Небольшая заметка с технологиями и полезными ссылками, которые позволили мне пройти собеседование и работать в Сбере.

Ilya @iboltaev
Программист
Теоретические основы всех популярных алгоритмов машинного обучения и их реализация с нуля на Python
Hard
1 min
Tutorial

В данной статье в виде ссылок представлены все популярные алгоритмы классического машинного обучения с их подробным теоретическим описанием и немного упрощённой реализацией с нуля на Python, отражающей основную идею. Помимо этого, в конце каждой темы указаны дополнительные источники для более глубокого ознакомления, а суммарное время прочтения статей ниже составляет более трёх часов!
Распределённое обучение с PyTorch на кластере для тех, кто спешит
Medium
14 min
Tutorial
Translation

Глубокие модели становятся всё больше и всё реже помещаются на один компьютер. Это перевод поста в блоге Lambda Labs, компании, специализирующейса на инфраструктуре для глубого обучения. В этом посте нам расскажут как организовать распределенное обучение модели PyTorch на нескольких вычислительных узлах.
В качестве инструмента для запуска задач рассматриваются torchrun и MPI.
Анализ временных рядов, применение нейросетей (1 часть)
9 min
Tutorial

В этой статье, я опишу некоторые основные понятия в теории анализа временных рядов, классические статистические алгоритмы прогнозирования и интересные алгоритмы машинного обучения, которые применяются для временных рядов
Если Вы готовы погрузиться в одну из очень интересных тем статистики и Вы любитель машинного обучения, продолжайте читать :-)
И снова процессоры: новые чипы от Intel, AMD, Huawei, особенности М1 от Apple
5 min

Процесс выхода на рынок новых процессоров явно ускорился — буквально каждый месяц на рынке появляются новые и новые чипы. Сейчас стали известны подробности сразу о нескольких новых чипах, включая как зарубежных, так и отечественных производителей. Среди этих подробностей — интересная особенность уже вроде как изученных процессоров М1 от Apple, о которых мы писали не так давно.
Илья Якямсев: Эффективность не работает
19 min
С точки зрения проект-менеджера и с точки зрения управления людьми, люди в депрессии — идеальные работники.
Привет, Хабр.
Недавно посмотрела выступление одного scrum-мастера и stand up комика по совместительству. Выступление оказалось эмоциональное, с большим количеством непечатных слов и долей здравого смысла.
В каждой шутке только доля шутки, но все же прошу не относиться к этому материалу слишком серьезно. Предлагаю для ознакомления свое изложение в «очищенном» формате. Увидеть полное выступление Ильи Якямсева «Эффективность не работает» на конференция FrontDays 2018 можно по ссылке.
Эффективность не работает
Этот доклад скорее жизнеутверждающий, позитивный, и он про жизнь, не про программирование. Хотя много будет про программирование, но косвенно.
Я работаю менеджером проекта. Начинал я в Тольятти, в 96 году, на должности «эй, пацан, принеси пиво». С 99 года я начал программировать front, тогда это называлось «верстак». Потом я открыл контору, закрыл ее, многое произошло, и сейчас я менеджер проектов.
Мой доклад называется «Эффективность не работает». И я объясню почему.
Жизнь после 30
Дело в том, что мне сорокет в этом году. Я работаю в основном с людьми помоложе себя, и они у меня часто спрашивают: «Илья, как она жизнь в IT после 30? Ну, то есть, что с ней происходит?». Я отшучиваюсь: как говорится, баб поменьше, детей побольше.

Но я всерьез задался этим вопросом, подумал, что случилось со всеми людьми, с которыми я начинал, с которыми продолжаю. Всем моим друзьям около 40, все по-разному живут. Какое у нас общее свойство? О чем стоит рассказать людям? На что им ориентироваться в процессе работы? Каким образом это будет у них? И я вывел то общее, о котором хочу сегодня рассказать.
Модификация ядра Linux: добавляем новые системные вызовы
5 min
Translation

В этой статье мы научимся изменять ядро Linux, добавим собственные уникальные системные вызовы и в завершении соберем ядро с новой функциональностью.
Apache Spark: оптимизация производительности на реальных примерах
13 min

