Comments 62
С другой стороны, а часто ли вам нужно понимание, как конкретно работает функция from_chars, при условии, что там нет багов и не нужно это дебажить?
Ну сам алгоритм, допустим, понятен.
Откуда вывод про ограничения именно на парсинге — не очень.
Бенчмарки стандартных стримов и strtod есть, а где результат с оптимизациями?
Ведь стрим и функция имеют чуть больше логики и гарантий, чем цикл с битовой магией.
Сколько кода нужно написать, что с платформами, багами?
Опять же, никто не спорит о возможности обогнать стандартную библиотеку и её суб-оптимальности, но хотелось бы цифр и ресурсов на поддержку с интеграцией подобных вещей.
Жёсткие диски запросто обеспечивают последовательное чтение со скоростью в несколько ГБ/с,
простите, а вы не могли бы указать, что это за диски такие?
или имеете в виду топовые NVMe SSD, а не шпиндельные HDD?
Почему обязательно топовые? Первый нагуглившийся Samsung 970 EVO выдаёт 3.4 ГБ/с и стоит всего 13т.р. за 1ТБ. 3.4 — вполне себе "несколько". А топовые уже добрались до 7ГБ/с.
Ну то есть надо было с оговоркой писать, что жесткие диски именно SSD, а не HDD, причем подключаемые именно по NVME (т.к. у SATA SSD скоростей выше 500-600 МБ/c я что-то не встречал). Слово "запросто" было точно лишнее.
подключаемые именно по NVME
Нет, не именно. OCZ RevoDrive 3 X2, например, обеспечивает 1.5 ГБ/c при последовательном чтении, но при этом ни в каком месте не является NVMe. Поступил в продажу 10 лет назад.
Слово «запросто» было точно лишнее.
Привет из 2021 года. Тут можно запросто пойти в любой компьютерный магазин и запросто купить NVMe SSD. Это не какая-то экзотика, доступная только избранным или за чемодан денег.
Ок, да, формально вы правы и ничего в форме диска в SSD нет и это слово использовать некорректно. С другой стороны — а какой термин в русском языке эквивалентен "hard drive"?
Собирательный термин — накопитель, или storage device.
С другой стороны — а какой термин в русском языке эквивалентен «hard drive»?Думаю, что жёсткий диск
Наверное имелось в виду PCIe так как NVMe это спецификация а не интерфейс, но в современных реалиях почти гвоздями прибит к PCIe, а упомянутый RevoDrive напрямую на PCIe вешался, оттуда и 1.5 GB/s.
Речь о софте для высокоскростного парсинга, который явно гоняют на серверах, а не домашних ноутбуках. Еще 10 лет назад можно было набить 2U сервер 24 дисками sff sas, каждый давал 180-200 МБ/с а весь массив запросто давал 3-4 ГБ/с. Сейчас скорости намного выше.
А вот обычные текстовый файлы (особенно большие) могут содержать ошибки, появление которых может стать внезапным сюрпризом.
ps: Cжатые текстовый файлы можно прасить быстрее, т.к. требуется на порядок меньшая пропускная способность дисковой подсистемы для того-же объёма данных. И плюс есть хотя бы контрольная сумма.
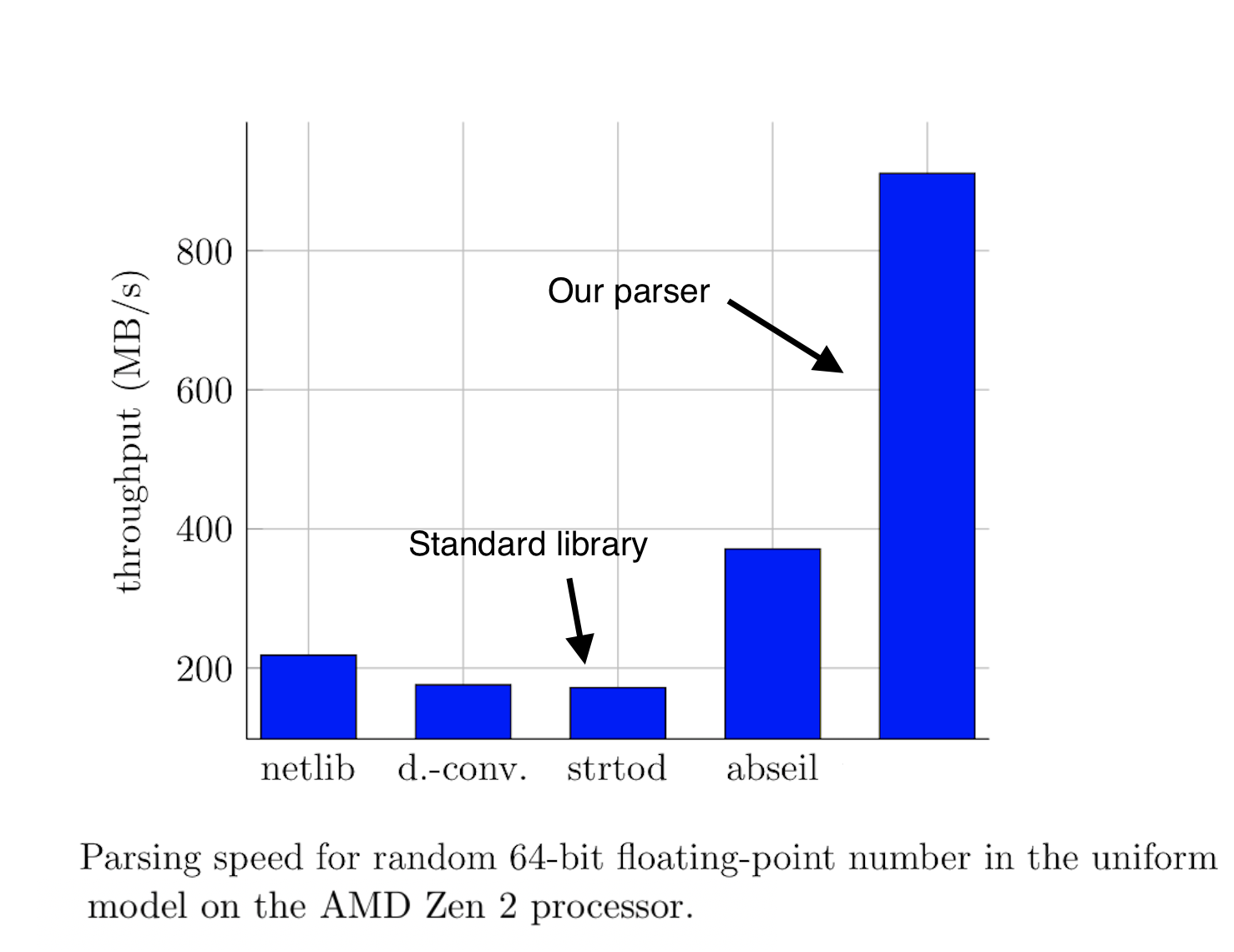
The guarantee that std::from_chars can recover every floating-point value formatted by std::to_chars exactly is only provided if both functions are from the same implementation.
