
Я постарался придумать самое простое объяснение дизайн-токенов на примере житейских ситуаций. Что это такое, как работают и зачем они нужны — в этой статье.
Про принципы наименований, экспорт токенов из фигмы и передачу токенов разработчикам.

Backend Developer
Я постарался придумать самое простое объяснение дизайн-токенов на примере житейских ситуаций. Что это такое, как работают и зачем они нужны — в этой статье.
Про принципы наименований, экспорт токенов из фигмы и передачу токенов разработчикам.

Всем привет! Возможно уже совсем скоро разные новостные и IT-ресурсы будут подчищать информацию о способах обхода блокировок. А пока этого не случилось, запасаемся полезными гайдами и разворачиваем свои собственные VPN с защищенными от блокировок протоколами. Расскажу как это сделать, как изменилась Amnezia и как мы защитили WireGuard от блокировок.

Мы в API отказались от большого количества unit-тестов в пользу большого количества интеграционных/системных, чтобы тестировать меньшим количеством кода большее количество функций, а также наблюдать за взаимодействием разных частей системы.
На самом деле мы просто решили писать тесты не на отдельные классы/методы, а на интерфейс api, которым пользуются клиенты - на сервисы этого API. Тестируя их, мы убиваем двух зайцев: проверяем логику работы сервисов api + форматирование результата.
А такое тестирование сопряжено с несколькими проблемами.
1. Общие сведения.
2. Увеличиваем потребление памяти вдвое.
3. Увеличиваем потребление памяти втрое.
4. Ещё раз увеличиваем потребление памяти на ровном месте.
5. Заключение.

На кластерах клиентов, которые мы обслуживаем, есть как «одноголовые» инсталляции Redis (обычно для кэшей, которые не страшно потерять), так и более отказоустойчивые решения — Redis Sentinel или Redis Cluster. По нашему опыту, во всех трех вариантах можно безболезненно переключиться с Redis на KeyDB и получить прирост производительности. Точнее, избавиться от бутылочного горлышка Redis в одно ядро. Хотя в новых версиях Redis(r) появилась обработка I/O в отдельных тредах, иногда этого бывает недостаточно.
В то же время, если мы хотим использовать отказоустойчивые решениями вроде Sentinel и Cluster, нам понадобится поддержка этих технологий на уровне библиотеки, которую приложение использует для подключения в Redis. Причем лишь немногие библиотеки умеют читать из реплик Redis — в обоих вариантах (Sentinel и Cluster) чтение, как правило, происходит с мастеров. И запись, естественно, тоже происходит в мастеры.
В итоге у нас есть несколько реплик довольно дорогого in-memory-хранилища, а в рабочем процессе используется только часть из них. Остальные — на подхвате. Хотя в большинстве кейсов операции с in-memory NoSQL DB — это именно операции чтения.
Однако если посмотреть в сторону KeyDB, то можно увидеть, что там есть киллер-фича — и даже две: я говорю о режимах Active Replica и Multi-Master. Использование этих режимов позволяет получить распределенный отказоустойчивый KeyDB, совместимый с Redis, писать в любую ноду, читать из любой ноды. И все это с точки зрения приложения выглядит как один экземпляр Redis без всяких Sentinel — то есть в коде приложения ничего менять не придется.
Звучит как фантастика?




Привет, Хабр! В статье расскажу о том, с какими трудностями можно столкнуться при разработке ORM на PHP и поделюсь опытом по их преодолению.
Рассказывать буду только о том, о чём знаю сам. У вас может быть абсолютно другое мнение. Поэтому если вы нашли ошибку или хотите обсудить — свяжитесь со мной.



Airflow это популярная опенсорсная платформа управления задачами. В частности его используют для построения ETL-пайплайнов. Например, мне доводилось переливать данные между базами данных, хранилищами и озерами данных с его помощью. А также я использовал его для препроцессинга данных для моделей машинного обучения. Но так ли подходит Airflow для ETL на сегодняшний день?
В этой статье мы рассмотрим как с помощью Airflow ETL операторов выгрузить данные из Postgres в BigQuery в парадигмах ETL и ELT. Далее разберем сложности, с которыми вы можете столкнуться при реализации инкрементальной загрузки данных в DAG (DAG - directed acyclic graph, ориентированный ацикличный граф - цепочка связанных задач). Наконец, мы обсудим почему Airflow ETL операторы не смогут покрыть все ваши потребности в интеграциях в дальней перспективе.