Apache Spark – фреймворк для обработки больших данных, который давно уже стал одним из самых популярных и часто встречаемых во всевозможных проектах, связанных с Big Data. Он удачно сочетает в себе скорость работы и простоту выражения своих мыслей разработчиком.
Разработчик работает с данными на достаточно высоком уровне и, кажется, что нет ничего сложного в том, чтобы, например, соединить два набора данных, написав всего одну строку кода. Но только задумайтесь: что происходит в кластере при соединении двух наборов данных, которые могут и не находится целиком на каком-либо из узлов кластера? Обычно Spark со всем справляется быстро, но иногда, а особенно, если данных действительно много, необходимо все-таки понимать – что происходит уровнем ниже и использовать это знание, чтобы помочь Spark работать в полную силу.
Мой уход из Яндекса, как не потерять мотивацию за полгода подготовки в FAANG и реджект в Google
12 min

Мой уход из Яндекса, как не потерять мотивацию за полгода подготовки в FAANG и реджект в Google.
Где начинающему тестировщику получить первый опыт: проект «Хомячки»
7 min
Привет! Меня зовут Ольга Ермолаева. Я работаю в тестировании с 2008 года. Сейчас руковожу департаментом качества в компании «Инттерра» и помогаю студентам на курсе для тестировщиков в Яндекс.Практикуме в качестве наставника.
Все, кто работает в IT-сфере, когда-то задавались вопросом, как найти первую работу. Ведь все работодатели требуют опыт, но никто не говорит, где его взять.
Начинающие программисты пишут свои pet-проекты, выкладывают на Github и добавляют ссылку в портфолио. Дизайнеры могут показать свою страницу на Behance или Dribble. Но что делать начинающим тестировщикам?
Можно пойти на платные курсы и приобрести учебный опыт, но его не всегда бывает достаточно для получения желаемой работы. Можно самому писать тестовую документацию, проводить тестирования, оформлять баги, но не факт, что итог будет приемлемого качества, потому что нет обратной связи.
В статье я поделюсь с вами одним из вариантов решения этой проблемы.

Как мы проверяли производительность новых процессоров в облаке для 1С по тесту Гилёва
3 min

Америку не откроем, если скажем, что виртуальные машины на новых процессорах всегда производительнее оборудования на процессорах старого поколения. Интереснее другое: при анализе возможностей систем, казалось бы, очень близких по своим техническим характеристикам, результат может быть совершенно различным. Мы в этом убедились, когда протестировали процессоры Intel в нашем облаке, чтобы проверить, какие из них дают наибольшую отдачу при работе систем на 1С.
