другой язык поверх C++ — и сами можете решать каким он будет. Да, это «закат солнца вручную», да, это «читерство»… но это «читарство» в том же смысле в каком перевод десятков вариантов машин Тьюринга друг в друга.И факт равенства терма другому терму на уровне типов у вас выразить не получится никак.Получится-получится. Было бы желание. Типы в C++ представляют собой полный по Тьюрингу язык, так что всё делается. Если речь идёт о теории. Можно ли этим будет пользоваться на практике — другой вопрос, как я уже сказал.
Обратите внимание, что даже по вашей ссылке в lookupS матчатся не на список как обычно, а на его синглтонное отображение.Если вы устраиваете «закат солнца вручную», то это логично: пыпытка «соединиться в экстазе» с уже существующими типами к добру не приведёт.
Разумеется в реальном мире с ними придётся взаимодействовать как-то и да, в этой точке проверок, невозможных в исходной системе типов, не будет. Но вы всегда можете от исходной системы взять только
True и False — для теоретического доказательства возможности этого достаточно.Практически же это будет значить, конечно, что вы не сможете использовать никакой существующий код, так что этот подход, мягко говоря, не слишком практичен.
Ну ок, что написать вместо знаков вопроса здесьВы там ничего не можете написать, так как вы нарушили основное правило: всё вообще в программе делается через
void foo(int x, int y, ????)
чтобы компилятор знал, что x и y равны?
FancyClass.А если предположить, что у вас
FancyClass<0, 0> — это «новый void», а FancyClass<1, ...> — ограниченный int — то вышеупомянутая функция у вас будет описываться какtemplate<
std::size_t... constraints_x,
std::size_t... constraints_y>
auto foo(
FancyClass<constraints_x...> x,
FancyClass<constraints_y...> y>
) -> std::enable_if_v<
IntClass<FancyClass<constraints_x...>> &&
IntClass<FancyClass<constraints_y...>> &&
EqualValue<
FancyClass<constraints_x...>,
FancyClass<constraints_y...>
>,
FancyClass<0, 0>>;
EqualValue «сгрузит» описания типов в какую-нибудь уже обычную constexpr функцию), на C++98 это было бы вообще убойно… но принципиально ничего не меняет.Тьюринг-полнота системы типов здесь не столь важна.Если у вас она не будет полна по Тьюрингу вы на ней прувер не сделаете, а тогда и завтипов не получится.
Если вы не можете параметризовать тип термом, то никакое количество кодогенерации каким угодно темплейт хаскелем вам это в общем случае не заменит.Ну здравствуйте, пожалуйста. С какого перепугу? Если все ваши
FancyClassы неизменяемы, то FancyClass<constraints_x...> и x имеют взаимно-однозначное соотвествие. И то, что в вычислениях на типах участвует FancyClass<constraints_x...>, а в вычислениях внутри функции — просто x ничего не меняет.Да, конечно, вы можете принять в функцию
x и y, а вычисленях на типах передать что-то другое… ну так это уже логическая ошибка, от неё ничего не спасёт. Можно некоторое количество макросов добавить в эту гремучую смесь, чтобы совсем хорошо стало…Ну подумайте сами, логически: ведь в языке с завтипами магии-то нету. В сгенерированном, в конечном итоге, коде, никаких завтипов нет, там только байты и биты.
Что мешает вам сделать точно такой же компилятор самому, а вместо байтов и битов — взять простейшие элементы из «базового» языка?
Ничего, кроме здравого смысла, по большому счёту: представить себе сколько времени эта вот вся конструкция будет компилироваться — просто страшно. Ещё на 2-3 порядке медленее, чем компилятор Idris. Но работать — будет.
Я его не пропустил, а проигнорировал. Потому что моя основная претензия к хайпу «строгая типизиция — несомненное добро» заключается именно в том, что настоящая строгая типизация, которая диффеоморфна математике (доказательна) — в реальном мире на поверку оказывается невозможна. А чистичная, по принципу «вот тут типизируем, а тут ансейф» — не только полностью ломает тезис о доказательности, но и начинает вставлять палки в колеса в самых неожиданных местах.
Вернемся к вашему примеру.
struct Data
strs_1::Vector{String}
ints_1::Vector{Int}
endКогда вы займетесь маршаллингом этого, вам придется написать специальный условный оператор, который удостоверится, что если strs_1 пуст, то он не попадает в вывод. Подход в лоб выдаст <strs_1/> вместо ничего, что семантически некорректно. И это — плата за типы, которые, в принципе, не дали вообще никакой выгоды.
А потом (мы все еще про XML) — на повестке для возникнет XPath, с его nth-child. Да и просто банальный интерфейс, который хочет видеть консюмер этого кода — append!( data, 42 ).
Мой тон обусловлен тем, что задача эта — нетривиальная (но проще, чем управление самолетом, не спорю) — и когда я вижу советы «вот же как можно!» от людей, которые явно даже не пытались понять предметную область, мне в среднем лень расписывать аргументы на пять страниц.
Я его не пропустил, а проигнорировал.
Хорошо хоть вы прямо признались, что игнорируете собеседника.
И это — плата за типы, которые, в принципе, не дали вообще никакой выгоды.
Без типов: никаких гарантий, что находится в данных. С такими, абсолютно простейшими типами: гарантии, что вот тут у вас строки, тут числа, тут структуры.
На всякий случай напоминаю: мы в ветке с предложенным мне кодом на Julia.
Подход в лоб в нетипизированном языке для начала уберет эту кашу из векторов:
abstract type Any end
struct Data
values::Vector{Any}
endИ тут все, что есть — должно быть сериализовано. А что пусто — того просто нет в исходном векторе. Проблемы валидации, разумеется, остаются, но вот эта конкретная проверка на пустоту — больше не нужна.
Подход в лоб в нетипизированном языке для начала уберет эту кашу из векторов:
Как вы себе представляете использование данных из этой структуры? В любом случае вам когда-то придётся проверять, какие элементы находятся в этом векторе и где. Так почему бы это не сделать один раз сразу после парсинга, и дальше везде передавать структуру с типизированными элементами?
Но я допускаю, что конкретно с этим примером мне просто не хватает бэкграунда, чтобы описать это правильными типами.Вы это и словами-то мне можете пока описать — но при этом утверждаете, что реализовали в программе.
Я, как и никто здесь, не видел вашей реализации, но на 99% уверен, что вы нифига не реализовали «парсер соотвествеющий спецификации». Нет, то, что вы реализовали это «парсер, проходящий все тесты». Это другое — и гораздо более простое.
Более того, по косвенным признакам (огромному количеству парсеров XSD и практически полному отсуствию «сертифицированных») можно заключить, что эту спецификацию вообще невозможно реализовать. В принциципе. Никак.
И единственная, как вы утверждаете, «сертифицированная реализация» (кто, кстати, её сертифицировал и когда) тоже реализиует не всё спецификации во всех случаях, а нечто, похожее на них, но настолько запутанное, что люди, которые за сертификацию отвечают не смогли понять где ошибка.
Когда и если вы вашу «герниальную» разработку откроете возможны несколько вариантов:
1. «Чеширский кот» — вы никакого формального сертификата не получите (потому как никому не интересно), но сможете заявлять, что «всё соотвествует, просто сертификат получать лень, хотите проверить — вот оно лежит, посмотрите». Наиболее верояный вариант и отлично сочетающийся с в современном мире продать — очень часто важнее чем сделать. То, что вы продаёте вещь, которой у вас нет — никого не волнует, а покупателю будет легко убедить своё начальство в том, что то, она таки есть и заплатить вам за неё деньги.
2. «Бег в колесе» — вы будете говорить, что вы всё сделали правильно, вам будут указывать на то, что какой-нибудь частный случай отрабатывается неверно, вы будете говорить, что в тестах такого нету, тесты будут меняться, вы будете менять реализацию и так далее. Ни о каком «я написал свою хрень за месяц и получил сертификат» речь идти не будет. Хорошо если за год соответствуюещий комитет устанет менять тесты и даст-таки вам сертификат, чтобы вы отвязались.
3. «Каждый считает, что он прав» — вам будут говорить, что спецификацию вы нарушили, вы будете отвечать, что тесты-то проходят… и обе стороны будут верить, что они правы.
4. «Вот вам, бумажка, отвяжитесь» — тут, конечно, многое зависит от того, какую бумажку вы хотите получить и от кого — очень может быть, что того факта, что тесты прошли окажется достаточно.
Собственно почему я и написал то, что написал: нормальному человеку, умеющему в логику, писать XSD, проходящий тесты, но очевидно не соотвествующий спецификации — противно. Человеку же, не умеющему в логику (а именно такие, чаще всего — фанаты языков с динамичекой типизацией) зачастую просто непонятно, в чём разница. Так как у них в голове каша и они считают что любая фраза в спецификации — устроена так же. И может тоже значить что угодно. А потому если тесты проходят, то смотреть в то, что написано в спецификации просто не нужно.
P.S. Вы никогда не задумывались почему индустрия, в общем и целом, отошла от XML и перешла, во многих местах, к использованию JSON? Вот именно потому, что «Valid XML» (с XSD) — это хтонический монстр. Имеющий массу странных, непонятных, и, главное, никому не нужных краевых случаев, где люди никак не могут договорится о том, что нужно делать. Результат работы бюрократов, которые порождают бумажки, а не код. К счастью, на практике, можно этим обойтись тем подмножеством, где противоречий не возникает — и только его большинство XSD парсеров и поддерживают. А то, что они не проходят все тесты — так это сознательное (и как по мне, лучшее решение): если спецификация говорит одно, тесты говорят другое и мы с таким странным вариантом в жизни не встречаемся — то и чёрт с ними, с тестами. Это — по крайней мере честно.
P.P.S. Вообще такое ощущение, что вы живёте в мире, который не потрясают регулярно скандалы, связанные с тем, что люди сознательно и постоянно «мухлюют с тестами». Вплоть до скандалов и отзыва лицензий. Рассказывать в этом мире что вы что-то реализовали и «оно проходит тесты», гордиться этим… ну то такое.
Рассказывать в этом мире что вы что-то реализовали и «оно проходит тесты», гордиться этим… ну то такое.
Это как с HackerRank и олимпиадами. Тесты прошли, по памяти и времени выполнения уложились — мы молодцы, написали корректный код. А то, что в тестах что-то не учли — это же не наши проблемы, правда?
data Then = TwoStrs ThenStr ThenStr
| TreeStrs ThenStr ThenStr ThenStrА если их не «два, или три», а не менее пяти и не более ста? Я понимаю, что это все нагенерится по шаблонам, но код-то можно будет посмотреть, понять, а главное — сгенерировать и документацию тоже?
Упарываться, конечно, проще на идрисе
Я даже немного поупарывался, на тривиальном примере, и это было очень круто. У меня что-то даже получилось. И именно первый подход к решению на идрисе просто неэпически помог мне сравнительно быстро написать то, что пошло в продакшн на эликсире.
Но есть нюанс. Я верю, в принципе, в возможность прокачать свой идрис до такого уровня, что время создания подобного приложения будет сопоставимо. Что дальше? (Допустим, у нас есть машина времени и 2.0 уже тут, продакшн-реди.) Что консьюмер получит в ответ при попытке скормить этому коду XML, у которого на шестом уровне вложенности валидация не прошла? А? Я просто не понимаю, как оттуда вернуть человекочитаемую ошибку «в поле //foo/bar/baz/baf/ban/bab ожидается дата в будущем», или это в принципе очень нелегко (сам тип bab по XSD может быть в пяти разных местах, по разным xpath)?
Часто ли вам, кстати, приходится работать с такими схемами?
Ну конкретно со схемами мне больше не приходится: когда новый тип документа добавляется, коллеги просто прогоняют генератор и пользуются получившимся кодом для своих гуёвых нужд.
Но это же просто одна из многих задач, которая просто первой пришла на ум.
Разве что сельский, который будут ломать на каждой пьянке и восстанавливать с похмелья.
Уже забор из профнастила или, в российских терминах, типовой «Махаон» таки обычно уже на шурупах или болтах с гайками. (Первая ссылка из гугла с фото, с производителем не связан.)
Что характерно (tm).
> Код, который без костылей элегантно отработает все такие сценарии проще всего написать на платформе, которая была разработана с учетом всего этого враждебного мира.
Именно это и есть аргумент за типизацию — если придёт нечитаемый мусор хотя бы случайно, то можно будет это опознать, а не пытаться парсить в условный ноль всё, что не так.
А вот как дальше на это реагировать — уже вопрос политики. Я работал с одним коллегой, у которого за плечами 10+ лет работы кадровым офицером (админ и всё такое). Так вот — подходы к решению задачи: надо прочитать из конфига диапазон значений — от и до. Моя реализация: читаю как два целых числа с проверкой корректности (всякие лишние символы кроме цифр и пробелов => ошибка), если min>max — посылаю в сад. Его реализация: то же чтение с теми же условиями корректности, но если min>max — он их меняет местами. Я тогда получил реальный инсайт.
Именно это и есть аргумент за типизацию — если придёт нечитаемый мусор хотя бы случайно, то можно будет это опознать, а не пытаться парсить в условный ноль всё, что не так.
Слушайте, ну это уже правда про «у рыбы шерсти нет, но если бы была — в ней бы жили блохи». Вы всерьез считаете, что я не отличу мусор от не мусора на любом языке по вашему выбору, хоть в машинных кодах? В коболе вообще все байтами хранится, но люди справлялись писать громадные системы, и — внезапно — самой страшной проблемой оказалось не отсутствие типизации, а ее наличие. Y2K — это неверно выбранный тип, прибитый гвоздями. Ладно, я утрирую немного, но в этой шутке есть доля правды.
Говоря о платформах, я имел в виду OTP, конечно. Она вся спроектирована так, что в каждом конкретном месте готова к тому, что процесс рухнет в середине выполнения из-за ошибки доступа к памяти, или из-за плохого ввода. Тут поля слишком узкие, чтобы подробно рассказывать, сколько часов спокойного сна мне это сэкономило, но уж то, что в десятки раз больше любых супер-типов — это вне всяких сомнений. А код, который я пишу, оперирует денеждыми средствами живых людей: транзакция с лишним нулем — и мы — банкрот.
Его реализация: то же чтение с теми же условиями корректности, но если min>max — он их меняет местами. Я тогда получил реальный инсайт.
Вот за то, что поделились — нечеловеческого размера спасибище! Я чуть со стула не свалился :)
Тут поля слишком узкие, чтобы подробно рассказывать, сколько часов спокойного сна мне это сэкономило, но уж то, что в десятки раз больше любых супер-типов — это вне всяких сомнений.Ну эта-то фича от типов не зависит. Google тоже активно этот подход применяет, хотя и на языках с типизацией.
А код, который я пишу, оперирует денеждыми средствами живых людей: транзакция с лишним нулем — и мы — банкрот.Странно тогда, что вы вообще упёрлись в типизацию или отсуствие оной. Я общался с людьми, которые Google Wallet разрабывают, на одной из конференций, так вот они чётко сказали, что главное там — не написать правильный код (тут как раз типы помогают, но не шибко принципиальны), но проследить за тем, чтобы все бессмысленные ритуалы, которые предписывают разного рода регулирующие органы, были соблюдены.
Если ваша торговалка упала [...]
Не побрезгуйте, загляните в мою последнюю заметку. Чтобы моя торговалка упала, нужно, чтобы рухнули все ноды в кластере, который умеет в шардинг на уровне кода.
Если вкратце, там hashring, который выбирает ноду, и когда нода падает, оно перестраивается на лету.
И моего кода там — только тонкий слой сверху, чтобы совсем джун мог пользоваться. Все остальное — OTP.
Я не очень представляю, как эффективно с такими вещами работать даже в зависимо типизированном языке. Ну, то есть, да. констрейнт вы выразили, а дальше-то что?
А я уже отвечал на этот вопрос. Дальше я взял динамически-типизированный язык, выразить констрейнты в котором мне помогли мои игрища с идрисом :)
Консьюмер получит доказательство того, что XSD не прошёл проверку. То есть, например, (date ** (PathTo date ..., date > parsingDate)).Вы с таким придыханием произносите слово «доказательство», что через океан слышно. Пользователю-то я что отвечу? Ну вот закачала чужая враждебная тупая CRM нам невалидную эксемельку. Нам хорошо бы не Error #12345. File corrupted. вернуть обратно, а что-то такое, по чему их CRM сможет, ну не знаю, что-то адекватное предпринять.
как вы будете совмещать эти кластеры с временами работы порядка сотен наносекунд от запроса до генерации ответа, я не очень понимаю, например
Это утверждение, а не вопрос. Если интересно, как у нас они совмещаются с накладными расходами в единицы наносекунд, так и скажите: «расскажите, пожалуйста, какие у вас на кластер накладные расходы, как вы их меряли, и как вы этого добились». Потому что «времена работы порядка сотен наносекунд» в вакууме — это ни о чем.
int foo(int x, int y, ????)Так, к слову, эликсир/эрланг с диалайзером так умеют.
@spec foo(integer(), integer()) :: any()
def foo(x, x)И диалайзер после компиляции скажет про любой вызов foo 42, 0, что нет ветки для foo, которая сумеет это обработать. А если это зависит от пользовательского ввода — то и строгая типизация не поможет.
А если это зависит от пользовательского ввода — то и строгая типизация не поможет.
Спасибо, добавлю ещё один кейс в будущую статью :)
А если это зависит от пользовательского ввода — то и строгая типизация не поможет.
Вообще-то поможет. На завтипах можно принимать аргументом доказательство того, что два числа одинаковы. В этом случае компилятор проверит, что проверка на равенство вообще есть, и, что немаловажно, позволит убедиться, что эта проверка производится только один раз, а не повторяется снова и снова. И работать это будет с любыми данными, в том числе и с пользовательским вводом.
Потому что «времена работы порядка сотен наносекунд» в вакууме — это ни о чем.Вообще-то это о классической байке «Чукче не надо бежать быстрее медведя, однако. Чукче надо бежать быстрее тебя.»
В биржевой торговле никакие наносекунды не являются достаточными. Потому что вам нужно среагировать не за секунду, не за миллисекунду, не за сколько-то там наносекунд… вам нужно среагировать быстрее соседа!
А ваша чудесная кластерная система, будет, в любом случае раза в два медленнее, чем система без кластеризации. То есть она, очевидно, «упустит» такой большой процент сделок (просто не успев на них вовремя отреагировать), что уже будет совершенно неважно — какая там у неё надёжность…
Я понимаю, что если вы будете говорить только о том, в чем хоть немного разбираетесь, вам придется всю дорогу молчать.
ваша чудесная кластерная система, будет, в любом случае раза в два медленнее, чем система без кластеризации.
О, «очевидно бинго». Юноша, про то, что она кластерная, имеет смысл говорить только в контексте аварии. До аварии ноды никак не общаются, уж не в рамках обработки одной сделки точно.
А после аварии мне даже бежать никуда не надо: сосед помер совсем, ему не то, что не до торговли, ему запускаться заново надо.
То есть, внешняя среда взаимодействует непосредственно с нодами, без посредника типа балансировщика? Тогда как эта самая внешняя среда узнаёт, какие ноды в данный момент живы и к кому, соответственно, обращаться?
Нет, не то есть.
В принципе, ну можно же попытаться понять, о чем идет речь, вместо того, чтобы просто цепляться к какому-нибудь знакомому слову, чтобы поспорить с незначительным тезисом.
Есть три фазы: установка соединения, нормальная работа, завершение или сбой.
Установка соединения процесс сколько-нибудь долгий, там наносекундами никогда не обойтись, хоть на триста раз строго типизированном ассемблере. В процессе нормальной работы есть канал общения (вебсокеты же работают мимо балансировщика, это вас не смущает?). А мы тут волею первого комментатора говорим о сбоях.
Сценариев два. Вне кластера нода упала из-за некорректного доступа к памяти, и работа окончена. В кластере hashring перестроился и задачи упавшей ноды оказались перераспределены по остальным. Там тоже есть нюансы, потому что придется переподключаться, да и небольшой кусок самых последних данных мог не доехать до eventlog’а, и так далее — но эти вопросы оказываются на практике часто (почти всегда) решаемыми, и именно про эту ситуацию я и говорил.
Вы всерьез считаете, что я не отличу мусор от не мусора на любом языке по вашему выбору, хоть в машинных кодах? В коболе вообще все байтами хранится, но люди справлялись писать громадные системы, и — внезапно — самой страшной проблемой оказалось не отсутствие типизации, а ее наличие.
Полностью согласен. Действительно, на любом языке можно реализовать распознавание между правильными и неправильными данными. Поэтому мне нравится ваше предложение использовать везде самый общий тип из возможных — последовательность байт. И каждый раз, когда требуется конкретный кусок данных, будем разбирать что там где среди этих байт. Ведь какие-нибудь модные «строки» и «числа», а тем более «классы» — это совершенно излишняя информация на уровне языка, и они не могут описать все свойства структуры данных.
Какие структуры? Давайте пользоваться ассемблером!
Впрочем… посмотрите хотя бы даже на КДПВ. Там ведь две альтернативы. Enterprise и Shit. И они не просто так там приведены. Собственно вся статья — построена вокруг этой картинки. И «главная чушь», которая отвергается — ведь тоже оттуда: «Баги, которые отлавливают типы, не стоят усилий, чтобы записать код этих типов».
А если вам не нужны ни типы, ни тесты, ни вообще какие-нибудь гарантии? Тогда программы с динамической типизаций вполне подходят. А если вы вообще делаете скипт для одного запуска — так вам вообще может быть пофигу что там с доказательствами и тестами.
Вот только… смотрю я на все эти наши
*_unittest.sh файлы… с юниттестами для скриптов на bash… и понимаю: опасное это дело. Слишком уж быстро и часто «разовый код» имеет привычку превращаться в что-то большее.А так-то да, до абсолюта ничего доводить не стоит…
кроме того — я имею опыт работы с обоими парадигмами, а мои оппоненты, увы — не имеютЧто значит «не имеют»? Я работал с Perl и моё желание (сейчас уже прошедшее) задушить его, если встречу — оно не на теоретическом опыте основано. А вот работали ли вы с Haskell или чем-то ещё или для вас типизация на C остановилась — я не знаю. Но подозреваю что нет.
