AI-сервис Phind - ассистент по программированию для не программистов. Или как я автоматизировал свою рабочую задачу, не написав самостоятельно ни строчки кода.

Пользователь
AI-сервис Phind - ассистент по программированию для не программистов. Или как я автоматизировал свою рабочую задачу, не написав самостоятельно ни строчки кода.

Одно из самых прикладных применений языковых моделей (LLM) - это ответы на вопросы по документу/тексту/договорам. Языковая модель имеет сильную общую логику, а релевантные знания получаются из word, pdf, txt и других источников.
Обычно релевантные тексты раскиданы в разных местах, их много и они плохо структурированы. Одна из проблем на пути построения хорошего RAG - нахождение релевантных частей текста под заданный пользователем вопрос.
Еще В. Маяковский писал: "Изводишь единого слова ради, тысячи тонн словесной руды." Примерно это же самое делают би-энкодеры и кросс-энкодеры в рамках RAG, ищут самые важные и полезные слова в бесконечных тоннах текста.
В статье мы посмотрим на способы нахождения релевантных текстов, увидим проблемы, которые в связи с этим возникают. Попытаемся их решить.
Главное - мы натренируем свой кросс-энкодер на русском языке, что служит важным шагом на пути улучшения качества Retrieval Augmented Generation (RAG). Тренировка будет проходит новейшим передовым способом. Схематично он изображен на меме справа)

Всем привет! Для того, чтобы усилить безопасность серверов Linux привожу ниже советы, основой которых является публикация 40 Linux Server Hardening Security Tips [2023 edition] Вивека Гите. В приведенных инструкциях предполагается использование дистрибутив Linux на базе Ubuntu/Debian. Часть материала от автора я опускаю, так как публикация ориентированна на безопасность хостов Linux в инфраструктуре.
!!! Приведенные ниже рекомендации необходимо тестировать на совместимость с используемыми сервисами. Веред внедрением рекомендую провести тестирование на каждом отдельном типе сервера/приложения. !!!

