Comments 43
И, о ужас, уже пятое сообщение анализатора оказалось реальной ошибкой! А также седьмое, девятое, двенадцатое и пятнадцатое
Вот в этом месте пора заканчивать с анализом качества кода и искренне перекреститься.
«Тебе что, заняться нечем? Ты всю команду хочешь на три недели отвлечь для правки ошибок, а у нас релиз через месяц! Ну и что, что ошибки реальные? Жили как-то с ними и ничего. Да, я понимаю, что было бы здорово не делать ошибки в новом коде. Ну так вы и не делайте! А старый код трогать не позволю! Он уже оттестирован и клиенты за него заплатили. А кто за три недели работы команды платить будет? Так что не будем мы покупать анализатор, да и код старый трогать не будем. А у тебя видимо текущие задачи кончились. Так мы сейчас тебе подкинем. И чтобы завтра готово было!»
Это очень плохая компания. С глупым и недальновидным руководителем. Сэкономит три недели сейчас — потратит десять потом, когда все внезапно на ровном месте сломается. Еще и клиентов растеряет из-за этого.
Это вполне реальная компания. Баги будут всегда, и их починка уже есть в плане, также как и реализация новых функций. Если до сих пор клиент не заметил баг и не разнес вас в пух и прах, то этот баг не критичен. Даже оптимизация не стоит 3 недель всей команды, если это не явное конкурентное преимущество. Стоит разделять бизнес цели и цели разработчиков. Если вы запускаете шаттл или делаете рентгеновское оборудование, то у вас в контракте прописан уровень качества и вы ЗАРАНЕЕ предусматриваете проверку качества кода. Если ваше приложение рисует картинки ASCII-артом, то вам не важно что в ней неверная проверка условия или ненужные вычисления. Вы просто сделаете работу которая никому не нужна и за которую вам не платят, когда те же силы можно было потратить с пользой.
Единственное замечание по поводу дальновидности описано в статье и звучит просто: «у нас нет 3 недель всей команды, но мы можем подключить анализатор, чтобы улучшить качество создания нового кода, и можем постепенно заложить прочистку старого кода, разбив ее на мелкие части»
Единственное замечание по поводу дальновидности описано в статье и звучит просто: «у нас нет 3 недель всей команды, но мы можем подключить анализатор, чтобы улучшить качество создания нового кода, и можем постепенно заложить прочистку старого кода, разбив ее на мелкие части»
Вы прямо на ровном месте предлагаете двойные стандарты, исходя из того, что код в рентгене должен быть, по не понятной мне причине, качественнее чем в коде рисователя картинок. Может так случиться что в рентгене опенсорс, а за рисователя заплатили денег.
В общем случае подход не верен априори. Разработчик не должен допускать плохого кода даже в мелочах, это должно войти в привычку, иначе плохой код будет всплывать в самых неожиданных местах, в пятницу вечером, перед релизом.
В общем случае подход не верен априори. Разработчик не должен допускать плохого кода даже в мелочах, это должно войти в привычку, иначе плохой код будет всплывать в самых неожиданных местах, в пятницу вечером, перед релизом.
Нужно понимать, что если, что-то сломается в рентген аппарате, то ценой ошибки могут быть множество человеческих жизней. Если сломается код ASCII-рисовалки картинок, кто-то может расстроиться, если вообще заметит.
Это называется ценой ошибки. Так вот, надеюсь, вы поймёте, почему код ПО рентгена должен быть качественнее, чем рисовалки. Если это конечно не МРТ-рисовалка. Да даже если и она.
Ну и картинку в тему «пятницу вечером, перед релизом»:
Кстати, для таких случаев должны быть процедуры. Потому что баг может вылезти не зависимо от того, насколько качественно, как вам кажется, написан код.
Это называется ценой ошибки. Так вот, надеюсь, вы поймёте, почему код ПО рентгена должен быть качественнее, чем рисовалки. Если это конечно не МРТ-рисовалка. Да даже если и она.
Ну и картинку в тему «пятницу вечером, перед релизом»:

Кстати, для таких случаев должны быть процедуры. Потому что баг может вылезти не зависимо от того, насколько качественно, как вам кажется, написан код.
Забавно вы так рассуждаете. Вспомните программу, которая просрала за несколько секунд весь бизнес, скупив «не правильные акции».
