Привет. Как и планировалось в прошлом посте об ограниченных машинах Больцмана, в этом будет рассмотрено применение RBM для предобучения обыкновенной многослойной сети прямого распространения. Такая сеть обычно обучается алгоритмом обратного распространения ошибки, который зависит от многих параметров, и пока не существует точного алгоритма выбора этих самых параметров обучения, как и оптимальной архитектуры сети. Разработано множество эвристик, позволяющих сократить пространство поиска, а также методик оценки качества выбранных параметров (например, кросс-валидация). Мало того, оказывается, и сам алгоритм обратного распространения не так уж хорош. Хотя Румельхарт, Хинтон и Вильямс показали сходимость алгоритма обратного распространения (тут еще более математическое доказательство сходимости), но есть небольшой нюанс: алгоритм сходится при бесконечно малых изменениях весов (т.е. при скорости обучения, стремящейся к нулю). И даже это не все. Как правило, этим алгоритмом обучают небольшие сети с одним или двумя скрытыми слоями из-за того, что эффект обучения не доходит до дальних слоев. Далее мы поговорим подробнее о том, почему же не доходит, и применим технику инициализации весов с помощью обученной RBM, которую разработал Джеффри Хинтон.

User
Рекурентная нейронная сеть в 10 строчек кода оценила отзывы зрителей нового эпизода “Звездных войн”
11 min
Hello, Habr! Недавно мы получили от “Известий” заказ на проведение исследования общественного мнения по поводу фильма «Звёздные войны: Пробуждение Силы», премьера которого состоялась 17 декабря. Для этого мы решили провести анализ тональности российского сегмента Twitter по нескольким релевантным хэштегам. Результата от нас ждали всего через 3 дня (и это в самом конце года!), поэтому нам нужен был очень быстрый способ. В интернете мы нашли несколько подобных онлайн-сервисов (среди которых sentiment140 и tweet_viz), но оказалось, что они не работают с русским языком и по каким-то причинам анализируют только маленький процент твитов. Нам помог бы сервис AlchemyAPI, но ограничение в 1000 запросов в сутки нас также не устраивало. Тогда мы решили сделать свой анализатор тональности с блэк-джеком и всем остальным, создав простенькую рекурентную нейронную сеть с памятью. Результаты нашего исследования были использованы в статье “Известий”, опубликованной 3 января.

В этой статье я немного расскажу о такого рода сетях и познакомлю с парой классных инструментов для домашних экспериментов, которые позволят строить нейронные сети любой сложности в несколько строк кода даже школьникам. Добро пожаловать под кат.
В этой статье я немного расскажу о такого рода сетях и познакомлю с парой классных инструментов для домашних экспериментов, которые позволят строить нейронные сети любой сложности в несколько строк кода даже школьникам. Добро пожаловать под кат.
Алгоритмы выделения контуров изображений
4 min
В свете недавних статей об обработке изображений я хотел бы немного рассказать об алгоритмах выделения контуров: методы Робертса, Превитта и Собеля (эти методы взяты для рассмотрения как самые известные и часто используемые).
Сборка XGBoost для Python под Windows
2 min
Windows is so evil that consumes extra energy to make the things running.

Библиотека XGBoost гремит на всех соревнованиях по машинному обучению и помогает завоёвывать призовые места. Однако, стать обладателем этого пакета для Python под Windows не так просто.
Процесс установки скудно описан на GitHub и немногим шире на форуме Kaggle. Поэтому попробую описать пошагово и более подробно. Надеюсь это поможет сохранить много времени неопытным пользователям.
Библиотека XGBoost гремит на всех соревнованиях по машинному обучению и помогает завоёвывать призовые места. Однако, стать обладателем этого пакета для Python под Windows не так просто.
Процесс установки скудно описан на GitHub и немногим шире на форуме Kaggle. Поэтому попробую описать пошагово и более подробно. Надеюсь это поможет сохранить много времени неопытным пользователям.
