Comments 45
Бежать по токенам в цикле и проверять что это за токены — это не очень быстро. JIT тут не сможет ничего соптимизировать. Самый быстрый метод — сгенерировать JS код и скормить его в new Function. На втором месте — для каждого подвыражения сформировать замыкание завязанное на конкретный набор подвыражений, тогда JIT сможет это неплохо оптимизировать. Пример второго подхода можно глянуть в библиотеке $mol_time, имеющей самый быстрый форматтер среди конкурентов:
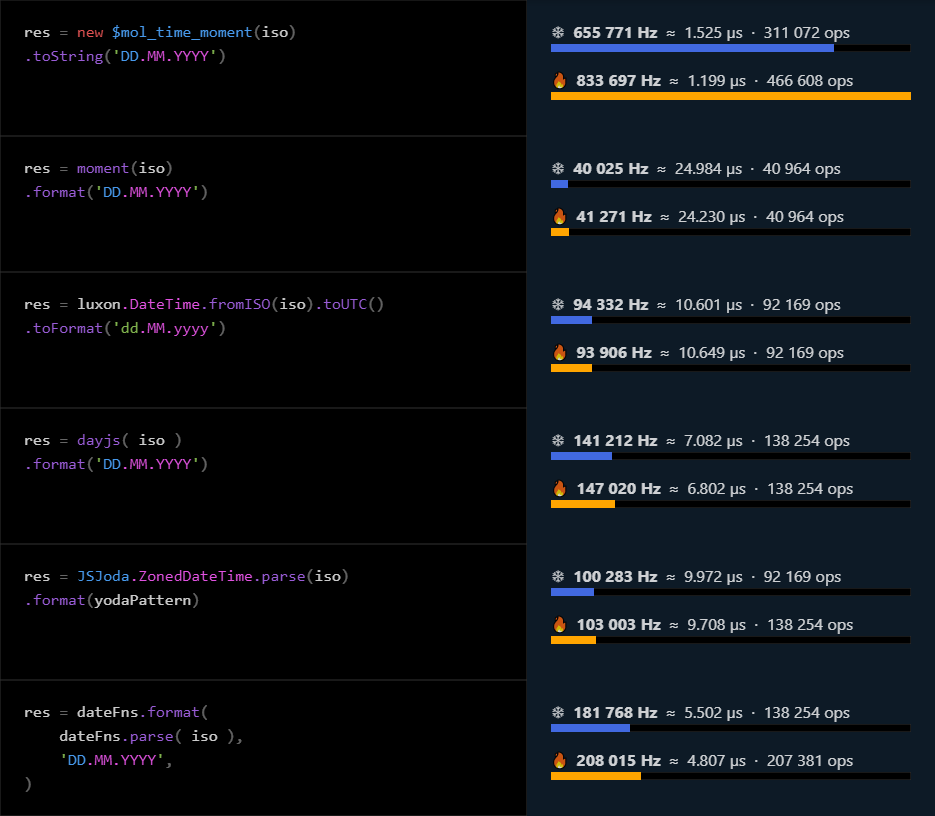
Кроме того, предложенные формульный движок довольно прост в реализации, не требователен к памяти, так как работает с объектами, доступ к которым осуществляется по ссылке, легко расширяем, а также не зависим от сторонних библиотек.
Так я и говорю про множественные вычисления. На одноразовых вычислениях указанные мной оптимизации только замедлят исполнение.
Форматирование времени так-то содержит в себе много нетривиальных вычислений. То, что на выходе строка, а не число, сути не меняет.
Ок, вот простой пример:
// Фабрики выражений
const Const = ( v )=> ()=> v
const Arg = ( index )=> x => x[ index ]
const Sum = ( a , b )=> x => a(x) + b(x)
const Pow = ( a , b )=> x => a(x) ** b(x)
const Square = ( a )=> Pow( a , Const(2) )
const Sqrt = ( a )=> Pow( a , Const(1/2) )
// Собираем формулу
const distance = Sqrt(
Sum(
Square( Arg('x') ),
Square( Arg('y') ),
)
)
// Вычисляем формулу
const result = distance({ x : 3 , y : 4 }) // 5После прогрева JIT получаем ускорение в несколько раз:

Хотя, так ещё быстрее:
// Аргументы: F( X , Y )
const X = (x,y) => x
const Y = (x,y) => y
// Фабрики выражений
const Const = ( v )=> ()=> v
const Sum = ( a , b )=> (x,y) => a(x,y) + b(x,y)
const Pow = ( a , b )=> (x,y) => a(x,y) ** b(x,y)
const Square = ( a )=> Pow( a , Const(2) )
const Sqrt = ( a )=> Pow( a , Const(1/2) )
// Создание формулы
const distance = Sqrt(
Sum(
Square( X ),
Square( Y ),
)
)
// Вычисление формулы
const result = distance( 3 , 4 ) // 5
=round2((A1^2+A2^2)^0.5) Проверить работу формулы при изменении исходных значений можно на bizcalc.ru (формулу нужно будет прописать вручную).