Важно быстро понять, что из тысяч старых ошибок действительно критично. Вот я недавно статическим анализом нашёл старую ошибку в коде проекта компании, над которым не работаю, и ткнул носом разработчиков. Приложение вроде для муниципальных властей, там где-то формировался отчёт по половому и возрастному распределению людей определённой категории (льготников каких-то или вроде того). Из-за кривой цепочки условий получалось, что в городе нет ни одной женщины в возрасте 55-59 лет (они ошибочно попадали в категорию 18-54). Получается, что все как-то жили с этим багом и никто не замечал. Но начальство того проекта всё равно было довольно, когда я им указал. Тут ошибка такая, что последствия есть и сразу, а не возникают в редких случаях при соблюдении ряда условий.
Ваш подход правильный конечно. Но это подход программиста. А может быть и подход менеджера, для которого старые ошибки в коде — не первоочередная проблема. Это и нужно осознать. Тут важнее то, что новый код можно делать с новым качеством.
Вполне реально. Исправлять древний код может оказаться очень накладно. Во первых, мало кто из команды будет «в теме», как он работает. Исправление может нарушить функционал (неправильная версия работала, с правильная перестала) — т.е. надо все тестировать.
А есть, или планируется, возможность потом каким-либо образом прорабатывать эту suppress базу? Ну например, вытащить оттуда все ошибки в каком то определенном файле/классе/модуле, на свет божий, при этом оставив все остальное под suppress'ом, таким образом можно было бы исправлять старый код малыми порциями в свободное время.
Да, можно. Нужно открыть SolutionName_WithSuppressedMessages.plog, где содержатся все сообщения. Далее в фильтрах указываем файл/проект. И потихоньку правим.
Думаю, одной картинки будет достаточно, чтобы пояснить работу с фильтрами.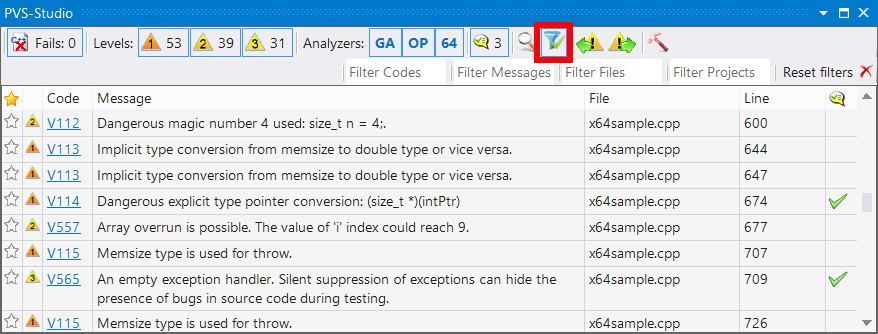

Да, это есть и это сделано именно для того, чтобы по частям выправлять старый код
такой вопрос, а как анализатор справляется с кодом написанным на Managed C++ / Native C++ в соотношении 20/80.
На данный момент больше интересует Managed C++ сторона так как Native C++ часть уже работает больше 10 лет и по идеи все что можно уже нашли и исправили.
На данный момент больше интересует Managed C++ сторона так как Native C++ часть уже работает больше 10 лет и по идеи все что можно уже нашли и исправили.
Есть опыт работы с конкурентом, которого вы должны хорошо знать, в рамках Embedded Linux по требованиям PCI-DSS v4 (да, на сайте пока только v3). Конкурента выбирали долго, сравнивая практически все возможные открытые и коммерческие предложения.
У них всё стекается на общий сервер с ± вменяемым веб-фронтендом и десктопным клиентом. Соответственно разработчики могут делать свои потоки для рабочих билдов, а так же билд-сервера могут пихать в потоки для каждой стабильной ветки проекта. При первом проходе, у нас нашлось около 9K проблем, включая малозначительные. Хватило менее недели коллективных усилий архитекторов чтобы рассортировать ложные срабатывания. Если бы мы возились с файлами, а не централизованной базой с удобным интерфейсом, это определённо заняло бы больше времени. При повторных проходах система сама определяет встречалась ли та же самая проблема, либо появилась новая.