Специализация по машинному обучению на Coursera от Физтеха и Яндекса
7 min
В начале года на Coursera открылся курс по машинному обучению от Яндекса и Вышки, о котором мы уже рассказывали. К моменту старта на него записались 14000 человек. Через час после открытия пользователи создали канал в Slack, где стали обсуждать программу. Сейчас слушателей уже 21000.

9 февраля на платформе стала доступна запись на специализацию по машинному обучению, которая разрабатывается нашими специалистами уже совместно с Физтехом. Она устроена таким образом, чтобы помочь слушателям плавно погрузиться в тему.
Специализация «Машинное обучение и анализ данных» состоит из пяти курсов и работой над собственным проектом. Обучение будет длиться несколько месяцев. Записаться на него можно до 19 февраля. Если вы не успеете это сделать, с 14 марта можно будет записаться на второй поток.
Авторы курса — сотрудники Яндекса, специалисты Yandex Data Factory, которые преподают на Физтехе. Константин Воронцов тоже среди них. Мы попросили некоторых из коллег рассказать, кому может быть полезна специализация и для чего она нужна. Также под катом — программа всех курсов.
9 февраля на платформе стала доступна запись на специализацию по машинному обучению, которая разрабатывается нашими специалистами уже совместно с Физтехом. Она устроена таким образом, чтобы помочь слушателям плавно погрузиться в тему.
Специализация «Машинное обучение и анализ данных» состоит из пяти курсов и работой над собственным проектом. Обучение будет длиться несколько месяцев. Записаться на него можно до 19 февраля. Если вы не успеете это сделать, с 14 марта можно будет записаться на второй поток.
Авторы курса — сотрудники Яндекса, специалисты Yandex Data Factory, которые преподают на Физтехе. Константин Воронцов тоже среди них. Мы попросили некоторых из коллег рассказать, кому может быть полезна специализация и для чего она нужна. Также под катом — программа всех курсов.
Структуры данных: бинарные деревья. Часть 1
6 min
Интро
Этой статьей я начинаю цикл статей об известных и не очень структурах данных а так же их применении на практике.
В своих статьях я буду приводить примеры кода сразу на двух языках: на Java и на Haskell. Благодаря этому можно будет сравнить императивный и функциональный стили программирования и увидить плюсы и минусы того и другого.
Начать я решил с бинарных деревьев поиска, так как это достаточно базовая, но в то же время интересная штука, у которой к тому же существует большое количество модификаций и вариаций, а так же применений на практике.
История об аспирантуре в США. Часть 3: Сколько получает аспирант и за чем стоит ехать делать PhD
8 min
В первых двух частях я описал свое поступление в аспирантуру и стоимость жизни в США. В этой части мы подойдем еще ближе к самому интересному, а если точнее, то я расскажу, откуда и в каких количествах появляются деньги у аспирантов, сколько надо платить за учебу и за чем сюда стоит ехать (или не ехать). Ну и наконец будет начало описания того, как можно сюда приехать.
Живет тут
Живет тут
Часть 1: Поступление
Живет тут
Часть 2: Стоимость жизни в США
Живет тут
Линейная алгебра: пробный заезд
7 min
Привет, Хабр!
Аналит, линейка, линал — эти слова ассоциируются скорее с фразой «сдать и забыть», а не с тем, для чего на самом деле нужен замечательный раздел математики под названием линейная алгебра. Давайте попробуем посмотреть на него с разных сторон и разберемся, что же в нем хорошего и почему он так полезен в приложениях.
Часто первое знакомство с линейной алгеброй выглядит как-то так:
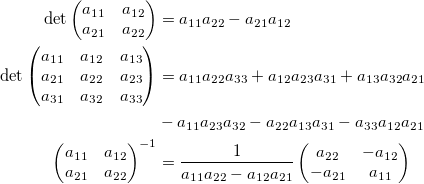
Не очень вдохновляет, правда? Сразу возникает два вопроса: откуда это все взялось и зачем оно нужно.