так что как раз ваши оппоненты «работали с обоими парадинмами» и сложными системами (где, как бы, и встречаются сложные алгоритмы иногда), а ваш потолок — это пресловутый «документооборот».
я здесь обсуждаю много веток с многими людьми.Класс какой. Впервые вижу демагога, который бы сознался в том, что он демагог.
Я вам дам бесплатный совет: не надо так делать. Даже на улице где-нибудь, на митинге, если вы будете перебегать от одной кучки людей к другой и говорить им противоположные вещи (каждой группе свои), то они, рано или поздно, временно отложат свои разногласия, скооперируются и вас побьют.
Что примерно, тут и прозошло.
А также покрытия сильно большего количества случаев.
Например, у меня метод класса вызывается через ссылку, полученную по getattr — ну да, приходится местами костылить. Но я в функции пишу, что на входе str — и получаю предупреждение «не складывай его с числом, дурень».
Или у меня 20 классов, в которых receiveRequest() — и указанием, какой именно может сюда поступить, я позволяю ему пожаловаться «ты сигнатуру нарушаешь» или из этих 20 по поиску «Find usages» отобрать только нужные 4. Меньше шума => легче работать.
тестами можно выявлять все возможные виды проблем.
Это утверждение либо ложно полностью, либо ложно частично — в зависимости от того, что Вы подразумеваете под «видами проблем». Очевидно, что тесты не могут покрыть ВСЕ ВОЗМОЖНЫЕ кейсы. Тем более, если внутри кода у Вас есть условный рандом.
То если этот X потратить например на тесты
Я себе вижу это так, что если Х времени тратится на типы, и тратится Y времени на тесты, то просто на тесты Вы потратите X+Y времени КАК МИНИМУМ. А то и хуже. А раз так — тайпхинтинг — вещь полезная. Это подтверждается тем, что его как раз завезли в Python.
Ваше «мы уже разбирали» предполагает, что ваши аргументы обнаружены безусловно правильными. Но я не вижу пока причин такое принимать.
> На тайпхинтинг тратится усилий X.
При этом тайпхинтинг выявляет исключительно проблемы вида «вместо типа X пришёл Y».
Теперь я уже повторюсь — не только. Он выявляет: нарушения количества аргументов, их порядка, опечатки в названиях переменных и методов, некорректный оверлоадинг, и много прочего.
Но и сам по себе приход другого типа это уже хороший такой звоночек пересмотреть всё.
> То если этот X потратить например на тесты, то можно получить лучший результат: тестами можно выявлять все возможные виды проблем. Не только несоответствие типов.
У меня в копилке есть роскошный пример, как никакие разумные тесты не ловили то, что отловила проверка типов.
Это было, грубо говоря:
RTYPE string_length_in_ucp(const char *s) {
RTYPE length = 0;
while (*s) {
s += utf8_ucp_length(s);
length++;
}
return length;
}
и в результате криворукого подпила среды сборки RTYPE оказался int8_t, а в тестах не было ни одной строки длиннее 127 символов. Было 100500 тестов на разные извращения в наборе символов… но вот длинной строки — никто не догадался привести. Потому что все думали «там должно быть не менее чем unsigned int, не буду же я совать строку на 2 миллиарда символов?»
А компилятор сразу сказал «чувак, ты уверен, что надо пытаться впихивать size_t в int8_t?»
ниша где нужны компилируемые языки — очень узкая. Поэтому мне даже не особо интересно их обсуждать.
То-то компилируемый (sic!) GoLang (два раза чихнул) захватывает мир — на нем уже пишут и сетевые программы, и всякие тулинги. И всячески расширяют его применение. В качестве замены #петухону его многие уже применяют
Ну, посмотрите отчеты сами.
Начать можете с
https://blog.golang.org/survey2018-results
https://www.tiobe.com/tiobe-index/
https://www.jetbrains.com/lp/devecosystem-2019/
и кстати поэтому полезных приложений на языках со строгой типизацией и нет.
Чем дальше в лес тем толще троллинг :) Либо у вас с общепринятым различается определение строгой типизации, либо понимание полезных приложений.
ниша где нужны компилируемые языки — очень узкая. Поэтому мне даже не особо интересно их обсуждать.
Вы уже удалили у себя весь софт, написанный на C/C++/Java/C#/многие другие языки?
и кстати поэтому полезных приложений на языках со строгой типизацией и нет.Реквестирую рассказ про то, как вы тут пишите, на Хабре. Браузоров же не существует, по вашему утверждению!
Или вы их не учитывате, потому что они не занимаются документооборотом?
Вон даже вебсервер не смогли написать: простейшее приложение. Один смельчак писал-писал, а потом загнобили — плюнул и ушёл.Вот же ж блин, как же ж так, шо ж такое? А самые популярные NGINX или IIS?
Или вы, всерьёз, пытаетесь топить за определение статически типизированного языка как любого языка, который вам не нравится? И Python (в котором проверок типов, без дополнительных инструментов, нет) — статически типизированный и компилируемый, а C (в котором они есть) — динамически типизированный не компилируемый?
Это уже не демагогия, это уже болезнь. Мания величия. Вам к психиатору.
Нет. Они раскрутились как раз благодаря динамической типизации. Потому что 15-20 лет назад никто даже не пытался решать задачу «как сделать веб-сайт, который будет тяжело взломать и увести данные кредиток».
Эм, если бы многословная жава была динамической, со всей своей тяжестью и сложностью развертывания. а условный php или python статическими.
То правда кто-то выбрал бы жаву, вместо питона или пхп?
а не добавил в пайтон пару символов для аннотации
def (a:str):
print(a)И мысли о безопасности тут вообще никаким боком, просто совпало что языки с наименьшим порогом вхождения — динамически типизированные. На них и правда можно было стартовать проект быстрее 10-15 лет назад. Но не думаю что это преимущество осталось сейчас.
притом, что создаёт его человек, вообще не имеющий представление о том, что такое программирование… динамические языки имеют преимущество.
С первой частью я согласен, что эти языки как стартовая площадка для людей, которые только только начали программировать, но не в динамичности дело, добавить обязательную аннотацию типов в питон, и что изменится для новичка, да ничего.
На них и правда можно было стартовать проект быстрее 10-15 лет назад. Но не думаю что это преимущество осталось сейчас.
Осталось во многом, если говорить о бэке. Инфраструктура прежде всего. И как-то так получается, что компилируемые Java и C# требуют больше ресурсов для запуска приложения, чем интерпретируемые.
И как-то так получается, что компилируемые Java и C# требуют больше ресурсов для запуска приложения, чем интерпретируемые.
LOL. А теперь можно попросить это удалить? И подумать? При прочих равных -я гарантирую, что Java и C# будут эффективнее. Если речь не идет про башнянку-портянку на 10 строк или микросервис на фласке на питоне не под нагрузкой. Другой вопрос, что на огромных, циклопических масштабах — начинаются нюансы с тем же выделением памяти под JVM и GC и, напрмиер, ту же Кассандру НЕ ПРОСТО так переписывают на C++.Но до каких масштабов, как говоритcя, надо еще дорасти.
Нельзя. Большинству проектов ещё надо, как говорится, дорасти до тех нагрузок, когда Java и C# будут эффективней по RAM, например. А JIT нынче не только их прерогатива, причём эта компиляция может быть без проверок типов в рантайме, если транслятор уверен в типах: может вывести или информация о них предоставлена в исходниках а-ля type hints
добавить обязательную аннотацию типов в питон, и что изменится для новичка, да ничего.Для новичка изменится примерно всё.
Вы вообще когда-либо пробовали кого-либо обучать программироанию? Да новички понять чем
if от while отличаются не могут!А динамически типизированные языки — они воспринимают как языки без типов. Вообще. Они даже понятия такого: «тип данных» не знают.
То что вот это вот:
$a = "a";
$a[1] = "b";
print $a;
А вы хотите человека, который методом комбинирования кусков кода с разных сайтов получить что-нибудь как-то работающее описывать типы? Да господь с вами!
Обсуждение идет в теории динамика vs статика. А в качестве примера почему-то конкретные языки.
Так я и хочу обсудить, совпадение ли, что доминирующие языки в вебе — языки с динамической типизацией.
Да, в целом ваши аргументы верны (ещё про Си забыли, я на нём начинал писать в вебе после трехзвенки с апп-сервером на C++), но, по-моему, они лишь следствие таких факторов в языках со статической типизацией как:
- многословность — типы надо же писать, автовывода так вроде толком не было
- более сложный процесс перехода от исходников к работающему серверу, почему-то языки со статической типизации сплошь компилируемые и никто из крупных игроков, насколько я знаю, не пытался сделать что-то вроде: заливаешь по ftp .c/.cpp/.сs/.java файлы, а они компилируются в фоне или при первом обращении. По крайней мере 20 лет назад про подобное слышно не было.
- большее количество ошибок на этапе разработки, которые на языке с динамической типизацией прошли бы незамеченными
Если отойти чуть в торону от конкретных языков. И рассмотреть только динамика vs статика, то почему аннотация типов должна сильно усложнить разработку.
Собственно, как я выше, написал: большая многословность (писать ладно, а читать сложнее), большее количество ошибок, более сложные процедуры тестирования и деплоя.
По крайней мере 20 лет назад про подобное слышно не было.Если вы ни о чём таком не слышали, то это не значит, что этого не было. JSP ровно так и работают, это 1999 год. Но
safe mode нету, а значит на каждый сайт нужна своя JVM, а значит — дешёвые хостинги отпадают.Разве они не требуют предварительной компиляции? Смутно помню, что когда пробовал, то на каждый чих тип изменения даже html кода надо было что-то запускать, а не просто залить файлик. Если даже и можно было что-то менять на лету, то определенно были проблемы с выявлением зависимостей.
.jsp. А программисты на Java, внезапно, любят писать на Java. А вот .java файлы автоматически не перекомпилировались.Не все программисты на Java любят писать на Java. Я вот программировал пару раз — не понравилось. Не то чтоб писать, а компилировать постоянно, заливать результат компиляции..
По-моему, были нюансы когда один шаблон инклудишь в другой, а потом обновляешь первый — перекомпиляции или инвалидации второго не проходило.
большее количество ошибок на этапе разработки, которые на языке с динамической типизацией прошли бы незамеченными
А вот тут я в корне не согласен. Гдето в треде было замечания, что ошибок типов в программах всего 8% от всех. Что казалось бы немного.
Но если вспомнить как идет процедура разработки на динамика vs статика
1)динамика
Создаешь список(slice, array) из набора данных.
Итерируешь по списку и что-то делаешь с элементами
запускаешь программу
a.get_value
Traceback (most recent call last):
AttributeError: type object 'object' has no attribute 'get_value'
WTF и полез разбираться, ты разобрался и понял что не то закидывал в список, и в конце концов ошибки нету и в статистику она не попала
2)Статика
Итерируешь список
IDE тебе говорит: «братан, ты хотел в список пихать type1, а пихаешь type2»
А ты ей такой, «спасибо», и исправил.
Результат пока такой же, но когнитивная нагрузка ниже, тебе не надо самому следить за типами и думать, почему ошибка не вылетела, потому что код верный или потому что в эту ветку мы не попали.
более сложный процесс перехода от исходников к работающему серверу
Сейчас все в докерах, собирается в 1 клик.
многословность — типы надо же писать
Вопрос привычки, ИМХО. Если сразу показать язык с типами, то проблем не будет. Мой самым первым был паскаль, на первом курсе университета. Потом C/C++. Несколько лет писал часть времени на питоне, но начинаю прозревать.
AttributeError: type object 'object' has no attribute 'get_value'
Это не тот случай, о котором я говорил. Я о тех, когда, формально ошибка типов есть, например, на null проверки нет, но null на реальных сценариях использования не приходит. Тест написать, на котором код упадёт можно. В будущем когда-нибудь в твою функцию кто-то, может и ты сам, null передашь и получишь, грубо говоря, UB. Но здесь и сейчас ошибок нет. А со статикой сидишь и доказываешь компьютеру, что ты не дурак и знаешь, что делаешь.
Сейчас все в докерах, собирается в 1 клик.
Мы от сборки PHP отказались. Вернее есть базовый контейнер с какой-то старой версией приложения, запускаем его, монтируем каталог с исходниками в него и работаем так, моментально получая актуальную версию кода. Со сборкой контейнера приходится ждать даже в самом лучшем случае, когда всё закэшировано и только последня COPY в докерфайле что-то реально делает и вотчер настроен, дольше чем требуется нажать alt+tab и f5 в браузере.
Вопрос привычки, ИМХО.
Возможно, человек ко всему привыкает :) Но объективно текста больше в статически типизированных языках. Даже с развитым автовыводом рано или поздно его придётся написать или из-за "недоразвитости" автовывода, который, например, не понимает, что шейп для этого джсона, прилетающего в typescript лежит вон в той репе на гитхабе если зайти с такими-то креденшелами, в виде PHP сериализации вон той таблицы, описанной в SQL миграции. Или просто получив сообщение об ошибке типов на 100500 симвлов без понимания откуда он вывелся.
Если бы Донцова писала плохие книжки, то их бы никто не читал.
Но это и не делает их нетленкой. У какой-нибудь газеты с кроссвордами я-ля "Тещин язык" тиражи еще больше, но о качестве их содержимого это не говорит ровным счётом ничего.
Так и типизацией. Когда надо "нафигачить по быстрому" — да, очень удобно. А если что-то более серьёзное — то это как собрать все выпуски "тёщиного языка" за год и выпустить трёхтомником в надежде увлечь читателя поворотами сюжета.
Это мироустройство, лучше* которого пока ничего не придумали.
Если вам кто-то заявит, что сможет завтра сделать, чтобы от голода и болезней никто не умирал, то скорей всего он заблуждается или врёт.
Если в данный момент куча людей умирает от голода и болезней — это не просто так, и для этого есть свои причины.
* обратите внимание: «лучше» — не значит «хорошо», «лучше» — значит, что альтернативы хуже
Если вы думаете, что люди и компании, использующие динамические языки, делают это от незнания о существовании статических, ну, дерзайте, конечно, но у меня другая точка зрения :)
А может из-за экономии?
Решение использовать динамический язык может оказаться самым правильным решением по метрике, например, прибыльности.
Гораздо прибыльней пойти программистом на динамически типизируемых языках :)
Про "свалить" где я что говорил? Запустить MVP на динамике, поднять денег и переписать динамический язык на статический :)
Так не нужен уже тот разработчик, который лабал на динамике. Если не может на статике эффективно, то или в архитекторы его, или увольняем. :)
И, кажется, шутку юмора вы не оценили: не проект на динамическом языке перепишем на статический язык, а сам динамический язык перепишем в статический с максимальной обратной совместимостью c "предком". Примеры: HHVM, KPHP, TypeScript :)
Но странно читать заявление
Динамическая типизация — адское говнище. Инженеры которые верят в такой подход — серьезно ошибаются.от автора всего 15 дней назад написавшего в блоге:
Паша пошарил экран, и следующие четыре часа я наблюдал, как выглядит офигенная система, которую я никогда бы не додумался построить… И какая гигантская разница с настоящим синьором с 10+ опыта.В посте есть разумные мысли и видно что автор старается серьезно подходить к выбору инструмента работы. И все же, на мой взгляд, вместо того чтоб спорить какой язык лучший в мире — лучше руководствоваться подходом озвученным Рихеторм еще в первой книге по C#/CLR в далеком 2003 году: Язык программирования нужно подбирать под задачу.
А то получается одни пытаются написать на руби ядро операционнки, другие считают что С++ говно — потому что в нем нет даже сборщика мусора:)
Не все то js, что динамический язык. Кложуры к фронтенду прикручивают люди, которые ощутили кайф от разработке на ней на бэке и расчитывают перенести во фронтенд часть тех-же ништяков.
По своему опыту, на какому-нибудь динамическом Elixir, написать простой, понятный и (что важно) не забагованный код, куда проще, чем на (все равно горячо любимой мной) статической Scala.
Вон, вроде, даже статистика есть о количестве ошибок в репозиториях:
dev.to/danlebrero/the-broken-promise-of-static-typing
Отнюдь не бесспорная отсылка, но мне зашло.
Дядюшка Боб тоже за динамическую типизацию:
blog.cleancoder.com/uncle-bob/2016/05/01/TypeWars.html
Такие дела.
Дядюшка Боб тоже за динамическую типизацию
Оставьте деда в покое, у него TDD головного мозга.
Оставьте деда в покое, у него TDD головного мозга.И дед прав!
Не считаю так.
Там в самом конце статьи написано: «So says this old C++ programmer», в этом вся суть.
То что он пишет про качественный код это выводы сделанные им ещё лет 30 назад(хорошие выводы, ничего против), и их совершенствование да преобразования, в том числе чтобы их продавать побольше.
В текущем топике я на него полагаться бы не стал.
Утверждать что 100% покрытие тестами гарантирует что-либо как это может делать типизация — глупо.
Как пример хотя бы sqlite покрытый тестами 5 раз по 100%.
Но всё было бы совсем по другому, возьмись автор клеветать на функциональщину! А ведь она реально того заслуживает. Но группа её фанатов гораздо более агрессивна и сплочена, а потому автор убежал бы от них поджав хвост и опустившись в карме позиций этак на 100.
Интересный вывод — в джаваскриптёры идут слабаки. Или нет? А вот функциональщиной занимаются крайне упорные ботаники, способные залить миллионом негативных комментариев любую попытку их немного успокоить. Ну и с миллиона аккакунтов залить карму автора минусами. Учитесь, скрипто-слабаки! Вот так зарабатывают себе место под солнцем.
Но всё было бы совсем по другому, возьмись автор клеветать на функциональщину! А ведь она реально того заслуживает.
Аргументы будут?
Но вы не с меня это всё вытягивайте, а с автора. Он ведь смелый против слабаков. Может вам чего подскажет.
ЗЫ. А накидайте мне плюсов — смогу чаще отвечать. Ведь вашей целю не является заткнуть рот возражениям, правильно?
В общем давайте простой примерчик проанализируем. Допустим нужно выбрать списки, не содержащие отрицательных чисел. На входе список списков, на выходе тоже список списков. Во вложенных списках — целые числа.
Вот императив:
List<List<Integer>> in;
... // fill it
List<List<Integer>> out=new ArrayList<List<Integer>>();
top:
for (List<Integer> l:in)
{
for (Integer x:l)
if (x<0) continue top;
out.add(l);
}Приведите аналог на хаскеле, сравним, покажу пальцем, где сложность.
f :: [[Int]] -> [[Int]]
f = filter (all (>= 0))Строку с определением типов можно и вовсе удалить — тогда будет работать для любых типов, значения которых можно сравнивать.
Лишней сложности нигде не вижу, кроме разве что вашего вашего кода (java, вроде?) :)
В случае императива:
1) Что такое список, операции с ним.
2) Что такое цикл по элементам списка.
В случае функциональщины:
1) Все пункты из императива.
2) Определение функции, включая
2.1) Функции с неполным набором аргументов.
2.2) Лямбда-функции.
2.3) Ну и собственно объявление (в императиве его не потребовалось).
3) Что такое рекурсия.
4) Как с помощью рекурсии решаются ряд стандартных задач.
5) Какие библиотечные функции решают конкретные алгоритмические задачи.
6) Как комбинировать библиотечные функции для решения нестандартных задач.
Собственно вот на простейшем примере мы видим «скромное» различие в количестве приседаний, которые должен совершить студент, изучающий хаскель против любого императива. В данном конкретном случае язык Basic вообще убил бы по простоте всех, но мы же «большие задачи» решать собрались? Поэтому императивный язык может быть чуть посложнее. А вот хаскель и вообще функциональщина проще быть не может.
Поэтому всё, что остаётся функциональщикам — убеждать мир в ценности использования кратких названий (типа функция f, ага). Но в императиве я могу круче:
o=f(i);Ну если захочу повыпендриваться, конечно.
В случае императива:
1) Что такое список, операции с ним.
2) Что такое цикл по элементам списка.
А перед этим — что такое переменная (и с усвоением этого понятия у людей действительно часто большие проблемы), отличие от константы, понятие о последовательном исполнении, оператор new и понятие конструктора, понятие типа и обобщённого типа, методы, понятие об объектах и интерфейсах, чтобы объяснить, чем отличается List от ArrayList, условный оператор, оператор continue, метка цикла.
В случае функциональщины:
1) Все пункты из императива.
Не все.
2) Определение функции, включая
Про main и в императивщине рассказать надо, вы же не в вакууме код запускаете. А там сразу возникнет и пресловутый public static void, и String[] args, которые тоже придётся или объяснять, или говорить "пиши, так надо, объясню позже".
2.1) Функции с неполным набором аргументов.
Можно и без каррирования, только зачем писать копию уже готовой filter?
2.2) Лямбда-функции.
Их тут нет.
2.3) Ну и собственно объявление (в императиве его не потребовалось).
let filtered = filter (all (>= 0)) list3) Что такое рекурсия.
4) Как с помощью рекурсии решаются ряд стандартных задач.
Чтобы объяснить работу filter и all, объяснять их через рекурсию ненужно.
5) Какие библиотечные функции решают конкретные алгоритмические задачи.
Угу, а составлять filter самому из говна и палок цикла с досрочным переходом на следующую итерацию и условного оператора — это сильно проще, ага.
6) Как комбинировать библиотечные функции для решения нестандартных задач.
А комбинировать операторы в императивщине, разумеется, не надо.
Собственно вот на простейшем примере мы видим «скромное» различие в количестве приседаний, которые должен совершить студент, изучающий хаскель против любого императива.
Согласен, в императиве больше мусора.
В данном конкретном случае язык Basic вообще убил бы по простоте всех
В Basic есть динамические списки?
Поэтому всё, что остаётся функциональщикам — убеждать мир в ценности использования кратких названий (типа функция f, ага).
Не только. Если я захочу в коде на Haskell, скажем, просуммировать все подсписки, то я добавляю эту операцию — не обязательно в эту же функцию — и у меня всё ещё остаётся один проход по списку. Добавляем вывод на печать — всё ещё один проход. В вашем варианте или придётся добавлять ещё циклы, добавляя лишние проходы, или пихать больше кода в один цикл, лишаясь переиспользования кода.