Ядро ОС выполняет программы параллельно и переключает потоки по таймеру. Каждый процессор выполняет поток независимо от других. Процессоры используют оперативную память совместно, поэтому важно защитить структуры данных от одновременного доступа. Потоки испортят данные, если процессор переключится на другой поток, когда первый поток еще не завершил запись.
Потоки конкурируют за доступ к структуре данных. Ядро кишит структурами, которые потоки используют совместно. Блокировки защищают данные при конкурентном доступе.
Глава расскажет, зачем нужны блокировки, как xv6 реализует и использует блокировки.
Эта статья описывает разработку Базисной модели интерактивного агента.
Интерактивные агенты описываются как: "интеллектуальный агент, способный автономно принимать подходящие действия на основе сенсорной информации, будь то в физическом мире или в виртуальной или смешанной реальности, представляющей физический мир". Для примера приведен робот, которого вытащили из коробки и он может сразу адаптироваться к выполнению бытовых задач в домашней среде.
Новый подход включает обучение одной нейронной модели на множестве задач и модальностей данных, используя достижения в области универсальных основных моделей. Она представляет собой переход от статичных, специфичных для задач систем ИИ к более адаптируемым и универсальным агентам.
Модель работает с тремя типами данных - текст, визуальные данные и действия. Таким образом, каждый входной образец содержит текстовые инструкции, видео и токены действий. Они обозначают каждый образец как последовательность S = (W,V1,A1,V2,A2,...,VT,AT), где W - это последовательность токенов, соответствующих текстовой инструкции, Vi - это последовательность патчей изображений, соответствующих кадру i, а Ai - это последовательность токенов действий, соответствующих кадру i видеопоследовательности из T кадров.
Базисная модель обучена на 13,4 миллионах видеокадров под несколько типов сред, может эффективно работать в интерактивных мультимодальных настройках, используя текст, видео, изображения, диалоги, подписи, визуальное ответ на вопросы и воплощенные действия в четырех различных виртуальных средах. Всего модель имеет 277 миллионов параметров.
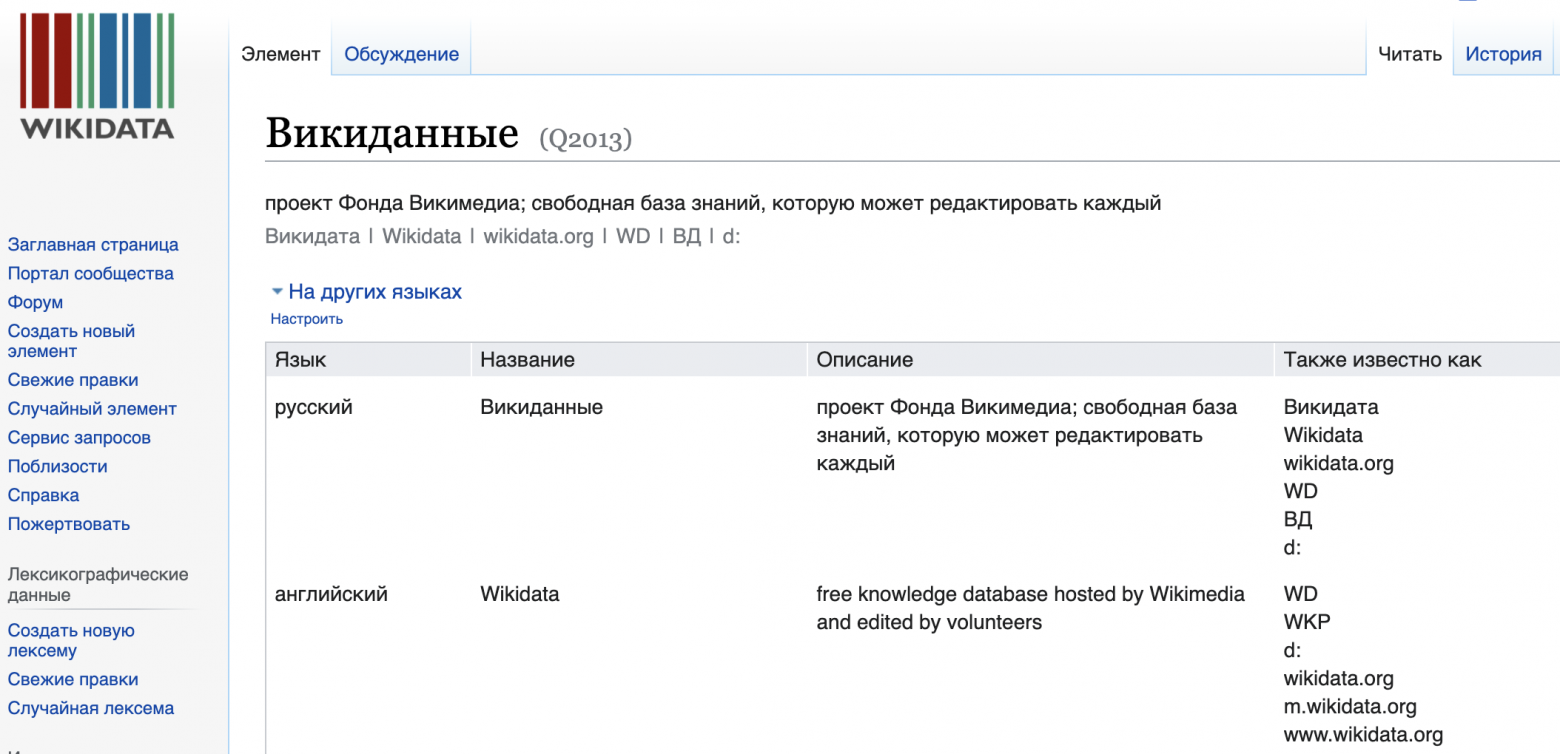
Существует множество сервисов по подбору синонимов, но они редко справляются с терминами, которые содержат в себе более одного слова. Для подбора синонимов для более сложных выражений могут помочь Викиданные. Мало кто знает, что помимо стандартной Википедии существует дополнительная база данных Викиданные(Wikidata), которая представляет собой граф знаний фонда Викимедия. Сейчас она интегрирована в саму Википедию, поэтому для многих статей в левом меню можно найти пункт Элемент Викиданных. Викиданные представлены в модели rdf, то есть информация имеет вид триплетов, которые характеризуют сущность. Триплет выглядит, как утверждение субьект - предикат - обьект. Пример, для сущности Англия одним из таких информационных триплетов представлен: Англия - имеет столицу - Лондон.
Один из предикатов(типов связи) это altLabel, подразумевающий под собой альтернативные названия, который как раз таки и поможет нам в поиске синонимов.
Сразу стоит учитывать, что Викиданные это очень обширная база знаний, но, тем не менее, не совершенная. Поэтому, для терминов, которые там не представлены, или представлены, но для их сущностей нет введенных альтернативных названий, синонимов найдено не будет.
Хочу представить вам пересказ-обзор на статью Large Language Model based Multi-Agents: A Survey of Progress and Challenges, представленную группой ученых(Taicheng Guo , Xiuying Chen , Yaqi Wang , Ruidi Chang , Shichao Pei, Nitesh V. Chawla, Olaf Wiest , Xiangliang Zhang) 21 января 2024 года.
Статья является обзором на тему нашумевших систем мультиагентов, рассказывая про различные методы классификации таких систем, проблемы в разработке мультиагентных систем и областях применения.
Благодаря развитию больших языковых моделей (LLM) открылись новые возможности сфере автономных агентов, которые могут воспринимать окружающую среду, принимать решения и предпринимать ответные действия. Таким образом, агенты на основе сильных LLM смогли достичь уровня понимания и генерации инструкций, подобных человеческим, что облегчает сложное взаимодействие и принятие решений в широком диапазоне контекстов.
На основе вдохновляющих возможностей одного агента на базе LLM были предложены системы мультиагентов на основе LLM(LLM-MA), позволяющие использовать коллективный разум, а также специализированные профили и навыки нескольких агентов. По сравнению с системами, использующими один агент на основе LLM, многоагентные системы предлагают расширенные возможности за счет специализации LLM на различных отдельных агентах с разными возможностями и обеспечения взаимодействия между этими различными агентами для моделирования сложных реальных процессов. В этом контексте несколько автономных агентов совместно участвуют в планировании, обсуждениях и принятии решений, отражая совместный характер групповой работы людей при решении задач.