Когда я занимался вычислительной гидродинамикой (CFD), один из коллег говорил: «Мы не решаем уравнения Навье-Стокса. Мы обращаем матрицы.» И действительно, линейная алгебра — «рабочая лошадка» вычислительной математики:

Аналит, линейка, линал — эти слова ассоциируются скорее с фразой «сдать и забыть», а не с тем, для чего на самом деле нужен замечательный раздел математики под названием линейная алгебра. Давайте попробуем посмотреть на него с разных сторон и разберемся, что же в нем хорошего и почему он так полезен в приложениях.
Часто первое знакомство с линейной алгеброй выглядит как-то так:
Не очень вдохновляет, правда? Сразу возникает два вопроса: откуда это все взялось и зачем оно нужно.
Начнем с практики
Когда я занимался вычислительной гидродинамикой (CFD), один из коллег говорил: «Мы не решаем уравнения Навье-Стокса. Мы обращаем матрицы.» И действительно, линейная алгебра — «рабочая лошадка» вычислительной математики:
Подходы и инструменты работы с BigData — все только начинается, начи-на-ет-ся
8 min
Вы еще не сохраняете десятки миллионов событий в день? К вам еще не забегают менеджеры с кричащим вопросом — когда твой дорогущий кластер на «надцати» машинах посчитает агрегированную статистику по продажам за неделю (а в глазах читается: «чувак, ребята на php/python/ruby/go решают задачу за час, а ты со своей Бигдатой тянешь время днями, доколе?»)? Вы еще не вскидываетесь ночью в холодном поту от кошмара: «разверзлось небо и на вас, ваших коллег и весь нафиг город вывалилось огромная куча… Бигдаты и никто не знает, что с этим всем теперь делать»? :-)
Есть еще интересный симптом — в компании скапливается много-много логов и кто-то, по фамилии, отдаленно звучащей как «Сусанин», говорит: «коллеги, а в логах на самом деле сокрыто золото, там есть информация о путях пользователей, о транзакциях, о группах, о поисковых запросах — а давайте это золото начать извлекать»? И вы превращаетесь в «извлекателя» добра из терабайт (и их десятков) информационного водопада под мотивирующие советы: «а разве нельзя в потоке получать ценную для бизнеса информацию, зачем гонять часами кластера?».
Если это не о вас, тогда и не заходите под кат, ибо там — треш и жесткий технологический трепет…
Есть еще интересный симптом — в компании скапливается много-много логов и кто-то, по фамилии, отдаленно звучащей как «Сусанин», говорит: «коллеги, а в логах на самом деле сокрыто золото, там есть информация о путях пользователей, о транзакциях, о группах, о поисковых запросах — а давайте это золото начать извлекать»? И вы превращаетесь в «извлекателя» добра из терабайт (и их десятков) информационного водопада под мотивирующие советы: «а разве нельзя в потоке получать ценную для бизнеса информацию, зачем гонять часами кластера?».
Если это не о вас, тогда и не заходите под кат, ибо там — треш и жесткий технологический трепет…
14 новых ролей в Big Data
4 min
Количество данных растет с каждым днем огромными рывками. Ежедневно в сеть заливается 2,3 триллиона гигабайт данных. К 2017 году ожидается, что количество данных вырастет на 800%. Чем больше данных, тем выше спрос на специалистов по их обработке.
Наука о данных настолько динамично развивается, что у каждого специалиста есть своя узкая зона ответственности. Мартин Джонс (Martin Jones), CEO и co-founder в Cambriano Energy предлагает выделить 14 основных ролей в работе с большими данными.

Наука о данных настолько динамично развивается, что у каждого специалиста есть своя узкая зона ответственности. Мартин Джонс (Martin Jones), CEO и co-founder в Cambriano Energy предлагает выделить 14 основных ролей в работе с большими данными.