Спойлер: как показал наш тест, всё зависит от поставленной задачи. Нам удалось из всей линейки новых процессоров Intel выбрать тот продукт, который дал кратный прирост производительности благодаря тому, что в Intel Xeon Gold 6244 меньшее количество ядер, на каждое ядро приходится большее количество L3 кэш-памяти и назначена большая тактовая частота — как базовая, так и в режиме Turbo Boost. Иными словами, именно эти процессоры лучше справляются с ресурсоёмкими задачами в пересчёте на единицу производительности/рубль. Для 1С это подходит как нельзя лучше: с новыми процессорами приложения на 1С в нашем облаке начали буквально «дышать».
А теперь расскажем, как мы проводили тестирование. Ниже — результаты синтетических тестов Гилёва. На них можно ориентироваться, но в любом случае нужно проверять реальную утилизацию самостоятельно на своих задачах.
Способы хранения деревьев в реляционных базах данных c использованием ORM Hibernate
Medium
33 min
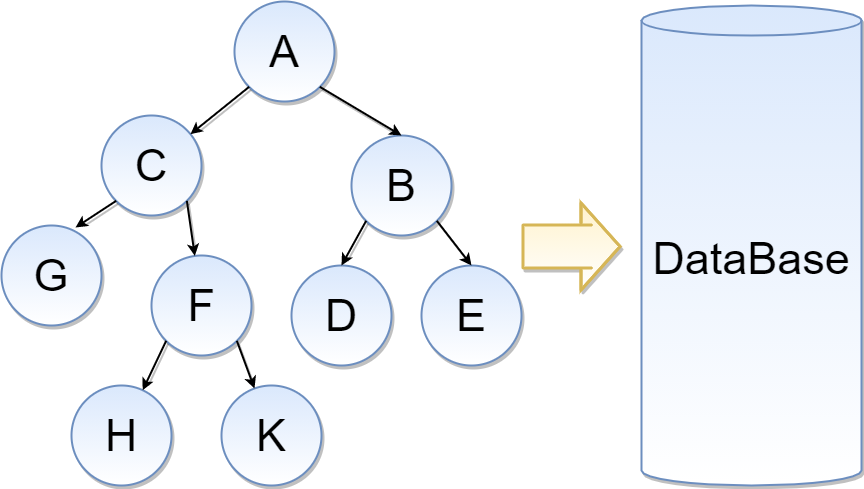
Здравствуйте! В этой статье, я постараюсь кратко рассказать о четырёх достаточно известных способах хранения деревьев с указанием преимуществ и недостатков. На идею написать подобную статью подтолкнул не раз слышимый мною вопрос: "А как это будет в Hibernate?", то есть как реализовать какой-либо из способов хранения дерева с использованием ORM Hibernate. Сразу замечу, что данная статья не является каким-либо призывом использовать именно реляционные БД для решения задач связанных с деревьями, так как понятно что реляционные базы не заточены конкретно для целей хранения\обработки таких данных. Для иерархии подходят и используются графовые базы данных. Поэтому эта статья будет полезная тем, кому необходимо по каким-либо причинам реализовать хранение дерева именно в реляционной БД. Необходимо также отметить, что и ORM Hibernate также не содержит каких-либо готовых решений из коробки для хранения\обработки деревьев по крайней мере на данный момент, поэтому реализация таких решений практически полностью ложиться на плечи разработчика. В примерах далее для полной и целостной картины, кроме сущностей(entity), рассмотрим кратко и такие базовые операции, как получение всех потомков с уровнем вложенности, получение всех родителей с уровнем вложенности, а также операции добавления, удаления и перемещения узла в дереве. В качестве примера дерева послужит структура папок на файловой системе, которая будет отражена в таблицах(е) БД. На такие моменты, как инициализация сущности(entity) не будем акцентировать внимание, полагаю что рассматривать это не имеет смысла, так как алгоритмы обхода дерева известны и описаны во многих книгах и публикациях и будут мало кому интересны. В любом случае мои реализации обхода дерева представлены на GitHub и с ними при желании можно ознакомиться.
Издательство Питер. Колонка редактора
5 min