Система была достаточно умной чтобы связывать проблемы на разных потоках. Т. е. не нужно рассортировывать заново всё для каждой новой стабильной ветки проекта или не воспроизводимых локальных сборок — новые проблемы были сразу видны.
Для завоевания корпоративного рынка вам жизненно необходимо разработать схожий обособленный проект. Помимо хардкорных вещей для разработчиков, тем самым руководителям, которые выполняют контракты, нужны ещё и красивые отчёты с историей по релизам для разнообразных сертификаций. Далее уже ползут интеграции с системами централизованных сборок, баг-трекинга, управления требованиями и т.п.
Не сочтите за критику. Это мой отзыв как профессионального пользователя различным утилит статического и динамического анализа.
У них всё стекается на общий сервер с ± вменяемым веб-фронтендом и десктопным клиентом. Соответственно разработчики могут делать свои потоки для рабочих билдов, а так же билд-сервера могут пихать в потоки для каждой стабильной ветки проекта. При первом проходе, у нас нашлось около 9K проблем, включая малозначительные. Хватило менее недели коллективных усилий архитекторов чтобы рассортировать ложные срабатывания. Если бы мы возились с файлами, а не централизованной базой с удобным интерфейсом, это определённо заняло бы больше времени. При повторных проходах система сама определяет встречалась ли та же самая проблема, либо появилась новая.
Система была достаточно умной чтобы связывать проблемы на разных потоках. Т. е. не нужно рассортировывать заново всё для каждой новой стабильной ветки проекта или не воспроизводимых локальных сборок — новые проблемы были сразу видны.
Для завоевания корпоративного рынка вам жизненно необходимо разработать схожий обособленный проект. Помимо хардкорных вещей для разработчиков, тем самым руководителям, которые выполняют контракты, нужны ещё и красивые отчёты с историей по релизам для разнообразных сертификаций. Далее уже ползут интеграции с системами централизованных сборок, баг-трекинга, управления требованиями и т.п.
Не сочтите за критику. Это мой отзыв как профессионального пользователя различным утилит статического и динамического анализа.
Мы учитываем код сообщения, текст текущей строки кода, а также текст предыдущей и следующей строк кода.
Я правильно понимаю, что если в своем проекте один раз подавить всё, а потом в какую-то новую функцию копипастнуть старый код с ошибкой, то анализатор промолчит?
А ещё интересно, если переименовать файл исходного текста?
В FindBugs (а также в Jenkins-плагине к нему) аналогичный механизм идентифицирует ошибки по классу и методу (с полной сигнатурой), а также по полной аннотации ошибки. Например, если ошибка в возможном NullPointerException при разыменовании переменной x, то переименование этой переменной приведёт к изменению аннотации, и баг будет считаться новым. Номера строк и контекст вокруг ошибки не учитываются. В принципе тоже вполне удобно работает. При копипасте в другой метод или класс ошибка будет считаться новой.
В FindBugs (а также в Jenkins-плагине к нему) аналогичный механизм идентифицирует ошибки по классу и методу (с полной сигнатурой), а также по полной аннотации ошибки. Например, если ошибка в возможном NullPointerException при разыменовании переменной x, то переименование этой переменной приведёт к изменению аннотации, и баг будет считаться новым. Номера строк и контекст вокруг ошибки не учитываются. В принципе тоже вполне удобно работает. При копипасте в другой метод или класс ошибка будет считаться новой.
Нет, не промолчит. Учитываются еще и имена файлов, где найден код.
Можете в двух словах сказать, почему бы тогда было не учитывать именования классов/функций? Чем хуже?
почему бы тогда было не учитывать именования классов/функций? Чем хуже?
Тем, что это надо было бы программировать. А имена файлов — уже были готовы. То есть этот механизм реализован на основе того, что уже выдает анализатор в лог (классы/функции не выдаются). Тесты показали, что он отлично справляется. В том числе мы тестировали на проекте в 300Mb исходников (9 млн строк кода), в который ежедневно коммитят 50 разработчиков. Никаких ложных срабатываний системы подавления не было.
В плане борьбы с непонимающим начальством удобнее, конечно, бесплатные инструменты. Их можно интегрировать в систему сборки тайком от начальства. И если текущая задача надоела или просто хочется переключиться, можно полчасика посидеть и поковырять старые баги.