Откуда есть пошло комплексное число
3 min
В современной математике комплексное число является одним из фундаментальнейших понятий, находящее применение и в «чистой науке», и в прикладных областях. Понятно, что так было далеко не всегда. В далекие времена, когда даже обычные отрицательные числа казались странным и сомнительным нововведением, необходимость расширения на них операции извлечения квадратного корня была вовсе неочевидной. Тем не менее, в середине XVI века математик Рафаэль Бомбелли вводит комплексные (в данном случае точнее сказать, мнимые) числа в оборот. Собственно, предлагаю посмотреть, в чем была суть затруднений, доведших в итоге солидного итальянца до подобных крайностей.
Лекция Дмитрия Ветрова о математике больших данных: тензоры, нейросети, байесовский вывод
2 min
Сегодня лекция одного из самых известных в России специалистов по машинному обучению Дмитрия Ветрова, который руководит департаментом больших данных и информационного поиска на факультете компьютерных наук, работающим во ВШЭ при поддержке Яндекса.
Как можно хранить и обрабатывать многомерные массивы в линейных по памяти структурах? Что дает обучение нейронных сетей из триллионов триллионов нейронов и как можно осуществить его без переобучения? Можно ли обрабатывать информацию «на лету», не сохраняя поступающие последовательно данные? Как оптимизировать функцию за время меньшее чем уходит на ее вычисление в одной точке? Что дает обучение по слаборазмеченным данным? И почему для решения всех перечисленных выше задач надо хорошо знать математику? И другое дальше.
Люди и их устройства стали генерировать такое количество данных, что за их ростом не успевают даже вычислительные мощности крупных компаний. И хотя без таких ресурсов работа с данными невозможна, полезными их делают люди. Сейчас мы находимся на этапе, когда информации так много, что традиционные математические методы и модели становятся неприменимы. Из лекции Дмитрия Петровича вы узнаете, почему вам надо хорошо знать математику для работы с машинным обучением и обработкой данных. И какая «новая математика» понадобится вам для этого. Слайды презентации — под катом.
Как можно хранить и обрабатывать многомерные массивы в линейных по памяти структурах? Что дает обучение нейронных сетей из триллионов триллионов нейронов и как можно осуществить его без переобучения? Можно ли обрабатывать информацию «на лету», не сохраняя поступающие последовательно данные? Как оптимизировать функцию за время меньшее чем уходит на ее вычисление в одной точке? Что дает обучение по слаборазмеченным данным? И почему для решения всех перечисленных выше задач надо хорошо знать математику? И другое дальше.
Люди и их устройства стали генерировать такое количество данных, что за их ростом не успевают даже вычислительные мощности крупных компаний. И хотя без таких ресурсов работа с данными невозможна, полезными их делают люди. Сейчас мы находимся на этапе, когда информации так много, что традиционные математические методы и модели становятся неприменимы. Из лекции Дмитрия Петровича вы узнаете, почему вам надо хорошо знать математику для работы с машинным обучением и обработкой данных. И какая «новая математика» понадобится вам для этого. Слайды презентации — под катом.
Как решать вступительный экзамен в Школу анализа данных Яндекса
7 min
Лето — время вступительных экзаменов. Прямо сейчас завершается отбор в Школу анализа данных Яндекса — идут собеседования для тех, кто уже сдал экзамен. В ШАД преподают машинное обучение, компьютерное зрение, анализ текстов на естественном языке и другие направления современной Computer Science. Два года студенты изучают предметы, которые обычно не входят в университетские программы, хотя пользуются огромным спросом как в науке, так и в индустрии. Учиться можно не только в Москве — у Школы открыты филиалы в Екатеринбурге, Минске, Киеве, Новосибирске, Санкт-Петербурге. Есть и заочное отделение, на котором можно обучаться, смотря видеолекции и переписываясь с преподавателями московской Школы по почте.

Но для того, чтобы поступить в ШАД, нужно успешно пройти три этапа — заполнить анкету на сайте, сдать вступительный экзамен и прийти на собеседование. Ежегодно в ШАД поступают старшекурсники, выпускники и аспиранты МГУ, МФТИ, ВШЭ, ИТМО, СПбГУ, УрФУ, НГУ и не все они справляются с нашими испытаниями. В этом году мы получили анкеты от 3500 человек, 1000 из которых была допущена к экзамену, и только 350 сдали его успешно.
