Применяем Deep Watershed Transform в соревновании Kaggle Data Science Bowl 2018
Представляем вам перевод статьи по ссылке и оригинальный докеризированный код. Данное решение позволяет попасть примерно в топ-100 на приватном лидерборде на втором этапе конкурса среди общего числа участников в районе нескольких тысяч, используя только одну модель на одном фолде без ансамблей и без дополнительного пост-процессинга. С учетом нестабильности целевой метрики на соревновании, я полагаю, что добавление нескольких описанных ниже фишек в принципе может также сильно улучшить и этот результат, если вы захотите использовать подобное решение для своих задач.
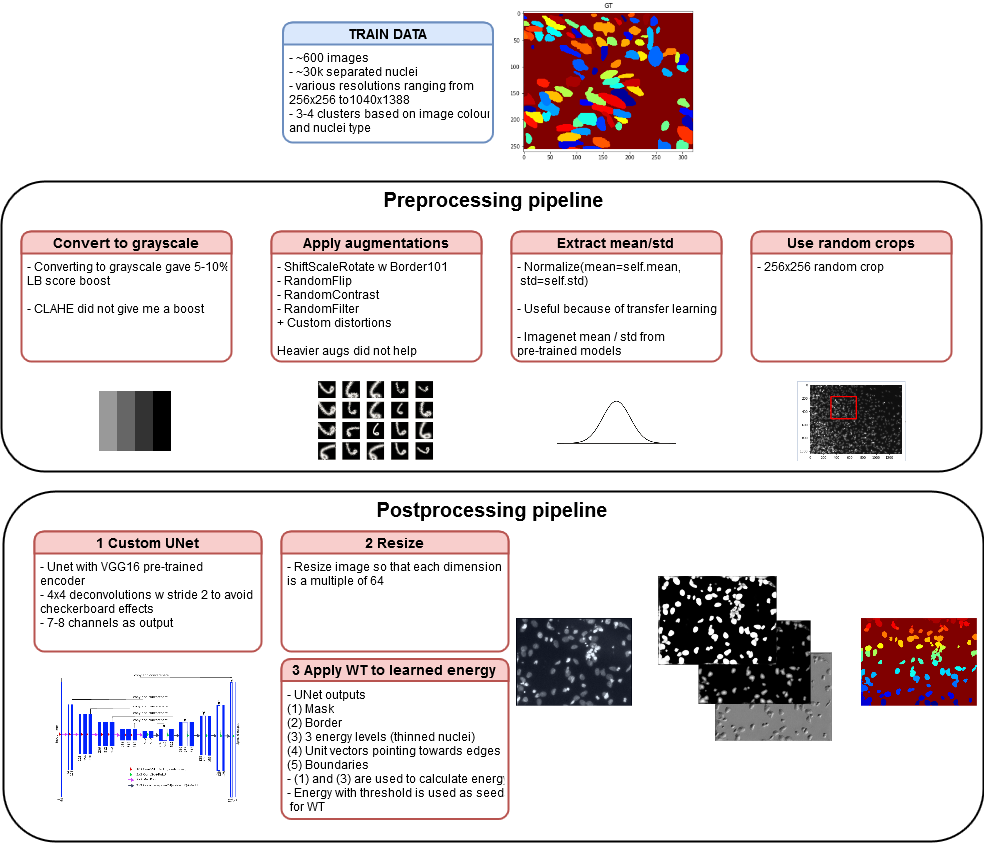
описание пайплайна решения







 Цель этой статьи — поделиться опытом и идеями реализации проекта, основанного на полном преобразовании текстов в семантическое представление и организации семантического (смыслового) поиска по полученной базе знаний. Речь пойдет об основных принципах функционирования этой системы, используемых технологиях, и проблемах, возникающих при ее реализации.
Цель этой статьи — поделиться опытом и идеями реализации проекта, основанного на полном преобразовании текстов в семантическое представление и организации семантического (смыслового) поиска по полученной базе знаний. Речь пойдет об основных принципах функционирования этой системы, используемых технологиях, и проблемах, возникающих при ее реализации. Сначала я хотел честно и подробно написать о методах снижения размерности данных —
Сначала я хотел честно и подробно написать о методах снижения размерности данных —