Прим. перев.: Эта статья написана Julia Evans — инженером международной компании Stripe, специализирующейся на интернет-платежах. Разбираться во внутренностях работы планировщика Kubernetes её побудил периодически возникающий баг с «зависанием» пода, о котором около месяца назад также сообщили специалисты из Rancher Labs (issue 49314). Проблема была решена и позволила поделиться деталями о техническом устройстве одного из базовых механизмов Kubernetes, которые и представлены в этом статье с необходимыми выдержками из соответствующего кода проекта.
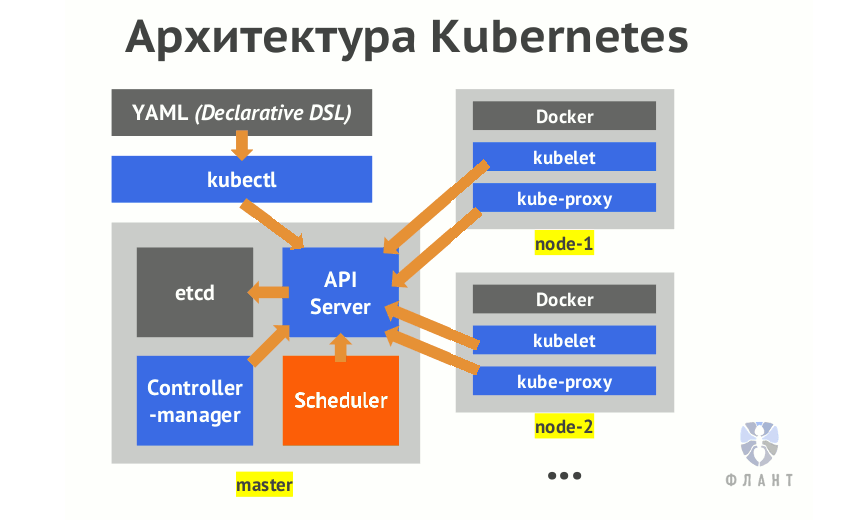
На этой неделе мне стали известны подробности о том, как работает планировщик Kubernetes, и я хочу поделиться ими с теми, кто готов погрузиться в дебри организации того, как это в действительности работает.
На этой неделе мне стали известны подробности о том, как работает планировщик Kubernetes, и я хочу поделиться ими с теми, кто готов погрузиться в дебри организации того, как это в действительности работает.
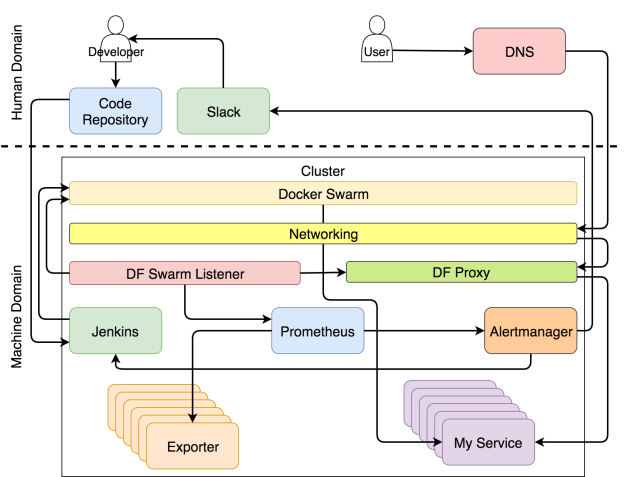



 Привет, Хаброжители! Наконец-то у нас вышла книга Дженнифер Дэвис и Кэтрин Дэниелс — Философия DevOps.
Привет, Хаброжители! Наконец-то у нас вышла книга Дженнифер Дэвис и Кэтрин Дэниелс — Философия DevOps.