
Сначала запрос адаптирован для работы в PostgreSQL 15.6.
Затем работа запроса проверена на достаточно объемной иерархии - в качестве источника данных использована структура архива jdk-master.zip из OpenJDK 22

User
Сначала запрос адаптирован для работы в PostgreSQL 15.6.
Затем работа запроса проверена на достаточно объемной иерархии - в качестве источника данных использована структура архива jdk-master.zip из OpenJDK 22


display: flex;
justify-content: center; /* Горизонтальное центрирование */
align-items: center; /* Вертикальное центрирование */display: grid;
justify-items: center; /* Горизонтальное центрирование */
align-items: center; /* Вертикальное центрирование */justify-content стало justify-items.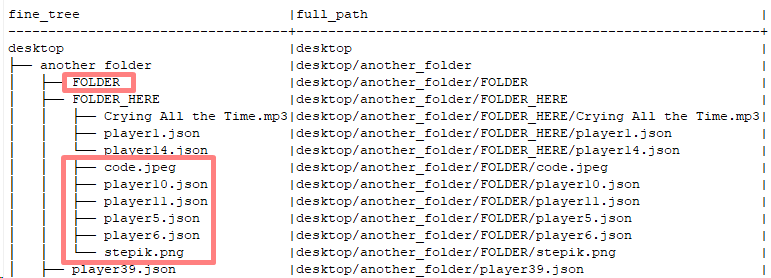
Продолжение статьи, в которой предложено решение задачи визуализации иерархической структуры средствами SQL запросов, на примере MySQL и SQLite
В этой части производится доработка запросов для отображения части иерархии, начиная с конкретных узлов, и анализируются возможные связанные ошибки
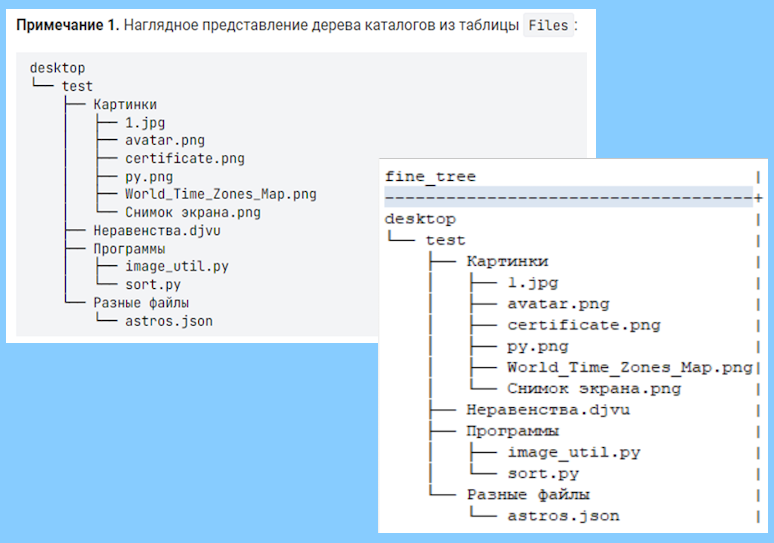
В процессе тестирования одного курса по SQL на stepik.org встретилась задача, из которой сочинилась другая, более интересная:
Необходимо с помощью одного SQL запроса с использованием обобщенных табличных выражений отобразить иерархию, в соответствии с иллюстрацией выше
В предыдущей статье обсуждалась функция ROW_NUMBER. Сейчас же мы рассмотрим другие функции ранжирования: RANK, DENSE_RANK и NTILE. Начнем с RANK и DENSE_RANK. Эти функции по функциональности и реализации аналогичны ROW_NUMBER. Разница в том, что ROW_NUMBER присваивает уникальное (возрастающее) значение каждой строке без учета связей в значениях ORDER BY, а функции RANK и DENSE_RANK присваивают одно и то же значение строкам, имеющим одинаковое значение ORDER BY. Разница между функциями RANK и DENSE_RANK заключается в том, как значения присваиваются строкам. Проще всего проиллюстрировать разницу между всеми этими функциями на простом примере:

