Comments 20
А почему не рассматривались альтернативные варианты?
Например рекурсивный с костылями. При обновлении дополнительная работа, но при выборке приличное ускорение простым запросом
Например рекурсивный с костылями. При обновлении дополнительная работа, но при выборке приличное ускорение простым запросом
Это отдельная большая тема для другой статьи — в каких случаях как эффективнее «материализовывать» иерархию, как модифицировать и как выбирать потом.
Т.е. куча страданий и потраченного времени программиста, лишь бы не вводить Lineage или какой-нить Nested set? Которые кучу проблем смогли бы решить гораздо проще.
Которые кучу проблем смогли бы решить гораздо проще.И создать рядом кучу других проблем.
Возьмем классический пример прямо из wiki про Nested Set:
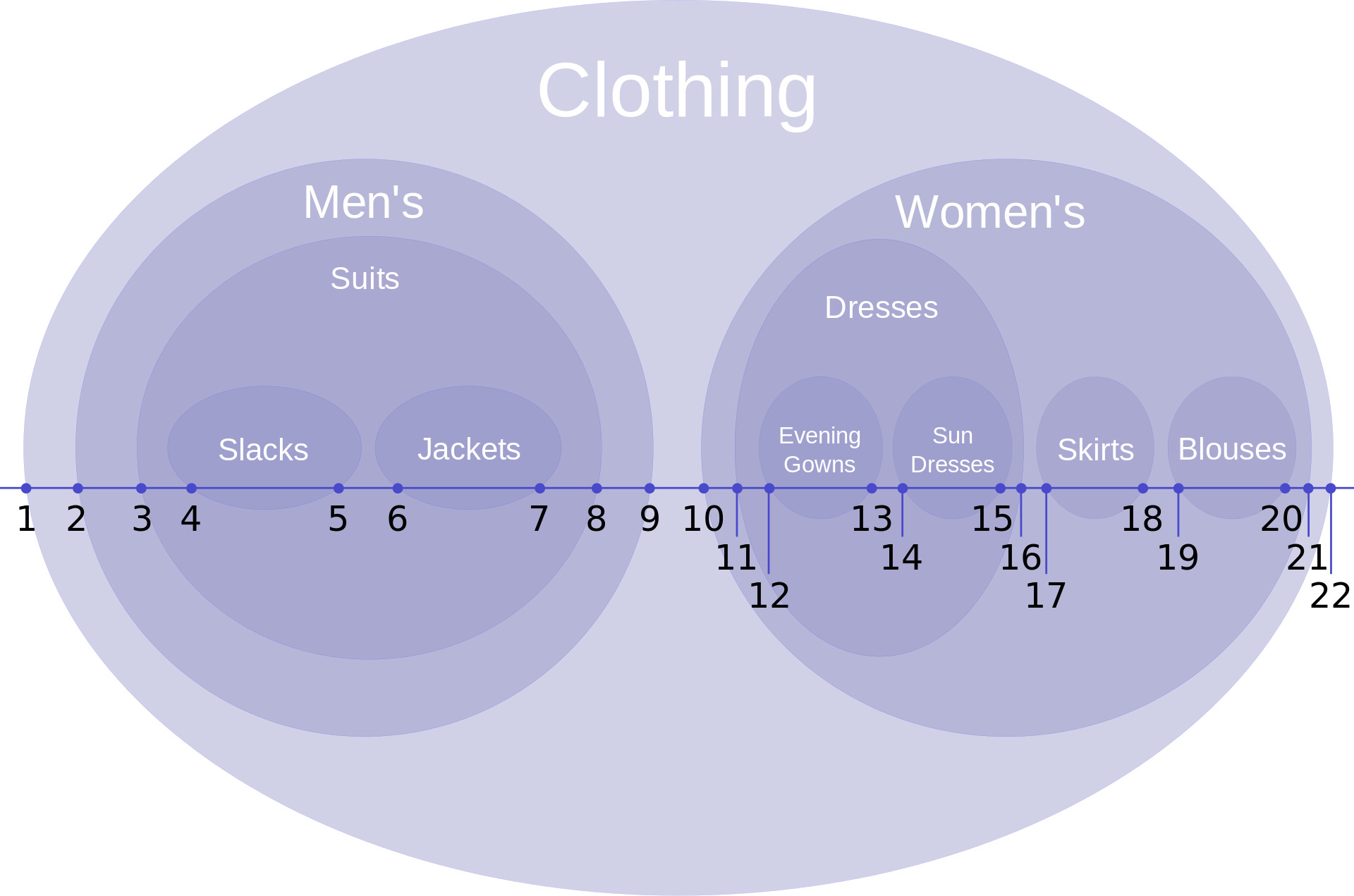
А теперь попробуем создать еще одну новую категорию внутри Jackets [6:7]…
Ой, надо все переупорядочивать, если ID целочисленные.