Задачи окружают нас повсюду — и дома, и на работе, и во всяческих аспектах нашей повседневной жизни. У каждого со временем появляются собственные приёмы и методики работы со списками задач. Кто-то предпочитает модные приложения и продвинутые программы, кто-то по старинке всё записывает в бумажный ежедневник. А некоторые вообще не занимаются специальным планированием, но при этом чудесным образом всё успевают.
За долгие годы работы в IT такие методики и принципы выработались и у меня. Например, «Принцип пустого почтового ящика». Или «Принцип постепенного проявления». Они проверены временем и помогают мне успешно ориентироваться в окружающем потоке задач. В этой статье я хочу поделиться с вами этими принципами. Возможно, какие-то из них покажутся вам полезными и пригодятся.
Данная статья планировалась мной, как небольшая "лабораторка" для знакомства с сервисом Grafana OnCall, ее возможностями и особенностями.

В предыдущей статье я рассказывал, как построить простой кластер Kubernetes с одним мастер-узлом. Прошло время, опали листья... и мне захотелось большего, поэтому решил позариться на высокодоступные кластеры. В интернете много статей о том, как построить подобное решение, и давайте даже опустим тот факт, что многие из них уже устарели. Одно дело — установить кластер, а как же обслуживание: удаление, добавление, замена узлов? Про это и не вспоминают! В итоге оказалось, что не всё так просто, и вот, спустя больше ста установок, удалений и замен, у меня получилось собрать подробнейшее руководство по установке и, главное, обслуживанию highly available кластера с помощью Kubespray.

Я очень люблю тему когнитивных искажений, и сейчас мне эта тема кажется актуальной, поэтому я решила написать о ней статью. На Хабре уже есть несколько статей о когнитивных искажениях, но еще одна статья вряд ли будет лишней.
Понимать, как работает мозг, очень важно. Это поможет избежать неправильных умозаключений, которые могут нанести вред не только вам, но и окружающим людям.
На русском языке когнитивные искажения часто называют “ошибками мышления”. Мне не очень нравится этот термин, потому слово “ошибка” подразумевает, что когнитивные искажения являются обязательно чем-то неправильным. Но это не совсем так, когнитивные искажения - это просто особенности мышления, которые очень часто помогают нам выживать, однако, в некоторых ситуациях могут играть не в нашу пользу.
Я не буду перечислять все когнитивные искажения, потому что их огромное множество, тогда я рискую не дописать свою статью в ближайшие месяцы. Я расскажу только о тех, которые мне кажутся наиболее актуальными и о которых мне есть, что рассказать.