Для тех, кто хочет попробовать себя и понять, на что он способен, мы подготовили разбор вступительного экзамена этого года. С вариантом, который мы выбрали для вас, справились 56% решавших его. В этой таблице вы можете увидеть, сколько человек смогли решить каждое из заданий в нём.
Но для начала хотелось бы объяснить, что мы проверяем экзаменом и как подходим к его составлению. В самые первые годы существования ШАД письменного экзамена не было, так как заявок было ещё немного, и со всеми, кто прошёл онлайн-тестирование, получалось поговорить лично. Но зато и собеседования были дольше; некоторые выпускники вспоминают, как с ними беседовали по шесть часов, предлагая много сложных задач. Потом поступающих стало больше – и в 2012 году появился письменный экзамен.
Но для того, чтобы поступить в ШАД, нужно успешно пройти три этапа — заполнить анкету на сайте, сдать вступительный экзамен и прийти на собеседование. Ежегодно в ШАД поступают старшекурсники, выпускники и аспиранты МГУ, МФТИ, ВШЭ, ИТМО, СПбГУ, УрФУ, НГУ и не все они справляются с нашими испытаниями. В этом году мы получили анкеты от 3500 человек, 1000 из которых была допущена к экзамену, и только 350 сдали его успешно.
Для тех, кто хочет попробовать себя и понять, на что он способен, мы подготовили разбор вступительного экзамена этого года. С вариантом, который мы выбрали для вас, справились 56% решавших его. В этой таблице вы можете увидеть, сколько человек смогли решить каждое из заданий в нём.
| Задание | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Решило | 57% | 68% | 40% | 35% | 29% | 12% | 20% | 6% |
Но для начала хотелось бы объяснить, что мы проверяем экзаменом и как подходим к его составлению. В самые первые годы существования ШАД письменного экзамена не было, так как заявок было ещё немного, и со всеми, кто прошёл онлайн-тестирование, получалось поговорить лично. Но зато и собеседования были дольше; некоторые выпускники вспоминают, как с ними беседовали по шесть часов, предлагая много сложных задач. Потом поступающих стало больше – и в 2012 году появился письменный экзамен.
Автоматизация тестирования Web-приложений
13 min
Tutorial
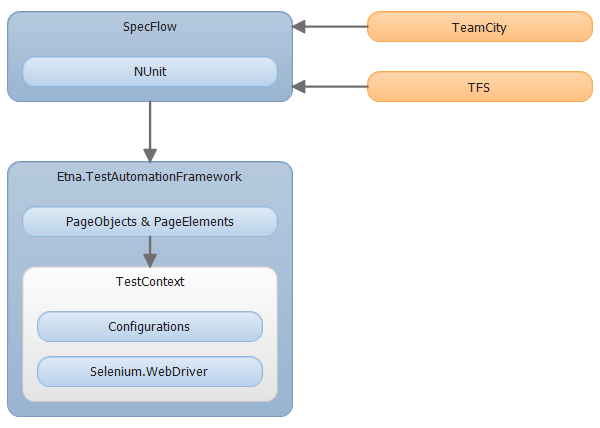
Автоматизация тестирования – место встречи двух дисциплин: разработки и тестирования. Наверное поэтому, я отношу эту практику к сложным, но интересным.
Путем проб и ошибок мы пришли к следующему технологическому стеку:
- SpecFlow (опционально): DSL
- NUnit: тестовый фреймворк
- PageObject + PageElements: UI-абстракиця
- Контекст тестирования (информация о целевом окружении, пользователях системы)
- Selenium.WebDriver
Для запуска тестов по расписанию мы используем TFS 2012 и TeamCity.
В статье я опишу, как мы к этому пришли, типовые ошибки и пути их решения.