Привет, Хаброжители! Предлагаем ознакомиться с краткими обзорами сданных в типографию новинок.
JIT-компилятор оптимизирует не круто, а очень круто
6 min
Недавно Лукас Эдер заинтересовался в своём блоге, способен ли JIT-компилятор Java оптимизировать такой код, чтобы убрать ненужный обход списка из одного элемента:
// ... а тут мы "знаем", что список содержит только одно значение
for (Object object : Collections.singletonList("abc")) {
doSomethingWith(object);
}Вот мой ответ: JIT может даже больше. Мы будем говорить про HotSpot JVM 64 bit восьмой версии. Давайте рассмотрим вот такой простой метод, который считает суммарную длину строк из переданного списка:
static int testIterator(List<String> list) {
int sum = 0;
for (String s : list) {
sum += s.length();
}
return sum;
}1 CPU 1 Гб – а я хочу мониторинг, как у больших дядей
14 min

Я обожаю читать на хабре статьи про то, как устроены системы больших интернет-компаний. Кластеры SQL-серверов, монг и редисов. Тут у нас кластер ELK собирает трейсинг, там – сборка логов, здесь балансер выдает входящим запросам traceID и можно отслеживать, как запрос ходит по всем нашим микросервисам. Класс. Но, допустим, у вас совсем маленький проект и вы можете себе позволить лишь VPS минимальной конфигурации. Реально ли на ней сделать мониторинг не хуже, чем у больших проектов? Я решил – надо попробовать.
Меняем Java на Scala. Базовое приложение
16 min
Tutorial
Здравствуй, Хабр.
Лето на дворе, скоро отпуск и появилось немного свободного времени поделиться наработками, каким-то опытом по написанию Web приложений на Java платформе. Как основной язык я буду использовать Scala. Это будет похоже на небольшой гайд, как человеку с опытом Java постепенно начать использовать Scala и не отказываться от уже имеющихся у него наработок.
Это первая часть из серии статей, в которой мы уделим внимание базовой структуре приложения. Ориентирована на людей знающих Java, работавших со Spring, Hibernate, JPA, JSP и другими 3-4ех буквенными сокращениями. Я попытаюсь рассказать как максимально быстро и безболезненно начать использовать Scala в ваших проектах и по-другому проектировать ваше новое приложение. Все это будет вокруг проекта, который должен выполнять ряд требований:
1. Приложение полностью закрыто, работаем только после авторизации
2. Наличие удобного API (REST мы забудем (он уже история) и напишем что-то вроде Google AdWords API, со своим SQL like запросником)
3. Возможность запуска на сервере приложений так и без него
4. i18n
5. Миграция БД
6. Среда для разработки должна разворачиваться через Vagrant
7. И, по мелочи, логирование, развертывание…
Все это нужно сделать так, чтобы сопровождать и развивать наше приложение было очень легко, чтобы не возникло такой ситуации, когда при добавление нового справочника программист оценивает это сроком в 2 дня. Если я вас заинтересовал, прошу под кат.
Лето на дворе, скоро отпуск и появилось немного свободного времени поделиться наработками, каким-то опытом по написанию Web приложений на Java платформе. Как основной язык я буду использовать Scala. Это будет похоже на небольшой гайд, как человеку с опытом Java постепенно начать использовать Scala и не отказываться от уже имеющихся у него наработок.
Это первая часть из серии статей, в которой мы уделим внимание базовой структуре приложения. Ориентирована на людей знающих Java, работавших со Spring, Hibernate, JPA, JSP и другими 3-4ех буквенными сокращениями. Я попытаюсь рассказать как максимально быстро и безболезненно начать использовать Scala в ваших проектах и по-другому проектировать ваше новое приложение. Все это будет вокруг проекта, который должен выполнять ряд требований:
1. Приложение полностью закрыто, работаем только после авторизации
2. Наличие удобного API (REST мы забудем (он уже история) и напишем что-то вроде Google AdWords API, со своим SQL like запросником)
3. Возможность запуска на сервере приложений так и без него
4. i18n
5. Миграция БД
6. Среда для разработки должна разворачиваться через Vagrant
7. И, по мелочи, логирование, развертывание…
Все это нужно сделать так, чтобы сопровождать и развивать наше приложение было очень легко, чтобы не возникло такой ситуации, когда при добавление нового справочника программист оценивает это сроком в 2 дня. Если я вас заинтересовал, прошу под кат.
4 толковых канала на Youtube про технические собеседования
4 min
Смотрю разные каналы ребят, которые проходят/проводят интервью в крупных компаниях и рассказывают про это. На русском прям что-то крутое не попадалось, но вот личный топ каналов на английском:

SORM. Новый элегантный и масштабируемый ORM фреймворк для Scala
2 min
Tutorial
Тот, кому доводилось иметь дело с выбором ORM для Scala, наверняка, наслышан о таких библиотеках, как Slick (Scala Query), Squeryl, Circumflex и пр., и, не менее вероятно, согласится со следующими утверждениями: они не абстрагируются от реляционных концепций, они требуют описания модели специфическими способами, API зачастую запутан и рассредоточен, и, наконец, то, насколько предложенные этими библиотеками абстракции в действительности упрощают работу с базой данных является, по меньшей мере, сомнительным.
Так и родилась идея создать фреймворк, который
Как видите, задачи все стояли достаточно бескомпромиссные, однако они были решены. За счёт этого удалось добиться последовательности, простоты и вытекающей интуитивности фреймворка, — и это при отнюдь не слабых возможностях. Boilerplate удалось, и вовсе, исключить.
Так и родилась идея создать фреймворк, который
- возведёт абстракцию над базой данных до более высокого уровня, представляя её через стандартные типы данных Scala: примитивы, кортежи, опции, коллекции и тд., а так же стандартные кейс-классы, представляющие собой сущности,
- выполняя первую задачу, будет «чистым», что означает полное исключение концепций реляционной стороны из API фреймворка: никаких таблиц, строк и реляционных связей,
- возведёт в принцип основы функционального программирования: только немутируемые типы данных, сведение State к минимуму,
- будет выполнять за пользователя всё, что он может, за счёт чего достигнет минимизации boilerplate.
Как видите, задачи все стояли достаточно бескомпромиссные, однако они были решены. За счёт этого удалось добиться последовательности, простоты и вытекающей интуитивности фреймворка, — и это при отнюдь не слабых возможностях. Boilerplate удалось, и вовсе, исключить.