Привет друзья, сегодня мы соберём самую маленькую контрольку на ATTINY85, я знаю, что никто из Вас не ждал продолжения этого проекта, но крупные проекты требуют много времени, а видео на канале не могут выходить раз в три месяца. Поэтому сегодня, мы завершим этот проект.
Несмотря на свои размеры, контролька обладает довольно большим функционалом по сравнению со своими китайскими собратьями с AliExpress.
Первое, контролька имеет функцию прозвонки, если прозваниваемый провод цел, на экране появляется надпись MASSA, SMD зумера под такие размеры платы я не нашёл, поэтому вместо него на выход PB0 (он же AREF) поставил конденсатор, для стабильности измерений (более подробно об этом мы поговорим при разборке скетча).
Второе, контролька может измерять напряжение в диапазоне от 0 до 50 вольт.
Третье, контролька имеет защиту от переплюсовки.
И при всех своих преимуществах, печатная плата нашего измерительного прибора меньше спичечного коробка.
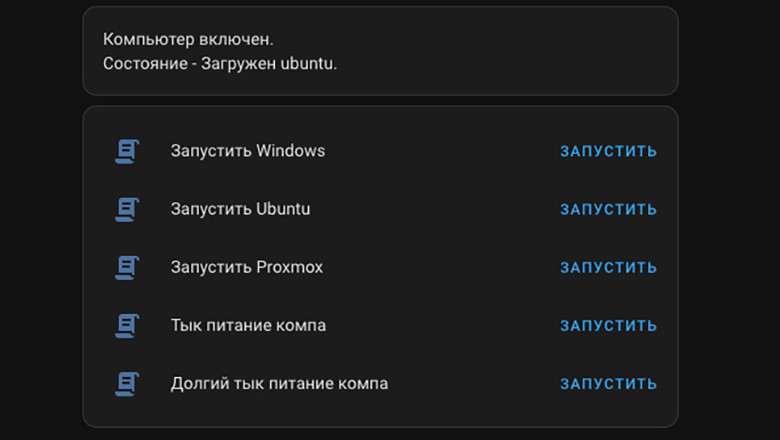
Мой основной компьютер - macbook, который всегда со мной, и на котором я делаю почти все что нужно как дома так и вне его. Но также есть домашний комп, на котором бывает оптимальнее делать ресурсоемкие задачи. Кроме того, некоторые вещи на маке делать неудобно или вовсе невозможно, поэтому на домашнем установлены windows, ubuntu и proxmox с десятком виртуалок под разные случаи. И меня всегда очень напрягала невозможность удаленно включить нужную операционную систему на домашнем, чтобы потом подключиться к ней удаленно и сделать все что нужно.
И что вы думаете - решил я эту проблему. Теперь из любого места я могу запустить нужную мне операционную систему на домашнем компе одним кликом.

Паркет устарел. Пора менять
В этой статье речь пойдет не о напольных покрытиях, а о програмном продукте, более современном конкуренте Apache Parquet, продукте который изначально в 2014 году был разработан компанией Huawei как закрытое и проприетарное ПО, но в 2016 году был преобразован в открытый код и передан в управление Apache Software Foundation, где сейчас поддерживается и разрабатывается open-source сообществом. Речь идет о Apache CarbonData.

Примеры кода на Python для работы с Apache Spark для «самых маленьких» (и немного «картинок»).
Данная статья представляет собой обзор основных функций Apache Spark и рассматривает способы их применения в реальных задачах обработки данных. Apache Spark — это мощная и гибкая система для обработки больших объёмов данных, предлагающая широкий спектр возможностей для аналитики и машинного обучения. В нашем обзоре мы сфокусируемся на ключевых функциях чтения, обработки и сохранения данных, демонстрируя примеры кода, которые помогут новичкам быстро включиться в работу и начать использовать эти возможности в своих проектах.

После того, как я научился запускать spark-submit с мастером в Kubernetes и даже получил ожидаемый результат, пришло время ставить мою задачу на расписание в Airflow. И тут встал вопрос, как это правильно делать. Во всемирной паутине предлагается несколько вариантов и мне было непонятно, какой из них стоит выбрать. Поэтому я попробовал некоторые из них и сейчас поделюсь полученным опытом.

В этой статье, посвященной Python streaming с использованием Spark и Kafka мы рассмотрим основные шаги по настройке окружения и запуску первых простых программ

Всем привет!
В этой статье возьмем за основу пару таблиц и пройдемся по планам запросов по нарастающей: от обычного селекта до джойнов, оконок и репартиционирования. Посмотрим, чем отличаются виды планов друг от друга, что в них изменяется от запроса к запросу и разберем каждую строчку на примере партиционированной и непартиционированной таблицы.

Меня зовут Александр Гирев, я Android-разработчик и технический интервьюер. В одной компании я выполнял роль interview expert: следил за качеством собеседований, готовил рекомендации и матрицы вопросов, обучал начинающих интервьюеров.
Однажды на интервью я спросил кандидата, был ли у него опыт проведения технических собеседований. Кандидат спросил: «Что за опыт — задать пару технических вопросов?». Услышав это, я слегка подвис, ведь я считал интервью серьёзным навыком, почти искусством.
В основе статьи лежит мой опыт проведения собеседований. Расскажу про важные качества технического интервьюера, хорошие и плохие примеры фидбека и про то, как быть, если на собеседовании случился форс-мажор.

Большая подборка для аналитиков данных, продуктовых аналитиков, веб аналитиков, маркетинговых аналитиков и особенно тех, кто хочет ими стать. От автора Telegram-канала «Аналитика и Growth mind-set».
Но прежде несколько важных моментов:



В этой статье я бы хотел рассказать о том, как можно управлять умным домом и всеми устройствами (не только Zigbee) в Home Assistant даже без подключения к интернету.
