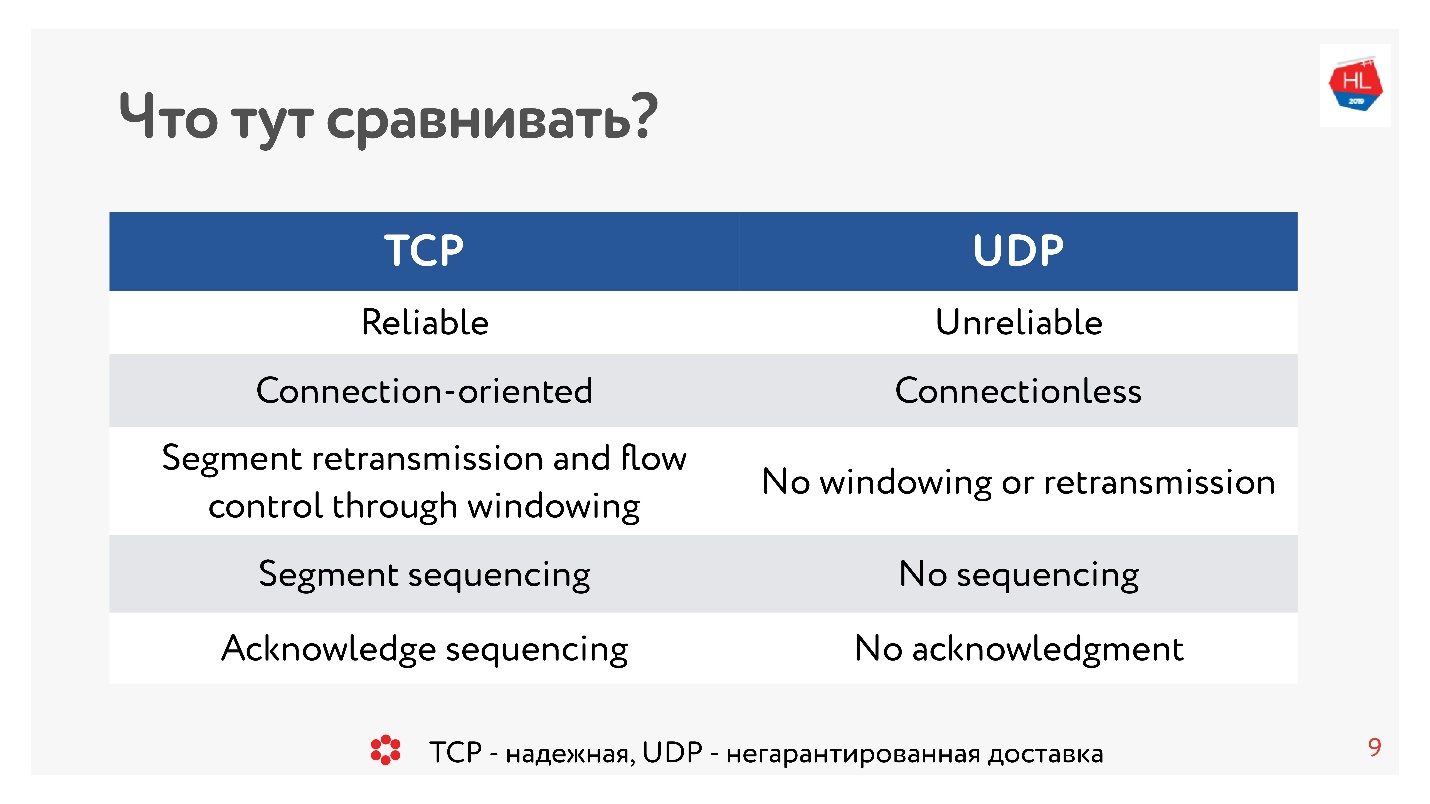
Облака подобны магической шкатулке — задаешь, что тебе нужно, и ресурсы просто появляются из ниоткуда. Виртуальные машины, базы данных, сеть — все это принадлежит только тебе. Существуют и другие тенанты облака, но в своей Вселенной ты единоличный правитель. Ты уверен, что всегда получишь требуемые ресурсы, ни с кем не считаешься и самостоятельно определяешь, какой будет сеть. Как устроена эта магия, которая заставляет облако эластично выделять ресурсы и полностью изолировать тенанты друг от друга?
Облако AWS это мегасуперсложная система, которая эволюционно развивается с 2006 года. Часть этого развития застал Василий Пантюхин — архитектор Amazon Web Services. Как архитектор он видит изнутри не только конечный результат, но и сложности, которые преодолевает AWS. Чем больше понимания работы системы, тем больше доверия. Поэтому Василий поделится секретами облачных сервисов AWS. Под катом устройство физических серверов AWS, эластичная масштабируемость БД, кастомная база данных Amazon и методы повышения производительности виртуальных машин с одновременным уменьшением их цены. Знание архитектурных подходов Amazon поможет эффективнее использовать сервисы AWS и, возможно, даст новые идеи по построению собственных решений.
Облако AWS это мегасуперсложная система, которая эволюционно развивается с 2006 года. Часть этого развития застал Василий Пантюхин — архитектор Amazon Web Services. Как архитектор он видит изнутри не только конечный результат, но и сложности, которые преодолевает AWS. Чем больше понимания работы системы, тем больше доверия. Поэтому Василий поделится секретами облачных сервисов AWS. Под катом устройство физических серверов AWS, эластичная масштабируемость БД, кастомная база данных Amazon и методы повышения производительности виртуальных машин с одновременным уменьшением их цены. Знание архитектурных подходов Amazon поможет эффективнее использовать сервисы AWS и, возможно, даст новые идеи по построению собственных решений.