Производящие функции — туда и обратно
9 min
«Производящая функция является устройством, отчасти напоминающим мешок. Вместо того чтобы нести отдельно много предметов, что могло бы оказаться затруднительным, мы собираем их вместе, и тогда нам нужно нести лишь один предмет — мешок».
Д. Пойа
Математика делится на два мира — дискретный и непрерывный. В реальном мире есть место и для того и для другого, и часто к изучению одного явления можно подойти с разных сторон. В этой статье мы рассмотрим метод решения задач с помощью производящих функций — мостика ведущего из дискретного мира в непрерывный, и наоборот.
Идея производящих функций достаточно проста: сопоставим некоторой последовательности <g0, g1, g2, ..., gn> — дискретному объекту, степенной ряд g0 + g1z + g2z2 +… + gnzn +… — объект непрерывный, тем самым мы подключаем к решению задачи целый арсенал средств математического анализа. Обычно говорят, последовательность генерируется, порождается производящей функцией. Важно понимать, что это символьная конструкция, то есть вместо символа z может быть любой объект, для которого определены операции сложения и умножения.
Д. Пойа
Введение
Математика делится на два мира — дискретный и непрерывный. В реальном мире есть место и для того и для другого, и часто к изучению одного явления можно подойти с разных сторон. В этой статье мы рассмотрим метод решения задач с помощью производящих функций — мостика ведущего из дискретного мира в непрерывный, и наоборот.
Идея производящих функций достаточно проста: сопоставим некоторой последовательности <g0, g1, g2, ..., gn> — дискретному объекту, степенной ряд g0 + g1z + g2z2 +… + gnzn +… — объект непрерывный, тем самым мы подключаем к решению задачи целый арсенал средств математического анализа. Обычно говорят, последовательность генерируется, порождается производящей функцией. Важно понимать, что это символьная конструкция, то есть вместо символа z может быть любой объект, для которого определены операции сложения и умножения.
Алгоритм Флойда — Уоршелла
6 min
 Алгоритм Флойда — Уоршелла — алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного графа без циклов с отрицательными весами с использованием метода динамического программирования. Это базовый алгоритм, так что тем кто его знает — можно дальше не читать.
Алгоритм Флойда — Уоршелла — алгоритм для нахождения кратчайших расстояний между всеми вершинами взвешенного графа без циклов с отрицательными весами с использованием метода динамического программирования. Это базовый алгоритм, так что тем кто его знает — можно дальше не читать.Этот алгоритм был одновременно опубликован в статьях Роберта Флойда (Robert Floyd) и Стивена Уоршелла (Stephen Warshall) в 1962 г., хотя в 1959 г. Бернард Рой (Bernard Roy) опубликовал практически такой же алгоритм, но это осталось незамеченным.
Базовые алгоритмы нахождения кратчайших путей во взвешенных графах
5 min
Наверняка многим из гейм-девелоперов (или просто людям, увлекающимися програмировагнием) будет интересно услышать эти четыре важнейших алгоритма, решающих задачи о кратчайших путях.
Сформулируем определения и задачу.
Графом будем называть несколько точек (вершин), некоторые пары которых соединены отрезками (рёбрами). Граф связный, если от каждой вершины можно дойти до любой другой по этим отрезкам. Циклом назовём какой-то путь по рёбрам графа, начинающегося и заканчивающегося в одной и той же вершине. И ещё граф называется взвешенным, если каждому ребру соответствует какое-то число (вес). Не может быть двух рёбер, соединяющих одни и те же вершины.
Каждый из алгоритмов будет решать какую-то задачу о кратчайших путях на взвешенном связном. Кратчайший путь из одной вершины в другую — это такой путь по рёбрам, что сумма весов рёбер, по которым мы прошли будет минимальна.
Для ясности приведу пример такой задачи в реальной жизни. Пусть, в стране есть несколько городов и дорог, соединяющих эти города. При этом у каждой дороги есть длина. Вы хотите попасть из одного города в другой, проехав как можно меньший путь.