Ой, а на эти ID в иерархичном словаре что-то внешнее при этом ссылалось.
То есть если иерархия нестатична, то Nested Set не самая подходящая модель.
Кирилл, твой ответ выглядит так, что ты пошёл гуглить что такое Nested Set и взял первую ссылку из гугла на википедию, и из этого сделал выводы :)
Отвечаю:
1. Да, Nested сет имеет более затратные операции изменения иерархии, при этом сильно упрощая операции поиска. Если у вас постоянная текучка кадров, что операции вставки становятся неприлично тяжёлыми, то стоило бы упомянуть это в задаче. Т.к. большинство иерархий достаточно редко меняются.
2. В Nested Set надо переупорядочивать только Left/Right указатели, Id — это отдельное поле, которое трогать не надо.
Отвечаю:
1. Да, Nested сет имеет более затратные операции изменения иерархии, при этом сильно упрощая операции поиска. Если у вас постоянная текучка кадров, что операции вставки становятся неприлично тяжёлыми, то стоило бы упомянуть это в задаче. Т.к. большинство иерархий достаточно редко меняются.
2. В Nested Set надо переупорядочивать только Left/Right указатели, Id — это отдельное поле, которое трогать не надо.
Так я ровно про это и написал выше:
Если мы заранее не знаем на 100%, как часто будет меняться структура, как много будет в ней элементов и т.д., то самый простой вариант — именно через ID предка.
в каких случаях как эффективнее «материализовывать» иерархию, как модифицировать и как выбирать потом
Если мы заранее не знаем на 100%, как часто будет меняться структура, как много будет в ней элементов и т.д., то самый простой вариант — именно через ID предка.
А как вы разрабатываете? Т.е. задача формулируется максимально абстрактно, и делается максимально абстрактно? Если вы настолько не знаете требования к своей же функциональности.
Через ID предка — самый простой вариант, но самый неэффективный. И оптимизировать его, вместо использования более логичных структур — интересное, но не очень полезное занятие.
Небольшую иерархию можно вообще засосать в память и не париться ни о чём. А если иерархия с 10 млн элементами, то стоит всё-таки подумать о конретных требованиях к задаче.
Конечно же, если статья написана с целью рассказать про CTE и рекурсивные джойны, а в реальности вы используете что-то другое, то это отдельный разговор.
Через ID предка — самый простой вариант, но самый неэффективный. И оптимизировать его, вместо использования более логичных структур — интересное, но не очень полезное занятие.
Небольшую иерархию можно вообще засосать в память и не париться ни о чём. А если иерархия с 10 млн элементами, то стоит всё-таки подумать о конретных требованиях к задаче.
Конечно же, если статья написана с целью рассказать про CTE и рекурсивные джойны, а в реальности вы используете что-то другое, то это отдельный разговор.
Ну вот представьте, что вы строите иерархию адресов России — пресловутый КЛАДР. Можно быть увереным, что регионы не меняются.
Ну то есть с момента последнего такого факта прошло уже 12 лет, «точно не будет», а потом — ой…
Ну то есть с момента последнего такого факта прошло уже 12 лет, «точно не будет», а потом — ой…
Т.е. раз в 12 лет поменять строчки в базе — это гигантская проблема?