И тут динамческие императивные языки имеют преимущество — даже обсуждать не стоит. Да, разработчики на таких языках стоят дешевле и на рынке их больше. Если это для вас является определяющим — то да, ваш выбор — условный PHP.
Просто нужно всегда понимать — за что вы платите и что вы получаете взамен.
А перед этим — что такое переменная (и с усвоением этого понятия у людей действительно часто большие проблемы), отличие от константы, понятие о последовательном исполнении, оператор new и понятие конструктора, понятие типа и обобщённого типа, методы, понятие об объектах и интерфейсах, чтобы объяснить, чем отличается List от ArrayList, условный оператор, оператор continue, метка цикла.
О да, только давайте уже не мелочиться, а сразу добавим сюда — что такое компьютер, что такое число, что такое отрицательное, и т.д. и т.п. Ну а потом заявим — студентам ФП это всё совсем не надо. Ага.
Можно детальнее разобрать ваш выпад, но и так очевидно — вы явно перегибаете и делаете из мухи слона с одной целью — спасти репутацию. Но поздно.
В случае функциональщины:
1) Все пункты из императива.
Не все.
Да все, все подряд. Что там за буквочки и что они значат — вот это всё основывается на тех самых концепциях. И эти основы универсальны, никакой студент не бросится изучать функциональщину, не понимая, что такое цикл, переменная и т.д.
Про main и в императивщине рассказать надо, вы же не в вакууме код запускаете. А там сразу возникнет и пресловутый public static void, и String[] args, которые тоже придётся или объяснять, или говорить «пиши, так надо, объясню позже».
Симметрично и для ФП нужно много чего дополнительного, что бы ваш код заработал. Так что вы опять и исключительно спасаете репутацию уходом в сторону от сути.
2.1) Функции с неполным набором аргументов
Можно и без каррирования, только зачем писать копию уже готовой filter?
Только вы же не против, что студент обязан изучить все эти готовые функции? И только после изучения десятков четырёх-пяти этих занимательных созданий, студент начнёт понимать, что вообще с ними можно делать.
2.2) Лямбда-функции.
Их тут нет.
Ну конечно есть. Вы их не видите, поэтому вам кажется, что их нет. А они есть.
В любом учебнике по хаскелю постоянно звучит одна песня — изучайте исходники. Массу библиотечных функций разбирают специально, что бы студент хоть что-то понял. Ну и разумеется, без передачи безымянных функций это всё никак и никогда не обходится.
Хотя вы можете доказать обратное — напишите код без библиотечных функций. И тогда я соглашусь, что лямбд там нет (если не будете использовать). Но пока вы используете чужое — я уверен, что вы просто не знаете, как оно внутри работает (во всех деталях, включая наличие или отсутствие там лямбд).
2.3) Ну и собственно объявление (в императиве его не потребовалось).
let filtered = filter (all (>= 0)) list
Ага, вот вы внесли ещё десяток головоломок для студента. Конструкция let сама по себе нетривиальна для начинающих, а тут ещё вроде как in забыт (давно я хаскелем баловался).
И кстати, в вашем начальном варианте нет аргумента list. Тут два варианта — либо используется очередной и совершенно неочевидный механизм для неявной передачи параметров (на столько неочевидный, что я его забыл), либо вы ошиблись, доказав наличие той самой сложности.
3) Что такое рекурсия.
4) Как с помощью рекурсии решаются ряд стандартных задач
Чтобы объяснить работу filter и all, объяснять их через рекурсию ненужно.
Повторюсь про то, о чём пишут во всех учебниках — читайте исходники. И как их понять без рекурсии? Хотя вы можете привести исходники filter и all, тогда станет очевидно, что я далеко не на все грабли для студентов указал.
5) Какие библиотечные функции решают конкретные алгоритмические задачи.
Угу, а составлять filter самому из говна и палок цикла с досрочным переходом на следующую итерацию и условного оператора — это сильно проще, ага.
Конечно проще. Это не требует всего того набора дополнительных понятий, про которые я вам тут доступно разъясняю. Хотя наверняка в каких-то либах есть функция итерации по вложенным спискам и я бы мог использовать её, ссылаясь на «не составлять самому», но проблема в том, что изучать все возможные либы — очень долго. И даже один Prelude — это реально много для студента. А в моём случае — всё быстро и тривиально. Ну а про нечистоты — тут уже ваш непонятный многим код напрашивается на комплимент.
6) Как комбинировать библиотечные функции для решения нестандартных задач.
А комбинировать операторы в императивщине, разумеется, не надо.
Разумеется, их там комбинировать намного проще. Там требуется школьная алгебра где-то класс за 4, максимум пятый. А в хаскеле требуется изучение массы понятий с нуля. Есть разница?
В Basic есть динамические списки?
Я вас удивлю, но версий басика в мире уже наверное больше, чем букв в Haskell Report 2010.
Если я захочу в коде на Haskell, скажем, просуммировать все подсписки, то я добавляю эту операцию — не обязательно в эту же функцию — и у меня всё ещё остаётся один проход по списку.
Ну про проходы по списку вообще зря заговорили. В моём случае в среднем имеем половинное количество операций от вашего кода, потому что отсеивание прерывается и сразу происходит добавление, а у вас обязателен полный проход по списку.
А какую там функцию кто-то может добавить — это вообще не в кассу. Кто-то всегда что-то может, но вот если разговор пойдёт о конкретной реализации, только тогда я вам смогу что-то ответить, а не в случае когда кто-то что-то и совершенно непонятно зачем.
В случае функциональщины:
1) Все пункты из императива.
Не все.
Да все, все подряд.
Да хотя бы понятие переменных, меняющих своё значение, не требуется.
… напишите код без библиотечных функций.
Вы же в своём коде используете библиотечные функции (add), сразу несколько библиотечных классов (list, arraylist — та ещё путаница для новичка), да те же циклы — напишите код без этого всего, тогда и посмотрим.
5) Какие библиотечные функции решают конкретные алгоритмические задачи.
Угу, а составлять filter самому из говна и палок цикла с досрочным переходом на следующую итерацию и условного оператора — это сильно проще, ага.
Конечно проще. Это не требует всего того набора дополнительных понятий, про которые я вам тут доступно разъясняю
Только ваш код в итоге требуется детально разбирать, чтобы понять что вообще он делает. Если в другом месте вам снова потребуется фильтровать список и вы напишете решение в таком же стиле, то придётся его снова разбирать — а использование функции filter сразу понятно читается.
Ну про проходы по списку вообще зря заговорили. В моём случае в среднем имеем половинное количество операций от вашего кода, потому что отсеивание прерывается и сразу происходит добавление, а у вас обязателен полный проход по списку.
Что, почему, откуда вы вообще это взяли? `all` конечно же вернёт результат сразу как получится false.
Хорошо работать инженером. Но, как интеграл посчитать, так хоть увольняйся.
Хорошо работать программистом. Но, как рекурсивную функцию с лямбда абстракцией понять, так хоть на пыхпых переходи (причем, на старые версии).
Ну да. Вместо циклов. О рекурсии рассуждать проще, чем по мне — инварианты как-то более очевидны.Не могли бы вы сформулировать это хм… более по-русски? Увидел словечко инвариант, но не понятно, к чему он относится.
не понятно, к чему он относится.
К рекурсии и к циклу. Вернее к доказательству правильности их работы.
Увидел словечко инвариантКоторое, казалось бы, неплохо описано даже и в Википедии.
Правильность работы рекурсивной программы тоже, обычно, с помощью инвариантов доказывается.
Как по мне, размышлять о квиксорте предельно просто — что сортированность результата, что завершимость алгоритма очевидны (лично мне, по крайней мере), тогда как для пузырька приходится включать голову.
Там всё по индукции доказывается. Но да, посложнее, чем для quick sort.
excludeWithNegatives = filter (all (>= 0))Уууууу, как сложно!
Во-первых, в тех императивных языках, на которых я писал, такой конструкции, какТо есть вы дейсвительно ни строчки на Java не написали? Это оттуда. Они, кстати, ещё очень гордятся тем, что у нихcontinue top, просто нет (gotoесть,continueпо метке нет).
goto нету… Changes requested, пожалуйста, перепишите более понятно.Там достаточно идеоматичный код, на самом деле. Но да, он требует знать массу разных вещей, если хочется его понять… но открою вам страшную тайну: большинство «Java-мартышек» понятия не имеют что они делают. Они комбинируют кусочки кода со Stack Overflow и смотрят на них в отладчике. Пока у них тесты не пройдут.
С декларативными языками этот фокус не проходит.
На Java оно тоже может декларативно выглядеть, для таких вещей циклы уже давно не обязательно писать:
jshell> var in = List.of(List.of(1,2), List.of(3, -4), List.of(-5,-6,-7))
in ==> [[1, 2], [3, -4], [-5, -6, -7]]
jshell> in.stream().filter(inner -> inner.stream().allMatch(e -> e >= 0)).collect(Collectors.toList())
$4 ==> [[1, 2]]Ну, за джаву, опять же, не скажу, но на плюсах я бы предложил использоватьЭто вы как хаскеллист-любитель или вы реально считаете, что люди на C++ так пишут? Я видел довольно много кода на C++ и могу сказать, что вот это вот всё используется горааааздо реже, чем другие части STL. Благо простой цикл обычно работает ничуть не медленнее.remove_if,copy_ifилиmove_ifcopy_if с make_move_iteratorили как его там, в зависимости от контекста.
Если бы это был remove_if, то пришлось бы ещё подумать, не пессимизирует ли это код, когда там у вектора есть эффективный move (сколько программистов из ста помнит?), и так далее.90% программистов на C++ этим, всё-таки, не заморачивается. Даже когда у вас C++-код, внезапно, оказался медленнее кода на Haskell — вы же не полезли в сгенерированный код выяснять «а почему вдруг тут C++ как-то сильно медленным стал», а накатали целую статью на Хабр…Хотя да, свойство C++ неожиданно «рассыпаться» из-за малых шевелений мы все наблюдали и не раз, но… даже с этим учётом он всё равно быстрее всех этих Python/PHP/JavaScript…
Ну ведь правда, понятнее, когда у вас код состоит из комбинаторов, семантику которых выводить не надо, а всё дано в названии.Если было бы «понятнее», то они применялись бы чуть чаще, чем «а что за херню ты так написал… оно что — в стандартной библиотеке есть… и всегда было… ух ты… круто… ладно, так и быть, поверю тебе, что оно работает».
Вот для человека с опытом работы на функциональных языках — да, оно, возможно, и понятнее. А для пришельцев с Java, C# и даже Python — не, нифига. Даже несмотря на то, что в Python это тоже в стандартной библиотеке всё есть. Как, кстати, и в современной Java.
Простой цикл по отношению к комбинаторам — это как jmp по отношению к циклам, условиям и свитчам.Всё так. Но, как вы думаете, какой процент использует циклы, условия и свитчи потому что они понятнее, а сколько — потому что им так сказали?
Примите, наконец, страшную, неприятную, но таки правду: 90% населения и больше 50% программистов не умеют в математику. Совсем не умеют. Максимум — сложение/вычитание. Ну и «больше/меньше». Иначе не было бы упаковок по 800-900 грамм и, соотвественно, директивы ЕС для указания цены за килограмм. Отсюда — и засилье императивных языков (которые они тоже не понимают, на самом деле, но могут в отладчик посмотреть) и многое другое. Да собственно кусок кода, который мы тут обсуждаем… откуда он такой взялся, как вы думаете?
Обычно в команде на десяток «месителей чана с перловой кашей» приходится один-два «гуру», которые реально понимают, что намешанный код делает (не глядя в отладчик), но для большинства — это загадка.
Вы вообще обратили внимание насколько часто вас спрашивают про всякие «окна отладчика» и прочее? Как вы думаете — почему? Да потому что они этот самый отладчик используют, чтобы «понять» как работает тот код, который они только что написали!
Я вот, честно, не скажу — что там такое творится в окне отладчика, так как я его за последние лет 5 никогда не видел и в принципе не скажу как там какие колонки называются. А они туда смотрят чуть ли не чаще, чем в окно редактирования — и не видят в этом никаких проблем!
И да, в какой-то момент вам приходится выбирать — либо вечно отказываться от позиции сеньора, либо-таки с этим мириться.
Ещё можно выбрать работу там, где другие люди тоже не имеют нужды смотреть в отладчик, проходить через код, чтобы понять, что он там делает, и так далее. Это как-то, наверное, полезнее в долгосрочной перспективе.Сложный вопрос. По моему опыту как раз в долгосрочной перспективе это плохо работает: крайне редко же бывает так, чтобы команда оставалась одного размера годами. Либо ваш проект закрывается, либо растёт. Первый случай явно в долгосрочной перспекиве… не очень перспективен, во-втором — вы, рано или поздно, получаете людей, которые не умеют в
remove_if, но «умеют» в for (int i=0;i<size;++i).выяснилось, что я не умею читать документацию на SIMD-инструкцииЕсть такие люди, кто это умеет? У меня регулярно оказвается, что инструкция делает… не совсем то, что она, вроде как должна делать.
Хотя обычно я ограничиваюсь исследованием того, как оно работает в железе на примерах…
Благо простой цикл обычно работает ничуть не медленнее.
Программисты на C++ всё ещё пишут циклы??? Слушайте, им надо как-то тактично намекнуть, что XX век уже кончился. Календарь показать там...
Чем вам не нравятся циклы?
Тем что они не нужны? В смысле — это типично императивный подход. А потом начинается. Тут цикл нужно развернуть — потому что эффективность вырастет. Как будто на С++ никогда не писали. Тут — цикл обратить. Да и вообще, если взять те же методы сортировки — кто там самый эффективный? Уж точно не пузырьки и вставки.
Если у вас нет зависимости по данным между разными итерациями — выгоднее map/filter/reduce. И пускай там компилятор разбирается — что эффективнее в конкретный момент.
Да, в этом случае цикл неявный. Но это и преимущество.
Тем что они не нужны?… выгоднее map/filter/reduce.
Стесняюсь спросить, а как по вашему устроены map и reduce под капотом?
Хвостовая рекурсия, которая разворачивается в цикл только на уровне машинного кода, как вариант. Но это, конечно, если компилятор так умеет.
Да, в этом случае цикл неявный. Но это и преимущество.
Вы читаете?
Отсюда то и недоумение. Вы, на голубом глазу, утверждаете, что циклы не нужны, а нужен синтаксический сахар вокруг них. Вам такой подход не кажется странным?
Окей, а если вот так?
Отсюда то и недоумение. Вы, на голубом глазу, утверждаете, что джампы не нужны, а нужен синтаксический сахар вокруг них: циклы и условные операторы. Вам такой подход не кажется странным?
Слишком много думать надо. Циклы — слишком низкоуровневые, их приходится читать целиком, чтобы понять, на какую более высокоуровневую структуру они отображаются. Более того, у них просто нулевая композируемость. Сравните:
fn get_ids_for_text_search(
sorted_ids: &[String],
spotted_ids_with_doc_count: &HashMap<String, usize>,
paging: Paging,
) -> (Vec<String>, usize) {
let mut ids_for_search = Vec::with_capacity(paging.limit);
let mut skip = paging.offset;
let mut iterated = 0;
let mut total = 0;
for id in sorted_ids {
if iterated >= paging.limit {
break;
}
let count = match spotted_ids_with_doc_count.get(id) {
Some(&count) => count,
None => continue,
};
if skip > 0 {
skip -= 1;
continue;
}
iterated += 1;
ids_for_search.push(id.clone());
total += count;
}
(ids_for_search, total)
}и
fn get_ids_for_text_search(
sorted_ids: &[String],
spotted_ids_with_doc_count: &HashMap<String, usize>,
paging: Paging,
) -> (Vec<String>, usize) {
sorted_ids
.iter()
.filter_map(|s| {
let &count = spotted_ids_with_doc_count.get(s)?;
Some((s, count))
})
.skip(paging.offset)
.take(paging.limit)
.fold((Vec::with_capacity(paging.limit), 0), |(mut ids, total), (s, count)| {
ids.push(s.clone());
(ids, total + count)
})
}Функционально оба фрагмента одинаковы, но второй куда понятнее говорит о том, что вообще происходит. В частности, во втором фрагменте сразу понятно, что из интересующих нас id на требуются только id в окне длины paging.limit, начиная с позиции paging.offset, в то время как в первом варианте эту же информацию приходится выковыривать из достаточно нетривиальной логики аки изюм из булочки.
Да. То, что удобно реализуется функциональными пайплайнами, удобно реализуется функциональными пайплайнами.
А если, скажем, нужен нерекурсивный поиск в ширину?
struct Foo;
fn next(item: Foo) -> impl Iterator {
// что-то там
}
fn breadth_first_search(start: Foo) -> Option<Foo> {
let queue = VecDeque::new();
queue.push(start);
while let Some(item) = queue.pop_front() {
if condition(item) { return Some(item); }
queue.extend(next(item));
}
None
}А еще циклы провоцируют типичные ошибки.
Помните? Ошибка в начальных и стартовых условиях, <= vs <. Потом когда циклы вложенные — разраб практически наверняка косячит с переменными и итерирует не по той. В целом — это все отлавливается, тот же PVS это ловит. Но это все время на разработку
А функциональные пайплайны провоцируют лишние циклы в рантайме. Там, где в императивном стиле я напишу один цикл, в функциональном выполнится их с десяток, например. И это тоже может быть ошибка (неисполнение нефункциональных требований), причём которую только бенчмарками и прочим нагрузочным тестированием можно заметить.
Не провоцируют. В примере выше будет выполняться единственный цикл в fold.
Это, по идее, проблема не функционального пайплайна как такового, а его "жадной" реализации, когда каждый filter/map/etc. немедленно генерирует значение. Если реализация условно "ленивая", и значение создаётся только по явному указанию (collect в Rust и, насколько я понимаю, вообще вся работа со списками в Haskell) — цикл как раз будет всего один, без необходимости вручную объединять в нём всю логику.
Ну, соглашусь. Именно поэтому если необходимо — нужно меть на более низкие уровни абстракции. Те же С++ и ассемблер поэтому в принципе не убить. Как вариант — язык может предоставлять какой-то механизм хинтования.
Другой вопрос, что скорость (точнее производительность) сейчас заливают железом… И всех это устраивает. Иначе не было того засилья интерпретируемых языков...
Ну, это вам понятней. Мне — нет. Вернее в целом понятно, но почти на каждой строчке после sorted_ids WTF.
Что вполне логично, если вы не знаете API Iterator. Но это учится только один раз, а восстанавливать структуру из циклов приходится каждый раз заново.
Цикл — это низкоуровневая конструкция, он громоздок и плохо выражает суть кода. Сейчас использовать циклы — это всё равно, что использовать goto при доступности структурного программирования.
Я сначала увидел код, а не описание задачи, попытался порассуждать об этом коде и что он делает, но у меня не получилось
Вот — вы почувствовали себя немного в шкуре того, кто учит хаскель.
Но лишь немного. Потому что непривычных вам понятий было мало. А в хаскеле — всё непривычное. Поэтому его и считают сложным большинство программистов. И не изучают. А что бы изучить, нужна какая-то серьёзная мотивация. Мало у кого её хватает.
А что касается и ваших и остальных возражений про якобы необходимость учить много фич императивного языка, то повторю — всё это очень простые вещи. Я бы мог для большей простоты вместо списков использовать массив, мог бы убрать типизацию элементов, мог бы и цикл в виде (i=0;i<;i++) сделать, но это всё конструкции одного порядка сложности, а в хаскеле уровень простейшей функции сразу требует гораздо более сложных абстракций. Поэтому перечисление названий использованных мною элементов синтаксиса ни в какое сравнение не идёт с перечислением обязательных для свободного владения концепций, без которых не написать даже самую простую программу на хаскеле.
А вообще — стыдно совать в нос определения типа «что такое буква» и заявлять что-нибудь такое — а монады в хаскеле ничуть не сложнее. Это говорит либо о полном непонимании вопроса, либо о самой очевидной предвзятости. И оба варианта — хуже!
in.stream().filter(inner -> inner.stream().allMatch(e -> e >= 0)).collect(Collectors.toList())Здесь (хотя и немало лишнего шума по сравнению с вариантом на хаскеле) как минимум сразу видно, что проводится именно фильтрация исходного списка, а не какая-то магия.
Вы просто почему-то под «понятностью» имеете в виду понятность для человека, только начавшего изучать программирование (хотя и с таким подходом ваши выводы спорные) — а код ведь обычно читают другие программисты на том же языке. Представьте, что вам нужно несколько списков отфильтровать по-разному — неужели вы каждый раз будете эти циклы городить?
Передам функцию фильтрации параметром :)
in.stream().filter(inner -> inner.stream().allMatch(e -> e >= 0)).collect(Collectors.toList())
на java, либо вот это:
filter (all (>= 0)) inна хаскеле.
либо на kotlin
in.filter{ it.all{ it >= 0 }}Ааа… Мне показалось, что тут про лаконичность и выразительность функциональных языков относительно всех остальных, потому и влез. Извините, коли не так :)
Максимум, что можно услышать, так это то, что ничто не запрещает, теоретически, такой язык создать… но про то, что он существует — никто даже не заикается.
Так что с функциональщиной ситуация [пока] совсем иная, чем со статической типизацией.
мог бы и цикл в виде (i=0;i<;i++) сделать, но это всё конструкции одного порядка сложности,
Возражаю, цикл for в стиле C — это очень сложная конструкция.
Watch — она проще.Единственно, что непонятно — это каким боком программирование связано с математикой...
Да ну?!
Это что же получается, печатая "Hello world!" я решаю математическую задачу?
Не бог весть какая сложная математическая задача, но… да, это оно и есть.
Строго говоря — нет. Я решаю проблему вывода "Hello world!". Программа, внезапно, тоже решает именно её. А кто и что там под капотом порождает — это уже совершенно другое дело.
А если еще строже говоря, то там не математика, а физика. p-n переходы всякие и прочая заумь.
p-n переходы всякие и прочая заумь.С этого момента — поподробнее. Вот берём мы всем известный компьютер:

Я решаю проблему вывода «Hello world!».В тот момент, когда пишите ТЗ — да.