В результате парсинга этой формулы вы можете собрать функцию как я описал выше. А то и вообще можете позволить выполнять произвольный яваскрипт.
На вивальди выдается странный результат:

Как правильно его реализовывать?
4^3^2= (4^3)^2= 4096или
4^3^2= 4^(3^2)= 262144Некоторое время назад столкнулся с таким вопросом, ответа не нашел.
Лучше всего кидать ошибку, чтобы пользователь не ломал голову, а чётко дал понять свои намерения. А так, первый вариант единообразен с остальными операторами, вычисляемыми обычно слева на право. С другой стороны он имеет мало смысла, ибо (4^3)^2 проще записать как 4^(3*2).
Другой вариант — убрать оператор и оставить функцию.
Как я понял у автора понятия ошибок нет, по крайней мере 1/0=0.
С ошибками могут быть проблемы, сейчас при вычислении
if(1;2+2;3+3) считается 2+2 и 3+3, а затем if(1;4;6), если вводить понятие ошибок то какой должен быть результат при if(1;2+3;4/0), 5 или ошибка?В JS, к примеру, 4**3**2 = 4**(3**2), то есть как в «степенной башне».
С другой стороны, расчетчик предназначен для электронных таблиц и разбора Excel-подобных формул, где используется классический математический подход. Кроме того, скобки никогда лишними не бывают (в разумных количествах) — они если и не меняют последовательность расчетов, то могут повысить читаемость формул.
Это не обратная польская запись, в ней 2 + 3 записывается как 2 3 +, а скобки вообще отсутствуют.
Дорогой автор, а в чем смысл публикации? Ваш код демонстрирует нежизнеспособный подход и обратной польской нотацией тут не пахнет.
Ваш код это демонстрация как делать нельзя. Обычно, для решения подобных задач делают токенизатор, парсер и интерпретатор. Ваш код ломается на элементарных вещах вроде « max(1;2--2)» А когда вы начнёте его расширять, то будет вообще мрак. Чтобы не ломался нужно
- Написать лексер, вполне сойдёт лексер на регулярках. На выходе лексера поток токенов (тип токена, значение). Из лексера вылетают лексемы, синтаксические примитивы вроде «имя», «число», «точка с запятой», «строка». На данном этапе никакой семерики нет. У вас есть тип токена — function, это не верно, может быть name, но точно не function.
- Написать грамматику в виде bnf и сделать для неё LL парсер руками или сгенерировать. Сгенерировать сложнее, там нужно больше теории знать. Парсер разбирает поток токенов и выплевывает либо AST, либо код для стековой машины (та сама польская запись), либо сразу интерпретирует.
Кода будет побольше на пару экранов, но все будет работать как часы. Почитайте про LL парсеры, найдите примеры, из полно онлайн. Раз вы делаете что-то вроде Excel, вам без этого никуда.
Что касается обработки ошибок, то согласен, ее пока нет. На текущий момент это было сделано, чтобы упростить код для понимания, когда в него вписывал механизм работы с функциями. Технически же реализовать обработку ошибок довольно просто — в типах токенов добавляется массив ожидаемых типов токенов по ходу движения парсера, которые отслеживаются на стадии разбора формул. По скобкам еще проще — вводятся счетчики открытых и закрытых скобок.
Алгоритм, который Вы предлагаете, вполне имеет право на существование. Просто я реализовал на JS свой алгоритм 20-летней давности на Java, когда еще в Java еще не было нормальной поддержки регулярных выражений, а приходилось работать с отдельными символами строки. Тем не менее, этот алгоритм вроде бы достаточно быстр, но хотелось бы получить объективную сравнительную оценку со стороны, ради которой и сделал эту публикацию.
массив операндов: [1, 1]
массив операторов: ["(", "+"]
2. Функция calcExpression после вычисления возвращает следующие стеки:
массив операндов: [2]
массив операторов: ["("]
3. Функция calc после возврата значения функцией calcExpression выбрасывает из стека открывающую скобку, в результате чего стеки имеют следующий вид:
массив операндов: [2]
массив операторов: []
4. В завершении цикла обхода токенов функция calc снимает из стека операндов последний результат, то есть 2
массив операндов: [1, 2, 3]
массив операторов: ["+", "-"]
Чем не обратная польская запись?
