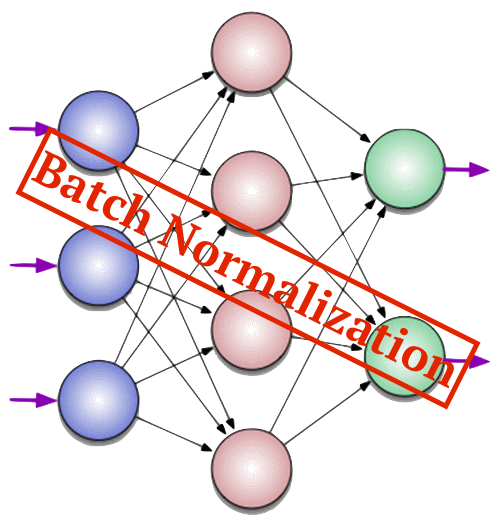
Добро пожаловать во вторую часть руководства по нейронным сетям. Сразу хочу принести извинения всем кто ждал вторую часть намного раньше. По определенным причинам мне пришлось отложить ее написание. На самом деле я не ожидал, что у первой статьи будет такой спрос и что так много людей заинтересует данная тема. Взяв во внимание ваши комментарии, я постараюсь предоставить вам как можно больше информации и в то же время сохранить максимально понятный способ ее изложения. В данной статье, я буду рассказывать о способах обучения/тренировки нейросетей (в частности метод обратного распространения) и если вы, по каким-либо причинам, еще не прочитали первую часть, настоятельно рекомендую начать с нее. В процессе написания этой статьи, я хотел также рассказать о других видах нейросетей и методах тренировки, однако, начав писать про них, я понял что это пойдет вразрез с моим методом изложения. Я понимаю, что вам не терпится получить как можно больше информации, однако эти темы очень обширны и требуют детального анализа, а моей основной задачей является не написать очередную статью с поверхностным объяснением, а донести до вас каждый аспект затронутой темы и сделать статью максимально легкой в освоении. Спешу расстроить любителей “покодить”, так как я все еще не буду прибегать к использованию языка программирования и буду объяснять все “на пальцах”. Достаточно вступления, давайте теперь продолжим изучение нейросетей.


 Lock-free list является основой многих интересных структур данных, — простейшего
Lock-free list является основой многих интересных структур данных, — простейшего 