Революция в области искусственного интеллекта переформатирует все отрасли нашей жизни, с одной стороны обещая невероятные инновации, а с другой ー сталкивая нас с новыми вызовами. В безумном потоке изменений эффективная обработка данных становится приоритетом для приложений, на основе больших языковых моделей, генеративного ИИ и семантического поиска. В основе этих технологий лежат векторные представления (embeddings, дальше будем называть их Эмбеддинги), сложные представления данных, пронизанные критической семантической информацией.
Эти вектора, созданные LLMs, охватывают множество атрибутов или характеристик, что делает управление ими сложной задачей. В области искусственного интеллекта и машинного обучения эти характеристики представляют различные измерения данных, необходимые для обнаружения закономерностей, взаимосвязей и базовых структур. Для удовлетворения уникальных требований к обработке этих вложений необходима специализированная база данных. Векторные базы данных специально созданы для обеспечения оптимизированного хранения и запросов векторов, сокращая разрыв между традиционными базами данных и самостоятельными векторными индексами, а также предоставляя ИИ-системам инструменты, необходимые для успешной работы в этой среде нагруженной данными.

Операционная система выполняет несколько процессов одновременно. ОС распределяет время работы с ресурсами компьютера между процессами. ОС даст каждому процессу шанс на выполнение, даже если число процессов больше числа процессоров.
ОС изолирует процессы друг от друга так, что ошибка в одном процессе не нарушит работу других.
ОС позволяет процессам взаимодействовать - обмениваться данными и работать совместно.
Глава 2 рассказывает, как xv6 выполняет эти требования, о процессах xv6 и как xv6 запускает первый процесс.

Я понимаю, что пока, за использования VPN, аннонимайзеров и/или tor не применяют уголовные статьи, поэтому гораздо проще скачать какое нибудь приложение из магазина приложений и бесплатно воспользоваться им. Но где гарантия, что завтра они будут работать?
Я понимаю (программисты, сисадмины, DevOps'ы и т.д.) данный способ нельзя назвать уникальным, оптимальным и вообще, так лучше не делать, но согласитесь - это достаточно простой способ туннелирования трафика, который позволяет обойти (если не все), то огромное количество разнообразных сетевых блокировок.
О туннелирование через SSH на хабре написана не одна статья, но в виде инструкции, которую можно дать любому домохозяйкеину (ведь в рф запретили феминитивы) лично я не нашел. Поэтому добро пожаловать подкат.
Так же, этот способ - достаточно дешевый (меньше чашки кофе в день) и очень быстрый с точки зрения реализации (буквально 5 минут).
Интересно?

Привет, меня зовут Денис. Я работаю руководителем проектов в компании Raft. Хочу поделиться с вами, насколько просто создать своего ассистента для вашей компании, работы или других вопросов, тем самым экономить на курсах и консультациях. До недавнего времени промпты воспринимались, как поисковые запросы. Но с их помощью можно создать небольшую программу.
Хотите узнать, как это сделать? Добро пожаловать под кат. Там мы с вами разработаем промпт для ассистента. В качестве примера рассмотрим создание ассистента для бизнеса, ориентированного на стратегические вопросы.