Программа, внезапно, тоже решает именно её.Программа, внезапно, решает математическую задачу, описанную в ТЗ.
А кто и что там под капотом порождает — это уже совершенно другое дело.Именно. Задача исполнения вашей программы — это уже не программирование. Задача формулировки условия — это ещё не программирование.
Когда вы пишите программу вас не волнует ни первое, ни второе. Вас волнует только и исключительно математика.
Да, конечно, чтобы ваша программа была кому-нибудь полезна вам нужна не какая-то случайная математическая задача, а вполне определённая.
И да, человек, способный её извлечь из бессвезных бредней заказчика (обычно его Product Manager зовут) — может получать больше программиста.
Но это вот всё — не программирование.
Программирование — это решение математической задачи и запись решения в некоем формализованном виде. И всё.
Программирование — раздел математики. Вот так вот, просто и незатейливо.
О каких «p-n переходах всяких и прочая зауми» вы говорите? О моделируемых? Так они — часть задачи!
О тех, что в кремнии.
Ну ладно, допустим не p-n переходы, а сила трения промеж шестерней/капелярные эффекты в трубках/доплеровское смещение/you name it…
Математика — это всего лишь инструмент, которым удобно описывать эти явления — не боле того.
Задача исполнения вашей программы
Честно говоря, мне (а, главное, пользователям и заказчику), совершенно по барабану, каким именно образом программа исполняется. Главное, чтоб правильно. А там хоть миллион макак за печатными машинками — главное, чтоб "Hello world!" в итоге было напечатано.
Ну ладно, допустим не p-n переходы, а сила трения промеж шестерней/капелярные эффекты в трубках/доплеровское смещение/you name it…А зачем мне «name it», если от этого математическая часть задачи ровно никак не зависит?
А там хоть миллион макак за печатными машинками — главное, чтоб «Hello world!» в итоге было напечатано.Это всё понятно. Но точно также, как для синтеза какого-нибудь каучука вам нужно решить химическую задачу, а для создания двигателя — физическую, так для печати «Hello world!» вам нужно будет решить математическую задачу.
И никакие разговоры про шестерни и капиллярные эффекты в трубках этого не изменят. Они — такие же внешние данные к математической задаче, как и правила бухучёта.
если от этого математическая часть задачи
Наконец-то. Ровно про то и речь, что в программировании "математическая" именно "часть", но никоем образом не альфа и омега.
так для печати «Hello world!» вам нужно будет решить математическую задачу.
Для печати "Hello world" мне надо написать print("Hello world"). Математики в этом действе 0 целых 0 десятых.
Ровно про то и речь, что в программировании «математическая» именно «часть», но никоем образом не альфа и омега.Ещё раз: программирование — это область математики. А то, что само по себе программирование не решает никакиз практических задач — это другая история.
Для печати «Hello world» мне надо написать print("Hello world"). Математики в этом действе 0 целых 0 десятых.Серьёзно? А что это тут такое вы понаписали? Я вижу некрасивую надпись какую-то. Почему так нельзя:print „Hello, world!“или так:
Print [Hello, world!]Я боюсь вы сильно недооцениваете количество математики, которую вам придётся ввести, чтобы объяснить мне как простую строчку на экран вывести. И это мы ещё не задались вопросом о том, что иногда вам может потребоваться что-то ещё и ввести.
А физика — это математика, quod erat demonstrandum.
А вот о таком, чтобы программа писалась под «физический» компьютер, а не «математический» и её потом приходилось бы испытывать (если это не программа на Verilog) — я не слышал нигде и никогда.
Даже в тех случаях, когда это могло бы быть, теоретически, осмысленным (скажем на системх с Z80 бывало так, что длина строки, которую можно переслать до того, как память начнёт терять данные зависела от конкретного экземпляра) — этим никто не пользуется, пользуются огрублённой матмоделью (пересылают за раз «не слишком много», так чтобы данные их памяти не терялись).
Даже всякие хитрые штуки для космоса, где возможны сбои… не затачиваются под «физический» компьютер ничего, обычно всё равно математикой обходятся.
То есть если говорить строго формально: да, теоретически можно себе представить «программирование как раздел физики» — но на практике таким подходом не пользуются.
А вот о таком, чтобы программа писалась под «физический» компьютер, а не «математический»
Жаккард смотрит на вас с недоумением
Да, конечно, когда станки только разрабатывали — то измерения проводились… но дальше… есть некоторые математические ограничения на то, сколько можно максимум пропустить нитей, чтобы узор был устройчив — и вот уже в рамках этих ограничений и создаются программы для этого устройства.
Эка вы прировняли естественную науку к фундоментальной.
Математика — это, в первую очередь, инструментарий, крайне удобный и полезный для естественных наук.
PS Мои слова могут показаться вам уничижающими в отношении математики, но это, спешу вас заверить, не так.
Не, ну вот тут вы дали маху на самом деле.
Одна из задач.
Для решения какой задачи?
Не думаю, что этим занимаются алгоритмы в фейсбуке и гугле. Скорее это удел мясных менеджеров.
За механизированной теорией принятия решений вам скорее к трейдерам. Или экономистам.
Может быть математическая. Как понять? В чём вообще разница?
Wikipedia говорит, что это процесс создания компьютерных программ. То есть процесс, который начинается когда у вас есть задача, которую вам нужно решить (и формулируется она, очевидно, как математическая задача, потому как компьютеры могут работать только с ноликами и единицами, ничего другого там нет), а заканчивается, когда у вас есть программа которая эту задачу решает.
Вот это всё — чистая математика.
А «закрытие тасков», «общение с закачиками» и всё такое прочее — это уже «второй слой». В конце-концов и токарь и маляр общаются с заказчиками — но мы же не считаем, что это неотъемлемая часть их профессии? Почему в случае с программированием должно быть иначе?
Топология тоже математика.
Тут же как с "альтернативной медициной". Она либо не работает, либо работает и называется просто "медициной".
потому как компьютеры могут работать только с ноликами и единицами, ничего другого там нетИзвините, но это неправда. Даже на Хабре была была статья про механический компьютер.
компьютеры могут работать только с электрическими сигналами и ничего там другого нет
Да, большинство компьютеров сегодня работают с электрическими сигналами… но этот факт — в современных программах не используется. Эра аналоговых компьюьеров осталась где-то в XX веке… её пытаются возродить, но пока — без большого устпеха.
Квантовые компьютеры исследуются… но пока не применяются.
Потому сегодня — только нолики и единички. Всё остальное — формулируется в этих терминах.
математика — выросла из философии.А прчём тут это? Да, математику можно рассматривать как раздел философии… но как это поможет написанию программ или решению математических задач? Зачем вы этот, совершенно не имеющий отношения к делу, факт постоянно вспомнинаете?
поэтому математика — это чистая философия
многие программисты врядли помнят как дискриминант квадратного уравнения вычисляется.Я вас, может быть, удивлю, но то же самое можно и про математиков сказать. В программировании действительно не так часто используется арифметика, а с какими-нибудь эллиптическими функциями вы можете встретится разве что если криптографией занимаетесь. Но вот логика, индукция, инварианты и вот это вот всё — при написании программ используется постоянно.
а уравнение скажем пятой степени врядли решат без гугла.
Ну… теми программистами, которые пишут программы не путём комбинирования случайных советов со Stack Overflow, а теми кто таки могут получив условия задачи — написать её решение.
и формулируется она, очевидно, как математическая задача, потому как компьютеры могут работать только с ноликами и единицами, ничего другого там нет
Её можно перевести на язык математики как описание конечного автомата, например, но обычно куда прозаичнее: я, как пользователь, нажимаю такие кнопки, ввожу такую-то информацию в форму и вижу сохраненные данные.
Её можно перевести на язык математики как описание конечного автомата, например, но обычно куда прозаичнее: я, как пользователь, нажимаю такие кнопки, ввожу такую-то информацию в форму и вижу сохраненные данные.А дальше, собственно и начинается. Оказывается, что вы и заказчиком по разному понимали такие вещи, как «нажать кнопку на экране», «ввести» и «вижу».
Кажется маразмом — но я на это вот всё натыкался. Вплоть до того, что в понитие «вижу» втаскивался мини-язык запросов с их запоминанием и выбором из списка.
Пока вы не опишите задачу «как описание конечного автомата, например» — вы, на самом деле, не имеете задачи, которую можно решать и для решения которой вы можете написать программу.
Это не "строго говоря", это одна из ментальных моделей программы.
Программирование, компьютер, программы можно описать с помощью математики, но чтобы программировать или пользоваться компьютером математику знать не надо
Но, вы не поверите, математические задачи все так устроены: если взять учебник по математике, долго-долго случайным образом комбиноровать предложения оттуда и предъявлять экзаменатору, то рано или поздно — вы сможете сдать экзамен и получить свой «зачёт».
Значит ли это, что для решения математических задач знание математики не нужно? Я так понял, что ваша позиция, что «да»…
Математика — это язык. Достаточно мощный, чтобы описать модель работы компьютера. Но "машина Тьюринга" куда более близкая к реальности модель, чем "машина Чёрча", хотя математически они эквивалентны вроде как.
Это как для описания движения небесных тел в Солнечной системе использовать геоцентрическую модель. Да, можно, но нужно ли?
Программирование — это разновидность инженерии, прикладной дисциплины, и таковым в обозримом будущем оно и останется.
Нерешаема проблема останова произвольной программы. Но никто не пишет произвольные программы, а потом проверяет делают ли они то, что надо. Программы конструируются. И есть способы конструирования доказано-корректных программ.
Трудоёмкость построения таких программ выше, да.
Отличия — не бинарное возможно/невозможно, а требуют оценки затрат, времени, последствий сбоев.
тогда уж программирование — часть философииС этим кто-то спорит? Из философии «выросло», в некотором смысле, вообще всё. Беда в том, что оно «выросло» — и «отросло». Философские диспуты при создании и решении математических задач никто больше не устраивает (хотя Древние Греки этим занимались, кто бы спорил).
А вот математические методы — при написании программ используются вовсю. Более того, часто ими всё и ограничивается: программу пишут — и используют. Не проводя над ней никаких «экспериментов» (а вдруг вчера неправильно работающая программа при обновлении компилятора заработат… уф… не заработала — нужно ещё новее сборку взять).
претензии математиков на математику
Математика не сводится к идеальным платоновским сущностям. Претензии математиков на вывод всей математики из аксиоматических систем это именно что прекратило. Они поняли, что математика описывает наш мир, и для ее развития нужен приток информации из внешнего мира.
Так считает, например, Чейтин.
Типовой for (i = 0; i < 10; ++i) {} компилируется в лоб в четыре машинных кода на довольно примитивных процессорах. Ребёнку, не умеющему читать и писать, можно объяснить на пальцах в буквальном смысле слова.
for s in ["a", "b", "c"]
println(s)
endи
string[] s = ["a", "b", "c"];
for (int i = 0; i < 3; i++) {
printf("%s\n", s[i]);
}for (i = 0; i < 10; ++i) он тоже не до конца понимает, как работает и увидев в цикле continue top будет удивлён… но он же сможет посмотреть в watch и «всё понять»!А если в вашем языке в
watch смореть не получается? Что ему, бедному, делать-то?Мне вообще кажется что изобретение интегрированного отладчика — одно из самых страшных вещей, которые когда-либо изобретались… то есть, с одной стороны, его можно всегда эмулировать отладочной печатью… с другой — отладочная печать это достаточно неприятный инструмент для того, чтобы её сложно было использовать для того, чтобы «понять что делает программа».
А вот, по-моему, совсем не очевидно. Как я буду ребёнку объяснять, что такое диапазон или множество?
И вот тут начинаются проблемы — я с этим у своих учеников насмотрелся.
Почему одинаковое i во всех трёх случаях? «Это надо запомнить.» А зачем тогда его писать? Что будет, если заменить одно i на ii или на j?
Что будет, если заменить < на <=? 0 на 1, -1? ++ на +-, -+, --, +++? Почему последняя итерация для 9, но мы пишем 10?
> Ребёнку, не умеющему читать и писать, можно объяснить на пальцах в буквальном смысле слова.
Смешно ;) я пробовал это в реале. Не-а.
По сути, вначале приходится запоминать пачку идиом на непонятном неизвестном языке — «тут говорят так!» — и только потом начинает включаться поиск логики в набранном.
И эти идиомы значительно сложнее, чем какое-нибудь «for i := 0 to 9», «for i in 0..9» и т.п.
Часть проходит этот барьер легко — а часть учеников приходится затягивать, как бегемота из болота.
он физик, лет 40 назад делал лабы на фортране, про функциональщину только знает, что что-то там такое существуетВы бы ещё математика попросили сравнить эти две реализации, честное слово.
Вы бы ещё математика попросили сравнить эти две реализации, честное слово.
Если «обычному человеку» сложно представить себе как может одна последовательность превращаться в другую (но можно проследить в отладчике куда элемнты двигаются чтобы «понять» что получится), то у математика от самой идеи о «переменной, которая меняет значение» мозги клинит. Хотя со временем аналогии находятся, конечно и разобраться можно во всём, но…
И вот ей в императивном языке выносило мозг, типа, как же так, тут вотА вы поговорите с преподавателями програмиирования в школе. У всех школьников, поначалу, это — проблема. Но год общения регулярного с дебаггером — и вот уже голов «специалист» умеющий писать программы только с использованием пресловутого окошкаa = 1, а потом ужеa = 2.
watch… и переставшего воспринимать функциональщину.Самое грустное — что большей части удаётся «отбить мозги» и отучить понимать программы, написанные в функциональном стиле — и так не удаётся научить понимать программы, написанные в императивном… Вот это действительно грустно.
Извините, что вклиниваюсь. Я один из "этих", кто калечит людей изучением отладчика. Вы, собственно, что предлагаете изучать, чтобы у человека была перспектива трудоустроиться?
Если же человеку это не интересно, а он просто хочет стать программистом, потому что у них высокие зарплаты… ну не ко мне это. Вот совсем не ко мне.
Извините.
И да — тут совершенно неважно что он изучит, на самом деле. С трудоустройством — проблем не будет. Проверено.
Расскажите подробнее о методике вашей проверки.
Почему вы думаете, что трудоустройство — следствие изучения ФП?
Может быть вы просто отсеяли середнячков и оставили сильных и любознательных, которым пофигу что изучать, хоть танцы с бубном?
Почему вы думаете, что трудоустройство — следствие изучения ФП?Вы путаете причину и следствие.
Трудоустройство — следствие желание научиться программировать. Работодатели, они, знаете ли, любят людей, умеющих что-то хорошо делать. Удивительно, да?
Желание (в первую очередь) и возможность (во вторую очередь) разобраться как работают функциональные языки программирования — следствие того же самого.
Может быть вы просто отсеяли середнячков и оставили сильных и любознательных, которым пофигу что изучать, хоть танцы с бубном?Ну если бы им было интересно что-то другое — то они изучли бы что-то другое, не так ли?
А так-то, глубоко на филосовском уровне, вы правы: я знаю как научить человека математике, программированию, немножко физике и некоторым другим предметам — но только при условии, что человеку интересно их изучать.
Если же неинтересно… и его цель деньги зарабатывать… ну это не ко мне. Честно: я не знаю, что таким посоветовать и я даже не уверен, что программирование для них — хорошее ремесло.
Потому что тут очень много всего нужно знать и либо ты это всё знаешь и умеешь, либо выдаёшь чужие достиженая за свои.
Последнему — я не знаю как обучать и даже если бы знал — не стал бы этого делать. Этих «специалистов» и без меня хватает.
Вы можете научить только тех, кому "интересно" само программирование, а я могу научить тех, у кого хватит сообразительности и ума.
Вы ведь не думаете, что абсолютно всем умным людям интересно программирование? Эти множества только частично пересекаются.
Как вы уже верно заметили, работодатели любят людей, которые умеют что-либо хорошо делать.
Если человек умен, смог освоить программирование, но оно не является любовью всей его жизни, то что, ему теперь деньги нельзя на этом зарабатывать?
Вы можете научить только тех, кому «интересно» само программирование, а я могу научить тех, у кого хватит сообразительности и ума.Вы уверены? Кого-то уже обучили? Какая-нибудь статистика есть?
Или это опять «держите меня семеро», когда есть теоратические рассуждения… и всё?
Если человек умен, смог освоить программирование, но оно не является любовью всей его жизни, то что, ему теперь деньги нельзя на этом зарабатывать?Про «любовь всей его жизни» речь не шла. Человек не настолько ограниченное существо: ему знеете ли, могут много разных вещей нравится.
Что же касается «нельзя на этом зарабатывать?»… то тут не мне решать — пока он со мной не общается, то пусть решают его работодатели.
Но если общается и, как бывает у таких деятелей, отбивается от всех попыток чему-то новому обучится — то я не буду искать ему применение. А буду искать способ от него избавиться. Да вот так — просто, банально и, возможно, где-то жестоко.
Потому что моей задачей — не является предоставление такому индивидууму возможностей по зарабатыванию денег. А на рынке хватает людей, которым это дело нравится.
Я — уверен. Моя уверенность основывается на сравнении "до" и "после" отдельных студентов. При этом у меня довольно разнообразные примеры. Есть как сильные, так и слабые студенты.
Я в жизни не смогу столько однородных людей, чтобы заявлять о статистической достоверности.
А как вы проверяете, что действительно учите, а не просто устраиваете клуб по интересам? Судя по всему у вас видимо были одни умницы, а если кто то не тянул, то вы его сбрасывали со скалы в море.
Я вообще влез в эту дискуссию, потому что вы заявили, что 90% людей в этом мире, которые умеют пользоваться отладчиком — это какие то умственные инвалиды.
До кучи вы еще считаете, что люди, которые просто хотят нормальную работу не заслуживают звания программиста.
Вы не правы. Мир не черно-белый.
А до линз, зипперов и прочего, специфического для иммутабельности, многим удалось дойти?
Это я к тому, что переменную тоже просто объяснить, как ящик с содержимым, на которое можно посмотреть или положить что-то другое.
Это я к тому, что переменную тоже просто объяснить, как ящик с содержимым, на которое можно посмотреть или положить что-то другое.
Указатели на такую аналогию не очень хорошо натягиваются.
Ящик в котором лежит номер другого ящика
Я про это уже писал: как «устроен» простенький функциональный язык — можно рассказать урок. Один урок. С примерами и комментариями.
И всё — больше вам ничего на протяжении четверти (а то и двух) от языка не нужно. Никаких новых понятий. Можно изучать рекурсию, системы счисления, разные матрицы и прочее.
Это всё легко делается самими школьниками. Руками. Как башня из кубиков.
А вот курс какого-нибудь Python — это целая серия из 10-15 уроков, на каждом из которых вводится какое-то новое понятие.
К концу обучения в голове у обучаемого «перловая каша», которую он потом, безуспешно пытается месить с целью получить что-то разумное.
Но зато. Зато. Можно легко составлять тесты и экзамены!
То есть если ваша цель — «обучение для понимания» — то функциональщина идеальна.
Если вам нужно — «обучение для галочки» — и расстановка оценок… ну тогда императив — наше всё, да.
описать как вычисляется значение фукнции в функциональном языке
C массивами, как функциями из I^N -> T, проблем нет?
Это всё легко делается самими школьниками. Руками. Как башня из кубиков.
Это описание реальных занятий? Есть данные какой максимальный "уровень башни" достигался большинством учеников?
То есть если ваша цель — «обучение для понимания» — то функциональщина идеальна.
Понимания чего?
Функциональное и императивное программирование в этом плане очень сильно отличаются. При том, что почти все компьютеры — императивны по природе своей.
Но нет, принципиальной разницы между императивной программой и функциональной нету.
И то и другое прекрасно пишется так, чтобы работать с первого раза, при должной аккуратности.
Да, с функциональщиной чуть попроще, но… как-то же люди в 60е свои программы разрабатывали, получая час машинного времени раз в неделю где-нибудь в пятницу поздно ночью.
Вы, кажется, меня в такие люди записали? Ошибочка, если так.
Ну и для меня функциональщина чуть сложнее чем императивщина, особенно если нет статической типизации.
Вот чуть ли не единственная причина для меня попробовать воспользоваться отладчиком — отладить программу на JS в функциональном стиле написанную. Вот где, как по мне, статическая типизация необходима, так это в ФП. Я, знаю, что есть функциональные языки без неё, но кажется это должно быть достаточно грустно.
У нас — пробовали. Потом, правда, перестали, но об этом ниже.
Взгляните ещё раз на описание уже упоминавшегося язычка. Там нет ни циклов, ни указателей, там вообще почти ничего нет. Даже строк и чисел нет! Строго говоря даже и понятия «работа программы» и, как следствие, «сложности вычислений» нет… но вот это как раз при попытке реально со средой поработать, школьники быстро придумывают как оценивать.
Тем не менее, за всё время не было обнаружено, насколько я знаю, ни одного школьника который мог бы прилично писать программы на этом языке — а потом не смог бы разобраться с указателями.
Да, было весьма ненулевое количество школьников, которые так и не понимали, даже спустя несколько месяцев не понимали, как вот с этим можно сделать ну хоть какие-нибудь простейшие действия.
Числа в двоичной системе сделать и написать программу их складывающую не могли. Такие были.
А вот чтобы они могли спокойно писать на RL, но «затыкались» на указателях — такого не было.
То есть ваш учитель, в некотором роде, прав — и неправ. Одновременно. Совершенно не нужно доходить до указаталей (кстати я видел и людей, «умеющих» в указатели… пока они не касаются рекурсивных структур) — что требуется реально — так это понимать рекурсивные структуры данных.
А теперь «почему перестали». Потому что требования в школе, как известно, «никто не уйдёт обиженным». Какой бы предмет вы ни преподавали вам категорически запрещено даже заикаться о том, что кто-то, вдруг, может этот предмет не освоить. Если бы в школе учили музыке, в обязательном порядке, то кто-нибудь догалася бы штрафовать выпускников за отсуствие у них абсолютного слуха.
А с функциональщиной — есть проблема: если ты не понимаешь как это работает, то, как я уже заметил, очень тяжело написать ну вообще хоть что-то работающее. Меси «чан с функциональной кашей» хоть целые сутки, но… «в синтаксическом мусоре лик Ларри Уолла» всё никак не проглядывается.