Сформулируем определения и задачу.
Графом будем называть несколько точек (вершин), некоторые пары которых соединены отрезками (рёбрами). Граф связный, если от каждой вершины можно дойти до любой другой по этим отрезкам. Циклом назовём какой-то путь по рёбрам графа, начинающегося и заканчивающегося в одной и той же вершине. И ещё граф называется взвешенным, если каждому ребру соответствует какое-то число (вес). Не может быть двух рёбер, соединяющих одни и те же вершины.
Каждый из алгоритмов будет решать какую-то задачу о кратчайших путях на взвешенном связном. Кратчайший путь из одной вершины в другую — это такой путь по рёбрам, что сумма весов рёбер, по которым мы прошли будет минимальна.
Для ясности приведу пример такой задачи в реальной жизни. Пусть, в стране есть несколько городов и дорог, соединяющих эти города. При этом у каждой дороги есть длина. Вы хотите попасть из одного города в другой, проехав как можно меньший путь.
Кучи. Часть 1. Биномиальная куча
4 min
Здравствуйте, Хабросообщество!
На хабре есть описание множества интересных структур данных, таких как деревья отрезков, дуча и т.п. Если Вам интересны сложные структуры данных, то добро пожаловать под кат!
На хабре есть описание множества интересных структур данных, таких как деревья отрезков, дуча и т.п. Если Вам интересны сложные структуры данных, то добро пожаловать под кат!
Оценка сложности алгоритмов
6 min
Не так давно мне предложили вести курс основ теории алгоритмов в одном московском лицее. Я, конечно, с удовольствием согласился. В понедельник была первая лекция на которой я постарался объяснить ребятам методы оценки сложности алгоритмов. Я думаю, что некоторым читателям Хабра эта информация тоже может оказаться полезной, или по крайней мере интересной.
Введение в анализ сложности алгоритмов (часть 3)
6 min
Tutorial
Translation
От переводчика: данный текст даётся с незначительными сокращениями по причине местами излишней «разжёванности» материала. Автор абсолютно справедливо предупреждает, что отдельные темы могут показаться читателю чересчур простыми или общеизвестными. Тем не менее, лично мне этот текст помог упорядочить имеющиеся знания по анализу сложности алгоритмов. Надеюсь, что он окажется полезен и кому-то ещё.
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Опубликовано ранее:
Часть 1
Часть 2

Если вы знаете, что такое логарифмы, то можете спокойно пропустить этот раздел. Глава предназначается тем, кто незнаком с данным понятием или пользуется им настолько редко, что уже забыл что там к чему. Логарифмы важны, поскольку они очень часто встречаются при анализе сложности. Логарифм — это операция, которая при применении её к числу делает его гораздо меньше (подобно взятию квадратного корня). Итак, первая вещь, которую вы должны запомнить: логарифм возвращает число, меньшее, чем оригинал. На рисунке справа зелёный график — линейная функция
Из-за большого объёма оригинальной статьи я разбила её на части, которых в общей сложности будет четыре.
Я (как всегда) буду крайне признательна за любые замечания в личку по улучшению качества перевода.
Опубликовано ранее:
Часть 1
Часть 2
Логарифмы
Если вы знаете, что такое логарифмы, то можете спокойно пропустить этот раздел. Глава предназначается тем, кто незнаком с данным понятием или пользуется им настолько редко, что уже забыл что там к чему. Логарифмы важны, поскольку они очень часто встречаются при анализе сложности. Логарифм — это операция, которая при применении её к числу делает его гораздо меньше (подобно взятию квадратного корня). Итак, первая вещь, которую вы должны запомнить: логарифм возвращает число, меньшее, чем оригинал. На рисунке справа зелёный график — линейная функция
f(n) = n, красный — f(n) = sqrt(n), а наименее быстро возрастающий — f(n) = log(n). Далее: подобно тому, как взятие квадратного корня является операцией, обратной возведению в квадрат, логарифм — обратная операция возведению чего-либо в степень.