Если, открывая холодильник вы еще не слышали из него про RAG, то наверняка скоро услышите. Однако, в сети на удивление мало полных гайдов, учитывающих все тонкости (оценка релевантности, борьба с галлюцинациями и т.д.) а не обрывочных кусков. Базируясь на опыте нашей работы, я составил гайд который покрывает эту тему наиболее полно.
Итак зачем нужен RAG?

С момента запуска GigaChat прошло около полугода, и за это время у нас появилось более полутора миллионов пользователей. Они активно используют нейросетевые технологии как в работе, так и для развлечения. От пользователей поступают разнообразные запросы: от просьбы сделать краткую выжимку из текста письма до срочного написания поэмы на день рождения коллеги-тестировщика. Мы всегда учитываем обратную связь, которая помогает нам развиваться и внедрять новые идеи.
За последнее время нами были выпущены новые модели и добавлены новые функциональные возможности в сервис. А теперь мы представляем новую нейросетевую модель, у которой более 29 миллиардов параметров. Она успешно прошла тест на ЕГЭ и показала отличные результаты в сравнении с другими системами. Если вы только начинаете интересоваться новыми технологиями в области искусственного интеллекта, то имейте в виду, именно они в ближайшие годы будут формировать наше с вами будущее и давать преимущество тем, кто ими владеет. Давайте познакомимся с ними поближе.

Всем привет! Меня зовут Дмитрий, я более 7 лет занимаюсь трансформациями компаний и построением процессов в области создания продуктов и управления проектами с помощью Гибких подходов управления Agile. Недавно меня пригласили в один развивающийся американский стартап, который делает SAAS B2B продукт.

Современный мир бизнеса и разработки программного обеспечения характеризуется высокой динамикой и необходимостью быстрого реагирования на изменения в рыночных условиях. В этом контексте эффективная организация команд становится ключевым фактором успеха.
Team Topologies - это концепция, которая предлагает рациональный и гибкий подход к организации команд внутри организации. Классические подходы к организации Agile команд, как правило, рекомендуют создавать универсальные и кроссфункциональные команды, где любая команда может сделать любую фичу из беклога.

В отличие от таких операционных систем как HPUX (dbc_min_pct, dbc_max_pct) или AIX (minperm%, maxperm%), в Linux нет возможности настраивать размер кэша страниц, читаемых с диска (страничный кэш, page cache). Под страничный кэш Linux использует всю доступную память. Размер страничного кэша можно увидеть в /proc/meminfo в параметре "Cached". В /proc/meminfo есть также значение "Buffers", которое часто путают с размером страничного кэша. "Buffers" — это память, содержащая сырые дисковые данные (raw disk data) и выступающая в роли промежуточного буфера между процессами, ядром и диском.
В этой статье рассмотрим, как Linux работает с памятью, и, в частности, со страничным кэшем, а также исследуем, как доступный объем памяти влияет на производительность буферизованного ввода-вывода (buffered IO).

Салют! Уже ни для кого не секрет, что GigaChat активно развивается, и обновление моделей не заставляет себя долго ждать. Рады сообщить вам, что новые версии GigaChat Lite и GigaChat Pro получили мощный апгрейд и стали еще более креативными, умными и точными в исполнении инструкций, а также получили более высокую оценку, чем ChatGPT (gpt-3.5-turbo-0613) на бенчмарке MMLU. На сегодняшний день GigaChat используют уже более 2,5 миллионов человек.
В новом обновлении GigaChat Lite получил расширение максимального контекста до 32768 токенов (GigaChat Lite+), а GigaChat Pro — до 8192 токенов. Вместе с контекстом мы улучшили качество ответов, превзойдя ChatGPT на русском SBS и английском MMLU, а также сделали апдейт датасетов по экономике, медицине и праву, добавили экспертные и редакторские данные, а также прокачали функции (улучшили работу запросов).
Узнать, как попробовать самую сильную версию GigaChat бесплатно, можно в конце статьи.

Скептически настроенные к теории всего читатели моих тем постоянно просили дать конкретный пример наблюдаемого следствия теории. Я не торопился, чтобы подготовить слабонервных. Однако, дальше откладывать нельзя. Тут надо вспомнить известную песню «Всё хорошо, прекрасная маркиза» и выкладывать плохие новости для одиозных старых теорий, начиная с пустяков.
Изложение теории Метавселенной логично начать с системы естественных единиц априорной теории всего. Например, широко известна система, предложенная в 1901 году немецким физиком Максом Планком и названная в его честь.