Пока стояла задача научить людей программированию… всё было хорошо. Но как только критическая масса недовольных родитей достигла определённых размеров… увы… пришлось эксперимент свернуть и заняться тем, чем занимаются и все другие школы и почти все ВУЗы: подготовкой к выдаче сертификата.
А умеет «человек с сертификатом» программировать или не умеет — это уже никого не волнует. Ну… в школе, я имею в виду.
P.S. Результат мы видим, он, как бы, соотвествует предсказанному: я знаю в точности нуль компаний, которые считают наличие программистского сертификата достаточным для того, чтобы принять человека на работу. Могут быть разного рода тестовые задания, собеседования, что угодно. Но вот просто «у меня есть сертификат, оформляйте на работу» — не видел нигде и никогда.
P.P.S. Впрочем это мы уже очень далеко от типизации ушли. Функциональные языки, как и императивные, могут быть как статически типизированными, так и динамически. И я, пожалуй, не готов заявить «все программы нужно писать на функциональных языках». Хотя для обучения — да, они хороши. Если хотите научить программировать, конечно…
Я императивщину изучал в третьем классе, "исполняя обязанности" и программиста, и компьютера, в тетрадке выписывая стейт системы (благо для стейта там всего 15 общих регистров и два стэка ) до и после выполнения каждой инструкции. Как бы я разбирался с функциональщиной, не представляя во что компилируется какой-нибудь filter или map под капотом — не представляю. Стейта же нет — что выписывать? Про стэк ничего неизвестно, про текущий индекс массива тоже. А лямбда-исчисление в нашу начальную школу не завозили, да и вообще понятие функции — это уже класс шестой, наверное, был.
В школьном курсе физики у нас было правило: числа при решении задачи подставляются в последнюю очередь. Сначала нужно подставить друг в друга все необходимые формулы, ну и, возможно, вычислить какую-то одну из них, если дальнейшие рассуждения будут разными в зависимости от результата (направление силы трения определить, например, прежде чем считать её величину). Так вот:
Как бы я разбирался с функциональщиной, не представляя во что компилируется какой-нибудь filter или map под капотом — не представляю.
Да точно так же — подставляя формулу в формулу и сокращая всё, что сокращается.
Стейта же нет — что выписывать?Результат, очевидно. У выражения
2 + 3 × 4 (на уроках математики, не программирования) ведь тоже нет никакго стейта — и «невероятно сложную» задачу — посчитать значание выражения вы же как-то решаете. Как раз примерно как-то в классе третьем.А лямбда-исчисление в нашу начальную школу не завозили, да и вообще понятие функции — это уже класс шестой, наверное, был.И чего теперь? Нельзя всё это использовать? Ну да, конечно. С физиками поговорите. У них вся наука построена на диффурах и, соотвественно, производных и интегралах. Что совершенно не мешает её изучать в средней школе, за многие годы до появления этих понятий на уроках математики.
Про стэк ничего неизвестно, про текущий индекс массива тоже.Какой стек, какой интекс? Нафига вам всё это нужно? В IBM/360, к примеру, никакого стека не было. И как раз его появление в PDP (для ускорения и упрощения типовых задач) явилось первым шагом на пути к тому безумию, которое у нас есть сейчас.
Функциональное программирование, как я сказал, вообще гораздо легче и проще, чем императивное.
Если не забывать что программирование — это, всё-таки, раздел математики и не ожидать, что у вас человечки будут по экрану прыгать.
Как оно изучается? Да очень просто: функциональное программирование — оно, удивительно, о функциях. Неожиданно, правда?
Но… «что такое функция»? Ну… это математическая фурмула. Ну вот если вы хотите цену паката с яброками посчитать — как это сделать?
цена_пакета + цена_яблока * количество_яблок — так понятно? Сколько будет, если цена пакета 10 рубрей и мы купим 7 яблок, какдое тоже по 7? Ну вот можно посмотреть что думает об этом Хаскель:$ ghci GHCi, version 8.4.4: http://www.haskell.org/ghc/ :? for help Prelude> цена_пакета = 10 Prelude> цена_яблока = 7 Prelude> количество_яблок = 7 Prelude> цена_пакета + цена_яблока * количество_яблок 59Ну, как видим, Хаскель думает то же, что и мы.
Но только это грустно очень, набирать каждый раз
цена_пакета + цена_яблока * количество_яблок, когда хочешь узнать цену яблок Для чего нам компьютеры, собственно? Можно объяснить компьютеру, что такое цена яблок:Prelude> цена_пакета_c_яблоками (цена_пакета, цена_яблока, количество_яблок) = цена_пакета + цена_яблока * количество_яблок
Да, разработчики языка Haskell — немного странные люди. Они очень-очень любят краткость и иногда изобретают… несколько странный синтакс. Читается это так (я добавил курсивом места, которые создатели Haskell решили «укоротить»):
цена_пакета_c_яблоками это, при наличии данных нам (цена_пакета, цена_яблока, количество_яблок) = по определению цена_пакета + цена_яблока * количество_яблок.Сложно? Ужасно? Кошмарно? Где вам тут, вдруг, стейт потребовался? Функция — это определение. Объясняет как взять какие-то данные, которые у нас есть, и получить другие данные, которых у нас нет.
Теперь
map, великий и ужасный. Что это такое? А это так называемая «функция высшего порядка». Уж как грозно звучит. Но… если без зауми? Да очень просто: если мы знаем как посчитать цену одного пакета с яблоками, то map позволит посчитать нам цену многих пакетов с яблоками. Вот так:Prelude> map цена_пакета_c_яблоками [(10, 7, 7), (50, 7, 20)] [59,190]Цена маленького пакета с 7 яблоками (и ценой 10 рублей за сам пакет) — 59 рублей, цена большого пакета за 50 рублей (и с целыми 20 яблоками) — 190 рублей.
Вот, собственно, и всё. А «функцией высшего порядка» эта конструкция называется потому, что она берёт «простое» определение и делает из него другое определение — ничего сверхестественного.
Ну и так далее. Вам понятие «стейта» не потребуется ну очень долго. Можно писать весьма сложные программы на Haskell даже не подозревая о том, что существует там какой-то стейт и какие-то там монады.
Будет ли это идеоматический Haskell? Нет, конечно. Но это будут работающие программы — и некоторые из них вполне могут быть небесполезными.
И понять какое у них будет значение — можно без всякого стейта и, внезапно, меняющихся переменных в ящиках.
А как это считать — пусть компьютер решает. Мы же не зря за него кучу денег отвалили?
Да, в какой-то момент потребуются и монады и состояние… но как при изучении C++ не начинают с изучения виртуального наследования (без которого там даже
Hello, World «под капотом» не обходится), так же и функциональное программирование нужно изучать… ну никак не с монад.Есть список имен.
Программа выводит нам по одному имени и ждет от нас решения приглашаем на вечеринку или нет.
Маша?
да
Даша?
да
Коля?
нет
ну и собственно формирует новый список
ну или мы последовательно дергаем урлы из списка, и в случае кода отличного от 200 надо сразу на консоль вывести и номер ошибки и описание и текст из тела ответа если есть.
Я уверен что сделать все на функциональщине можно, особенно когда есть опыт. Но на императивный язык просто блок в блок переносится блоксхема с листика. А на фукциональный нет.
Как будет выглядть на хаскеле примерно такая программа.
Есть список имен.
Программа выводит нам по одному имени и ждет от нас решения приглашаем на вечеринку или нет.
Маша?
да
Даша?
да
Коля?
нет
ну и собственно формирует новый список
А зачем для этого программа? Сделайте Эксель, в нем столбец имя, столбец «приглашаем?» и фиксированные значения да/нет (сразу, чтобы оператор не мог ввести белиберду и вернуться и исправить значение, если, например, он передумал Машу приглашать в последний момент, потому что Коля не идет). А потом функционально можно всем параллельно отправить приглашения )
Но на императивный язык просто блок в блок переносится блоксхема с листика.
скорее да, чем нет
Ну блок-схема сама по определению императивна. Как и алгоритм в принципе.
Но на императивный язык просто блок в блок переносится блоксхема с листика.Зависит от того, что у вас там в этой блок схеме написано. Можно в схеме из 10 квадратиков и 10 робиков столько узлов навязать, что вы заколебаетесь её куда-то переносить.
Особенно если блоксхему рисовал не программист и там будут ещё какие-нибудь чудные пометки типа «тут выполнять только если нам потребуется когда-либо это число для полного отчёра рассчитать».
Вы, фактически, придумали весьма бессмысленную задачу (про Excel вам уже сказали) — и сформулировали её в виде, которое неудобно пользователю (потому что он не может вернуться назад и вычеркнуть Машу, потому что Коля решил не идти), а с другой — очень удобную для реализации на императивном языке.
ну или мы последовательно дергаем урлы из списка, и в случае кода отличного от 200 надо сразу на консоль вывести и номер ошибки и описание и текст из тела ответа если есть.А почему последовательно? А не параллельно, но максимум в 4 потока, как браузеры делают? Потому что вот как раз это хорошо ляжет на функциональщину с монадами и плохо — на императивный подход?
Ну да, таки да: если реальную задачу преобразовать в нечто, что хорошо ложится на функциональный подход — то можно, конечно, всё это легко реализовать.
Заметьте, что для этого вам пришлось переместиться в прошлое… и не просто в прошлое, а в определённую его точку.
Когда телетайп к компьютеру уже прикрутили (и batch processing ушёл в прошлое), а вот компьютерныей терминал ещё либо не изобрели, либо не научились иначе, как в режиме эмуляции телетайпа.
Вам не кажется, что подход «а зато со всем этим удобно работать с техникой 1970х годов»… звучит… э… несколько странно в 2020м, а?
Вы, фактически, придумали весьма бессмысленную задачу (про Excel вам уже сказали)
Ага, а корзина с яблоками в Excel не ложится, да 90% красивых задач на хаскеле ложится в эксель.
«Смотрите дети как красиво мы щас все числа умножим на 2»
«Смотрите дети как красиво мы щас все числа сложим»
Но почему-то такие задачи и показываем, а как императивщина, так «бессмысленная»
А какая вообще задача не бессмысленная при обучении программированию? Мы же о нем говорим.
Я студент и говорю, «А покажите как такое решается», а ты мне такой «Ты херню решаешь, не буду показывать». Это так то говоришь что функциональщина лучше понятней и тд и тп?
то можно, конечно, всё это легко реализовать.
я помойму тоже сказал, что можно. Хочешь в 4 потока, покажи в 4, я хотел на код посмотреть, а не на принципиальную возможность решить задачу, и посмотреть насколько он будет просще по сравнению с императивщиной. Когда мы не яблоки в экселе считаем.
Я студент и говорю, «А покажите как такое решается»,Отлично, я студент и говорю: вот есть у меня фотки вот этой самой Даши, Маши и Коли. Как мне сделать, чтобы человечки по экрану с их лицами бегали.
Вроде простая ж задача, да? Таких игрушек в AppStore — миллион, а может больше.
Ваши действия? Вы начинаете рассказывать как радотать с OpenGL/Vulkan… или всё-таки говорите, что лучше бы приглашения им разослать?
Как будет выглядеть на хаскеле примерно такая программа.
askUser name = do
putStrLn $ name <> "?"
(== "yes") <$> getLine
filterByUserPromt = filterM askUserdo-нотация и многое другое.Я о другом говорил: о том, что, во-первых, даже «простая» программа на интерактивном языке — нифига не проста, во-вторых — «классика жанра», программа, которая задаёт вопросы человеку и получает ответы, хотя и прекрасно ложится на инперативные языки, но, мягко говоря, не слишком актуальна.
А реальные программы (какая-нибудь, пусть даже простенькая, игрушка под Android) — требуют уже неплохого владения массой технологий.
Потому начинать обучение вы будете, в любом случае, с каких-то «ограниченных» и «упрощённых» задач.
И да — они будут разными для императивных языков и для функциональных.
С чего вы решили, что они должны быть, обязательно, одинаковыми?
var-begin-end-нотация в паскале никого не смущала, а do это прям отвал башки.
Восьмикласников отлично обучают хаскелю на https://code.world
Надеюсь никто не будет спорить что реализация на питоне какомнить хоть и многословней но явно читабельней и более понятна человеку которому дали азы языка.
names = ['masha','dasha']
invite = []
for n in names:
print(n+"? yes/no")
answer = input()
if answer=="yes":
invite.append(n)
print(invite)Захочет подтверждения, добавит вложенный if,
Я хоть и примерно понял что написано в хаскель варианте, но сразу на вскидку не скажу, как продублировать вопрос, в случае если ответили no например.
Хаскель отличный императивный язык. Уж чего-чего а с такими подкатами это точно не к нему.
Переносится всё ровно такими же методами, как и в каком-нибудь питоне. Разница начинается в том, что будет после — питонокод останется и сгниёт. По хаскельному будет видно где можно упростить и отрефачить.
И если «что-то идёт не так» — то мы получаем дикое количество ругани от компилятора.
Только почему-то в случае с C++ это считается неприятной особенностью конкретного языка, а в случае с Haskell — принципиальной проблемой вообще всего функционального подхода.
Почему в случае с C++ фраза типа «нет, не нужно писать
(x, y), так это не работает и прибавлять ' ' тоже не стоит, нужно писать ровно как учили… std::cout << x << " " << y; — а почему, поймёшь потом» — есть нормально и приемлемо, а в случае с Haskell — это низя-низя-низя, изучите сначала 100500 других вещей, потому узнаете как вводить текст и выводить его?Вот чего я понять не могу…
Но эта же проблема точно есть и у императивных языков! У большинства.
Там это решают «двухстадийным обучением»: вначале научим писать как-нибудь, порешаем плюс-минус полезные (хотя и учебные) задачи, а потом уж — узнаем как писать красиво и идеоматично.
Для Haskell тоже было бы полезно иметь книгу в таком духе… но я, скорее, не берусь её написать.
Так тут синтаксических форм как раз получается меньше — запятых нет, скобочек нет!Полным-полно, к сожалению. Причюм многие — это взрыв мозга для новичка. Какое-нибудь банальное:
zipWith (==) [1] [2]Вот зачем тут скобочки и что они делают? И вообще — почему это называется
zipWith, а не map2? Или вообще — почему не map?Да, если учесть полный набор, то в C++ синтаксических форм будет тоже немало. Но, увы, в Haskell их тоже хватает — и не все они просты.
map, а сравнить два элемента — это zip, да ещё и Width, да ещё и со скобочками? Почему-то в слуае с map о (== 0) такого вопроса не возникало.Но это всё не в упрёк Haskell, на самом деле. В Haskell есть очевидные косяки, но не тут, хотя да, ответить на вот эти вот вопросы можно только так, как вы сказали: потому что
zip — это логично, из него zipWidth — тоже очевидно отчего, а уже когда у вас оно уже есть, то заводить ешё и map2 с той же семантикой — это уже перебор.Собственно как известно в IT есть всего 2 сложных вещи: инвалидация кешей и придумывание названий… и что забавно, что почти вся наша дискуссия с rsync тут этому посвящена… правда в контексте конкатенации строк и сложения чисел.
Но если посмотреть на код, который сейчас под неё компилируется (на современных языках, а не на каком-нибудь RPG) — там этот стек будет успешно эмулироваться в принятом ABI:
main:
stmg %r6,%r15,48(%r15)
larl %r13,.L10
lay %r15,-192(%r15)
и так далее.
А байки 70-х годов, что виновного за его отсутствие в S/360 «отправили во внутрифирменный аналог Сибири». Да, байки, но показательно их появление.
Про остальное не возражаю — но в мире тотального ИП элементам ФП достаточно сложно выжить, чтобы использовались обе парадигмы.
Но если посмотреть на код, который сейчас под неё компилируется (на современных языках, а не на каком-нибудь RPG) — там этот стек будет успешно эмулироваться в принятом ABI:Было бы странно, если было бы иначе. Стек отлично подходит для интерактивных однопоточных языков с рекурсией… а вот для многих других — уже нет.
Про остальное не возражаю — но в мире тотального ИП элементам ФП достаточно сложно выжить, чтобы использовались обе парадигмы.Поживём — увидим. Пока что императивные языки всё ещё выигрывают по скорости. Но вот там, где это не критично (и где сейчас используются скриптовые языки) — они вполне могут оказаться востребованными. Haskell — отличная штука для работы с текстами.
Да и в императивных языках всё чаще пишут «в функциональном стиле».
вы, условно, зачем-то требуете чуть ли не формально математического понимания монад, чтобы написать немного кода в IO, но не требуете аналогичных вещей для императивных языков
Проблема в том, что для написания программ на хаскеле реально нужно понимать монады. Пусть без математической мути, но зато все концепции, вроде аппликативов и прочих функторов, разбавленные массой шаблонов реализации стандартных алгоритмов (которых в хаскеле вообще тьма — там почти всё, что придумало человечество в области универсальных алгоритмов). А ещё масса сложностей с типами. Опять же — ленивость. Ну и сам синтаксис хаскеля очень разнообразен. Хотя на фоне сотни базовых алгоритмов, запомнить полсотни базовых вариаций синтаксиса, это уже приемлемо, но тем не менее — это всё нужно отлично знать, что бы писать что-то вменяемое на хаскеле (или другом языке, но именно в чистом функциональном стиле).
Вам сложно понять простую истину — вы уже знаете несколько сотен базовых алгоритмов, шаблонов и прочих закорючек из мира ФП, а тем кто начинает, сотня новых шаблонов — это смерть. Они просто говорят — зачем мне это? Я могу делать то же самое без этой мути. И реально могут. И нет необходимости запоминать сотни нетривиальных понятий. Может они в итоге не смогут креативно упростить модель некой области до уровне «нелапшекод», но тем не менее они свою копейку зарабатывают и вполне довольны. И не видят смысла усложнять. Потому что деньгами это никак не поддерживается. Они и так на пошлом Го сотни штук зелени в год рубят.
Хотя проблема стандартная, гошники тоже так как вы считают — если я понимаю, значит все остальные либо дураки, либо конкретно я — ну очень умный. В обоих случаях имеем вознесение чсв до небес. А понимания не имеем.
Код на джаве он не понял совсем за какое-то разумное время, код на хаскеле выше — «ну, тут что-то фильтруется по условию сравнения с нулём, да?»
Прочитать слово filter и подумать о фильтрации — о да, это было совсем неочевидное предположение!
Вам самому-то опять не стыдно такое говорить?
Хотя по другому — в приведённых примерах используется библиотечная функция filter, поэтому я тоже считаю себя в праве использовать библиотечные функции, значит я тоже могу написать что-то вроде filter(list,Enum.LessThanZero) — вы спросите у отца, он наверняка такой вариант сразу поймёт, ну а ваш довод с отцом сразу померкнет.
И нет необходимости запоминать сотни нетривиальных понятий.Нужно-нужно. Только это сотни других понятий. Посмотрите как-нибудь на курс Python (а это, вроде как считается, «простой» язык). Там будет 10-20 уроков и количество новых понятий — ничуть не меньше, чем в случае с Haskell.
А понимания не имеем.Имеем-имеем. Вот только оно — не там, где вы его хотите представить.
Инпереативные языки — нифига не просты и с ними тяжело работать… но, конечно, если вас императивным языкам учили полгода-год (а быстрее я не видел, чтобы людей с нуля учили программированию), а на функциональные вы готовы потратиь пару часов, не больше… тогда да — функциональщина кажется сложной.
На самом деле — она просто другая.
Может они в итоге не смогут креативно упростить модель некой области до уровне «нелапшекод», но тем не менее они свою копейку зарабатывают и вполне довольны.А что — с этим кто-то спорит? Спор идёт про утвержление: «функциональщина — это сложно».
Это и так и не так одновременно: да, функцианальщина нетривиальна, но… она проще, чем императивные языки. Просто одно — вы изучали, второе — не хотите.
Вот и вся разница.
Хотя по другому — в приведённых примерах используется библиотечная функция filter, поэтому я тоже считаю себя в праве использовать библиотечные функции, значит я тоже могу написать что-то вроде filter(list,Enum.LessThanZero) — вы спросите у отца, он наверняка такой вариант сразу поймёт, ну а ваш довод с отцом сразу померкнет.Почему померкнет? Проделав такое преобразование — вы сделали один шаг на пути от императвного спагетти к функциональному описанию… ничего удивительного в том, что код стал читабельнее.
да, функцианальщина нетривиальна, но… она проще, чем императивные языки.
Есть какие-то объективные метрики это подтверждающее? Может мне пора в PHP от ООП переходить на ФП, благо стрелочные функции только что завезли.
Есть какие-то объективные метрики это подтверждающее?Размер «промышленных» языков. Почти все «промышленные» языки (неважно — C++ это, PHP или C#) имеют, даже в урезанной версии, описания в сотни страниц.
Функциональные языки, очень часто, обходятся десятком страни или двумя.
И да — речь не о примерах тьюринговской трясины, а реальных, используемых, языках.
Может мне пора в PHP от ООП переходить на ФП, благо стрелочные функции только что завезли.Не могу знать. Существует много задач, где функциональные языки работают хорошо (недаром 0xd34df00d ими логи обрабатывает — действительно бывает удобно и быстро). Существуют так же задачи, где они работают… не так хорошо.
Пропорции тех и других — зависят от решаемых вами задач.
Вообще, есть ощущение, что у функциональщины «большое будущее, которое никак не наступит».
Дело тут вот в чём. На железо функциональщина ложится лучше чем императивщина. Никто не мешает, в теории, сделать компьютер, который будет исполнять — и очень быстро исполнять — функциональные программы (по крайней мере те, в которых много параллелизма).
Более того — известно, что огромное количество задач именно так и «должны» решаться (иначе их не смог бы решить человеческий мозг с его катастрофически низким быстродействием и невероятным параллеллизмом).
Однако существующее железо — завязано в некоторый фиксированный «узел», призванный эмулировать фон Неймана.
И вот уже поверх этого — функциональщина работает плохо.
