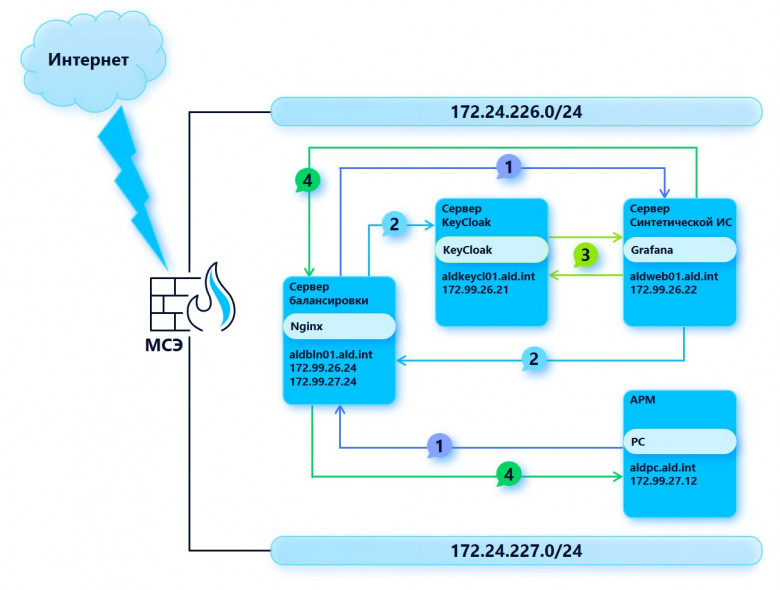
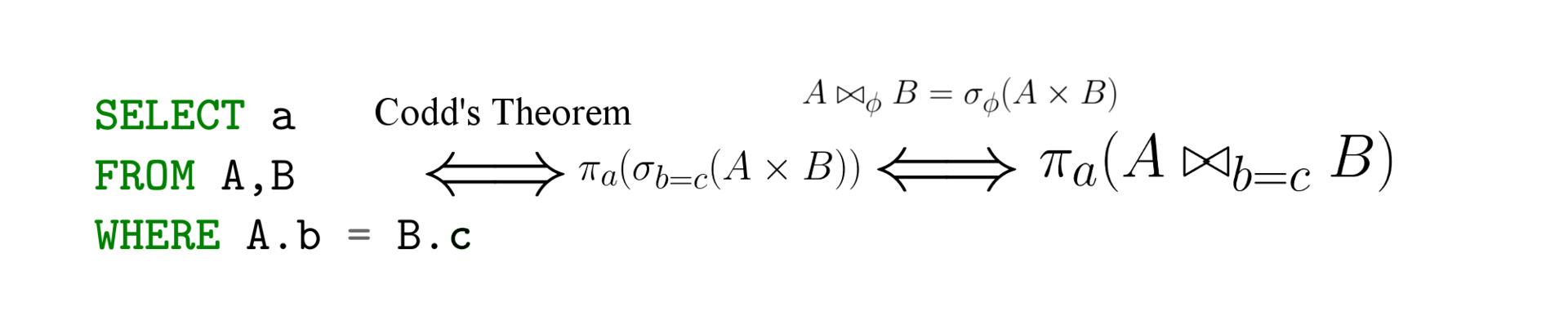Один из наших заказчиков пришел к нам с запросом по комплексному импортозамещению — требовалось организовать переход на новую службу каталогов. В качестве основного решения по замене была выбрана система ALD Pro. Но по ходу проработки решения мы столкнулись с рядом сложностей. Самые большие из них были связаны с заменой компонентов AD FS и публикацией веб-сервисов с помощью WAP. В этом посте рассказываем, как мы решали эту задачу.
За эту статью попрошу благодарить патриотично размороженных граждан в целом, и @WebPeople (регистрация 2012, разморожен с первым комментарием 8 июл 2023 в 20:47) в частности. Глобальное потепление, ничего не поделать.
В мае 2022 в комментариях @hippohood отметился не имеющим аналогов текстом: Примерно опишу мыслительный процесс позитивно (патриотично) настроенных граждан.
Оборудование можно сделать и самим, но пока можно и просто привезти серым импортом. Оборудование выглядит примерно как большой ящик с дырками, включённый в розетку; в одну дырку складываешь кремний, в другую заливаешь фоторезистор. Под третью дырку надо подставить ведро - в него будут ссыпаться чипы. Вёдра мы делать умеем (хотя и импортируем сейчас, но чертежи-то остались), фоторезистор научатся намешивать в Зелинограде; с кремнием разберемся, не всё сразу. Надо ещё заранее заказать в Китае переходник с европейской розетки на нормальную - лучше сразу 3 или 4, они постоянно горят. Вроде все ясно.
Привет, Хабр! В предыдущей статье мы рассмотрели парадигму параллельных вычислений MapReduce. В этой статье мы перейдём от теории к практике и рассмотрим Hadoop – мощный инструментарий для работы с большими данными от Apache foundation.
В статье описано, какие инструменты и средства включает в себя Hadoop, каким образом установить Hadoop у себя, приведены инструкции и примеры разработки MapReduce-программ под Hadoop.
Технологии Big Data создавались в качестве ответа на вопрос «как обработать много данных». А что делать, если объем информации не является единственной проблемой? В промышленности и прочих серьезных применениях часто приходится иметь дело с большими данными сложной и переменной структуры, разрозненными массивами информации. Встречаются задачи, способ решения которых наперед не известен, и аналитику необходимы средства исследования исходных данных или результатов вычислений на их основе без привлечения программиста. Нужны инструменты, сочетающие функциональную мощь систем BI (а лучше – превосходящие ее) со способностью к обработке огромных объемов информации.
Одним из способов получить такой инструмент является создание логической витрины данных. В этой статье мы расскажем о концепции этого решения, а также продемонстрируем программный прототип.
Во время общения с медиа мы в Relap.io часто сталкиваемся с массой заблуждений, в которые все верят, потому что так сложилось исторически. На сайте есть блоки типа «Читать также» или «Самое горячее» и т.п. Словом, всё то, что составляет обвязку статьи и стремится дополнить UX дорогого читателя. Мы расскажем, какие заблуждения есть у СМИ, которые делают контентные рекомендации, и развеем их цифрами.
На Хабре и за его пределами часто обсуждают реляционную алгебру и SQL, но далеко не так часто акцентируют внимание на связи между этими формализмами. В данной статье мы отправимся к самым корням теории запросов: реляционному исчислению, реляционной алгебре и языку SQL. Мы разберем их на простых примерах, а также увидим, что бывает полезно переключаться между формализмами для анализа и написания запросов.
Зачем это может быть нужно сегодня? Не только специалистам по анализу данных и администраторам баз данных приходится работать с данными, фактически мало кому не приходится что-то извлекать из (полу-)структурированных данных или трансформировать уже имеющиеся. Для того, чтобы иметь хорошее представление почему языки запросов устроены определенным образом и осознанно их использовать нужно разобраться с ядром, лежащим в основе. Об этом мы сегодня и поговорим.
Большую часть статьи составляют примеры с вкраплениями теории. В конце разделов приведены ссылки на дополнительные материалы, а для заинтересовавшихся и небольшая подборка литературы и курсов в конце.