Да, но бесплатные инструменты в большинстве случаев не позволяют игнорировать старые ошибки. А без этого часто легкое внедрение получается не возможно.
Но я как разработчик инструмента статического анализа горячо приветствую наличие бесплатные инструментов! Люди узнают о технологии и рано или поздно приходят к производителям коммерческих инструментов.
В частности я очень рад наличию и /analyze в Visual Studio, и clang analyzer — все это обучает программистов, что такие инструменты есть. А кто дозревает до регулярного их использования, как правило нуждаются в дополнительных возможностях.
Но я как разработчик инструмента статического анализа горячо приветствую наличие бесплатные инструментов! Люди узнают о технологии и рано или поздно приходят к производителям коммерческих инструментов.
В частности я очень рад наличию и /analyze в Visual Studio, и clang analyzer — все это обучает программистов, что такие инструменты есть. А кто дозревает до регулярного их использования, как правило нуждаются в дополнительных возможностях.
Для информации: Как использовать PVS-Studio бесплатно.
Удаляются ли «пропавшие» ошибки из списка suppressed?
Чтобы отловить момент «программист пофиксил баг, а потом через N недель кто-то его вернул, но анализатор на это не поругался».
Чтобы отловить момент «программист пофиксил баг, а потом через N недель кто-то его вернул, но анализатор на это не поругался».
Нет. Не удаляются. Но проблемы мне кажется здесь нет. Маловероятно, что кто-то вернёт баг именно туда, где он был. А если баг будет рядом, то это уже другой баг. Если кто-то вернёт всё обратно, то это уже скорее административные проблемы. Как это кто-то откатил чужие правки?
P.S. В принципе никто не мешает перегенерировать базу. И тогда ошибка не останется незамеченной.
P.S. В принципе никто не мешает перегенерировать базу. И тогда ошибка не останется незамеченной.
Прошу прощения за оффтоп, такой вопрос возник по CppCat и PVS-studio, можно ли с их помощью проверить файлы проекта не компилируя сам проект и будет ли при этом разница при анализе исходных кодов?
Вопрос не понятен. Можно проверить, не компилируя. Но что-бы проверить, проект должен быть компилируемым. Иначе результат будет так себе.
Прошу уточнить вопрос.
Прошу уточнить вопрос.
Проект создан в среде IAR (или KEIL) для микроконтроллеров.
Соответственно в среде Visual Studio он компилироваться не будет, так как используются специфичные для данного семейства микроконтроллеров заголовочные файлы.
А вот просто добавить исходные файлы в Visual Studio, создав консольное приложение и проверить проект без компиляции было бы очень удобно.
Соответственно в среде Visual Studio он компилироваться не будет, так как используются специфичные для данного семейства микроконтроллеров заголовочные файлы.
А вот просто добавить исходные файлы в Visual Studio, создав консольное приложение и проверить проект без компиляции было бы очень удобно.
«Просто добавить» не получится, потому что нужны заголовочные файлы. Зато, насколько я помню, можно «просто взять» выходные файлы препроцессора и проверить их без Visual Studio.
Скачал CppCat, создал новое консольное приложение в Visual Studio, добавил исходники проекта для Cortex4, попробовал скомпилировать проект в студии, выдало кучу ошибок (что ожидаемо), запустил проверку CppCat вручную, нашел несколько ошибок.
Вероятно такой способ вполне рабочий, единственный вопрос, который мучает, насколько полная происходит проверка файлов без компиляции самого проекта в Visual Studio. Точнее, влияет ли отсутствие или наличие файлов, которые создает сама студия во время компиляции.
Вероятно такой способ вполне рабочий, единственный вопрос, который мучает, насколько полная происходит проверка файлов без компиляции самого проекта в Visual Studio. Точнее, влияет ли отсутствие или наличие файлов, которые создает сама студия во время компиляции.
Набор файлов проверить не удастся. Можно попробовать сгенерировать и проверить *.i файлы в Standalone версии (пример). Но анализатор не готов к особенностям этого компилятора и результат может быть не очень хорош. Как вариант попробуйте Cppcheck.
Предлагаем попробовать новый релиз PVS-Studio 6.22:
- Появилась поддержка ARM Compiler 5 и ARM Compiler 6 в составе среды Keil uVision 5.