Но это не значит, что её нельзя испоьзовать для решения задач. Можно. Но вот в нефункциональном языке…
Я не знаю что там в PHP, но посмотрите на пример из Java. Собственно часть фильтрации — явно понятнее, чем в императивной версии:
filter(inner -> inner.stream().allMatch(e -> e >= 0)).Но ведь чтобы «пришить это» к императивным списка нужно «стартовать» с
in.stream() (причём тут stream — это вообще что такое? кстати и allMatch тоже нужен, и опять и снова, этот самый stream), а потом, в конце, не забыть «собрать» результат в collect(Collectors.toList()).В итоге: сама по себе функциональная часть — проста, проще, чем цикл. Но вот с учётом её «вклеивания в императивный код»… не уверен, что это правильный подход.
Но многим нравится… попробуйте.
Чем меньше ядро языка — тем лучше. Очевидно. Потому что чем больше стндарт — тем больше возможность возникновения в нем "взаимоисключающих параграфов"
В чём-то лучше, но вот в удобстве использования малое ядро языка может оказаться основной причиной его непопулярности из-за того, что нужно снова и снова описывать элементарные, атомарные для других языков вещи. Вот нет в языке if/for/while, а вместо них предлагается использовать метки и условный и безусловный переход — прекрасно же, упрощение, да? Или нет подпрограмм — вместо них переход не по метке, а по значению
Давайте теперь возьмём Haskell 2010 Language Report.Я бы Haskell сравнивал в основном с C++. Да, это самый «хайповый» функциональный язык, но нифига не самый маленький и не самый простой.
Да, статическая типизация — повышает надёжность и имеет массу других преимуществ, но описание языка она, очевидно, усложняет.
А мы ведь тут обсуждаем именно сложность языка, в первую очередь.
Haskell 2010 Language Report. 90 страниц
Ну вы сравнили. Репорт — это поверхностное описание концепций. А стандарт языка (или спецификация) — это подробное описание всего, что касается языка. Там все алгоритмы работы каждой конструкции, плюс обязательное описание стандартных функций (они всегда есть, без них нет языка, поэтому сложно назвать их библиотечными).
Хаскель вообще вырос в условиях бесшабашной вольницы. Авторы ещё в момент обсуждения основ согласились — обязательно сделаем формальную спецификацию. И так до сих пор и не сделали. А вы сравнили те спецификации, которые люди всё-таки сделали, с тем, что лишь обещали создатели хаскеля, но чего в природе просто нет.
Но если бы вы этот haskell report хотя бы открыли, то увидели бы, что там и описание подробное (вполне себе на уровне плюсового стандарта, и читать его легче), включая семантику и формальный синтаксис, и вполне себе есть секция про стандартные библиотеки.
Открывал. Видел, что там не 90 (по вашему) а 300+ страниц, ага.
Ну и монады — вы видели там главу про IO? 4 страницы.
Для сравнения в той же Java exception-ам отведено 14 страниц. Только exception-ам. А в хаскеле меньше одной страницы на Exception Handling in the I/O Monad. Ну что — супер спецификация.
Взял для примера Let Expression. Выше один знаток мне писал код для отбора списков с использованием этого выражения, я ему указал на отсутствие части in, он промолчал. Я решил, что опять забыл синтаксис и полез в этот самый репорт. Ну и вижу — строчка псевдокода, 5 строчек описания, строчка с очень частным примером. И всё. Далее идёт какая-то обведённая часть с названием Translation, в ней как я понял показано преобразование конструкции к ядру языка. И всё, больше ничего про Let нету.
Вот так — 5 строчек описания.
Хотя вы конечно сможете показать, как мне там найти вариант Let Expression без части in? Либо согласитесь, что даже те, кто считают себя знатоками путаются в простейших выражениях. И сложность здесь совсем ни причём.
Ну и Java — какой-нибудь простейший Assignement Context — 5 страниц описания. Больше чем на всё IO в Report-е.
В общем если не знаете смысла спецификации — можно было хотя бы просто промолчать. А то-ж вынесли на свет божий безалаберность и нежелание хоть что-то пояснять со стороны авторов Haskell Report.
Это как?
Пока что все LISP-машины и т.п. успешно дохли. Если бы у них было явное преимущество, они остались бы хотя бы как доступные сопроцессоры.
Увы, железо пока что в разы дешевле выполняет действие типа «поместить значение в R3», чем «вызвать функцию G с хвостовой рекурсией, перемапив аргументы».
> Более того — известно, что огромное количество задач именно так и «должны» решаться (иначе их не смог бы решить человеческий мозг с его катастрофически низким быстродействием и невероятным параллеллизмом).
Мы про мозг вообще ничего не знаем. И про «функциональность» его устройства — тоже. Пока что известно, что это скорее всего динамически перестраиваемая «матрица» с событийно-управляемыми блоками нескольких уровней.
Увы, железо пока что в разы дешевле выполняет действие типа «поместить значение в R3», чем «вызвать функцию G с хвостовой рекурсией, перемапив аргументы».
Ну, так фигли — давайте писать на ассемблере. Зачем нам тогда языки высокого уровня. С циклами ведь процессор тоже не справляется — у него в базе их нет (есть условные инструкции cmp + jmp). Если что — я немного передергиваю. Но если идти дальше — те же классы — их тоже не существует на аппаратном уровне. Поэтому почему сразу не писать на том, что лучше отражает область применения и позволяет писать эффективный и безопасный (а еще и поддерживаемый) код. Не люди для компьютера, а компьютер для людей. Почему-то об этом забывают
Каким образом это связано с моим сообщением?
> Поэтому почему сразу не писать на том, что лучше отражает область применения и позволяет писать эффективный и безопасный (а еще и поддерживаемый) код.
Можно. Там, где потеря на конверсии оказывается достаточно малой, чтобы с ней можно было смириться, и где сама аппаратная реализация не теряет порядки в производительности за счёт своих свойств.
mov cx, 0dh
kykle:
...
loop kykleДругое дело, что loop инструкция неэффективна, т.к. на dec+jnz оно меньше циклов тратит.
Увы, железо пока что в разы дешевле выполняет действие типа «поместить значение в R3», чем «вызвать функцию G с хвостовой рекурсией, перемапив аргументы».Конечно нет. Пока у вас этих регистров десяток или даже сотня — да, первое проще.
Если вы попытаетесь создать железяку с миллиардом регистров (а это, казалось бы, разумно, если у нас сотни миллиардов регистров) — то это чудо во-первых, будет иметь дико низкую тактовую частоту, а во-вторых — это нифига не ускорит выполнение программ. Потому «ядро» современного процессора — это, по прежнему, сотни тысяч транзисторов (притом что в проследних процессорах AMD их 40 миллиардов), а всё «вокруг» — это «ускоряторы» вот для этих несколькиз тысяч.
Для вызова «функции G с хвостовой рекурсией, перемапив аргументы» вам потребуется сравнимое количество транзисторов, да, но вы можете вызывать одновременно десятки тысяч этих функций вызывать!
Что такое программа на функциональном языке программирования? Это программа с минимальной зависимостью между её частями. В «чистом функцинальном языке» вообще есть только один вход и один выход. Все промежуточные состояния «железо» может исполнять где угодно и как угодно.
Так что «на железо» функциональщина ложится хорошо… но не на существующую архитектуру компьютеров!
Пока что все LISP-машины и т.п. успешно дохли. Если бы у них было явное преимущество, они остались бы хотя бы как доступные сопроцессоры.Увы, разница не настолько велика. Но главная проблема — у нас нет «железной» архитектуры, которая бы позволяла хорошо параллелить функциональщину. Все эти LISP-машины просто аппаратно реализовывали однопоточную реализацию. А тут я вообще не уверене, что функциональный подход может, даже в теории, выиграть.
А на какую? Есть какая-то уже реальная и испытанная архитектура? А то помечтать и я могу :)
> Для вас железо — это-таки Фон-Нейманн, всё равно.
«Яка розумная тому альтернатива?»
Есть какая-то уже реальная и испытанная архитектура?Если бы была — может быть LISP-компьютеры бы и не вымерли.
«Яка розумная тому альтернатива?»А вот на эту тему — идёт масса исследований и разработок.
Но до промышленной реализации, увы, ничего пока, насколько я знаю, не добралось. Кроме, пожалуй, Cell… но это направление было, в итоге, признано бесперспективным.
Впрочем некоторые компьютерные системы заняты всего одной задачей, так что… возможно.
В конце-концов Intel® Xeon® Scalable processor with integrated Intel® Arria® 10 FPGA в природе существует? Кто-то это покупает?
Так что всё может быть…
Проблема в том, что FPGA никак не сочетаются с многозадачностью.
Апчхи чего? Прекрасно там всё с многозадачностью. Берём OpenCl, добавляем SDK, добавляем плату с BSP и наслаждаемся.
Берём OpenCl, добавляем SDK, добавляем плату с BSP и наслаждаемся.Наслаждаемся чем? Одной программой? Или десятком? На одной FPGA?
Добавить-то можно что угодно. Но вот сейчас у меня на компьютере работающих программ — сотни две. Из них актиных — с десяток. Что будет с вашей FPGA, если вы попробуете раз 20-30 в сукунду загружать новую программу? Да вы их загружать-то не успеете, не то, что использовать!
Заметьте: я не сказал, что FPGA не сочетаются с многозадачной OS, которая исполняется не на FPGA. Они никак не сочетаются с многозадачностью… в том смысле что вам, в любом случае нужна одна прошивка — а дальше, да уже она, одна — может что-то и многозадачное исполнять…
И даже OpenCL ничего не сделает: запустить на одном GPU паралельно десяток задач — пока нельзя. И даже когда можно — это не десяток задач на одном GPU. Это «шинкование GPU» на маленькие кусочки, на каждом из которых работает одна задача.
2) Если задачи не связаны по выделенной памяти/данными — то без проблем, пока хватит ресурсов памяти и логических вентилей я вам хоть 100 разных кернелов запущу и они там параллельно будут вертеться.
3) Наслаждаемся одной программной на одной FPGA, одной программой на нескольких FPGA, несколькими программами на одной FPGA, несколькими программами на нескольких FPGA.
2) Если задачи не связаны по выделенной памяти/данными — то без проблем, пока хватит ресурсов памяти и логических вентилей я вам хоть 100 разных кернелов запущу и они там параллельно будут вертеться.Это не многозадачность, извините. Когда у вас на CPU работает, скажем, NGINX — всё ядро им занято. Когда там запускается mySQL — он тоже получает всё ядро.
А сменять они могут друг друга 100 раз в секунду. И на одноядерной системе — тоже.
3) Наслаждаемся одной программной на одной FPGA, одной программой на нескольких FPGA, несколькими программами на одной FPGA, несколькими программами на нескольких FPGA.Наслаждаемся чем угодно кроме нескольких задач, использующих ресурсы всего FPGA. А это, собственно, то, ради чего многозадачность и изобрели.
Но да, если говорить строго формально, FPGA умеют в многопоточность, но вот в разделение времени — не умеют.
Извиняюсь за неточность формулировок, потому что да, они важны: не всем и не всегда нужно разделение времени, если многопоточности вам хватает, то FPGA могут использоваться, да…
А вот кстати, интересно, были ли какие-нибудь эксперименты по запуску функционального кода на GPU? При беглом взгляде кажется, что как раз туда-то этот подход должен лечь почти идеально.
На хаскеле есть фреймворк Accelerate, который умеет компилироваться в CUDA.
Нужно-нужно. Только это сотни других понятий. Посмотрите как-нибудь на курс Python (а это, вроде как считается, «простой» язык). Там будет 10-20 уроков и количество новых понятий — ничуть не меньше, чем в случае с Haskell.
Я даже больше скажу — JavaScript в его полном виде реально сложнее хаскеля вместе со всеми системами автоматического вывода доказательств вместе взятыми. Но с другой стороны — он так же реально проще в использовании новичками.
JS (как и другие императивные языки) позволяет ходить маленькими шагами. То есть нужно знать лишь циклы и массивы — вот вам и вся основа для реализация алгоритма отбора списков. Да, не самым явным образом здесь ещё участвуют переменные, плюс некое обрамление для запуска программы, плюс понимание о последовательностях действий вообще, плюс математика, плюс какая-то логика и всё такое, но это уже реально самые базовые основы, которые знают сегодня все начиная со школы (там для этого есть информатика). Главное — ограничившись малым можно реально творить что-то важное. А в хаскеле так нельзя.
Возьмём для примера монады. Почему их? Потому что программа всегда должна что-то выводить и что-то получать на вход. Поэтому любая нетривиальная программа обязана как-то работать с монадами. В императиве есть файлы и потоки — это опять небольшой шаг, сделав который, ученик мгновенно становится способным писать что-то более или менее серьёзное. А в хаскеле так просто взять и почитать про монады нельзя. Для понимания посмотрите учебник на haskell.org, называется The Haskell Wikibook. Там часть про монады состоит из 9-ти глав, и что бы перейти к той же IO монаде нужно прочитать 5 глав из этой части, а перед ней 27 глав про хаскель, включая главу, например, о функторах (явно не каждый с такими понятиями встречался). И без прочтения 27 глав вы не поймёте монады. Плюс про сами монады 9 глав. И всё это не просто так, случайность или глупость. Во всех примерах в части про монады самым активным образом используется синтаксис и приёмы работы, показанные в предыдущих главах. То есть там нельзя пропускать (ну почти нельзя). А в случае с императивом — массивы, потом циклы, потом файлы, потом потоки — всё, вы уже программист (ну почти). Никаких классов и нетривиальностей с хаскелевскими datatypes, никаких функторов, аппликативов (а это всё предки в иерархии монад). Даже в монадической части учебника монада Maybe изучается только после двух вводных глав. И это самая простейшая монада! А сколько там «very handy» костылей! Вот например один:
We have seen how (>>=) and return are very handy for...
И вот таких закорючек (абсолютно бессмысленных в угоду сокращению длины текста программы) там огромное количество. Если с потоками можно сказать ученику — отдаёшь туда байты, они дальше ложатся куда попросил, то с монадами — ну вы сами почитайте тот учебник — как и куда там байты положить, что бы они в файл попали? И со сколькими промежуточными понятиями потребуется не просто познакомиться, а тщательно зазубрить, что бы понимать, как же наши байты куда-то ложатся?
Короче — сложность есть и большая. Нужно долго и упорно писать что-то на хаскеле, либо как-то по другому зазубрить очень приличное количество материала, прежде чем можно будет что-то записать в файл. При этом ссылки на do notation не подходят, потому что чуть более сложная программа, чем просто сохранение одного массива (например с логикой типа фильтрации) уже поставят вопросы перед учеником, на которые он ответить по простому не сможет. А в императиве он уже знает циклы, знает массивы, может фильтровать явно, без использования функций, которые пока не зазубрил.
Хотя конечно, можно всё это запомнить и повторять, но вот мне лично было неинтересно убивать время на постоянное повторение и я очень многое про все эти монады уже забыл. А забыть циклы — не проблема, потому что потом можно прочитать очень немного и всё вспомнишь.
Импереативные языки — нифига не просты и с ними тяжело работать… но, конечно, если вас императивным языкам учили полгода-год (а быстрее я не видел, чтобы людей с нуля учили программированию), а на функциональные вы готовы потратиь пару часов, не больше… тогда да — функциональщина кажется сложной.
На самом деле — она просто другая.
Она не другая, она сложнее из-за необходимости решать задачки через одно узкое отверстие. Там принципиально запрещены привычные в мире вещи вроде последовательности шагов с состоянием. Всё нужно оборачивать в функции. А если сложно — вводятся новые понятия, которые нужно учить.
Проделав такое преобразование — вы сделали один шаг на пути от императивного спагетти к функциональному описанию… ничего удивительного в том, что код стал читабельнее.
Опять нет. Я раньше тоже малость глупым был — думал, что функциональщина нам дала передачу функции в качестве параметра, но потом поумнел — адрес исполняемого кода передавали ещё когда программы писали прошивкой железных переключателей. То есть суммарно функциональщина показывает пример лишь в плане способности человека находить пути извернуться даже тогда, когда он сам себе наставил массу заборов, включая внутри самого себя.
Да, они весьма креативно развили идею чистой реализации функционального подхода. Но цена, на мой взгляд, получилась слишком большой. Я не смог выучить и потом не забыть те части подхода ФП, которые нужны для написания вменяемых программ. И не могу вспомнить за пять минут, почитав что-то из серии «что такое циклы». Мне теперь опять нужно тратить приличное количество времени. Может я тупой, может память плохая, но с императивом никогда такого не было, хотя языки я менял и на новые иногда поглядываю. Одна основа в императиве позволяет мне легко переходить между разными языками. А в ФП такой основы я не нашёл.
В императиве есть файлы и потоки — это опять небольшой шаг, сделав который, ученик мгновенно становится способным писать что-то более или менее серьёзное.Да вот нифига подобного. Чтобы прочитать банальный массив двумерный из файла и там какие-то суммы вывести — нужно разобраться в уйме понятий.
Работа с динамической памятью, все эти
resize и прочее. Жуткое количество… «добра», чтобы, банально, считать несколько чисел и потом их назад вывести.А в случае с императивом — массивы, потом циклы, потом файлы, потом потоки — всё, вы уже программист (ну почти).Ага. Щаз.
Если научитесь дёргать правильные примеры со stackoverflow — то, может быть, «в обнимку с отладчиком» и напишите чего-нибудь.
Но малейшие, простейшие, ошибки… Ну, скажем, наивная попытка вывести две переменный на экран написав такое:
std::cout << x, y << std::endl;Что будет? reference to overloaded function could not be resolved; did you mean to call it?. Не знаю что и кто тут
overloaded, точно не я, ну да ладно, поправим… candidate function template not viable: requires single argument '__os', but no arguments were provided… ась? вчера же всё нормально было, тааак invalid operands to binary expression ('std::string' (aka 'basic_string<char>') and 'basic_ostream<char, std::char_traits<char> >')… куда я попал… что это за зазеркалье?В общем если человек упорный — он, через полчаса-час, чего-нибудь и выведет. Но далеко не факт, что то, что требовалось. И ещё более не факт, что так, как надо, а не как-нибудь так… после чего простая замена строки на число почему-то выведет на экран 35… откуда 35, когда я 1 и 2 вывожу? Вы издеваетесь.
Если с потоками можно сказать ученику — отдаёшь туда байты, они дальше ложатся куда попросил.Это у вас они ложатся. У новичка — ложится что угодно и куда угодно, кроме того, что нужно.
Короче — сложность есть и большая.Ну а чего вы хотите. Взяли «модный», «индустриальный» язык и жалуетесь, что он… типа… индустриальный.
При этом ссылки на do notation не подходят, потому что чуть более сложная программа, чем просто сохранение одного массива (например с логикой типа фильтрации) уже поставят вопросы перед учеником, на которые он ответить по простому не сможет. А в императиве он уже знает циклы, знает массивы, может фильтровать явно, без использования функций, которые пока не зазубрил.А в императиве у него два числа распечатать — проблема! Вы думаете я всё вот это вот — сам придумал?
Там принципиально запрещены привычные в мире вещи вроде последовательности шагов с состоянием.Они становятся «привычными» когда вы годик «в обнимку с дебаггером» посидите.
Для новичка они — ну вот нифига не «привычны». Или, вернее, «привычны» — но совсем не те. А как на кухне. Когда можно сказать «добавить соли по вкусу» на третьем шаге — притом, что вкус у блюда, появится на десятом.
А в ФП такой основы я не нашёл.А искали? Разные языки функциональные попробовать, разные парадигмы? Потому что с императивными-то языками вы этим занимаетесь:
Может я тупой, может память плохая, но с императивом никогда такого не было, хотя языки я менял и на новые иногда поглядываю.
Странно ожидать, что навыки, которые вы постоянно поддерживаете в «живом состоянии» будут развиты так же, как те, на которые вы «забили».
И не могу вспомнить за пять минут, почитав что-то из серии «что такое циклы».Не сможете. Я регулярно интервьюирую бывших программистов, которые так считают. Ну то есть формально должность у них — какой-нибудь «Главный Архитектор», но реально — они признаются, что не писали кода «уже года три».
Так вот для них fuzzbuzz написать — проблема, катастрофа, полная невозможность!
Хотя в resume есть и программистские должности… лет 10 назад… и у меня нет основания им не верить.
Но вот после 3-5 работы чистым менеджером и не «языки менял», а «докладные записки соствлял»… всё. Нуль. Никаких пять минут — может неделю нужно восстанавливать форму, а может и полгода… я не знаю… но знаю что явно не 5 минут…
Для понимания посмотрите учебник на haskell.org, называется The Haskell Wikibook.Посмотрел, кстати. Неплохой такой учебник. Для математика или для человека, который владеет десятком других языков программирования.
Чтобы не сравнивать яблоки и вертолёты — не могли бы вы привести подобный же учебник C++. В котром перед тем, как вы пишите подобную программу:
#include <iostream>
using namespace std;
int main() {
int x, y;
cout << "Enter x: ";
cin >> x;
cout << "Enter y: ";
cin >> y;
cout << "Sum is " << (x+y) << std::endl;
}
— работу со включаемыми файлами (в том числе разницу между системными и несистемными)
— области видимости и, отдельно, пространства имён видимости и управление оными
— типы значений (glvalue, prvalue, xvalue, lvalue, и rvalue) и связанные с ними ссылки (включая разницу между Lvalue ссылками и Rvalue ссылками)
— классы, наследование (в том числе не забудьте про множестенное и виртуальное, пожалуйста, потому как без этого ж с std::ios работать не получится), и, конечно шаблоны и типажи, а также виртуальные функции (потому как
cin/cout — это всё испольуют)— разные виды инициализации (включая, статическую, динамическую и раннююю динамическую… а то вы без
cin/cout останетесь)— Перегрузка процедур и функций (включая, конечно, перегрузку операторов)
— ну и, до кучи, всякие мелочи там — фундаменталиные типы и числовые лимиты, порядок вычисления с приоритетом операций (это разные вещи, прошу не путать) и ещё десяток вещей, про которые я забыл (включая такие шедевральные вещи, как то, что функция main обазана иметь возращаемым типом int — но при этом возвращать значение в ней (и только в ней) — необязательно)
Что? Нетути? Ни одного примера нетути? Даже и первые издания учебника от Строутсрупа к этому не приближались (просто потому что в те время язык был проще)?