Мы занимаемся разработкой огромного количества сложного ПО для автоматизации и энтерпрайза и Workflow для нас — это большая и больная проблема. Если для вас тоже — я расскажу, как писать и оркестрировать очень сложные процессы на масштабах, и как убедиться, что они не падают. А также как делать таймеры на 30 дней внутри процессов. И самое главное, как всё это пилить на PHP.
Меня зовут Антон Титов. Я более 17 лет занимаюсь коммерческой разработкой. Являюсь соавтором Spiral Framework, RoadRunner и Cycle ORM. Основной стек: PHP и Golang. Разговор пойдет про нашу разработку Temporal PHP SDK, которая и помогает решать все вышеперечисленные сложные задачи.
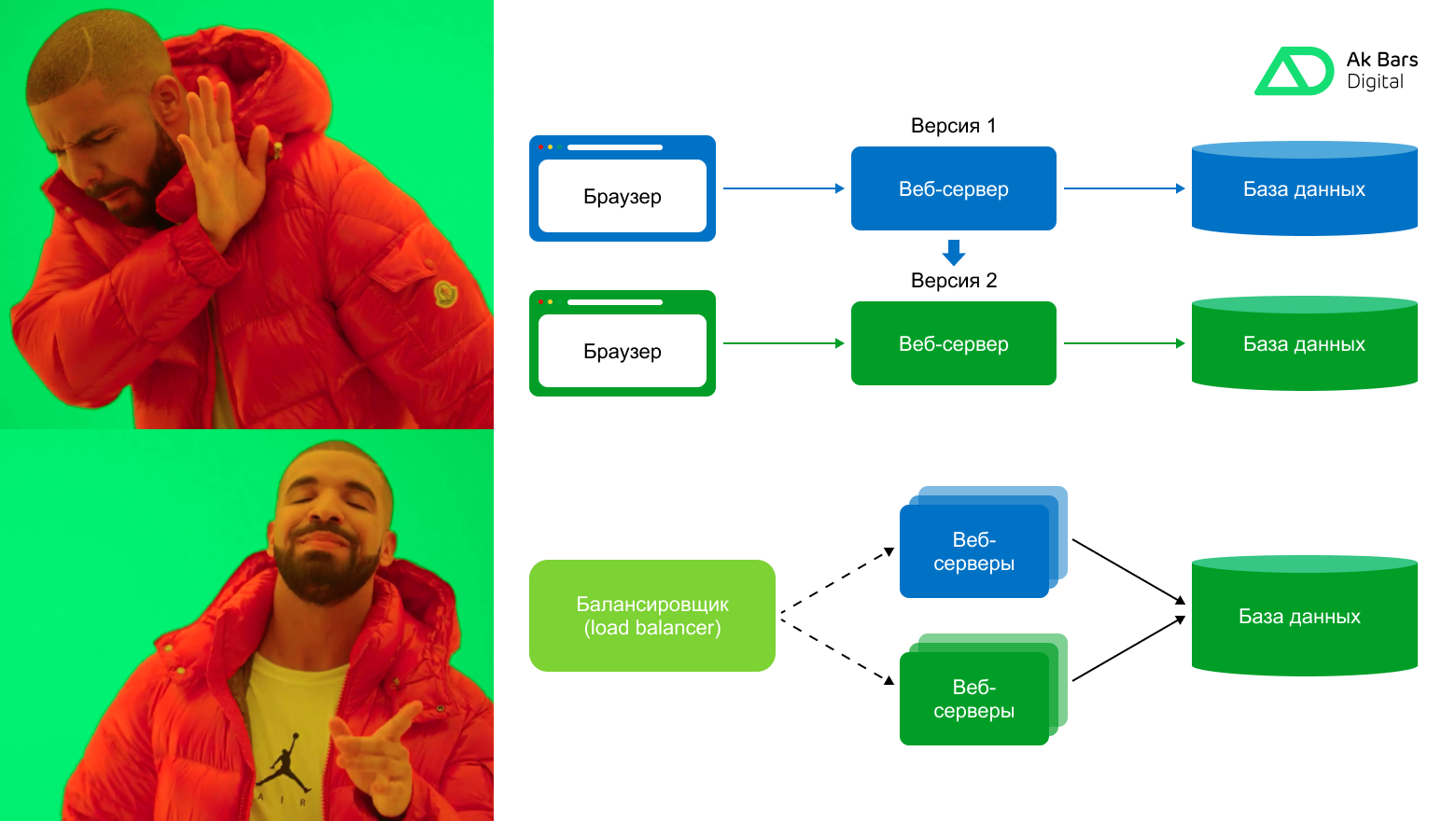
Банковские сервисы по умолчанию не должны падать, и даже прилечь на секундочку, и даже когда мы обновляемся. Ведь даже секунды могут привести к потерям с множеством нулей. Чтобы этого не произошло мы используем blue-green deployment.
Простым языком blue-green deployment - способ развертывания, который позволяет обновлять приложения не отклоняя ни одного запроса, без остановок. Как это сделать, расскажу и покажу на примере. Статья подойдет DevOps-инженерам и бэкенд-разработчикам, особенно на HighLoad-проектах, а также моим будущим коллегам, как методичка по безрисковым релизам, чтобы прод не падал каждые 2 недели по графику релизов (а такое тоже бывало).

На днях по работе потребовалось сделать утилиту, которая прямо вот из консоли ходит в апи нашего клауд сервиса и берет оттуда кое-какую информацию.
Подробности что и зачем - вне этого рассказа. Принципиальный вопрос здесь другой - скорость. Скорость реально важна (порядок количества запросов - десятки и сотни). Потому что ждать - не кайф.
Здесь я хочу поделиться своим ресёрчем на тему запросов, как делать круто, а как нет. С примерами кода конечно. А так же рассказать, как я тупил.