Наверное, тем что в обратной польской записи операции идут за операндами?
1 + 2 - 3 в RPN будет 1 2 + 3 - а вовсе не "массив операндов" и "массив операторов".
Вы упорно продолжаете путать запись и алгоритм — первое это то с чем имеет дело пользователь, второе (ваши массивы и прочие детали) он вообще не видит (и ему всё равно).
Если бы вам нужно было реализовать обработку выражений именно в RPN — то реализация алгоритма уместилась бы в двух десятках строк (но пользователи вас бы проклинали).
В самом начале сказано же — "форма записи математических и логических выражений" — причём тут вообще алгоритмы и способы обработки?
производящую вычисления по обратной польской записи
Это значит — "производит вычисления имея на входе обратную польскую запись" — это не название алгоритма.
Почему важно называть вещи правильно? Да потому что любой, знакомый с RPN и прочитав название вашей статьи решит что речь о том что выражения записаны в RPN (что, собственно, несколько человек уже и отметило).
Вы уже второй, который не видит ее в алгоритме.
Я буду третий (наверное). Потому что, как уже чуть выше сказали, речь про "запись", да и ваша ссылка говорит о способе записи выражений, а у вас обычный инфикс. Как это реализовано внутри (стеки, регистры etc) совершенно не имеет значения с точки зрения нотации.
Кстати, есть неплохая реализация разбора и вычисления выражений на JS, может вам пригодится в качестве источника идей, раз уж интересуетесь этой темой.
Она нужна для упрощения обработки выражений введённых человеком. Алгоритм который будет разбирать и обрабатывать инфиксную запись потребует гораздо больше ресурсов (памяти и кода) чем алгоритм который обрабатывает обратную польскую запись — это единственная её польза, правда, ценой того что на человека перекладывается тяжкое бремя расстановки операндов и операций в нужной последовательности.
В калькуляторах (старых) были очень ограниченные ресурсы, именно по этой причине старались всё упростить — вот собственно и вся история.
Вы же пытаетесь называть стековую (и то не совсем — у вас массивы, которые их эмулируют) обработку "обратной польской нотацией" — хотя стек он и есть стек, он появился до того как появилась RPN, более того, она появилась как раз по той простой причине что прекрасно "ложилась" на стековую архитектуру, а не наоборот.
Кстати, в репозитории, на который Вы дали ссылку, функция evaluate также выполняется на стеке в виде массива, плюс там используются временные переменные, которых у меня нет, так как два стека передаются по ссылке в виде аргументов функции вычисления промежуточных результатов, в которой и обрабатываются. Хотя довольно интересно сравнить эту и мою реализацию на больших объемах вычислений.
При этом не понятно, для чего человек должен сам переводить запись формул из инфиксной в постфиксную форму, если машина на стеках это делает просто не задумываясь?
функция evaluate также выполняется на стеке в виде массива
Да, безусловно, почти все разборщики выражений используют стеки в том или ином виде (прямо или через массивы), но это всё не имеет ровно никакого отношения к RPN, в принципе, по причинам которые я уже описал несколько раз в других ответах.
для чего человек должен сам переводить запись формул из инфиксной в постфиксную форму
Потому что когда-то были калькуляторы (и другие вычислительные устройства) которые не понимали инфиксной формы. На самом деле они всё ещё есть, в ряде очень специфичных областей, и есть даже языки программирования с RPN записью и стековой архитектурой, к которым относится и PostScript.
"… который применяется для разбора математических выражений, представленных в инфиксной нотации. Может быть использован для получения вывода в виде обратной польской нотации или в виде абстрактного синтаксического дерева.."
Только у вас на два стека, данных и команд, хотя можно обойтись одним.
Тоже делал на два стека, тогда казалось, что так логичнее.
Все-же я не понял, это просто эксперимент или вы делаете рабочий продукт? если последнее почему не взять что-нибудь готовое и куда более мощное, хотя-бы math-js?
С другой стороны, в рамках проекта BizCalc также происходит переосмысление некоторых концепций, которые сейчас реализованы в проекте JetCalc, в котором я участвую только в части постановки и тестирования по предметной области и в части организации структуры базы данных.
Ну и не следует упускать из внимания тот фактор, что большой объем кода потенциально может нести и большое количество уязвимостей. И то, что код открыт, совершенно не означает, что даже крутой профессионал способен быстро найти потенциальные уязвимости в таком коде.
Формульный движок с обратной польской нотацией на JavaScript