
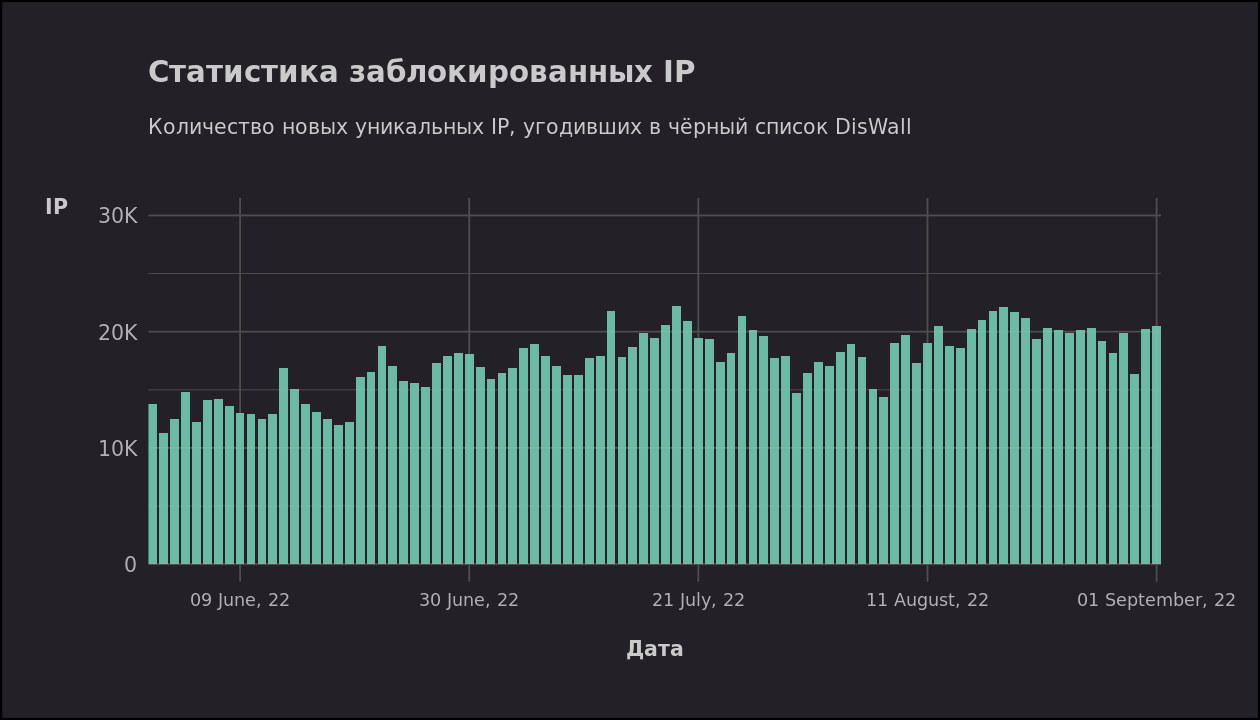
Серверы в опасности!
Вы знали, что каждый включенный и подключенный к сети сервер постоянно подвергается атакам? Это могут быть разные атаки и с разной целью.
Это может быть перебор портов с целью найти открытые от какой-то компании, которая позиционирует себя борцом за безопасность, но которая собирает статистику открытых портов на будущее по всем доступным IP (например Censys).
Может быть Shodan, который тоже собирает базу о том, где какие порты открыты, и отдаёт эту информацию любому заплатившему. И могут быть менее известные компании, которые работают в тени. Представьте, кто-то ходит по всем домам и переписывает модели замков входных дверей, дергает за дверь и выкладывает это в публичный доступ. Дичь! Но тоже самое происходит в интернете тысячи раз в секунду.
Кроме компаний могут быть бот-сети, перебирающие порты для поиска чего-то конкретного или для подготовки к целевым атакам.
Ну и собственно целевые атаки, во время которых ваши серверы в первую очередь тестируются на наличие открытых портов, а затем производятся атаки на найденные сервисы. Это может быть подбор эксплоитов для использования известных дыр или пока неизвестных 0-day, как и обычный DDoS.
Во всех этих сценариях используется предварительный перебор открытых портов. Скорее всего применение nmap или подобных утилит в каких-то скриптах.
Как защитить сервер от сканирования портов без CloudFlare и подобных прослоек?

 Эдвард Мэтью Ворд.
Эдвард Мэтью Ворд.  Пауль де Вос.
Пауль де Вос. 




{kind=link}
{kind=link}