- Компиляторов ARM Compiler 5 и ARM Compiler 6 в составе среды Keil DS-MDK.
- Мы поддерживаем IAR C/C++ Compiler for ARM в составе среды IAR Embedded Workbench.
Полсотни комментариев на тему «Зачем пишутся программы». Ответов — сколько и должностей.
Для Прожектера — зарабатывание денег. ДосрАчно сданный код — его премия. Сложно найти руководителя, который от них откажется. Зато потом, когда баг все-таки всплывает (и, по закону Мерфи, это происходит в самый удачный момент), начинается поиск крайних, кроме него самого, любимого.
Для Проектанта — все зависит от того, с кем работаешь. Есть коллективы, где работают от забора до обеда. Есть и такие, где ищут 68 причин, почему что-то не сделано (например, не куплен новый коврик для мышки — по старому она плохо елозит/испачкался/расцветка не по фэн-шую и т.д.). Есть и работающие «в стол» — авось пригодится (их мало).
В любом случае, ошибки ВСЕГДА обходятся дорого. И не всегда — только деньгами.
Для Прожектера — зарабатывание денег. ДосрАчно сданный код — его премия. Сложно найти руководителя, который от них откажется. Зато потом, когда баг все-таки всплывает (и, по закону Мерфи, это происходит в самый удачный момент), начинается поиск крайних, кроме него самого, любимого.
Для Проектанта — все зависит от того, с кем работаешь. Есть коллективы, где работают от забора до обеда. Есть и такие, где ищут 68 причин, почему что-то не сделано (например, не куплен новый коврик для мышки — по старому она плохо елозит/испачкался/расцветка не по фэн-шую и т.д.). Есть и работающие «в стол» — авось пригодится (их мало).
В любом случае, ошибки ВСЕГДА обходятся дорого. И не всегда — только деньгами.
Все круто, но мой опыт работы со статическим анализатором (не PVS) был не такой радужный, как описано в начале статьи.
В коде (больше 10мб) на C# было найдено около 3000 ошибок. Просмотрели первые 100 — все false positives. Потом еще 300 через 3 — аналогично. В итоге не было найдено НИ ОДНОЙ реальной ошибки. Было найдено несколько ошибок, которые могли бы стать проблемой, но с исчезающей вероятностью. К сожалению, пришлось отказаться.
Интересно узнать мнение автора — C# менее подвержен ошибкам (более высокий уровень абстракции, сборщик мусора, функциональные расширения, поддержка await/async и прочих многопоточных примитивов на уровне языка), или просто анализаторы для него менее распространены. Есть ли планы по анализу C# кода?
В коде (больше 10мб) на C# было найдено около 3000 ошибок. Просмотрели первые 100 — все false positives. Потом еще 300 через 3 — аналогично. В итоге не было найдено НИ ОДНОЙ реальной ошибки. Было найдено несколько ошибок, которые могли бы стать проблемой, но с исчезающей вероятностью. К сожалению, пришлось отказаться.
Интересно узнать мнение автора — C# менее подвержен ошибкам (более высокий уровень абстракции, сборщик мусора, функциональные расширения, поддержка await/async и прочих многопоточных примитивов на уровне языка), или просто анализаторы для него менее распространены. Есть ли планы по анализу C# кода?
Ну если реально просмотрели 100 сообщений и все ложные, то либо инструмент совсем плох, либо не настроен. В целом C# намного лучше, чем C++, но и в C# много чего можно найти статическим анализом.
Что касается наших планов, то у нас конечно с C++ на 10 лет дел в todo записано. Но мы посматриваем на Roslyn от Microsoft и может быть когда-нибудь и попробуем что-то предложить для этой сферы.
Что касается наших планов, то у нас конечно с C++ на 10 лет дел в todo записано. Но мы посматриваем на Roslyn от Microsoft и может быть когда-нибудь и попробуем что-то предложить для этой сферы.
инструмент был от Coverity, в который перешел Eric Lippert, один из главных разработчиков Roslyn.
Они тоже показывали много примеров на С++, однако с C# какая-то пустота, вот и интересно, почему.
Они тоже показывали много примеров на С++, однако с C# какая-то пустота, вот и интересно, почему.
Sign up to leave a comment.
Как внедрить статический анализ в проект, в котором более 10 мегабайт исходного кода?