 В предыдущих частях опуса (
В предыдущих частях опуса (



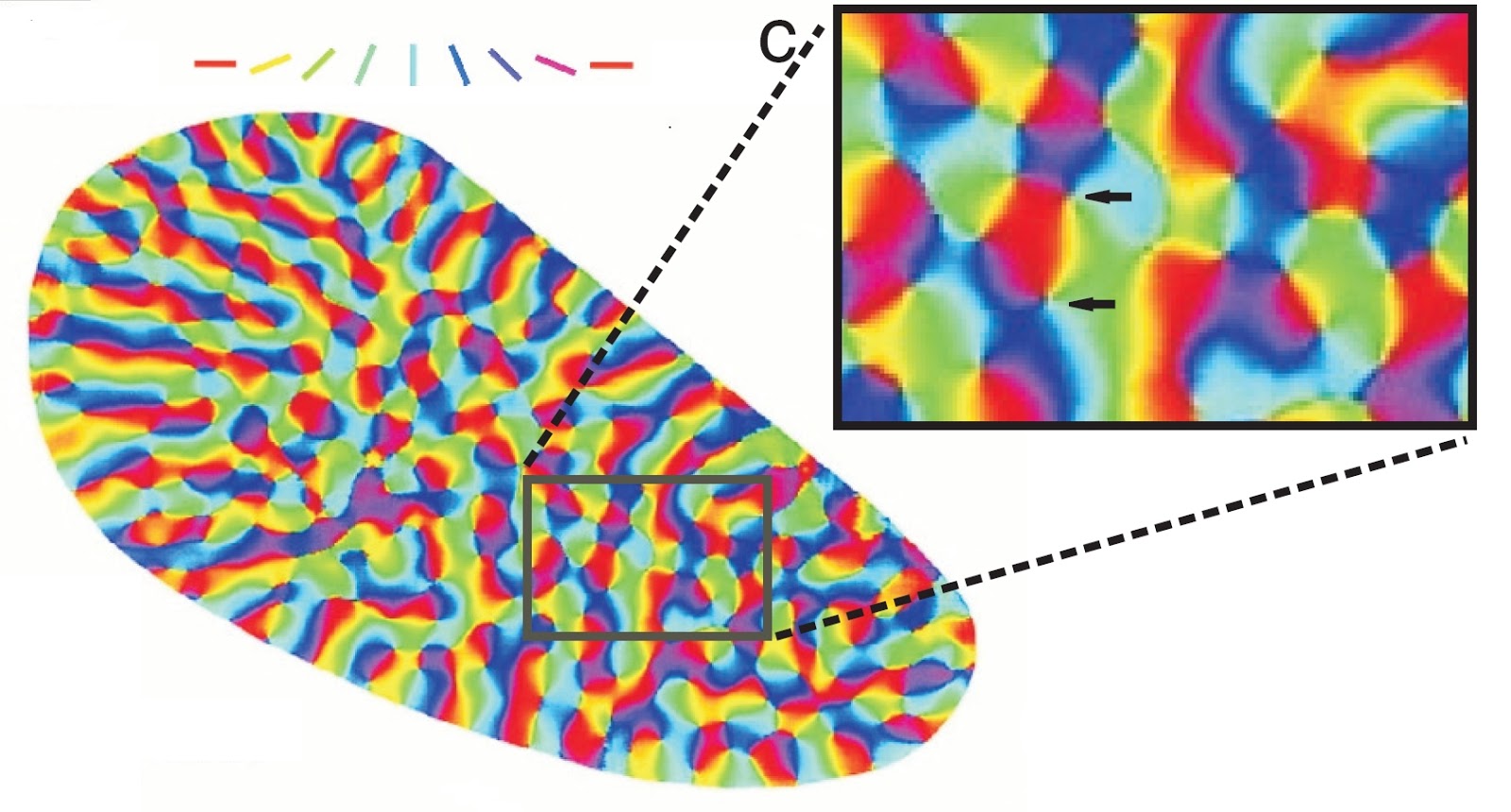

 Что такое информация, как найти скрытый в ней смысл, что вообще есть смысл? В большинстве толкований
Что такое информация, как найти скрытый в ней смысл, что вообще есть смысл? В большинстве толкований 
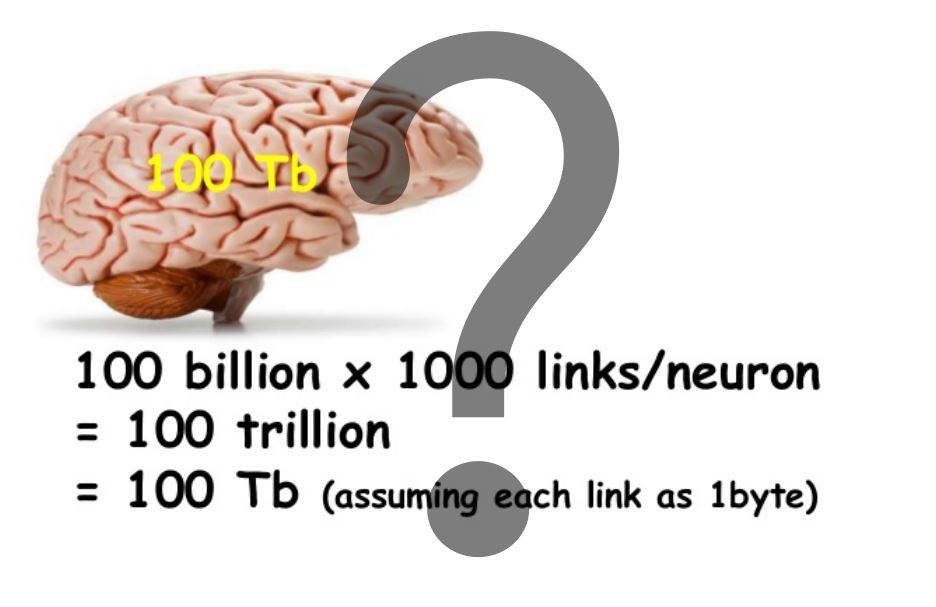 Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.
Когда с нами что-то происходит наш мозг фиксирует это, создавая воспоминания. Изменения, которые при этом происходят с мозгом, принято называть энграммами или следами памяти.