А почему нетути? Потому разобраться в императивном языке так «просто», да… или потому что в таком учебнике любой ученик «утонет» и до ввода пары чисел с их последующим суммированием просто не доберётся?
Ну так собственно вот им доказательство того, что функциональные языки проще: там такой учебник не только кто-то реально рискнул написать — но по нему люди даже и сам язык изучают успешно!
Не только для C++, но и для более простых языков (C, Python) мне подобных учебников (без пассажей «не пытайтесь это понять, пока просто запомните») не встречалось… потому что они очень просты для изучения, надо полагать…
Что? Нетути? Ни одного примера нетути?
Нет. Но люди всё-равно как-то научаются писать на императивных языках. Что-то щёлкает и концепция последовательного применения операций к мутабельному состоянию становится ясна. И все эти pr-values, scopes, классы рассматриваются в контексте структурирования мутабельного состояния и последовательностей операций.
С другой стороны есть множество подробных описаний того, что такое монада. Не конкретных инстансов монады, с которыми действительно не очень сложно разобраться, а монады вообще. И у меня, например, до сих пор не "щёлкнуло".
Да, это я не к тому, что функциональные языки не нужны. Многие их концепции удобны и полезны. Сам ими пользуюсь.
И у меня, например, до сих пор не «щёлкнуло».И не «щёлкнет». Пока вы не поймёте чем монада, на самом деле, не является. Она не является чем-то, что вообще имеет ну хоть какое-то, хоть малейшее, отношение к вводу-выводу.
Это просто конструкция, которая позволяет связать набор функций в цепочку. Ну и ешё она позволяет, при этом объединении, что-то там хитрое делать с этими функциями. Всё.
И вся эта мистика с моноидами и эндоморфизмами — это просто заумный способ сказать ровно это.
Почему же она тут вкорячена, прямо посреди языка, в самую простейшую программу
Hello, World!?Нет, не потому что без монад никакой ввод-вывод был бы невозможен. Это всё враки.
Есть полным-полно других функциональных языков, где таких ограничений нету.
Монада туда вкорячена для того, чтобы отделить «чисто функциональный код» от «грязного кода, общающегося с внешним миром». И всё. Больше никаких причин нету.
Создать монаду IO невоможно, одна должна откуда-то придти… ну и собственно, всё.
Функции у вас либо имеют доступ к этой монаде (тогда они «грязные» и она в них, каким-нибудь образом, «заходит»), либо не имеют (тогда они «чистые»).
Но это всё — исскуственная конструкция. Просто потому что авторам языка так захотелось.
Да, она даёт массу преимуществ… как Java получает кой-какие-то преимущества из-за помещения всех функций в классы.
Но никакого сакрального смысла ни в отказе от глобальных функций в Java, ни в необходимости общаться с внешним миром исключительно через монаду IO в Haskell — нету.
Вот поймите ровно это… и вдруг, внезапно, окажется, что «великой тайны монад» — не существует…
Потому разобраться в императивном языке так «просто», да…
На порядки проще, чем в функциональном. Поскольку любая — абсолютно любая повседневная деятельность человека происходит именно императивно. Начиная от "встал, умылся, позавтракал" и заканчивая "подумал, написал, скомпилировал, повторить если ошибки"
Потому эту импереативность при изучении языков программирования приходится довольно болго насаждать (почему я не могу использовать эту переменную… что значит «её значение ещё не определено»?) и только потому вам начинает казаться что вы, вдруг, что-то там такое поняли.
До тех пор пока не начнёте отлаживать lockfree алгоритмы и высните, что вы, на самом деле, ни черта не поняли.
На самом деле дейтельность не одна, их много
И что это меняет? Питие кофе у нас становится не процессом, а фактом? Желание выпить кофе, помол, заварка, его вливание мне в рот и выход естественным путём произошли одномоментно в один квант времени, без причинно-следственной связи и итеративного следования одного события за другим?
Проблема в другом, что исполнитель главный один, а коисполнителей много. И приходится делать примерно как в компьютере — один процессор + прерывания, чтобы накидать задач коисполнителям. Обменяться данными и все прочее. Сама парадигма однопоточного выполнения… Допустима. Но не жизненна для большинства задач. А с многопоточностью… Там все интересно. Во-первых, map/filter/reduce под капотом легко параллелятся на столько потоков, сколько возможно. Но это скрытая деятельность. Вот тебе и хадуп и бигдата. Во-вторых, многопоточное программирование и векторизация тащит за собой целый пласт отдельный проблем — с теми же дедлоками и всем прочим
Хех. А какой будет рецепт функционального заваривания чая? IO или какие-то другие способы взаимодействия со stateful миром, всё-таки придётся перед этим объяснять.
Потому эту импереативность при изучении языков программирования приходится довольно болго насаждать
Вот очень в этом сомневаюсь. В реальном мире мы совершаем действия, изменяющие состояния объектов (при этом что-то ещё происходит параллельно). То есть реальный мир — это IO a.
Что нужно объяснять, это то как мутабельное состояние, знакомое по обычному миру, отображается на переменные и какой смысл делить это состояние на части, а также почему такой естественный подход становится проблематичным для параллельных алгоритмов.
У меня есть один знакомый программист 1С, самоучка, который всё держал в глобальных переменных. Это было для него естественно — общее мутабельное состояние, над которым мы производим действия. И что-то у него даже работало.
Чтобы не сравнивать яблоки и вертолёты — не могли бы вы привести подобный же учебник C++. В котром перед тем, как вы пишите подобную программу:
#include <iostream> using namespace std; int main() { int x, y; cout << "Enter x: "; cin >> x; cout << "Enter y: "; cin >> y; cout << "Sum is " << (x+y) << std::endl; }
Вам подробно описывают, всё, что в ней происходит. То есть:
— работу со включаемыми файлами (в том числе разницу между системными и несистемными)
— области видимости и, отдельно, пространства имён видимости и управление оными
— типы значений (glvalue, prvalue, xvalue, lvalue, и rvalue) и связанные с ними ссылки (включая разницу между Lvalue ссылками и Rvalue ссылками)
— классы, наследование (в том числе не забудьте про множестенное и виртуальное, пожалуйста, потому как без этого ж с std::ios работать не получится), и, конечно шаблоны и типажи, а также виртуальные функции (потому как cin/cout — это всё испольуют)
— разные виды инициализации (включая, статическую, динамическую и раннююю динамическую… а то вы без cin/cout останетесь)
— Перегрузка процедур и функций (включая, конечно, перегрузку операторов)
— ну и, до кучи, всякие мелочи там — фундаменталиные типы и числовые лимиты, порядок вычисления с приоритетом операций (это разные вещи, прошу не путать) и ещё десяток вещей, про которые я забыл (включая такие шедевральные вещи, как то, что функция main обазана иметь возращаемым типом int — но при этом возвращать значение в ней (и только в ней) — необязательно)
Вы логично, но неправильно, строите возражение.
Да, у каждого действия в программе есть «подноготная». Но есть нюанс. Нам не нужно знать детали, если мы уже знакомы с концепцией. Но если мы незнакомы с концепчией, то только по деталям мы выясним суть происходящего.
Так в вашем примере имеем вполне логичные стрелки, указывающие направление движения информации, плюс объявление прерменных, плюс арифметику уровня первого класса, плюс std::endl (символ конца строки вроде?). Всё это показывает нам пример модели, давно и прочно усвоенной каждым ещё до школы — берём что-то и пихаем это по стрелке. Все остальные детали совершенно не важны, ведь вам не важно, что вы не знаете, как происходит процесс дыхания, как течёт кровь, как сокращаются мышцы и как работают нейроны в момент вашего «пихания по стрелке». Вам важно одно — вы достигаете цель.
Теперь хаскель. Аналогичная по сложности программа будет выглядеть примерно так же, но уже объявление переменных придётся либо исключить, либо вводить дополнительные конструкции языка. Но как я говорил ранее — этого мало, ведь чуть шаг влево-вправо — вас расстреляет компилятор. А почему? Спросит студент. Я ведь использую привычную модель со стрелками, а он её не понимает! Вот так на очередном простом примере мы снова видим разницу. Но если пример будет чуть сложнее — вы сами обязательно согласитесь, что модель движения по стрелке сразу умрёт, потому что стрелки будут разбавлены промежуточными конструкциями с той же фильтрацией или какой-то другой логикой. А вот в сишном примере можно включить фильтрацию просто очередным шагом, совершенно не влияющим на окружающие действия. Никак не влияющим, если нет связей по переменным. В ФП же в следствии необходимости всё заворачивать в функции нам придётся добавить ещё одну зависимость — по последовательности вызова функций. Не по привычной последовтельности шагов (взял яблоко с первой полки, положил на вторую), а именно по непривычным для обычного мира способав создания зависимостей.
Ну и чем дальше в лес — тем страшнее хаскель. Ведь каждый раз мы опять и опять должны находить способы заворачивания всего на свете в функции, да так, что бы «всё было чисто». И вот этим способам и посвящена львиная доля учебника. В случае же с императивом нам не надо ничего никуда заворачивать. Мы просто берём привычную модель полок, ступенек, ящичков, корзинок и работаем с ней без всяких обёрток. Привычно, логично, доступно, просто.
Так в вашем примере имеем вполне логичные стрелки, указывающие направление движения информации
нет. Это не стрелки вовсе. И они точно не относятся к "направлению потока информации". Вы натянули какой-то паттерн из жизни, но без подноготной студент увидев этот же оператор в виде битового сдвига сломает мозг. А можно было начать изучение с обратной стороны...
Привычно, логично, доступно, просто.
это порочная модель. Вы бы сказали — обмен сообщения, объекты, SmallTalk-76. А так студент берет метод для полки и применяет на ступеньку. После чего весь мир идет крахом
Вот так на очередном простом примере мы снова видим разницу.Нет, на одном простом примере мы видим патологическое желение натянуть сову на глобус.
Давайте рассмотрим простейшую программу. Она два числа выводит:
int main() {
std::string x = "a";
std::string y = "b";
std::cout << x, y << std::endl;
}int main() {
std::string x = "a";
std::string y = "b";
std::cout << x, y << std::endl();
}Почему после того как ученик «сдался» и решил эти две переменные склеить:
int main() {
std::string x = "a";
std::string y = "b";
std::cout << x + " " + y << std::endl;
}int main() {
int x = 1;
int y = 2;
std::cout << x + " " + y << std::endl;
}Но как я говорил ранее — этого мало, ведь чуть шаг влево-вправо — вас расстреляет компилятор.Извините, но вы просто не видели что говорит компилятор C++ на простейшие ошибки новичиков, пытающихся применить в жизнь вот это вот «берём что-то и пихаем это по стрелке».
Это ещё хорошо, когда компилятор что-то говорит. А если нет? А если вот так:
int main() {
int x = 1;
int y = 2;
std::cout << (x, y) << std::endl;
}А вот это вот:
int main() {
int x[2] = {1, 2};
std::cout << x << std::endl;
}0x7ffe4a85b2a8? Это вообще что такое? Это из какого угла вылезло?Haskell, по сравнению с этим, просто милашка.
Что же касается всего остального — то это полный бред, потому что там вы не пытатесь кого-то научить программировать на Haskell.
Вы, с упорством, достойным лучшего применения, продолжаете тянуть сову на глобус и рассказывать о том, как писать Java-скрипт программы на Haskell.
Так это не работает. Функция не вызывается. Нет никакой «последовательности вызова функций».
«Ведь вам не важно, что вы не знаете, как происходит процесс дыхания, как течёт кровь, как сокращаются мышцы и как работают нейроны в момент вашего «пихания по стрелке».»
ИЗМЕНЕНИЕ СОСТОЯНИЯ — ЭТО ТО, О ЧЁМ ВЫ НЕ ДОЛЖНЫ ДУМАТЬ, ТАК ЖЕ, КАК ВЫ НЕ ДУМАЕТЕ О ДЫХАНИИ, когда вы пишите функциональную программу.
Об этом компилятор должен думать, не вы.
А вы старатесь это изменения состояния вытащить из любого места, а потом удивляетесь — а почему так сложно-то?
Вот объясните, просто и понятно, почему программа выводившая одно число работала, а как попытались вывести два — так сразу, почему-то, просит вызвать функцию?
Потому что вы нарушили правила, которые вам рассказывали во время урока по потокам. Не нарушали бы правила — всё бы работало.
Получается, что вы ради того самого указания на процессы течения крови в ваших жилах теперь умышленно находите примеры, требующие учёта протекания крови. А если не ставить задачи во время обучения ожидать от учащегося знаний о процессах течения крови? Тогда мы вернёмся к тому, что я написал в предыдущем посте. Поэтому попробуйте ответить как-то по другому, ведь вот так «натягивая сову на глобус» ((с) ваше), вы обязательно отобьёте желание учиться у любого ученика.
Haskell, по сравнению с этим, просто милашка.
Приведите же пример, аналогичный сишному. И мы сравним. А так — ну опять сова на глобусе.
Что же касается всего остального — то это полный бред, потому что там вы не пытатесь кого-то научить программировать на Haskell.
Я пытаюсь вам показать проблему. А учить я вас не собирался, вы ведь вроде уже не школьник?
Так это не работает. Функция не вызывается. Нет никакой «последовательности вызова функций»
Есть последовательность. Если уж вам так хочется — начнём сразу с лямбда исчисления. Ну и посмотрим на последовательность подстановок при циклическом применении правила редукции.
ИЗМЕНЕНИЕ СОСТОЯНИЯ — ЭТО ТО, О ЧЁМ ВЫ НЕ ДОЛЖНЫ ДУМАТЬ, ТАК ЖЕ, КАК ВЫ НЕ ДУМАЕТЕ О ДЫХАНИИ, когда вы пишите функциональную программу.
Я не знаю, какими аналогиями вы пользуетесь, когда пишете реальные программы, но если вы касались, ну например записи в БД, то я с нетерпением жду ваших пояснений по такому процессу, но без мыслей о состоянии. И только потом я смогу показать, почему ваш подход неэффективен.
Потому что вы нарушили правила, которые вам рассказывали во время урока по потокам. Не нарушали бы правила — всё бы работало.Ну а с таким подходом и Haskell без проблем учится. Если не рассказывать про моноид и эндофункторы и на «странную ругань от компилятора» отвечать «не нарушали бы правила — всё бы работало» — то можно и программы, запрашивающие имена и меняющие переменные на нём писать без проблем. Смысла нет только, сначала бы другие вещи стоило бы изучит, но писать, если есть желание, — можно.
Я не знаю, какими аналогиями вы пользуетесь, когда пишете реальные программы, но если вы касались, ну например записи в БД, то я с нетерпением жду ваших пояснений по такому процессу, но без мыслей о состоянии.О! Ешё один отличный пример. Я-то напишу… если вы мне сначала расскажите — что за задача у вас с базами данных, что она требует массу кода для записи и совсем чуть-чуть — для чтения. Ну это вы же утверждаете, что не тяните сову на глобус всеми силами, а «оно само так получается».
То есть где-то когда-то как-то у вас была задача, где нужно много-много в базу писать (причём, ещё раз повторяю, не по количеству записанных гигабайт, а по количеству кода, мы же о программе говорим) и… почти никогда не нужно это читать.
А так-то да, запись в базу… это не самый хороший пример для функционального языка… вот чтение или модицикация… дело другое. SQL и функциональщина — очень близки (хотя и не совпадают).
Но вот как-то в моей практике всё время получалось, что читать из базы нужно было хитро и заморочно, а вот писать — ну что от пользователя или датчика получили — то и записали…
Ну а с таким подходом и Haskell без проблем учится
С любым подходом к изучению хаскеля будут проблемы.
Ещё раз — связать программу в строгую последовательность передачи параметров и вызова (ладно, условного) функций — это большой геморой. И для его устранения нужно запомнить массу шаблонов, которые нельзя забывать, потому что связность сразу потеряется.
В случае императива имеем возможность разбить обучение на независимые шаги, когда ученик получает некую основу и спокойно решает задачи соответствующего уровня. При переходе к новому совсем не обязательно, что ранее данная основа вообще понадобится. Поэтому учить можно независимыми кусками. С функциональщиной же такой фокус не пройдёт.
что за задача у вас с базами данных, что она требует массу кода для записи и совсем чуть-чуть — для чтения.
Имелась в виду работа с БД вообще. Не только запись.
вот чтение или модицикация… дело другое.
Отлично, теперь покажите отсутствие состояния при чтении, ну и при модификации.
SQL и функциональщина — очень близки (хотя и не совпадают).
Это очень разные подходы.
На SQL мы говорим, что нужно получить. На ФПЯ мы выстраиваем синтаксически правильную последовательность из аргументов и функций. Если эта последовательность получится читабельной — вы можете сказать, что стало похоже на SQL, но в большинстве случаев получается нечитабельно.
А нечитабельно потому, чтонужно зазубрить (тупо и нудно) очень много всего, начиная от синтаксиса, который на пару порядков разнообразнее SQL, и до всех тех шаблонов, которые обязательны для получения связной конструкции из функций и аргументов.
Или по другому. В ФП нельзя остановиться. В принципе нельзя до тех пор, пока не получится выходное значение. Иначе — ошибки компиляции. В императиве можно задать переменную, потом подумать, потом добавить ещё переменную, потом вынести в отдельную структуру, если показалось сложным. И каждый раз программа компилируется. Можно понемногу продвигаться к результату. В ФП же всегда нужны заглушки в виде недописанных функций. И эти функции никак не декомпозируют предметную область. Потому что область декомпозируется на элементы её состояния, а не на функции.
Вообще погуглите о проблемах с ФП в энтерпрайз разработке. Вам везде встретится проблема состояния. Точнее его отсутствия в ФП. Например — куда девать сессию при работе с браузерным клиентом? Ну и всё вот такое.
В паскале мутирующее присваивание выглядит как хер с яйцами и ничего, все довольны. А тут вдруг стрелочка и всё, взрыв мозга. Фантастические отличия, ничего не понятно!
Проблема в том, что для написания программ на хаскеле реально нужно понимать монады.
Да откуда вы это всё берёте? Максимум там надо знать разницу между заведением именованных выражений через let и получением результатов процедур через <-. Выдумали мне тоже… Монады-шмонады...
Отчасти это из-за того, что «комбинаторно программировать» на функциональных языках тяжело. Отчасти — из-за того, что тьюториалы пишут математики… которым кажется разумным ввести все определения и леммы, а уж потом, если все студенты не разбегутся, заняться изучением, собственно, того, что они, вроде как изучают.
Когда язык ну вот совсем крошечный, учебный — это неплохо работает. Когда так изучают промышленный язык… ну тут остаётся только развести руками. Я чуть выше попытался описать как выглядел бы учебник по C++ в таком же стиле. Не думаю что его вообще хоть один человек в мире смог бы осилить…
Если бы в статье не было практически прямых оскорблений и принижения чужой позиции, она была бы менее популярной на хабре?
Я могу согласиться с посылом статьи, так как я тоже за статическую типизацию, но нападения на других людей отталкивает от текста, отвлекает от мысли. Мне не нравится читать о "динамической типизации", но отвлекаться на описание чьей-то "башки" и приравнивание её к тупой.
В списке причин минуса к статье нет такого, который описывал бы агрессивность изложения, а ставить за "другое" не хочется. Есть "личная неприязнь к автору", но я же автора как человека не знаю, мне конкретно текст не нравится. :)
Куда смотрят moderator?
Между тем питон — топовый язык программирования на динамической типизации.
Куда смотрят moderator?Иногда приходит усталость от толерантного не черно-белого мира, и просто хочется назвать вещи своими именами.
То есть я знаю, что вот эта функция работает только вот с такими объектами, я описываю их в ее сигнатуре и получаю гарантию — объект другого типа в функцию передан не будет.
Если автор так боится, что его функция получит объект не того типа, то что будет при виде указателей, когда в этом блоке памяти может быть вообще всё, что угодно? Паника? Обморок?
Может, если в языке единственный способ создать указатель — это взять адрес уже существующих данных.
Я возьму нормальный язык, в котором подобное не скомпилируется.
Могу конечно ошибаться, потому что, как уже написал, никогда с Rust не работал.
Только не ещё один ансейфосрач, пожалуйста :) Вообще да, сырые указатели есть, но есть и неоднократно высказанная рекомендация — без особой необходимости unsafe (который необходим, чтобы сделать с ними что-то осмысленное) не использовать, а если она есть — чётко описать, почему этот unsafe корректен.
В JS есть куда более ужасные вещи чем динамическая типизация.
Потому что это частный случай задачи коммивояжера — ты НИКОГДА не можешь предусмотреть все кейсы.
Тут наверняка имелась в виду задача остановки. Коммивояжер таки вполне конечный.
И зачем было срать прямо в комментах?
Большинство преимуществ можно свести к "не надо заморачиваться с типами пока программу не запустил"
Но когда вижу какие сложные библиотеки пишутся на том же джаваскрипте или питоне, понимаю, что и такая практика заслуживает внимания.У меня есть либа, занимающаяся датавизом и процедурной графикой. 95% данных — числа, и одно-двумерные массивы их. Пара сотен функций принимает массив точек, несколько параметров в float и int, и возвращает массив точек. О чём тут писать статью? Как я несколько тысяч раз написал бы float и int, если бы писал на статике, и ничего бы не изменилось?
А вот завтра понадобилось переписать часть логики. И не вам, а другому человеку. Открывает он такой одну из ваших функций, а там def parametrize(x, t, d). И он такой "так-так-так, интересно, а они тут все инты?". И задача такая — "а я теперь не линейной сложности, я теперь фрактал!" и гнусненько хихикает.
def parameterize(float x, int t, int d). Вам сразу понятно, и зачем функция, и что она делает? Мне — нет.Зато мне понятно, чем она оперирует. И чтобы понять, что она делает, мне будет достаточно проанализировать поток выполнения только в прямом направлении, а не в обоих.
Окей. Пусть у нее будет такое вот тело
return x + t * dЧто она вернёт?
И?
Либо список любых значений, ага.
return [(date(1970, 2, 7), "ggg"), 2, 3.2] + ["vasya"] * 3И любой язык, в котором конкатенация и арифметическое сложение — разные операторы, скастует это всё в числа и вернёт числа.
Меня нет, но кто поручится за автора кода?
А вот завтра понадобилось переписать часть логики. И не вам, а другому человеку.