Кто-нибудь может объяснить, почему так?
Кто-нибудь может объяснить, почему так?стандарт гарантирует что для любого double значения преобразование to_chars и последующее from_chars всегда вернет ровно то же самое число. Так что либо реализация автора не дает такой гарантии, либо он додумался до чего-то, до чего уже несколько лет не могли додуматься разработчики компиляторов. Ну или последний вариант, на который бы я поставил — автор сравнивал парсинг с std::chars_format::general, который предполагает что в double числе может быть экспонента. А обработка этого случая уже может и замедлить код.
Upd: посмотрел код бенчмарка (ссылка с гитхаба автора). Действительно, автор использует формат по умолчанию, который и есть std::chars_format::general. Ему бы стоило замерить с std::chars_format::fixed, и уже потом заявлять о 7-кратном приросте.
Upd2: перепроверил, у автора тоже параметризуется формат, в полной аналогии со стандартным. Возвращаемся к первым двум гипотезам.
std::from_chars и std::to_chars, а у ускоренного from_chars есть только одна реализация, содержащая только одну эту функцию, так что к ней замечание «if both functions are from the same implementation» никак не могло бы относиться.Разработчики компиляторов в меньшей степени, чем автор, интересуются платформо-зависимыми оптимизациями, так что ничего удивительного.
Есть еще вот инструкции старинные: http://www.hugi.scene.org/online/coding/hugi%2017%20-%20coaax.htm (для полноты топика) — но, скорее всего, с ними только медленнее будет, уж очень они старые.
Так зачем сдерживать себя и не попробовать?
Чтобы не тратить $5000 на реализацию оптимизации, которая сэкономит $50.
Именно поэтому автор начинает с анализа скорости парсинга относительно скорости диска: если разница в сто раз, то ускорение парсера имеет большой практический смысл. Если разница в два-три раза, то это уже больше спортивный интерес.
Вот если векторизацию этого случая встроить прямо в GCC, тогда она может окупиться, даже если конкретно на этой задаче сэкономит очень мало.
Или, почему используется десятичный формат записи double, а не шестнадцатиричный, в котором десятичный парсинг остаётся только для порядка.
Но так как могут быть тонны внешних причин, на которые нельзя влиять — задача вполне достойная.
А еще у меня был заказчик из эквадора. У него таксопарк. Каждое такси три раза в секуду шлет отчет о состянии авто, вместе с GPS координатами. Объем пакета — где-то 10Кб. Когда количество машин прибилизилось к сотни, появились лаги парсера. В общем, там пришлось слегка поковыряться, но я гарантировал, что теперь проблемы возникнут когда количетсво машин приблизится к десятку тысяч :-)
На вопрос «а какого [ПИП] надо три раза в секуду»? Мне хозяин ответил: «Стреляют. Надо успеть разблокировать оружие до того, как водителя убьют».
Лайфхак: как спарсить гигабайт double-ов в секунду