А в течение 12 лет тратить на обогрев улицы ресурсы CPU постоянно делая неэффективные операции — это норма?
А в течение 12 лет тратить на обогрев улицы ресурсы CPU постоянно делая неэффективные операции — это норма?
Это сильно зависит от глубины легаси и частоты таких запросов.
Тут была история, как банки Cobol-специалистов искали, так что иногда и «поменять строчки» — проблема.
Тут была история, как банки Cobol-специалистов искали, так что иногда и «поменять строчки» — проблема.
Про глубину legacy и скриншоты СБИСа мне понравилось :)
Но вообще, есть же вьюшки и триггеры в базе данных, т.е. можно изменить структуру, улучшить алгоритмы, а для legacy кода подснуть представление.
Но вообще, есть же вьюшки и триггеры в базе данных, т.е. можно изменить структуру, улучшить алгоритмы, а для legacy кода подснуть представление.
Для такого deep legacy (звучит как заголовок порно-ролика) можно сделать отдельную таблицу с иерархией «сбоку». Да, дополнительный join, зато можно гибко настроить иерархию (или даже несколько).
Если такое легаси, что даже с этим сложности — остаётся только посочувствовать…
P.S. Для Cobol есть драйвер для PostgreSQL? :)
Если такое легаси, что даже с этим сложности — остаётся только посочувствовать…
P.S. Для Cobol есть драйвер для PostgreSQL? :)
Если в иерархию пишется чаще, чем читается — повод задуматься, а стоит ли хранить её в реляционной БД :)
Nested set не самый удобный подход с точки зрения вставки, но не всё так плохо — id там менять не надо.
Nested set не самый удобный подход с точки зрения вставки, но не всё так плохо — id там менять не надо.
id там менять не надоБывает вот такое:
— PM: У нас иерархия будет 100% статична, ничего там меняться не будет!
— TL: Давайте Nested Set, а заодно сэкономим поля и объединим ID/left.
…
— PM: А давайте теперь дадим пользователю настраивать иерархию самому!
:)
Бывает вот такое:
— PM: У нас иерархия будет 100% статична, ничего там меняться не будет!
— TL: Давайте Nested Set, а заодно сэкономим поля и объединим ID/left.
…
— PM: А давайте теперь дадим пользователю настраивать иерархию самому!
:)
Так а в чём проблема с редактированием nested set? Главное, как я уже говорил, чтобы не требовалось оптимизировать больше вставку чем чтение. А это крайне редко требуется.
Строго говоря, я вижу два варианта:
— мы со страшной силой пишем что-то, например, с датчиков и непременно в иерархию (повод задуматься о специализированном хранилище);
— требуется выпрямить руки программистам, которые небрежно спроектировали решение.
В остальных случаях, nested set будет работать нормально. Для более экзотических случаев (или экзотических разработчиков, которым вдруг сложно будет с ним разобраться) можно что-то ещё придумать.
Если интересно — зайдите на redmine.org — там вполне себе иерархические задачи на nested set и (ой!) они редактируются ;)
P.S. Может, это вообще всё сильно субъективно, но лично я между CTE со склейкой id на простой структуре БД и nested set с нетривиальной логикой по вставке выберу nested set.
Поищите в сети историю про «шипящие дифтонги».
Если переписывать ваш пост в соответствии с духом той истории, то он должен заканчиваться так:
… программист на Oracle написал CONNECT BY, нажал Enter и с чувством выполненного долга отвернулся от клавиатуры. «И это всё?» – недоумённо спросил Postgres-программист. «Всё!»…
Если переписывать ваш пост в соответствии с духом той истории, то он должен заканчиваться так:
… программист на Oracle написал CONNECT BY, нажал Enter и с чувством выполненного долга отвернулся от клавиатуры. «И это всё?» – недоумённо спросил Postgres-программист. «Всё!»…
Sign up to leave a comment.
PostgreSQL Antipatterns: насколько глубока кроличья нора? пробежимся по иерархии