Как, кстати, поможет статика, если в функции 4 параметра, все одного типа, и вы перепутали их порядок, когда вызывали?
"Ошибся -> исправил" VS "Увидел тип и сразу написал правильно". Как по мне, так второе предпочтительнее.
По секрету вам скажу, что от вторжения инопланетян статическая типизация тоже не спасёт.
Правда такая стратегия подразумевает отказ от психологической плюшки в виде «там точно нет ошибки такого класса».
в типах тоже самое, даже хуже ситуация (тестов хоть
пишут пакет, а не один).
Можете привести пример?
Вот именно за счёт этого: за счёт отрицания самых её основ. Если не считать, что у фразы, написанной на бумаге (или на экране) вообще есть какой-то смысл и согласиться с тем, что «истинный смысл» существует где-то ещё… ооо, тут можно хорошо развернуться.
Потому нужно обязательно пройти этап, когда ты выбиваешь, всеми правдами и неправдами, хоть лестью, хоть признием себя идиотом, неважно, право считать что написанная фраза таки имеет какой-то смысл.
Но нет, не у rsync и ему подобных (это бесполезно и бессмысленно, уж своё главное оружие они никогда не «сдадут») — у их начальства.
Дальше уже можно начинать процедуру изживания… что, на самом деле, занимает куда как меньше времени и сил — и является задачей чисто технической.
ещё раз: если программист написал правильное решение, то пофиг на каком языке он это сделал.
1)Я осознаю, произвольные ошибки язык за человека не исправит
2)Я так же понимал что ты это должен понимать
В дополнение выяснилось, что то что я считаю логическими ошибками — неправильное понимание задачи, опечатка потянувшая за собой другие ошибки(написал в функции плюс вместо минуса и вывел 4 леммы для этого плюса как следствие ошибки) и всякие тупняки, ты такими не считаешь. Глупо спорить о том помогает ли язык исправить логические ошибки, если мы под ними понимаем разные вещи. Мои не помогает, твои помогает)

Что скажете насчёт Deno (новая среда исполнения с поддержкой TypeScript от самого создателя Node.js.)? Как раз на днях вышла версия 1.0.
О чем это говорит? О том, что дизайнеры новых языков внимательно изучают опыт программирования на динамических языках, считая его полезным.
И о том, что происходит конвергенция динамических и статических языков — в новые динамические, например, явно будут добавлены необязательные аннотации типов, как это уже сделано в Перл6.
А двухминутки ненависти устраивают чистые прикладники, которым просто надоело все время обслуживать хотелки бизнеса и хочется чего-нибудь чисто для души, например,
поругаться.
Программы на современных хипстерских статических языках (Go, Swift, Rust, в какой-то мере C#) куда больше напоминают Питон, чем С++.Все языки что вы перечислили имеют статическую типизацию. Автовывод типов не делает язык динамическим, а плюсы образцом надежной/выразительной системы типов вовсе не являются.
О чем это говорит? О том, что дизайнеры новых языков внимательно изучают опыт программирования на динамических языках, считая его полезным.И делают статически типизированные языки, развивая системы типов, да. А неудачный опыт полезен как любой другой.
И о том, что происходит конвергенция динамических и статических языков — в новые динамические, напримерНе ясно как вы пришли к таким выводам, учитывая что все приведенные вами новые языки статически типизированные.
Не ясно как вы пришли к таким выводам, учитывая что все приведенные вами новые языки статически типизированные.Ну если не знать истории и замечать только похожие элементы в разных языках, то может показаться что какие-то вещи перекочевали из Python или там JavaScript в современные статически типизированные языки. Тот факт, что даже сам Pytnon прямо в документации говорит про Standard ML, Ocaml и Haskell… разумеется никого не волнует. Зачем себе голову забивать?
Похоже на то, что видел когда-то в PHP — значит PHP это всё и изобрёл… и из PHP в Rust оно всё и перетекло. А что там Wikipedia пишет (а там, кстати, есть даже целый раздел «Influenced By» и у Go и у Rust. У последнего, впрочем, всё подробно задокументировано и он действительно кой-чего взял из языков с динамической типизацией. Из Ruby: closure syntax. А из Erlang — message passing и thread failure.
Не самые центральные фичи, а главное — с типизацией они никак не связаны. Вообще.
Автовывод типов не делает язык динамическим
Как и тайпхинтинг в динамических языках не делает их статическими. Но программы на таких языках могут быть неотличимыми за исключением нюансов синтаксиса и одинаково типобезопасны. А то и динамический безопасней будет. Разница только в моменте выявления ошибки.
а плюсы образцом качественоой системы типов вовсе не являются.
А какие из мэйнстрим языков ими являются? Java? C#? ну не C же :) Нет ли корреляции: чем качественнее система типов, тем менее он популярен? а может это не корреляция, а причинно-следственная связь?
а может это не корреляция, а причинно-следственная связь?Причинно-следственная связь, только не совсем туда: создание качественной системы типов требует времени — и соотвественно, ниша оказывается занята.
В C++, увы, система типов взята прямо из C — это 70е годы. Все языки с более-менее вменяемой системой типов — это 80е-90е…
Если вы требуете тайпхинтинг во всей кодовой базе и всех библиотеках, то вы внезапно получаете статически типизированный язык.Разве для этого не нужны какие-то гарантии от компилятора, что тайп хинты корректные?
Тайп хинтинг в том же php это просто добавление проверок в рантайме во все места, где указан тайпхинт, их корректность до выполнения никак не гарантируется, программа по прежнему падает только в рантайме, плюс всякие неразрешимые с т.з. системы типов преобразования/операции допускаются.
Не получаем. Проверки проводятся в рантайме. Получаем, грубо говоря, строго динамически типизированный язык из слабо динамически типизированного.
Круто. Минусы из двух миров. Надо всё типизировать, но об ошибках не узнаем пока не запустим.
Это же можно считать и плюсом: ошибки в мёртвом коде не требуют исправления :)
Пока он не станет живым в каком-нибудь corner case в 3 часа ночи.
Вы-таки явно заплатили за что-то ненужное…
Был нужен, потом перестал использоваться. Не удалили по каким-то причинам от "не знали" до "страшно трогать"
А вдруг нет? Вдруг только внешне мёртвый, или дергается только раз в год (реальный случай, только для годового отчёта использовался код с "UI" через базу данных)
А вдруг нет?Ну значит когда он дёрнится — тогда и почините. И тесты напишите.
Потому что если «страшно трогать» — то вы всё равно понятия не имеете работает этот код или нет,
реальный случай, только для годового отчёта использовался код с «UI» через базу данныхИ откуда у вас тогда берётся уверенность, что этот годовой отчёт показывает что-то реальное, а не «цены на папайя в Гонолулу» (что, так-то, может кончится не только штрафами, но и посадками, если сильно не повезёт).
Они или не работает, или работает правильно, потому что никто не жалуется.
И откуда у вас тогда берётся уверенность, что этот годовой отчёт показывает
Нет такой уверенности. Когда-то кто-то по просьбе финаналитика написал код, который что-то там в базу выгружает, аналитик его принял, и раз в год запускает его, и лезет в базу.
О чем это говорит? О том, что дизайнеры новых языков внимательно изучают опыт программирования на динамических языках, считая его полезным.Нет, это говорит о том, что фанаты динамических языков никак не могут смириться с тем, что все «новомодные» фичи, которые позволяют Go или Rust не всегда описывать типы появились в ML больше четверти века назад (через OCaml), а совсем даже не из динамических языков.
Да блин, вот прямая цитата: Although we expected C++ programmers to see Go as an alternative, instead most Go programmers come from languages like Python and Ruby. Very few come from C++.
Как видим про динамические языки никто даже не думал!
И вдруг мы видим, что почему-то современные средства разработки начинают потакать лентяям, для чего выкопали даже древние академические разработки.
И с чего бы это?
Так описывать типы — это же очень круто и стильно, тут весь пост про это.Видимо мы о разных постах, особенно учитывая что автор предпочитает таки f# а не джаву.
Впрочем, если игнорировать суть, цепляться за слова, личности, аппелировать к другим языкам, решениям, не разбираясь как и для чего они были приняты, и увиливать от ответов это вся ваша аргументация, диалог смысла не имеет.
Значит случайно так получилось, что программа на статическом языке с автовыводом типов очень похожа на программу на динамическом языке. Но эта "случайность" привлекает разработчиков на динамических языках — им почти не надо менять своих привычек. Она же подтверждает один из основных аргументов против статических языков: типы писать сложнее и дольше, чем их не писать :)
То есть не то, чтобы люди хотят именно динамической типизации — нет, они просто не хотят описывать типы. Думают они всё равно в этих терминах зачастую.
Ты же в старт посте написал чушь
Go, Swift, Rust, в какой-то мере C#
Их разработчики избавили программистов от утомительного аннотирования переменных
и почему то после это появилось аж несколько ответов.
Где, где в этих языках избавились от аннотации типов?
Все только привносят типы в популярные языки JS -> TS, python -> аннотация типов + mypy.
Где, где в этих языках избавились от аннотации типов?
Везде, где это возможно. И компилятор старается выводить типы сам, без явных подсказок.
let a = 5;Где здесь аннотация? И, кстати, угадайте язык по строке.
Смысл статической типизации в том, что тебе помогает компилятор на основе контрактов которые ты заключил.
А смысл динамической проверки типов в том, что тебе помогает система времени исполнения.
И?
И, кстати, угадайте язык по строке.
OCaml, Swift, Rust
Ну как же не помогает, если сообщает об ошибке?
Сообщает, если исполняется тот путь, на котором возникает ошибка несоответствия типов.
А если не исполнится, то и фиг с ней с той ошибкой :)
К несчастью он, ко всему прочему, был ещё и нашим заказчиком… собственно после общения с ним я и стараюсь избегать динамически типизированных языков…
А где-то заказчики считают риски использования динамически типизированных языков приемлемыми. и даже если у заказчика что-то меняется и он начинает хотеть статическую типизацию, то узнав о стоимости перехода просит, например, статанализ динамического языка включить в пайплайны
И, кстати, угадайте язык по строке.
Это точно не go и не c#, так делают в rust, про swift не знаю.
1) От того, то тут явно не указан тип, не значит что он не выведен компилятором, если компилятор по какой-то причине не сможет его вывести он попросит его указать.
В сигнатуре функций без аннотации не обойтись
2)От того, что компилятор выводит тип самостоятельно, это не делает язык динамически типизированным.
1+«1»
динамически типизированный — ошибка во время исполнения, может быть через месяц после запуска программы, когда попадем в эту ветку
статически типизированный — ошибка сразу при запуске/компиляции.
Как по мне, то смысл статической типизации заключается в том, чтобы доказать компилятору, что ты знаешь, что делаешь.
По-моему, языки с динамической типизацией сделаны немного для другого, не для смены типа переменной на лету, а для задания его на лету. Вроде некоторые из них даже и не позволяют менять — тип переменной определяется в момент инициализации и может быть любым, но меняться уже не может.
Язык, где тип переменной определяется в момент её создания и потом не проверяется до запуска программы (хотя мог бы!) — это ошибка дизайна. Зачем вам объединять одновременно огранияения статически типизированных языков и динамически типизированных «в одном флаконе»? Зачем и кому, извините, такой язык нужен?
Момент создания переменной хоть в куче, хоть на стеке — обычно после запуска программы, нет?
В коде прописано объявление переменной и её инициализация. Создаётся она когда до рантайма дело дойдёт.
Ну допустим я исследователь в машинном обучении. 90% кода, который я пишу, имеет срок жизни 1 сутки. Потому что за эти сутки я провёл нужный мне эксперимент, написал отчёт и поехал дальше, ставить новый эксперимент. Типов данных у меня 2: матрица, и функция на матрице. Давай, расскажи мне, как сильно мне нехватает статической типизации :)
Как действительно и то, что статические типы «помогают» компилятору, если программируется нечто тривиальное, что автор описал как:
А я говорю, что описание типов — и есть описание процесса, который ты автоматизируешь. В объектно-ориентированном программировании, в функциональном программировании, в любом другом программировании мы описываем вещи из реального мира, и наш код содержит те знания о них, без которых он не сможет работать.Но по-настоящему «вопрос о типизации» становится интересным при создании, сильного (самообучающегося) искусственного интеллекта. Если существенная часть задачи состоит в формировании (ранее неизвестного системе) типа объекта реального мира и методов взаимодействия с ним, то тут исключительно-статическая типизация языка может серьезно усложнить дело…
Я лишь хотел обозначить область, где со статическими типами могут быть принципиальные трудности…
А в чем ступор?
let dict = decode @(HashMap Text Value) s
А дальше то же, что в динамике
lookup "foo" dictobj["foo"]Как видно, никакой проблемы работать с объектами неизвестной структуры нет. Правда, что полезного можно сделать с такими объектами?!.. Наверняка, у вас есть хотя бы частичные представления о структуре (например, должны присутствовать поля «foo», «bar», опционально «baz», ну и хрен его знает что еще). Никакой проблемы описать тип:
data MyFancyData = MyFancyData
{ foo :: Int
, bar :: Text
, baz :: Maybe Bool
, fields :: HashMap Text Value
}
instance FromJSON MyFancyData where
parseJSON = withObject "MyFancyData" $ \obj ->
MyFancyData <$> (obj .: "foo") <*> (obj .: "bar") <*> (obj .:? "baz") <*> pure obj
instance ToJSON MyFancyData where
toJSON = Object . fields
У вас есть почти бесплатно сериализатор/десериализатор+валидатор, а также доступ ко всем полям исходного JSON объекта. Это элементарно обобщить до
data WithRawObject a =
{ decodedVal :: a
, rawObject :: HashMap Text Value
}
instance (FromJSON a) => FromJSON (WithRawObject a) where
parseJSON = withObject "Raw" \obj ->
WithRawObject <$> parseJSON (Object obj) <*> pure obj
И теперь это будет работать с любым типом, для которого определен JSON десериализатор.
data MyFancyData = MyFancyData
{ foo :: Int
, bar :: Text
, baz :: Maybe Bool
} deriving (Generic, FromJSON)
main = do
bs <- queryAPI
case eitherDecode bs of
Left e -> error e -- Например, поле "foo" отсутствует. Ну или это вообще не JSON
Right (WithRawObject (MyFancyData foo_val bar_val baz_val) fields) ->
doSmth1 foo_val bar_val baz_val
doSmth2 fields
Будучи ссторонником типизации, в большинстве случаев предпочту ТС. Да, я в курсе, что много ошибок ловится на этапе компиляции. И в курсе, что на порядок больше не ловится. Типизированный на 100% код в ТС — это дорогое удовольствие, которое сталкивается с законом Парето. За это спасибо и ограничениям самого ТС, и качеству типов сторонних библиотек. Существует баланс между строгой типизацией и покрытием тестов, которых тоже не бывает слишком много. Но допускаю, что не всем фанбойствующим теоретикам в розовых очках это известно.
Чтоб вам при барахлящем infer приснилось no-any.
За это спасибо и ограничениям самого ТС, и качеству типов сторонних библиотек.
То есть вы пишете об ограничениях одного конкретного используемого вами языка и его экосистеме, но тем не менее обощаете свои выводы на всех.
По-моему, обобщением занимается именно автор — экстраполирует свой однобокий опыт с JS-разработкой и противопоставляет ей TS в качестве панацеи,Автор таки, насколько известно из его статей, не js- и не ts- разработчик, хотя наверняка имеет опыт написания кода на них.
И статья эта вовсе не про js/ts, а как раз про два разных подхода в целом. JS тут скорее в роли наиболее близкого большей доле читателей антагониста.
Выбирая JS в роли наиболее близкого большей доле читателей антагониста, логично ожидать, что по ту сторону баррикад эти читатели будут рассматривать TS. И если он приносит им боль, то всю её они, скорее всего, будут проецировать на статическую типизацию в целом, как минимум в комментариях к такой статье.
И кроме того, на этих языках банально сложнее писать — хуже работают подсказки в IDE, автодополнение и т. п.
На динамических языках зачастую IDE работает ничуть не хуже, выполняя статический анализ кода и, опционально, незначащих для языка аннотаций, но значащих для статанализаторов в принципе. Особенно если на уровне проекта запретить или сильно ограничить динамические "хаки" типа формирование имени переменно, свойства или метода в рантайме без возможности узнать его во время статанализа.
На динамических языках зачастую IDE работает ничуть не хуже, выполняя статический анализ кода
Вы эту сказку рассказывайте кому-нибудь другому. Какое-нибудь банальное:
class Foo:
def __init__(self):
self.x = False
def Process(self, a, b, c):
if a:
self.x = (b, c)
Особенно если на уровне проекта запретить или сильно ограничить динамические «хаки» типа формирование имени переменно, свойства или метода в рантайме без возможности узнать его во время статанализа.Ну это уже другая история. В языках со статической типизацией такое тоже возможно — и да, тут IDE тоже, зачастую, оказываются бессильны.
Так вы тут меняете тип свойства в рантайме. Код типа
class Foo {
private ?Closure $x = null;
public function process($a, $b, $c) {
if ($a) {
$this->x = 7;
}
}
}вполне IDE распознаётся как ошибочный.
Так вы тут меняете тип свойства в рантайме.А для чего ещё мне может потребоваться язык с динамической типизацией, чёрт побери?
Да и не меняю я тут ничего, на самом деле. В C++ это будет как-то примерно так:
class Foo {
public:
void Process(auto a, auto b, auto c) {
if (a) {
x = {b, c};
}
}
private:
std::optional<std::tuple<int, int>> x;
};
Ваш пример всем хорош, кроме одного вопроса: если вы уже указываете типы, всё равно, почему не использовать язык со статической типизацией и, соответственно, проверками до запуска?
А для чего ещё мне может потребоваться язык с динамической типизацией, чёрт побери?
Для определения типов в рантайме и контроля их соответствия.
если вы уже указываете типы, всё равно, почему не использовать язык со статической типизацией и, соответственно, проверками до запуска?
Инфраструктура усложняется. Я вот сейчас курс по Java прохожу для общего развития и задолбался уже писать что-то вроде javac Maun.java && java Main вместо ./main.php
Ну и можно типами пренебречь иногда.
Я вот сейчас курс по Java прохожу для общего развития и задолбался уже писать что-то вроде javac Maun.java && java Main вместо ./main.phpВы уж определитесь — то ли у вас «всемогущая IDE», то ли вы ручками «javac Maun.java» вызываете. А то как-то смешно: как языки были динамические, IDE у вас была, как появилась Java — так IDE, внезапно, куда-то растворилась.
Это если их специально так писать с аннотациями типов (где они возможны — типа как в Python3).
Без этого… я сейчас занимаюсь переводом одного компонента с Python (пока прибиты к Py2) на Java и могу сравнить: при одинаковых условиях (JetBrains'овские бесплатные IDE для обоих) — с Java, например, опознание «у кого же этот метод вызывается» происходит чётко, а с Python — есть с два десятка классов, у которых есть receiveRequest() — и PyCharm беспомощно вываливает «ну ты сам разберись, кто это был...»
Далее, на Python требуется в 2-3 раза больше циклов «написав код, прогнать его через тесты» — с ловлей ошибок типа: тут пришёл dict вместо одной переменной; тут опечатался в названии метода, такого просто нет, и не реализовал нужный; тут несовместимость типов (пришла строка, прибавляю к числу)…
Результат — по оценке навскидку, в данном проекте использование динамически (хоть и в основном строго!) типизированного языка увеличивает время разработки в 2-3 раза. По-моему. тут даже с не сильно продвинутой типизацией Java переход того стоит :)
Ну вот у PHP, даже без использования тайпхинтов, PhpStorm именно с методами вполне нормально работает, если не использовать динамическую генерацию имени вызываемого метода. На Java, как я понимаю, это тоже можно сделать через рефлексию и тоже IDE не справится: и там, и там некоторые методы будет подсвечивать как неиспользуемые.
Ну и внешние статанализаторы PHP можно настроить так, что разница с Java будет минимальна, даже без phpdoc, кроме того, что останется таки возможность залить на прод что-то анализатор сочтёт ошибкой типов.
Для информации, можете посмотреть https://github.com/oroinc/crm/blob/master/src/Oro/Bundle/AccountBundle/Controller/AccountController.php и т. п.
Как по мне, то различия с Java непринципиальны, кроме того что обязательная проверка типов будет в рантайме, ну и заметно быстрее может работать на некоторых задачах.
Динамическая типизация позволяет экономить время и силы, не продумывая и не описывая то, что не нужно, и работать только с тем, что нужно.
Например в js очень удобно фильтровать списки по какому-либо критерию — достаточно только описать сам критерий. Очень лаконично.
Что касается поддержки IDE — да, тут у динамической типизации всегда будет хуже результат, по понятным причинам. Хотя на практике это не особо мешает: современные IDE достаточно глубоко анализируют код + не сложно отладить.
Да, если что-то меняется — что-то отваливается. Без поддержки нельзя. Но это не прихоть программиста — это прихоть бизнеса: бизнес решает, что лучше получить что-то дешево и быстро, и потом понемногу платить за поддержку, чем получить что-то более дорогое и надежное, но с необходимостью ждать дольше. Для бизнеса критично в первую очередь время, во вторую — цена, а надежность и правильная архитектура — в десятую.
В условиях РФ тесты пишут только крупные компании для больших сервисов, либо одиночки для своих проектов.
О полном покрытии речи не идет — лично я только смеюсь с тех тестов, что видел: они чисто для галочки, покрывают только интерфейс, и проверяют только, совпадает ли ответ с ожидаемым или нет, зачастую на одном наборе данных. Такие тесты бессмысленны — что с ними, что без них, одинаково.
Но посмотрим: вроде один высер архитектурных астронавтов (когда лекарство хуже болезни) пережили, Rust показывает как можно решить эту проблему не поджигая дом, чтобы поджарить бифштекс, может и с CSS, со временем, что-нибудь сделают.
Поживём-увидим.
Я бы лайкнул автора, если бы мог.
идиоты
Болваны
ослы
Серьёзно? Серьёзно? Научись уважать Людей, даже если ты прав, а они нет, хамло.
Динамическая типизация — это не инструмент для разработки. Это чепуха (паршивая)